
AOR Pismeni Skripta
AOR Pismeni Skripta
You might also like
- Pengujian MesinDocument23 pagesPengujian MesinDaleArchgod100% (1)
- Parameter Farmakokinetik Secara Oral Dan IV - IfahDocument10 pagesParameter Farmakokinetik Secara Oral Dan IV - IfahMusdhalifah FayVfhyNo ratings yet
- Amali 1Document13 pagesAmali 1Rafiy AsNo ratings yet
- Unit 5 (KAEDAH AGIHAN MOMEN (KERANGKA) )Document54 pagesUnit 5 (KAEDAH AGIHAN MOMEN (KERANGKA) )Zara Nabilah100% (1)
- Guidelines For Schematic DesignDocument14 pagesGuidelines For Schematic DesignAli AimranNo ratings yet
- ANOVADocument79 pagesANOVAael6166No ratings yet
- Sukatan MembulatDocument19 pagesSukatan MembulatAmil SyedNo ratings yet
- RumusDocument49 pagesRumussusanto0% (1)
- Teori Ekonomi Mikro IIDocument40 pagesTeori Ekonomi Mikro IICitta AnindyaNo ratings yet
- Solusi Ujian Akhir DIUPLOADDocument9 pagesSolusi Ujian Akhir DIUPLOADScribdTranslationsNo ratings yet
- Laporan Tetap PC10-3Document21 pagesLaporan Tetap PC10-3Ajim100% (1)
- Feq Dec 40053 Embedded System ApplicationDocument106 pagesFeq Dec 40053 Embedded System ApplicationWong Guan ChenggNo ratings yet
- Ujian 1 Fizikf 4Document6 pagesUjian 1 Fizikf 4eriire79No ratings yet
- Nota 5Document15 pagesNota 5Nurul ShakirahNo ratings yet
- Jawapan Bab 7 SemarakDocument13 pagesJawapan Bab 7 SemarakNIK AIDA MASTURA BINTI NIK ABDUL MAJID100% (1)
- Kadar Nadi MaksimumDocument2 pagesKadar Nadi MaksimumJing Min ChuaNo ratings yet
- PerhitunganDocument5 pagesPerhitunganRifqi ZuhdiNo ratings yet
- AVR Merupakan Seri Mikrokontroler CMOS 8Document21 pagesAVR Merupakan Seri Mikrokontroler CMOS 8Banyubiru PutraNo ratings yet
- Laporan Perkal He (Fix)Document14 pagesLaporan Perkal He (Fix)Mohammad Nurifki FilinoNo ratings yet
- Topik 12 Kecerunan Dan Luas Di Bawah GrafDocument19 pagesTopik 12 Kecerunan Dan Luas Di Bawah GrafIrinePallNo ratings yet
- Model Absorbsi KinetikDocument21 pagesModel Absorbsi KinetikMOCHILNo ratings yet
- Nota Kuliah Bab 3 Dan 4Document31 pagesNota Kuliah Bab 3 Dan 4Nur Fatiha Ahmad ZaidiNo ratings yet
- Faktor Kuasa (Pengiraan)Document4 pagesFaktor Kuasa (Pengiraan)aimiza100% (2)
- Penggunaan OskDocument10 pagesPenggunaan OskRoszana SelamatNo ratings yet
- Sistem KoinsidensiDocument10 pagesSistem KoinsidensiMustofa BrohimNo ratings yet
- Nama: Terry Ayu Nirmalasari NIM: 048147748 Matkul: Matematika EkonomiDocument3 pagesNama: Terry Ayu Nirmalasari NIM: 048147748 Matkul: Matematika EkonomiSiti Nur Janah (Siti)No ratings yet
- Nota Tingakatan 4 FizikDocument50 pagesNota Tingakatan 4 Fizikmuhdsabri51No ratings yet
- Bab Xii Pencerminan GeserDocument13 pagesBab Xii Pencerminan GeserUlul AfidahNo ratings yet
- Laporan TahananDocument38 pagesLaporan TahananAhmad Kahar RitongaNo ratings yet
- 3,4,5,6 - Fenomena Perpindahan Dalam Pengering1Document85 pages3,4,5,6 - Fenomena Perpindahan Dalam Pengering1Anugrah ArevaNo ratings yet
- Dec40053 Embedded Systems Applications Sesi Jun 2019Document10 pagesDec40053 Embedded Systems Applications Sesi Jun 2019SITI NUR SHAZANA BINTI RAHMAD MoeNo ratings yet
- Bengkel Teknik Kertas 3 BiologiDocument60 pagesBengkel Teknik Kertas 3 BiologiMuhammad Afifuddin ZulkifliNo ratings yet
- Graf GerakanDocument9 pagesGraf GerakanParam VaramanNo ratings yet
- Dec40053 Embedded System ApplicationsDocument6 pagesDec40053 Embedded System ApplicationsLakshana 24No ratings yet
- Rumus Lab Internal Combution SPDDocument4 pagesRumus Lab Internal Combution SPDdaswanNo ratings yet
- Fungsi KeuntunganDocument16 pagesFungsi KeuntunganPS MarNo ratings yet
