
Croot Part6 Eportfolio
Croot Part6 Eportfolio
You might also like
- Adam, B. (2008) - of Timescapes Futurescapes and TimeprintsDocument9 pagesAdam, B. (2008) - of Timescapes Futurescapes and TimeprintsbrenderdanNo ratings yet
- 6 Historical Phase of SenDocument23 pages6 Historical Phase of SenRebecca OngNo ratings yet
- Stats ProjectDocument14 pagesStats Projectapi-302666758No ratings yet
- Skittles Project Part 1Document6 pagesSkittles Project Part 1api-457501806No ratings yet
- Skittles Project 1Document7 pagesSkittles Project 1api-299868669100% (2)
- Skittle Term ProjectDocument15 pagesSkittle Term Projectapi-260271892No ratings yet
- M&M ReportDocument5 pagesM&M ReportPamela L. Robinson100% (1)
- Visualize This: The FlowingData Guide to Design, Visualization, and StatisticsFrom EverandVisualize This: The FlowingData Guide to Design, Visualization, and StatisticsRating: 3.5 out of 5 stars3.5/5 (23)
- Mbti Workshop - 2 DayDocument2 pagesMbti Workshop - 2 DayManish JhuraniNo ratings yet
- Jean Piaget's TheoryDocument15 pagesJean Piaget's TheoryRosman Drahman100% (1)
- Semi-Detailed Lesson Plan in Arts 10Document5 pagesSemi-Detailed Lesson Plan in Arts 10joy89% (9)
- The Rainbow ReportDocument11 pagesThe Rainbow Reportapi-316991888No ratings yet
- Math 1040 Statistics Term Project: Blake FreemanDocument10 pagesMath 1040 Statistics Term Project: Blake Freemanapi-252919218No ratings yet
- StatsfinalprojectDocument7 pagesStatsfinalprojectapi-325102852No ratings yet
- Term Project - EportfolioDocument7 pagesTerm Project - Eportfolioapi-251981709No ratings yet
- Skittles ProjectDocument6 pagesSkittles Projectapi-319345408No ratings yet
- Skittles AssignmentDocument8 pagesSkittles Assignmentapi-291800396No ratings yet
- Final ProjectDocument6 pagesFinal Projectapi-283261340No ratings yet
- Final ProjectDocument9 pagesFinal Projectapi-262329757No ratings yet
- The Full Skittles ProjectDocument6 pagesThe Full Skittles Projectapi-340271527100% (1)
- Skittle Pareto ChartDocument7 pagesSkittle Pareto Chartapi-272391081No ratings yet
- Math 1040 Term ProjectDocument7 pagesMath 1040 Term Projectapi-340188424No ratings yet
- EportfolioDocument12 pagesEportfolioapi-251934892No ratings yet
- Skittles Project 5-02Document8 pagesSkittles Project 5-02api-354040698No ratings yet
- EportfolioDocument8 pagesEportfolioapi-242211470No ratings yet
- Skittles ProjectDocument9 pagesSkittles Projectapi-242873849No ratings yet
- The Skittles Project FinalDocument8 pagesThe Skittles Project Finalapi-316760667No ratings yet
- Skittles ProDocument9 pagesSkittles Proapi-241124972No ratings yet
- Term Project ReportDocument9 pagesTerm Project Reportapi-238585685No ratings yet
- Math 1040 Skittles Term ProjectDocument9 pagesMath 1040 Skittles Term Projectapi-319881085No ratings yet
- Skittles Project With ReflectionDocument7 pagesSkittles Project With Reflectionapi-234712126100% (1)
- TP 2 StatsDocument5 pagesTP 2 Statsapi-240850453No ratings yet
- Skittles Final ProjectDocument5 pagesSkittles Final Projectapi-251571777No ratings yet
- SkittlesdataclassprojectDocument8 pagesSkittlesdataclassprojectapi-399586872No ratings yet
- Final Math ProjectDocument7 pagesFinal Math Projectapi-316775963No ratings yet
- Math 1040 Skittles Term Project EportfolioDocument7 pagesMath 1040 Skittles Term Project Eportfolioapi-260817278No ratings yet
