Download as pdf or txt
You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5822)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1093)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (852)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (898)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (540)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (349)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (823)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (403)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Becoming The Perfect Daughter - Spacer XDocument414 pagesBecoming The Perfect Daughter - Spacer XSergio Seferino33% (3)
- Terex RT 780. 80 Ton RTDocument20 pagesTerex RT 780. 80 Ton RTBhavana Kewlani67% (3)
- Turn Your Life Into A Living Masterpiece Masterclass by Jon Butcher WorkbookDocument12 pagesTurn Your Life Into A Living Masterpiece Masterclass by Jon Butcher WorkbookWalid HaouariNo ratings yet
- Tle10 He Cookery q2 Mod1 Performmiseenplace v3 (70 Pages)Document75 pagesTle10 He Cookery q2 Mod1 Performmiseenplace v3 (70 Pages)erra100% (5)
- 4 LD0266Document1 page4 LD0266luyckxj100% (1)
- Peta CalculusDocument2 pagesPeta CalculusAbby NavarroNo ratings yet
- Solvents Used in PharmacyDocument19 pagesSolvents Used in PharmacyMuhammad Mustafa IjazNo ratings yet
- Throw Training ProgramDocument3 pagesThrow Training ProgramSir Manny100% (1)
- Nitriding & Nitrocarburising: Mikael Fällström Bodycote AGI NEEDocument51 pagesNitriding & Nitrocarburising: Mikael Fällström Bodycote AGI NEEPushparaj Vignesh100% (1)
- Equipement Instrument ListDocument10 pagesEquipement Instrument Listcsc EXPERTISENo ratings yet
- Mechanical Engineering Elective 1 Week 34 PDFDocument5 pagesMechanical Engineering Elective 1 Week 34 PDFPatrickNo ratings yet
- Final Demo Lesson Plan Olermo Bonifacio Jr. C. 1Document17 pagesFinal Demo Lesson Plan Olermo Bonifacio Jr. C. 1juniobendiegoNo ratings yet
- 99+ Tiếng AnhDocument41 pages99+ Tiếng AnhducNo ratings yet
- CB Unit 2Document67 pagesCB Unit 2Hardik KhandharNo ratings yet
- Tripp Lite Apsint612Document12 pagesTripp Lite Apsint612samsogoyeNo ratings yet
- Anterior and Lateral Views of The SkullDocument18 pagesAnterior and Lateral Views of The SkullArshad hussainNo ratings yet
- Desastres Naturales y Plagas Del Valle ElquiDocument40 pagesDesastres Naturales y Plagas Del Valle ElquiWalter Foral LiebschNo ratings yet
- Cisco901 HW OverDocument10 pagesCisco901 HW Overkala-majkaNo ratings yet
- Outline and Critically Evaluate The Classical Conditioning Explanation of Phobias. How Have Such Explanations Influenced The Treatment of These Conditions?Document4 pagesOutline and Critically Evaluate The Classical Conditioning Explanation of Phobias. How Have Such Explanations Influenced The Treatment of These Conditions?AlineMola100% (1)
- Leviton 49253-Xxx 4925C-XxM Five-Ring Horizontal Cable ManagerDocument2 pagesLeviton 49253-Xxx 4925C-XxM Five-Ring Horizontal Cable ManagerJosé Luis RobalinoNo ratings yet
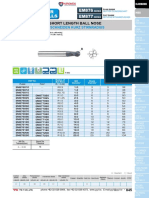
- X-Power End Mills EM877 EM876: Carbide, 2 Flute Short Length Ball NoseDocument2 pagesX-Power End Mills EM877 EM876: Carbide, 2 Flute Short Length Ball NosesahNo ratings yet
- Introduction:-: Mission & VisionDocument10 pagesIntroduction:-: Mission & Visionzalaks100% (5)
- Post-Translational Modification: Myristoylation PalmitoylationDocument2 pagesPost-Translational Modification: Myristoylation PalmitoylationAlanChevalNo ratings yet
- Modelling of Triple Friction Pendulum Bearing in Sap2000 PDFDocument8 pagesModelling of Triple Friction Pendulum Bearing in Sap2000 PDFJ Guerhard GuerhardNo ratings yet
- CH 4.2 - Mass BrainGuard IMAM-12Document21 pagesCH 4.2 - Mass BrainGuard IMAM-12tolerancelost607100% (1)
- Electrochemical Model For Performance Analysis of A Tubular SOFCDocument20 pagesElectrochemical Model For Performance Analysis of A Tubular SOFCpapillon tubaNo ratings yet
- Chapter-12 Hydro Generator and Excitation System TestsDocument13 pagesChapter-12 Hydro Generator and Excitation System TestsSe SamnangNo ratings yet
- Class 6 NSTSE PQP 10-Papers 2019-20 2-In-A4 PDFDocument85 pagesClass 6 NSTSE PQP 10-Papers 2019-20 2-In-A4 PDFSanjib Mandal100% (3)
- X9 User Manual: ImportantDocument28 pagesX9 User Manual: ImportantWolleo LW100% (1)
- Feubo Katalog 2016Document44 pagesFeubo Katalog 2016Suelen BarbosaNo ratings yet