- Pengukuran Triangulasi1Document27 pagesPengukuran Triangulasi1nik_razaliNo ratings yet
- DavidDocument2 pagesDavidkeny dcNo ratings yet
- Contoh Soal CdmaDocument12 pagesContoh Soal CdmaRionandoJefryNo ratings yet
- k5 KP Interpret Counter and Register (3-4)Document49 pagesk5 KP Interpret Counter and Register (3-4)Muhammad TaufikNo ratings yet
- Kumpulan RumusDocument3 pagesKumpulan RumusA454 874 Afif Rakha MurtadhaNo ratings yet
- CS - Group DDocument17 pagesCS - Group DSquib WardNo ratings yet
- Bab 3Document54 pagesBab 3Hanis QistinaNo ratings yet
- Laporan Akhir Praktikum Fenomena Dasar MesinDocument29 pagesLaporan Akhir Praktikum Fenomena Dasar MesinAfanNo ratings yet
- KalkulatorDocument17 pagesKalkulatorSaxarine von Karlbernikoff100% (1)
- Jadual 1Document8 pagesJadual 1Rashid SaidNo ratings yet
- Laporan CO AdjusterDocument6 pagesLaporan CO Adjustercarolus ryanNo ratings yet
- Bab 3.4Document6 pagesBab 3.4Joseph LeeNo ratings yet
- Ubahan SubjektifDocument5 pagesUbahan Subjektifshera rashidNo ratings yet
- Penerimaan MarjinalDocument10 pagesPenerimaan MarjinalMaya Dina Jessica100% (2)
- Ulam #8 (Kecerunan & Luas Bawah GrafDocument7 pagesUlam #8 (Kecerunan & Luas Bawah GrafPuvaneswary RanggasamyNo ratings yet
- Kecerunan Dan Luas Dibawah GrafDocument7 pagesKecerunan Dan Luas Dibawah GrafSARIPAH BINTI AHMAD0% (1)
- PDF Analisis Struktur Statis Tak Tentuk Dengan Metode Consistent Deformation CompressDocument10 pagesPDF Analisis Struktur Statis Tak Tentuk Dengan Metode Consistent Deformation CompressWullan AgustiaNo ratings yet
- Perhitungan Dan Perancangan Power Supply DC 12 VDocument8 pagesPerhitungan Dan Perancangan Power Supply DC 12 VLuvi NMasfufaNo ratings yet
































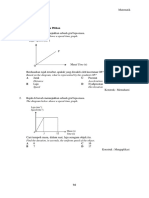












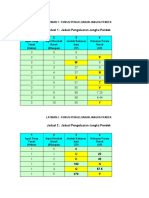








Download as pdf or txt
You might also like
- Pengujian MesinDocument23 pagesPengujian MesinDaleArchgod100% (1)
- Parameter Farmakokinetik Secara Oral Dan IV - IfahDocument10 pagesParameter Farmakokinetik Secara Oral Dan IV - IfahMusdhalifah FayVfhyNo ratings yet
- Amali 1Document13 pagesAmali 1Rafiy AsNo ratings yet
- Unit 5 (KAEDAH AGIHAN MOMEN (KERANGKA) )Document54 pagesUnit 5 (KAEDAH AGIHAN MOMEN (KERANGKA) )Zara Nabilah100% (1)
- Guidelines For Schematic DesignDocument14 pagesGuidelines For Schematic DesignAli AimranNo ratings yet
- ANOVADocument79 pagesANOVAael6166No ratings yet
- Sukatan MembulatDocument19 pagesSukatan MembulatAmil SyedNo ratings yet
- RumusDocument49 pagesRumussusanto0% (1)
- Teori Ekonomi Mikro IIDocument40 pagesTeori Ekonomi Mikro IICitta AnindyaNo ratings yet
- Solusi Ujian Akhir DIUPLOADDocument9 pagesSolusi Ujian Akhir DIUPLOADScribdTranslationsNo ratings yet
- Laporan Tetap PC10-3Document21 pagesLaporan Tetap PC10-3Ajim100% (1)
- Feq Dec 40053 Embedded System ApplicationDocument106 pagesFeq Dec 40053 Embedded System ApplicationWong Guan ChenggNo ratings yet
- Ujian 1 Fizikf 4Document6 pagesUjian 1 Fizikf 4eriire79No ratings yet
- Nota 5Document15 pagesNota 5Nurul ShakirahNo ratings yet
- Jawapan Bab 7 SemarakDocument13 pagesJawapan Bab 7 SemarakNIK AIDA MASTURA BINTI NIK ABDUL MAJID100% (1)
- Kadar Nadi MaksimumDocument2 pagesKadar Nadi MaksimumJing Min ChuaNo ratings yet
- PerhitunganDocument5 pagesPerhitunganRifqi ZuhdiNo ratings yet
- AVR Merupakan Seri Mikrokontroler CMOS 8Document21 pagesAVR Merupakan Seri Mikrokontroler CMOS 8Banyubiru PutraNo ratings yet
- Laporan Perkal He (Fix)Document14 pagesLaporan Perkal He (Fix)Mohammad Nurifki FilinoNo ratings yet