- Skittles Term Project 11 9 14Document5 pagesSkittles Term Project 11 9 14api-192489685No ratings yet
- Math 1040Document3 pagesMath 1040api-219553415No ratings yet
- Team Project Part 6 Final ReportDocument8 pagesTeam Project Part 6 Final Reportapi-316794103No ratings yet
- The Science of Collecting, Organizing, Summarizing, and Analyzing Information To Draw Conclusions or Answer QuestionsDocument7 pagesThe Science of Collecting, Organizing, Summarizing, and Analyzing Information To Draw Conclusions or Answer Questionsapi-438148756No ratings yet
- Group Project #1 - SkittlesDocument9 pagesGroup Project #1 - Skittlesapi-245266056No ratings yet
- Skittles Project Stats 1040Document8 pagesSkittles Project Stats 1040api-301336765No ratings yet
- Skittles Project FinalDocument5 pagesSkittles Project Finalapi-271348941No ratings yet
- Skittles Term ProjectDocument10 pagesSkittles Term Projectapi-273060240No ratings yet
- Math 1040 Final ProjectDocument3 pagesMath 1040 Final Projectapi-285380759No ratings yet
- Skittles 2 FinalDocument12 pagesSkittles 2 Finalapi-242194552No ratings yet
- Term Project Part 7Document8 pagesTerm Project Part 7api-291870758No ratings yet
- Skittles FinalDocument12 pagesSkittles Finalapi-241861434No ratings yet
- Statistics Term Project E-Portfolio ReflectionDocument8 pagesStatistics Term Project E-Portfolio Reflectionapi-258147701No ratings yet
- Math 1040Document5 pagesMath 1040api-534403229No ratings yet
- SkittlesDocument5 pagesSkittlesapi-249778667No ratings yet
- Term Project Part 5 Compile Term Project Reflection and Eportfolio Posting 1Document8 pagesTerm Project Part 5 Compile Term Project Reflection and Eportfolio Posting 1api-303044832No ratings yet
- Skittles ProjectDocument5 pagesSkittles Projectapi-271444168No ratings yet
- Stats StuffDocument7 pagesStats Stuffapi-242298926No ratings yet
- Skittles ProjectDocument9 pagesSkittles Projectapi-252747849No ratings yet
- Math ProfileDocument9 pagesMath Profileapi-454376679No ratings yet
- Numerical Calculations or Graphs or Tables. Inferential Statistics Makes Inferences and Predictions About A Population Based On A Sample of Data Taken From The Population in QuestionDocument2 pagesNumerical Calculations or Graphs or Tables. Inferential Statistics Makes Inferences and Predictions About A Population Based On A Sample of Data Taken From The Population in QuestionArjay CajesNo ratings yet
- Skittles Project 2Document5 pagesSkittles Project 2api-355504623No ratings yet
- Final SkittlesDocument6 pagesFinal Skittlesapi-272838320No ratings yet
- 1040 Term ProjectDocument8 pages1040 Term Projectapi-316127151No ratings yet
- Skittles ProjectDocument6 pagesSkittles Projectapi-366671561No ratings yet
- Difference Between Descriptive and Inferential StatisticsDocument2 pagesDifference Between Descriptive and Inferential StatisticsRegine GierzNo ratings yet
- Skittles Project Group Final WordDocument6 pagesSkittles Project Group Final Wordapi-316239273No ratings yet
- Skittlesgroup 1Document2 pagesSkittlesgroup 1api-242416392No ratings yet
- Croot ResumeDocument2 pagesCroot Resumeapi-276896975No ratings yet
- Signature Assignment Eportfolio ReflectionDocument2 pagesSignature Assignment Eportfolio Reflectionapi-276896975No ratings yet
