Download as pdf or txt
You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5824)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1093)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (852)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (903)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (541)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (349)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (823)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (403)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Oisd 169Document27 pagesOisd 169Anonymous 70lCzDJv100% (3)
- ASME B46.1-2009 Surface Texture (Surface Roughness, Waviness, and Lay) - Part2Document37 pagesASME B46.1-2009 Surface Texture (Surface Roughness, Waviness, and Lay) - Part2R JNo ratings yet
- Record Linkage Similarity Measures and AlgorithmsDocument130 pagesRecord Linkage Similarity Measures and AlgorithmsbvishwanathrNo ratings yet
- Duplicate Record Detection - A SurveyDocument16 pagesDuplicate Record Detection - A SurveyvthungNo ratings yet
- p802 KoudastutorialDocument2 pagesp802 KoudastutorialvthungNo ratings yet
- Genetic ProgrammingDocument11 pagesGenetic ProgrammingvthungNo ratings yet
- Data Services in Your SpreadsheetDocument10 pagesData Services in Your SpreadsheetvthungNo ratings yet
- Genetic ProgrammingDocument11 pagesGenetic ProgrammingvthungNo ratings yet
- Message Broker Message FlowsDocument1,756 pagesMessage Broker Message Flowsvthung80% (5)
- Bernstein Presentation 03Document38 pagesBernstein Presentation 03vthungNo ratings yet
- Xquery: An XML Query LanguageDocument19 pagesXquery: An XML Query LanguagevthungNo ratings yet
- Answering Queries Using Views - A SurveyDocument25 pagesAnswering Queries Using Views - A SurveyvthungNo ratings yet
- Data Integration: A Theoretical Perspective: Maurizio LenzeriniDocument14 pagesData Integration: A Theoretical Perspective: Maurizio LenzerinivthungNo ratings yet
- Information Integration Using Logical ViewsDocument22 pagesInformation Integration Using Logical ViewsvthungNo ratings yet
- Information Integration: Maurizio LenzeriniDocument110 pagesInformation Integration: Maurizio LenzerinivthungNo ratings yet
- The Dell Vostro 1510Document3 pagesThe Dell Vostro 1510vthungNo ratings yet
- Provenance and Scientific WorkflowsDocument6 pagesProvenance and Scientific WorkflowsvthungNo ratings yet
- Querying and ReUsing Workflows With VisstrailsDocument4 pagesQuerying and ReUsing Workflows With VisstrailsvthungNo ratings yet
- Querying and Creating Visualizations by AnalogyDocument8 pagesQuerying and Creating Visualizations by AnalogyvthungNo ratings yet
- The State of The Art in End-User Software Engineering: Submitted To ACM Computing SurveysDocument50 pagesThe State of The Art in End-User Software Engineering: Submitted To ACM Computing SurveysvthungNo ratings yet
- XML Schema Automatic Matching SolutionDocument7 pagesXML Schema Automatic Matching SolutionvthungNo ratings yet
- Dfhuynh ThesisDocument134 pagesDfhuynh ThesisvthungNo ratings yet
- Line Follower Robot Using LabVIEWDocument6 pagesLine Follower Robot Using LabVIEWTrần Huy Vinh QuangNo ratings yet
- Fiber Optic Network DesignDocument2 pagesFiber Optic Network DesigndanilosilvestriNo ratings yet
- LPC2148 DacDocument14 pagesLPC2148 DacSmruti Pore100% (1)
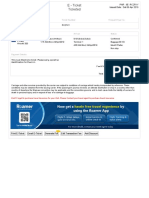
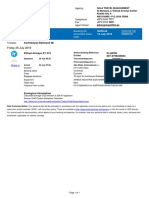
- Pax Details Ticket Number Frequent Flyer NoDocument1 pagePax Details Ticket Number Frequent Flyer NoRohit Kumar ChalotraNo ratings yet
- Pengukuran Tingkat Kematangan Simaster M F5155afeDocument12 pagesPengukuran Tingkat Kematangan Simaster M F5155afeseptian maulanaNo ratings yet
- Tda 2613 QDocument11 pagesTda 2613 Qpaulmx13No ratings yet
- Performance of A Coaxial Swirl Injector With Flow Path ReversalDocument8 pagesPerformance of A Coaxial Swirl Injector With Flow Path ReversalrakeshsakoteNo ratings yet
- STM RP Suzuki Samurai Transmission Rebuild Kits and Parts Parts I IIDocument118 pagesSTM RP Suzuki Samurai Transmission Rebuild Kits and Parts Parts I IIHatnean CristianNo ratings yet
- Kodak Professional Apparatus 1936Document62 pagesKodak Professional Apparatus 1936ajsikelNo ratings yet
- Inversor Automatico de Fuente de Poder Masterpact UA-BADocument38 pagesInversor Automatico de Fuente de Poder Masterpact UA-BARodolfoAntonioLeónCárdenas100% (1)
- Viking: Product ManualDocument26 pagesViking: Product ManualMailson Apaza KatataNo ratings yet
- ApcDocument20 pagesApcShaw ShaokNo ratings yet
- Manual IDS v1.0Document47 pagesManual IDS v1.0André SantanaNo ratings yet
- Importance of English in Computer ScienceDocument6 pagesImportance of English in Computer ScienceEdmond100% (3)
- Price R$ 216: Pousada Caravelas Di San RoccoDocument2 pagesPrice R$ 216: Pousada Caravelas Di San RoccoRildo ReisNo ratings yet
- KarthikeyanRatheesh MRDocument1 pageKarthikeyanRatheesh MRRatheeshKRNo ratings yet
- 5 5 32 4Document452 pages5 5 32 4Keith MorrisNo ratings yet
- Neon 2000 Parts ManualDocument275 pagesNeon 2000 Parts Manualhiguy71100% (1)
- Agma Gear Rating Suite 3Document1 pageAgma Gear Rating Suite 3mgualdiNo ratings yet
- Technology Enabled Solutions To Grow Your Business: Abuja: 5th Floor, IGI HouseDocument17 pagesTechnology Enabled Solutions To Grow Your Business: Abuja: 5th Floor, IGI HouseOyaje IdokoNo ratings yet
- LGK-100/120/160/200IGBT: Operator'S ManualDocument32 pagesLGK-100/120/160/200IGBT: Operator'S Manualservicio tecncioNo ratings yet
- FlowchartDocument6 pagesFlowchartyleno_meNo ratings yet
- EASA - IM .E.041 TCDS Issue 7Document20 pagesEASA - IM .E.041 TCDS Issue 7Rodrigo Hernanes Bezerra DinizNo ratings yet
- ISU - AMI - 1: Advanced Metering Infrastructure (New)Document70 pagesISU - AMI - 1: Advanced Metering Infrastructure (New)Amiz IzmmNo ratings yet
- Manual Spray Dryer DL410Document50 pagesManual Spray Dryer DL410Juanita Hincapie BedoyaNo ratings yet
- The Production of Organic Manure Using Kitchen WasteDocument27 pagesThe Production of Organic Manure Using Kitchen WasteAabhas RathNo ratings yet
- Daftar PustakaDocument2 pagesDaftar PustakaJohny Iskandar Arsyad NstNo ratings yet
- Au 3Document439 pagesAu 3Amit SinghNo ratings yet