Download as pdf or txt
You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5825)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1093)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (852)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (903)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (541)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (349)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (823)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (403)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- GH Bladed Theory ManualDocument88 pagesGH Bladed Theory ManualCFDiran.ir100% (2)
- Amca 99Document85 pagesAmca 99simonlia100% (5)
- Cocr Lect01Document67 pagesCocr Lect01Balajee KowshikNo ratings yet
- Performance Evaluation of Encryption Algorithms' Key Length Size On Web BrowsersDocument4 pagesPerformance Evaluation of Encryption Algorithms' Key Length Size On Web BrowsersBalajee KowshikNo ratings yet
- Improving Security For Elliptic Curve Implementations On Smart Cards: A Random Number Generator Test UnitDocument149 pagesImproving Security For Elliptic Curve Implementations On Smart Cards: A Random Number Generator Test UnitBalajee KowshikNo ratings yet
- EC2051Document7 pagesEC2051Balajee KowshikNo ratings yet
- NFC Technology: Jonathan Main Mastercard Worldwide Chairman, Technical CommitteeDocument29 pagesNFC Technology: Jonathan Main Mastercard Worldwide Chairman, Technical CommitteeBalajee KowshikNo ratings yet
- Combining Encryption Methods in MultipurposeDocument6 pagesCombining Encryption Methods in MultipurposeBalajee KowshikNo ratings yet
- Ibm 1Document5 pagesIbm 1ShwaNo ratings yet
- Ec2051 QBDocument3 pagesEc2051 QBBalajee Kowshik0% (1)
- M408L Exam 2Document9 pagesM408L Exam 2Nathan ThaiNo ratings yet
- KD Kakuro 5x5 v3 s2 b010Document3 pagesKD Kakuro 5x5 v3 s2 b010RADU GABINo ratings yet
- Vedic Mathematics: Prof M. BasannaDocument60 pagesVedic Mathematics: Prof M. BasannaM BasannaNo ratings yet
- Design and Analysis of A Shock Absorber: Conference PaperDocument16 pagesDesign and Analysis of A Shock Absorber: Conference PapercmuruganNo ratings yet
- Calculation Desk BookDocument145 pagesCalculation Desk Bookachmaddach100% (2)
- Communication System Lab ManualDocument81 pagesCommunication System Lab Manualabdulrehman001No ratings yet
- An Improved Clarke and Wright Savings Algorithm For The Capacitated Vehicle Routing ProblemDocument12 pagesAn Improved Clarke and Wright Savings Algorithm For The Capacitated Vehicle Routing ProblemC Villa LobosNo ratings yet
- Active Control of Quarter Car Suspension System UsDocument10 pagesActive Control of Quarter Car Suspension System UsFaris HadiyantoNo ratings yet
- Cvijetic-555 ch04Document88 pagesCvijetic-555 ch04miheretNo ratings yet
- Study and Design, Simulation of PWM Based Buck Converter For Low Power ApplicationDocument17 pagesStudy and Design, Simulation of PWM Based Buck Converter For Low Power ApplicationIOSRjournalNo ratings yet
- A12 Logarithms BP 9-22-14Document7 pagesA12 Logarithms BP 9-22-14aaoneNo ratings yet
- Fuzzy Rule Based System For Iris Flower Classification by Labin SenapatiDocument23 pagesFuzzy Rule Based System For Iris Flower Classification by Labin Senapatimail2laveenNo ratings yet
- Scratch Doc BookletDocument21 pagesScratch Doc Bookletsamsoum1No ratings yet
- PX C 3894038Document7 pagesPX C 3894038Sharad JadhavNo ratings yet
- Mass and Energy BalanceDocument9 pagesMass and Energy Balancerussell_mahmood100% (1)
- Stress ScenariosDocument13 pagesStress ScenariosAtul KapurNo ratings yet
- Control of Electric Vehicle PDFDocument31 pagesControl of Electric Vehicle PDFBrunoZueroNo ratings yet
- Lecture - Note3 - Introduction To MATLABDocument28 pagesLecture - Note3 - Introduction To MATLABali ranjbarNo ratings yet
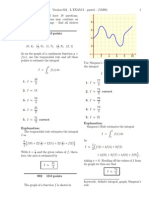
- X + y 4 2x + 3y 3 X, YDocument148 pagesX + y 4 2x + 3y 3 X, YVinayaka RamNo ratings yet
- Peak To Valley Ratio in ChromeleonDocument2 pagesPeak To Valley Ratio in ChromeleonDewi Wulandhari50% (2)
- GWR and HealthDocument12 pagesGWR and HealthRimjhim BajpaiNo ratings yet
- Michael Clapis Cylinder BlocksDocument5 pagesMichael Clapis Cylinder Blocksapi-734979884No ratings yet
- Instructor Guide: © 2011 APICS Confidential and ProprietaryDocument12 pagesInstructor Guide: © 2011 APICS Confidential and ProprietaryAminur RahamanNo ratings yet
- Plaxis Tutorial 8Document10 pagesPlaxis Tutorial 8Didik JunaidiNo ratings yet
- JJ311 MECHANICAL OF MACHINE CH 2 Simple Harmonic MotionDocument38 pagesJJ311 MECHANICAL OF MACHINE CH 2 Simple Harmonic MotionAh Tiang100% (3)
- Curriculum Map Template 1Document3 pagesCurriculum Map Template 1Manuel John SorianoNo ratings yet
- 2Document65 pages2jayashree rajNo ratings yet
- Optimization of The Cooling Tower Condenser Water Leaving Temperature Using A Component-Based ModelDocument11 pagesOptimization of The Cooling Tower Condenser Water Leaving Temperature Using A Component-Based ModelNevzatŞadoğlu100% (1)