- Croot Project3 Visual1Document13 pagesCroot Project3 Visual1api-276896975No ratings yet
- Croot Project3 CoverletterDocument1 pageCroot Project3 Coverletterapi-276896975No ratings yet
- Free or Equal Questions (1-10)Document4 pagesFree or Equal Questions (1-10)api-276896975No ratings yet
- Luray Ii National High SchoolDocument5 pagesLuray Ii National High SchoolKrizzie Jade CailingNo ratings yet
- If SCH CSH Provincial Teacher Resource ListDocument31 pagesIf SCH CSH Provincial Teacher Resource Listcarlosdgo1No ratings yet
- Mapeh DLL q2 Wk5Document9 pagesMapeh DLL q2 Wk5Nota BelzNo ratings yet
- Summary of TheoriesDocument24 pagesSummary of TheoriesalabanzasaltheaNo ratings yet
- Teachers Guide 1 PDFDocument25 pagesTeachers Guide 1 PDFSJK (C) CHUKAI TERENGGANUNo ratings yet
- NiftDocument7 pagesNiftAnkit Kashmiri GuptaNo ratings yet
- Assignment 4: Unit 6 - Week 4: Attainment of Outcomes (Module 1: NBA and OBE Framework)Document4 pagesAssignment 4: Unit 6 - Week 4: Attainment of Outcomes (Module 1: NBA and OBE Framework)Narendrasinh GohilNo ratings yet
- Special Ed HandoutDocument2 pagesSpecial Ed Handoutapi-420112600No ratings yet
- Pecb Iso 37001 Lead Implementer Exam Preparation GuideDocument15 pagesPecb Iso 37001 Lead Implementer Exam Preparation GuideSiti Zull100% (1)
- Lesson 3 CiDocument19 pagesLesson 3 Ciapi-252424167No ratings yet
- Basic Calc TGDocument322 pagesBasic Calc TGRyland Ace MabungaNo ratings yet
- Eloisa de Guzman Meas EvalDocument4 pagesEloisa de Guzman Meas EvalEloisa Deguzman50% (2)
- Lesson Plan 1Document3 pagesLesson Plan 1api-457603008No ratings yet
- A Review On Question Generation System From Punjabi TextDocument3 pagesA Review On Question Generation System From Punjabi TextInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Art Research PaperDocument7 pagesArt Research Paperapi-297625788No ratings yet
- Extended Responce Resource GuideDocument33 pagesExtended Responce Resource GuideMichael KeagNo ratings yet
- National Watercolor Society - Since 1920 SPRING 2016: President's MessageDocument12 pagesNational Watercolor Society - Since 1920 SPRING 2016: President's MessagenationalwatercolorsocietyNo ratings yet
- Weekly Reinforcement: The City SchoolDocument6 pagesWeekly Reinforcement: The City SchoolfafaNo ratings yet
- Reading Comprehension Exercise # 218Document2 pagesReading Comprehension Exercise # 218Nuria CabreraNo ratings yet
- English Israeli Army Project 1Document11 pagesEnglish Israeli Army Project 1api-290836768No ratings yet
- CAPE Pure Math Unit 1 (2012)Document25 pagesCAPE Pure Math Unit 1 (2012)Brodrick100% (2)
- CWH Cervical Smear WBV FormDocument2 pagesCWH Cervical Smear WBV FormYwagar YwagarNo ratings yet
- Professional Development For Primary Teachers in Science and Technology The Dutch VTB Pro Project in An International Perspective PDFDocument297 pagesProfessional Development For Primary Teachers in Science and Technology The Dutch VTB Pro Project in An International Perspective PDFEQo AttamiriNo ratings yet
- First Periodical Test in English 3 NewDocument4 pagesFirst Periodical Test in English 3 NewGinalyn Matildo AfableNo ratings yet
- IT 103 Programming IIDocument5 pagesIT 103 Programming IIMarlon Benson QuintoNo ratings yet












































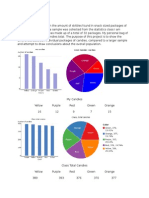





