Download as pdf or txt
You might also like
- Operating System 2 Marks and 16 Marks - AnswersDocument45 pagesOperating System 2 Marks and 16 Marks - AnswersDiana Arun75% (4)
- Kernel Architecture: UNIX Kernel: P.C.P Bhatt OS/M14/V1/2004 1Document27 pagesKernel Architecture: UNIX Kernel: P.C.P Bhatt OS/M14/V1/2004 1shreeyanshsinghNo ratings yet
- General Overview of The System: Why UNIX Became So PopularDocument5 pagesGeneral Overview of The System: Why UNIX Became So PopulargowthamNo ratings yet
- Unix Process ManagementDocument9 pagesUnix Process ManagementJim HeffernanNo ratings yet
- Assignment No1Document6 pagesAssignment No1hajimastanbaapNo ratings yet
- Session - 1 PDFDocument14 pagesSession - 1 PDFSai susheel gupta sanagapalliNo ratings yet
- IL-Module 4Document12 pagesIL-Module 4Kanak RTNo ratings yet
- Assingnment No.1: Name: Harsh Kumar ENROLLMENT: EN19CS301131 Batch: C1Document12 pagesAssingnment No.1: Name: Harsh Kumar ENROLLMENT: EN19CS301131 Batch: C1Harsh KumarNo ratings yet
- Unit-2 Operating System StructureDocument8 pagesUnit-2 Operating System StructurePrajwal KandelNo ratings yet
- Operating SystemDocument41 pagesOperating SystemDaisy KhojaNo ratings yet
- NSK OS I 13 Solution 1Document7 pagesNSK OS I 13 Solution 1kotreshisnNo ratings yet
- Lecture (Chapter 2)Document24 pagesLecture (Chapter 2)ekiholoNo ratings yet
- Lecture (Chapter 2)Document24 pagesLecture (Chapter 2)ekiholoNo ratings yet
- Assignment No1Document9 pagesAssignment No1Leenal BuraNo ratings yet
- Introduction To UNIX Signals and System CallsDocument8 pagesIntroduction To UNIX Signals and System CallsskskNo ratings yet
- Ca2Document8 pagesCa2ChandraNo ratings yet
- Unix Case StudyDocument24 pagesUnix Case StudyJaikumar GuwalaniNo ratings yet
- Kernal DevelopementDocument20 pagesKernal DevelopementSarath P Subramaniam100% (1)
- Unix Viva QuestionsDocument20 pagesUnix Viva QuestionsRohit VijayvargiNo ratings yet
- Resources AllocationDocument10 pagesResources AllocationTedla MelekotNo ratings yet
- Introduction of O. S KernelDocument3 pagesIntroduction of O. S KernelKadiri precious EghosaNo ratings yet
- Presentation 9Document9 pagesPresentation 9Haadi KhanNo ratings yet
- ConfidenceDocument10 pagesConfidenceBraimah AishatNo ratings yet
- Suyash Os NotesDocument13 pagesSuyash Os Notesakashcreation0199No ratings yet
- 1 Introduction To Operating System 10 Jul 2019material I 10 Jul 2019 IntroductionDocument23 pages1 Introduction To Operating System 10 Jul 2019material I 10 Jul 2019 IntroductionAhmed Shmels MuheNo ratings yet
- OS TT SolvedDocument13 pagesOS TT Solvedfofini3433No ratings yet
- Os Practical FileDocument34 pagesOs Practical FileSonam SainiNo ratings yet
- Operating Systems Lecture Notes: Matthew DaileyDocument31 pagesOperating Systems Lecture Notes: Matthew DaileyMegha HegdeNo ratings yet
- Aim: Theory: What Is Kernel?Document6 pagesAim: Theory: What Is Kernel?Akash ZambreNo ratings yet
- Good Material OSDocument103 pagesGood Material OSKarthik SekharNo ratings yet
- Chapter 1Document21 pagesChapter 1Shefali DsouzaNo ratings yet