- Topik 12 Kecerunan Dan Luas Di Bawah GrafDocument19 pagesTopik 12 Kecerunan Dan Luas Di Bawah GrafIrinePallNo ratings yet
- Model Absorbsi KinetikDocument21 pagesModel Absorbsi KinetikMOCHILNo ratings yet
- Nota Kuliah Bab 3 Dan 4Document31 pagesNota Kuliah Bab 3 Dan 4Nur Fatiha Ahmad ZaidiNo ratings yet
- Faktor Kuasa (Pengiraan)Document4 pagesFaktor Kuasa (Pengiraan)aimiza100% (2)
- Penggunaan OskDocument10 pagesPenggunaan OskRoszana SelamatNo ratings yet
- Sistem KoinsidensiDocument10 pagesSistem KoinsidensiMustofa BrohimNo ratings yet
- Nama: Terry Ayu Nirmalasari NIM: 048147748 Matkul: Matematika EkonomiDocument3 pagesNama: Terry Ayu Nirmalasari NIM: 048147748 Matkul: Matematika EkonomiSiti Nur Janah (Siti)No ratings yet
- Nota Tingakatan 4 FizikDocument50 pagesNota Tingakatan 4 Fizikmuhdsabri51No ratings yet
- Bab Xii Pencerminan GeserDocument13 pagesBab Xii Pencerminan GeserUlul AfidahNo ratings yet
- Laporan TahananDocument38 pagesLaporan TahananAhmad Kahar RitongaNo ratings yet
- 3,4,5,6 - Fenomena Perpindahan Dalam Pengering1Document85 pages3,4,5,6 - Fenomena Perpindahan Dalam Pengering1Anugrah ArevaNo ratings yet
- Dec40053 Embedded Systems Applications Sesi Jun 2019Document10 pagesDec40053 Embedded Systems Applications Sesi Jun 2019SITI NUR SHAZANA BINTI RAHMAD MoeNo ratings yet
- Bengkel Teknik Kertas 3 BiologiDocument60 pagesBengkel Teknik Kertas 3 BiologiMuhammad Afifuddin ZulkifliNo ratings yet
- Graf GerakanDocument9 pagesGraf GerakanParam VaramanNo ratings yet
- Dec40053 Embedded System ApplicationsDocument6 pagesDec40053 Embedded System ApplicationsLakshana 24No ratings yet
- Rumus Lab Internal Combution SPDDocument4 pagesRumus Lab Internal Combution SPDdaswanNo ratings yet
- Fungsi KeuntunganDocument16 pagesFungsi KeuntunganPS MarNo ratings yet
- Pengukuran Triangulasi1Document27 pagesPengukuran Triangulasi1nik_razaliNo ratings yet
- DavidDocument2 pagesDavidkeny dcNo ratings yet
- Contoh Soal CdmaDocument12 pagesContoh Soal CdmaRionandoJefryNo ratings yet
- k5 KP Interpret Counter and Register (3-4)Document49 pagesk5 KP Interpret Counter and Register (3-4)Muhammad TaufikNo ratings yet
- Kumpulan RumusDocument3 pagesKumpulan RumusA454 874 Afif Rakha MurtadhaNo ratings yet
- CS - Group DDocument17 pagesCS - Group DSquib WardNo ratings yet
- Bab 3Document54 pagesBab 3Hanis QistinaNo ratings yet
- Laporan Akhir Praktikum Fenomena Dasar MesinDocument29 pagesLaporan Akhir Praktikum Fenomena Dasar MesinAfanNo ratings yet
- KalkulatorDocument17 pagesKalkulatorSaxarine von Karlbernikoff100% (1)
- Jadual 1Document8 pagesJadual 1Rashid SaidNo ratings yet
- Laporan CO AdjusterDocument6 pagesLaporan CO Adjustercarolus ryanNo ratings yet
- Bab 3.4Document6 pagesBab 3.4Joseph LeeNo ratings yet
- Ubahan SubjektifDocument5 pagesUbahan Subjektifshera rashidNo ratings yet
- Penerimaan MarjinalDocument10 pagesPenerimaan MarjinalMaya Dina Jessica100% (2)
- Ulam #8 (Kecerunan & Luas Bawah GrafDocument7 pagesUlam #8 (Kecerunan & Luas Bawah GrafPuvaneswary RanggasamyNo ratings yet
- Kecerunan Dan Luas Dibawah GrafDocument7 pagesKecerunan Dan Luas Dibawah GrafSARIPAH BINTI AHMAD0% (1)
- PDF Analisis Struktur Statis Tak Tentuk Dengan Metode Consistent Deformation CompressDocument10 pagesPDF Analisis Struktur Statis Tak Tentuk Dengan Metode Consistent Deformation CompressWullan AgustiaNo ratings yet
- Perhitungan Dan Perancangan Power Supply DC 12 VDocument8 pagesPerhitungan Dan Perancangan Power Supply DC 12 VLuvi NMasfufaNo ratings yet