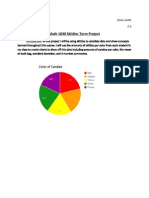












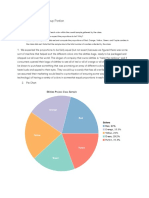































Download as docx, pdf, or txt
You might also like
- Adam, B. (2008) - of Timescapes Futurescapes and TimeprintsDocument9 pagesAdam, B. (2008) - of Timescapes Futurescapes and TimeprintsbrenderdanNo ratings yet
- 6 Historical Phase of SenDocument23 pages6 Historical Phase of SenRebecca OngNo ratings yet
- Stats ProjectDocument14 pagesStats Projectapi-302666758No ratings yet
- Skittles Project Part 1Document6 pagesSkittles Project Part 1api-457501806No ratings yet
- Skittles Project 1Document7 pagesSkittles Project 1api-299868669100% (2)
- Skittle Term ProjectDocument15 pagesSkittle Term Projectapi-260271892No ratings yet
- M&M ReportDocument5 pagesM&M ReportPamela L. Robinson100% (1)
- Visualize This: The FlowingData Guide to Design, Visualization, and StatisticsFrom EverandVisualize This: The FlowingData Guide to Design, Visualization, and StatisticsRating: 3.5 out of 5 stars3.5/5 (23)
- Mbti Workshop - 2 DayDocument2 pagesMbti Workshop - 2 DayManish JhuraniNo ratings yet
- Jean Piaget's TheoryDocument15 pagesJean Piaget's TheoryRosman Drahman100% (1)
- Semi-Detailed Lesson Plan in Arts 10Document5 pagesSemi-Detailed Lesson Plan in Arts 10joy89% (9)
- The Rainbow ReportDocument11 pagesThe Rainbow Reportapi-316991888No ratings yet
- Math 1040 Statistics Term Project: Blake FreemanDocument10 pagesMath 1040 Statistics Term Project: Blake Freemanapi-252919218No ratings yet
- StatsfinalprojectDocument7 pagesStatsfinalprojectapi-325102852No ratings yet
- Term Project - EportfolioDocument7 pagesTerm Project - Eportfolioapi-251981709No ratings yet
- Skittles ProjectDocument6 pagesSkittles Projectapi-319345408No ratings yet
- Skittles AssignmentDocument8 pagesSkittles Assignmentapi-291800396No ratings yet
- Final ProjectDocument6 pagesFinal Projectapi-283261340No ratings yet
- Final ProjectDocument9 pagesFinal Projectapi-262329757No ratings yet
- The Full Skittles ProjectDocument6 pagesThe Full Skittles Projectapi-340271527100% (1)
- Skittle Pareto ChartDocument7 pagesSkittle Pareto Chartapi-272391081No ratings yet
- Math 1040 Term ProjectDocument7 pagesMath 1040 Term Projectapi-340188424No ratings yet
- EportfolioDocument12 pagesEportfolioapi-251934892No ratings yet
- Skittles Project 5-02Document8 pagesSkittles Project 5-02api-354040698No ratings yet
- EportfolioDocument8 pagesEportfolioapi-242211470No ratings yet
- Skittles ProjectDocument9 pagesSkittles Projectapi-242873849No ratings yet
- The Skittles Project FinalDocument8 pagesThe Skittles Project Finalapi-316760667No ratings yet
- Skittles ProDocument9 pagesSkittles Proapi-241124972No ratings yet
- Term Project ReportDocument9 pagesTerm Project Reportapi-238585685No ratings yet
- Math 1040 Skittles Term ProjectDocument9 pagesMath 1040 Skittles Term Projectapi-319881085No ratings yet
- Skittles Project With ReflectionDocument7 pagesSkittles Project With Reflectionapi-234712126100% (1)
- TP 2 StatsDocument5 pagesTP 2 Statsapi-240850453No ratings yet
- Skittles Final ProjectDocument5 pagesSkittles Final Projectapi-251571777No ratings yet
- SkittlesdataclassprojectDocument8 pagesSkittlesdataclassprojectapi-399586872No ratings yet
- Final Math ProjectDocument7 pagesFinal Math Projectapi-316775963No ratings yet