- Present Intro Notes-Operating Systems - CS222Document11 pagesPresent Intro Notes-Operating Systems - CS222ShahidH.RathoreNo ratings yet
- Basic Features of Unix Operating SystemDocument50 pagesBasic Features of Unix Operating SystemKamalakar Sreevatasala67% (3)
- 2020.04.30 - Design of UNIX - LectureDocument29 pages2020.04.30 - Design of UNIX - LectureKristijan GrozdanoskiNo ratings yet
- Chapter 01: Introduction CSS430 Systems ProgrammingDocument27 pagesChapter 01: Introduction CSS430 Systems ProgrammingAlan NguyenNo ratings yet
- Welcome: Eds Sun Level - 1 TrainingDocument399 pagesWelcome: Eds Sun Level - 1 Trainingchandrashekar_ganesanNo ratings yet
- Chapter 2 Processes - 230210 - 084007Document30 pagesChapter 2 Processes - 230210 - 084007AC AtelierNo ratings yet
- Reenternal KernelsDocument3 pagesReenternal KernelsNooriya ShaikhNo ratings yet
- Operating SystemDocument103 pagesOperating SystemYUVRAJ WAGH100% (1)
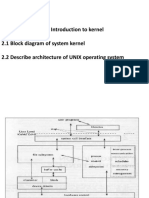
- Introduction To Kernel 2.1 Block Diagram of System Kernel 2.2 Describe Architecture of UNIX Operating SystemDocument33 pagesIntroduction To Kernel 2.1 Block Diagram of System Kernel 2.2 Describe Architecture of UNIX Operating SystemShefali DsouzaNo ratings yet
- Unit I: 1.1 OS StructuresDocument22 pagesUnit I: 1.1 OS Structuresshashi176597No ratings yet
- Module 20: More On LINUX: Linux Kernel Architecture The Big PictureDocument39 pagesModule 20: More On LINUX: Linux Kernel Architecture The Big PictureAnkit SanghviNo ratings yet
- Sun TrainingDocument399 pagesSun TrainingArun Praveen100% (2)
- Linux KernelDocument9 pagesLinux KernelNavneetMishraNo ratings yet
- Kernel (Computing) : o o o o o o o o o oDocument13 pagesKernel (Computing) : o o o o o o o o o ohritik_princeNo ratings yet
- Lecture 4, OSDocument12 pagesLecture 4, OSMaria Akter LuthfaNo ratings yet
- Os Files SDocument63 pagesOs Files Smohitpar128No ratings yet
- OS CrashcourseDocument151 pagesOS CrashcourseRishabh SinghNo ratings yet
- The Kernel Boot Process: Booting and The KernelDocument9 pagesThe Kernel Boot Process: Booting and The KernelpavlikNo ratings yet
- Unit 1Document14 pagesUnit 1Devika KachhawahaNo ratings yet
- Lecture Notes On Operating SystemDocument10 pagesLecture Notes On Operating SystemSumit SinghNo ratings yet
- Kernel (Computing) : From Wikipedia, The Free EncyclopediaDocument19 pagesKernel (Computing) : From Wikipedia, The Free EncyclopediaYogesh GandhiNo ratings yet
- CA Classes-11-15Document5 pagesCA Classes-11-15SrinivasaRaoNo ratings yet
- Chapter 2 PDFDocument83 pagesChapter 2 PDFMebratu AsratNo ratings yet
- Operating System AssignmentDocument45 pagesOperating System AssignmentvikramNo ratings yet
- Context Switch DefinitionDocument2 pagesContext Switch DefinitionLop MangNo ratings yet
- Ch2 - Process and Process ManagementDocument70 pagesCh2 - Process and Process ManagementHabtie TesfahunNo ratings yet
- Linux for Beginners: Linux Command Line, Linux Programming and Linux Operating SystemFrom EverandLinux for Beginners: Linux Command Line, Linux Programming and Linux Operating SystemRating: 4.5 out of 5 stars4.5/5 (3)