
Web Mining - Concepts and Research Directory
Web Mining - Concepts and Research Directory
You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5822)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1093)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (852)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (898)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (540)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (349)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Six Sigma Updated PDFDocument127 pagesSix Sigma Updated PDFprudhvi ch100% (3)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (822)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (403)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Lembar Kerja UD. Mudah HasilDocument41 pagesLembar Kerja UD. Mudah HasilRoni NNo ratings yet
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Interview NotesDocument134 pagesInterview NotesJerrico GomezNo ratings yet
- Edge Feb9Document24 pagesEdge Feb9bearteddy17193No ratings yet
- Network Marketing Business Techniques 1Document7 pagesNetwork Marketing Business Techniques 1usman saleemNo ratings yet
- Jaswant Kumar Sharma - Offer LetterDocument1 pageJaswant Kumar Sharma - Offer LetterABHINAV PATHAKNo ratings yet
- Meyer Sound Acheron Designer QuoteDocument2 pagesMeyer Sound Acheron Designer QuoteJasmine WilsonNo ratings yet
- TH THDocument9 pagesTH THP.MannaNo ratings yet
- Create A Seat Booking Form With Google Forms, Google Sheets and Google Apps Script - Yagisanatode - AppsScriptPulseDocument3 pagesCreate A Seat Booking Form With Google Forms, Google Sheets and Google Apps Script - Yagisanatode - AppsScriptPulsebrandy57279No ratings yet
- Auditing Quiz - Accepting The Engagement and Planning The AuditDocument11 pagesAuditing Quiz - Accepting The Engagement and Planning The AuditMarie Lichelle AureusNo ratings yet
- Sustainable Cocoa Production Program (SCPP) : Case StudyDocument19 pagesSustainable Cocoa Production Program (SCPP) : Case StudyfrendystpNo ratings yet
- Knott V Cottee (1852) 51 ER 705Document3 pagesKnott V Cottee (1852) 51 ER 705schoolemailsdumpNo ratings yet
- Materials Management ManualDocument346 pagesMaterials Management ManualAddis NurhussienNo ratings yet
- Project 1Document20 pagesProject 1pandurang parkarNo ratings yet
- Nguyen Thi Thuy hs150356 Ib1502 Individual Assignment mgt103Document9 pagesNguyen Thi Thuy hs150356 Ib1502 Individual Assignment mgt103Do Quang Anh (K16HL)No ratings yet
- Mimf MDG ClaimDocument2 pagesMimf MDG ClaimDeanna HazierraNo ratings yet
- Ec 413 - Programs and Policies On Enterprise Development: Business Administration and EntrepreneurshipDocument12 pagesEc 413 - Programs and Policies On Enterprise Development: Business Administration and EntrepreneurshipDaienne Abegail EspinosaNo ratings yet
- Chapter 3Document38 pagesChapter 3shera samyNo ratings yet
- Final Chapter 1 5 - MergedDocument77 pagesFinal Chapter 1 5 - MergedMolleno MichelleNo ratings yet
- Strategy, Value Innovation, Knowledge Economy ReviewDocument3 pagesStrategy, Value Innovation, Knowledge Economy ReviewDiana Leonita FajriNo ratings yet
- Akhil ResumeDocument4 pagesAkhil ResumeAkhil SharmaNo ratings yet
- Faktor-Faktor Yang Mempengaruhi Financial Distress (Studi Pada Perusahaan Manufaktur Di BEI)Document17 pagesFaktor-Faktor Yang Mempengaruhi Financial Distress (Studi Pada Perusahaan Manufaktur Di BEI)Vero MhjNo ratings yet
- 200+ Public VC FirmsDocument43 pages200+ Public VC FirmsrowieNo ratings yet
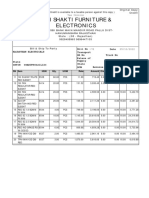
- Shri Shakti Furniture & Electronics: Credit OrginalDocument1 pageShri Shakti Furniture & Electronics: Credit OrginalRahul BansalNo ratings yet
- Checklist of Requirements: Resource-Based Industries Service (Rbis)Document1 pageChecklist of Requirements: Resource-Based Industries Service (Rbis)MeowthemathicianNo ratings yet
- KL Kel 8 - P5-1 P5-4 P5-8 - Eka NisrinaDocument5 pagesKL Kel 8 - P5-1 P5-4 P5-8 - Eka NisrinaicadeliciafebNo ratings yet
- DLL in Commercial Cooking 7-Week 5Document5 pagesDLL in Commercial Cooking 7-Week 5JeeNha BonjoureNo ratings yet
- Topic 3.1Document16 pagesTopic 3.1SITINo ratings yet
- Kerala: A Case Study of Classical Democratic DecentralisationDocument84 pagesKerala: A Case Study of Classical Democratic DecentralisationK RajasekharanNo ratings yet