- Math 1040 Skittles Term Project EportfolioDocument7 pagesMath 1040 Skittles Term Project Eportfolioapi-260817278No ratings yet
- Skittles Term Project 11 9 14Document5 pagesSkittles Term Project 11 9 14api-192489685No ratings yet
- Math 1040Document3 pagesMath 1040api-219553415No ratings yet
- Team Project Part 6 Final ReportDocument8 pagesTeam Project Part 6 Final Reportapi-316794103No ratings yet
- The Science of Collecting, Organizing, Summarizing, and Analyzing Information To Draw Conclusions or Answer QuestionsDocument7 pagesThe Science of Collecting, Organizing, Summarizing, and Analyzing Information To Draw Conclusions or Answer Questionsapi-438148756No ratings yet
- Group Project #1 - SkittlesDocument9 pagesGroup Project #1 - Skittlesapi-245266056No ratings yet
- Skittles Project Stats 1040Document8 pagesSkittles Project Stats 1040api-301336765No ratings yet
- Skittles Project FinalDocument5 pagesSkittles Project Finalapi-271348941No ratings yet
- Skittles Term ProjectDocument10 pagesSkittles Term Projectapi-273060240No ratings yet
- Math 1040 Final ProjectDocument3 pagesMath 1040 Final Projectapi-285380759No ratings yet
- Skittles 2 FinalDocument12 pagesSkittles 2 Finalapi-242194552No ratings yet
- Term Project Part 7Document8 pagesTerm Project Part 7api-291870758No ratings yet
- Skittles FinalDocument12 pagesSkittles Finalapi-241861434No ratings yet
- Statistics Term Project E-Portfolio ReflectionDocument8 pagesStatistics Term Project E-Portfolio Reflectionapi-258147701No ratings yet
- Math 1040Document5 pagesMath 1040api-534403229No ratings yet
- SkittlesDocument5 pagesSkittlesapi-249778667No ratings yet
- Term Project Part 5 Compile Term Project Reflection and Eportfolio Posting 1Document8 pagesTerm Project Part 5 Compile Term Project Reflection and Eportfolio Posting 1api-303044832No ratings yet
- Skittles ProjectDocument5 pagesSkittles Projectapi-271444168No ratings yet
- Stats StuffDocument7 pagesStats Stuffapi-242298926No ratings yet
- Skittles ProjectDocument9 pagesSkittles Projectapi-252747849No ratings yet
- Math ProfileDocument9 pagesMath Profileapi-454376679No ratings yet
- Numerical Calculations or Graphs or Tables. Inferential Statistics Makes Inferences and Predictions About A Population Based On A Sample of Data Taken From The Population in QuestionDocument2 pagesNumerical Calculations or Graphs or Tables. Inferential Statistics Makes Inferences and Predictions About A Population Based On A Sample of Data Taken From The Population in QuestionArjay CajesNo ratings yet
- Skittles Project 2Document5 pagesSkittles Project 2api-355504623No ratings yet
- Final SkittlesDocument6 pagesFinal Skittlesapi-272838320No ratings yet
- 1040 Term ProjectDocument8 pages1040 Term Projectapi-316127151No ratings yet
- Skittles ProjectDocument6 pagesSkittles Projectapi-366671561No ratings yet
- Difference Between Descriptive and Inferential StatisticsDocument2 pagesDifference Between Descriptive and Inferential StatisticsRegine GierzNo ratings yet
- Skittles Project Group Final WordDocument6 pagesSkittles Project Group Final Wordapi-316239273No ratings yet
- Skittlesgroup 1Document2 pagesSkittlesgroup 1api-242416392No ratings yet
- Croot ResumeDocument2 pagesCroot Resumeapi-276896975No ratings yet
