Download as pdf or txt
You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5825)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1093)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (852)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (903)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (541)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (349)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (823)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (403)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- US 6599130 Claim Chart (Public)Document4 pagesUS 6599130 Claim Chart (Public)Anonymous qyExl9dUQuNo ratings yet
- Mtcna KeyDocument38 pagesMtcna KeyWelly Andri100% (1)
- Silencing A HP DL380 Gen8 - Homelab PDFDocument7 pagesSilencing A HP DL380 Gen8 - Homelab PDFAlexandru Octavian GrosuNo ratings yet
- Lightning Network SlideDocument54 pagesLightning Network SlideEdukasi BitcoinNo ratings yet
- MT6737M Android ScatterDocument8 pagesMT6737M Android Scatterandroid makeer0% (1)
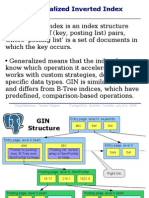
- Generalized Inverted Index An Inverted Index Is An IndexDocument14 pagesGeneralized Inverted Index An Inverted Index Is An IndexNikolay Samokhvalov100% (1)
- Returned Results Could Slightly Differ FromDocument3 pagesReturned Results Could Slightly Differ FromNikolay SamokhvalovNo ratings yet
- Gavin M. Roy: myYearBook - Com Architecture (Highload++, Moscow, Russia, October 2008)Document30 pagesGavin M. Roy: myYearBook - Com Architecture (Highload++, Moscow, Russia, October 2008)Nikolay Samokhvalov100% (1)
- Full-Text Search in PostgreSQLDocument77 pagesFull-Text Search in PostgreSQLNikolay Samokhvalov100% (20)
- PostgreSQL Performance TuningDocument63 pagesPostgreSQL Performance TuningNikolay Samokhvalov100% (9)
- Video Radar Tps 78Document14 pagesVideo Radar Tps 78Nikolay SamokhvalovNo ratings yet
- XML Support in PostgreSQLDocument6 pagesXML Support in PostgreSQLNikolay Samokhvalov100% (2)
- Using PostgreSQL in Web 2.0 ApplicationsDocument21 pagesUsing PostgreSQL in Web 2.0 ApplicationsNikolay Samokhvalov100% (8)
- Amazon Web Services (Aws)Document20 pagesAmazon Web Services (Aws)M ShaanNo ratings yet
- Enterprise SAP GRC Compliance and Security TrainingDocument128 pagesEnterprise SAP GRC Compliance and Security TrainingKamesh Vellanki100% (1)
- Software Engineering SyllabusDocument1 pageSoftware Engineering SyllabussunithaseaNo ratings yet
- 1.4.business Analysis Definition and Context PDFDocument15 pages1.4.business Analysis Definition and Context PDFsuman bhandariNo ratings yet
- C10 Remote Control Via Apple Ipad - enDocument15 pagesC10 Remote Control Via Apple Ipad - enVolodymyr TarnavskyyNo ratings yet
- Internet Security: Multiple Choice Question & AnswersDocument34 pagesInternet Security: Multiple Choice Question & AnswersEkta YadavNo ratings yet
- BITS Pilani: Distributed Computing Global State & Snapshot Recording AlgorithmsDocument53 pagesBITS Pilani: Distributed Computing Global State & Snapshot Recording AlgorithmsNithinNo ratings yet
- ELDO Software - Full Stack Software EngineerDocument2 pagesELDO Software - Full Stack Software EngineerMeshackMukakaNo ratings yet
- Enhanced Db-Scan AlgorithmDocument5 pagesEnhanced Db-Scan AlgorithmseventhsensegroupNo ratings yet
- CRC PDFDocument45 pagesCRC PDFMick SousaNo ratings yet
- Cisco Cobras For Unity Connection Unrestricted 0Document6 pagesCisco Cobras For Unity Connection Unrestricted 0Arun ParanjothiNo ratings yet
- Permiso SDocument69 pagesPermiso SantonyNo ratings yet
- MELFA - CatalogDocument50 pagesMELFA - Catalogjesus torgarNo ratings yet
- Proper Arrival Times: Calica, Jannah Mae B. 11/14/16 Bsee V-Eb1 Web Exercises Activity 7Document9 pagesProper Arrival Times: Calica, Jannah Mae B. 11/14/16 Bsee V-Eb1 Web Exercises Activity 7Lorenz BanadaNo ratings yet
- Mcafee Web Gateway 9.2.X Release NotesDocument28 pagesMcafee Web Gateway 9.2.X Release NotesshubhamNo ratings yet
- Activiti 5.9 User GuideDocument211 pagesActiviti 5.9 User GuideMaya Irawati SalehNo ratings yet
- jn0 104Document10 pagesjn0 104OSAMAH ABU BAKERNo ratings yet
- Adjunto - Cano Ruiz - Carlos AlbertoDocument2 pagesAdjunto - Cano Ruiz - Carlos AlbertoJ Alfredo RgNo ratings yet
- Basic Mobile Phones Hardware Repair Troubleshooting Techniques TutorialDocument7 pagesBasic Mobile Phones Hardware Repair Troubleshooting Techniques TutorialHaftamuNo ratings yet
- 1.0 Route Mapping Syllabus PMC RM-110Document4 pages1.0 Route Mapping Syllabus PMC RM-110Αλβέρτος ΟρτίζNo ratings yet
- APPENDIX A - Introduction To MATLAB PDFDocument13 pagesAPPENDIX A - Introduction To MATLAB PDFkara_25No ratings yet
- HTTP://WWW - Worldcolleges.info/ Anna University Chennai:: Chennai 600 025 Curriculum 2004 B.E.Document89 pagesHTTP://WWW - Worldcolleges.info/ Anna University Chennai:: Chennai 600 025 Curriculum 2004 B.E.abhynayaNo ratings yet
- Dell Latitude 14 Rugged Extreme Spec HeetDocument2 pagesDell Latitude 14 Rugged Extreme Spec HeetyoniNo ratings yet
- SQL Having ClauseDocument6 pagesSQL Having ClauseGood ManNo ratings yet
- 1.1-2 Basic Terms, Concepts, Functions and Characteristics of PC Hardware ComponentsDocument8 pages1.1-2 Basic Terms, Concepts, Functions and Characteristics of PC Hardware ComponentsRJ Villamer100% (1)