- Bank Statement - 2024Document14 pagesBank Statement - 2024mauryaavantika39No ratings yet






































































Download as pdf or txt
You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5822)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1093)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (852)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (898)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (540)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (349)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Six Sigma Updated PDFDocument127 pagesSix Sigma Updated PDFprudhvi ch100% (3)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (822)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (403)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Lembar Kerja UD. Mudah HasilDocument41 pagesLembar Kerja UD. Mudah HasilRoni NNo ratings yet
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Interview NotesDocument134 pagesInterview NotesJerrico GomezNo ratings yet
- Edge Feb9Document24 pagesEdge Feb9bearteddy17193No ratings yet
- Network Marketing Business Techniques 1Document7 pagesNetwork Marketing Business Techniques 1usman saleemNo ratings yet
- Jaswant Kumar Sharma - Offer LetterDocument1 pageJaswant Kumar Sharma - Offer LetterABHINAV PATHAKNo ratings yet
- Meyer Sound Acheron Designer QuoteDocument2 pagesMeyer Sound Acheron Designer QuoteJasmine WilsonNo ratings yet
- TH THDocument9 pagesTH THP.MannaNo ratings yet
- Create A Seat Booking Form With Google Forms, Google Sheets and Google Apps Script - Yagisanatode - AppsScriptPulseDocument3 pagesCreate A Seat Booking Form With Google Forms, Google Sheets and Google Apps Script - Yagisanatode - AppsScriptPulsebrandy57279No ratings yet
- Auditing Quiz - Accepting The Engagement and Planning The AuditDocument11 pagesAuditing Quiz - Accepting The Engagement and Planning The AuditMarie Lichelle AureusNo ratings yet
- Sustainable Cocoa Production Program (SCPP) : Case StudyDocument19 pagesSustainable Cocoa Production Program (SCPP) : Case StudyfrendystpNo ratings yet
- Knott V Cottee (1852) 51 ER 705Document3 pagesKnott V Cottee (1852) 51 ER 705schoolemailsdumpNo ratings yet
- Materials Management ManualDocument346 pagesMaterials Management ManualAddis NurhussienNo ratings yet
- Project 1Document20 pagesProject 1pandurang parkarNo ratings yet
- Nguyen Thi Thuy hs150356 Ib1502 Individual Assignment mgt103Document9 pagesNguyen Thi Thuy hs150356 Ib1502 Individual Assignment mgt103Do Quang Anh (K16HL)No ratings yet
- Mimf MDG ClaimDocument2 pagesMimf MDG ClaimDeanna HazierraNo ratings yet
- Ec 413 - Programs and Policies On Enterprise Development: Business Administration and EntrepreneurshipDocument12 pagesEc 413 - Programs and Policies On Enterprise Development: Business Administration and EntrepreneurshipDaienne Abegail EspinosaNo ratings yet
- Chapter 3Document38 pagesChapter 3shera samyNo ratings yet
- Final Chapter 1 5 - MergedDocument77 pagesFinal Chapter 1 5 - MergedMolleno MichelleNo ratings yet
- Strategy, Value Innovation, Knowledge Economy ReviewDocument3 pagesStrategy, Value Innovation, Knowledge Economy ReviewDiana Leonita FajriNo ratings yet
- Akhil ResumeDocument4 pagesAkhil ResumeAkhil SharmaNo ratings yet
- Faktor-Faktor Yang Mempengaruhi Financial Distress (Studi Pada Perusahaan Manufaktur Di BEI)Document17 pagesFaktor-Faktor Yang Mempengaruhi Financial Distress (Studi Pada Perusahaan Manufaktur Di BEI)Vero MhjNo ratings yet
- 200+ Public VC FirmsDocument43 pages200+ Public VC FirmsrowieNo ratings yet
- Shri Shakti Furniture & Electronics: Credit OrginalDocument1 pageShri Shakti Furniture & Electronics: Credit OrginalRahul BansalNo ratings yet
- Checklist of Requirements: Resource-Based Industries Service (Rbis)Document1 pageChecklist of Requirements: Resource-Based Industries Service (Rbis)MeowthemathicianNo ratings yet
- KL Kel 8 - P5-1 P5-4 P5-8 - Eka NisrinaDocument5 pagesKL Kel 8 - P5-1 P5-4 P5-8 - Eka NisrinaicadeliciafebNo ratings yet
- DLL in Commercial Cooking 7-Week 5Document5 pagesDLL in Commercial Cooking 7-Week 5JeeNha BonjoureNo ratings yet
- Topic 3.1Document16 pagesTopic 3.1SITINo ratings yet
- Kerala: A Case Study of Classical Democratic DecentralisationDocument84 pagesKerala: A Case Study of Classical Democratic DecentralisationK RajasekharanNo ratings yet
- Bank Statement - 2024Document14 pagesBank Statement - 2024mauryaavantika39No ratings yet