- Signature Assignment Eportfolio ReflectionDocument2 pagesSignature Assignment Eportfolio Reflectionapi-276896975No ratings yet
- Croot Project3 Visual1Document13 pagesCroot Project3 Visual1api-276896975No ratings yet
- Croot Project3 CoverletterDocument1 pageCroot Project3 Coverletterapi-276896975No ratings yet
- Free or Equal Questions (1-10)Document4 pagesFree or Equal Questions (1-10)api-276896975No ratings yet
- Luray Ii National High SchoolDocument5 pagesLuray Ii National High SchoolKrizzie Jade CailingNo ratings yet
- If SCH CSH Provincial Teacher Resource ListDocument31 pagesIf SCH CSH Provincial Teacher Resource Listcarlosdgo1No ratings yet
- Mapeh DLL q2 Wk5Document9 pagesMapeh DLL q2 Wk5Nota BelzNo ratings yet
- Summary of TheoriesDocument24 pagesSummary of TheoriesalabanzasaltheaNo ratings yet
- Teachers Guide 1 PDFDocument25 pagesTeachers Guide 1 PDFSJK (C) CHUKAI TERENGGANUNo ratings yet
- NiftDocument7 pagesNiftAnkit Kashmiri GuptaNo ratings yet
- Assignment 4: Unit 6 - Week 4: Attainment of Outcomes (Module 1: NBA and OBE Framework)Document4 pagesAssignment 4: Unit 6 - Week 4: Attainment of Outcomes (Module 1: NBA and OBE Framework)Narendrasinh GohilNo ratings yet
- Special Ed HandoutDocument2 pagesSpecial Ed Handoutapi-420112600No ratings yet
- Pecb Iso 37001 Lead Implementer Exam Preparation GuideDocument15 pagesPecb Iso 37001 Lead Implementer Exam Preparation GuideSiti Zull100% (1)
- Lesson 3 CiDocument19 pagesLesson 3 Ciapi-252424167No ratings yet
- Basic Calc TGDocument322 pagesBasic Calc TGRyland Ace MabungaNo ratings yet
- Eloisa de Guzman Meas EvalDocument4 pagesEloisa de Guzman Meas EvalEloisa Deguzman50% (2)
- Lesson Plan 1Document3 pagesLesson Plan 1api-457603008No ratings yet
- A Review On Question Generation System From Punjabi TextDocument3 pagesA Review On Question Generation System From Punjabi TextInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Art Research PaperDocument7 pagesArt Research Paperapi-297625788No ratings yet
- Extended Responce Resource GuideDocument33 pagesExtended Responce Resource GuideMichael KeagNo ratings yet
- National Watercolor Society - Since 1920 SPRING 2016: President's MessageDocument12 pagesNational Watercolor Society - Since 1920 SPRING 2016: President's MessagenationalwatercolorsocietyNo ratings yet
- Weekly Reinforcement: The City SchoolDocument6 pagesWeekly Reinforcement: The City SchoolfafaNo ratings yet
- Reading Comprehension Exercise # 218Document2 pagesReading Comprehension Exercise # 218Nuria CabreraNo ratings yet
- English Israeli Army Project 1Document11 pagesEnglish Israeli Army Project 1api-290836768No ratings yet
- CAPE Pure Math Unit 1 (2012)Document25 pagesCAPE Pure Math Unit 1 (2012)Brodrick100% (2)
- CWH Cervical Smear WBV FormDocument2 pagesCWH Cervical Smear WBV FormYwagar YwagarNo ratings yet
- Professional Development For Primary Teachers in Science and Technology The Dutch VTB Pro Project in An International Perspective PDFDocument297 pagesProfessional Development For Primary Teachers in Science and Technology The Dutch VTB Pro Project in An International Perspective PDFEQo AttamiriNo ratings yet
- First Periodical Test in English 3 NewDocument4 pagesFirst Periodical Test in English 3 NewGinalyn Matildo AfableNo ratings yet
- IT 103 Programming IIDocument5 pagesIT 103 Programming IIMarlon Benson QuintoNo ratings yet