
High-Performance Cone Beam Reconstruction Using Cuda Compatible Gpus
High-Performance Cone Beam Reconstruction Using Cuda Compatible Gpus
You might also like
- Auditory Verbal+Therapy+Science,+Research+and+Practice+by+Warren+Estabrooks,+Helen+McCaffrey+Morrison,+Karen+MacIver LuxDocument1,052 pagesAuditory Verbal+Therapy+Science,+Research+and+Practice+by+Warren+Estabrooks,+Helen+McCaffrey+Morrison,+Karen+MacIver LuxAndra Hazaparu100% (1)
- LESSON PLAN Listening SpeakingDocument3 pagesLESSON PLAN Listening SpeakingMuhammad Saifullah100% (2)
- SAP Workflow Extended NotificationDocument23 pagesSAP Workflow Extended NotificationNKNo ratings yet
- Eveline Anonymous PDFDocument2 pagesEveline Anonymous PDFJessicaNo ratings yet
- Image Parallel Processing Based On GPU PDFDocument4 pagesImage Parallel Processing Based On GPU PDFEider CarlosNo ratings yet
- A LBM Solver 3D Fluid Simulation On GPUDocument9 pagesA LBM Solver 3D Fluid Simulation On GPUZhe LiNo ratings yet
- Neural Network Implementation Using CUDA and OpenMPDocument7 pagesNeural Network Implementation Using CUDA and OpenMPWinicius FidelisNo ratings yet
- GPU QuicksortDocument22 pagesGPU QuicksortKriti JhaNo ratings yet
- CUDA Cuts Fast Graph Cuts On The GPUDocument8 pagesCUDA Cuts Fast Graph Cuts On The GPUas.dcdvfdNo ratings yet
- Research Article: Hybrid MPI and CUDA Parallelization For CFD Applications On Multi-GPU HPC ClustersDocument15 pagesResearch Article: Hybrid MPI and CUDA Parallelization For CFD Applications On Multi-GPU HPC Clusterszhaojie qinNo ratings yet
- Electronics 08 00065Document19 pagesElectronics 08 00065Maryam WaheedNo ratings yet
- GPU ClusterDocument12 pagesGPU ClusterPrashant GuptaNo ratings yet
- Accelerating Large Graph Algorithms On The GPU Using CudaDocument12 pagesAccelerating Large Graph Algorithms On The GPU Using Cudaabc010No ratings yet
- Improving The Performance of A Ray Tracing Algorithm Using A GPUDocument10 pagesImproving The Performance of A Ray Tracing Algorithm Using A GPUŤüšhâř ĶêšãvâñNo ratings yet
- Image Processing Using Fpgas: ImagingDocument4 pagesImage Processing Using Fpgas: ImagingAnonymous s516rsNo ratings yet
- Bandwidth Intensive 3-D FFT Kernel For Gpus Using Cuda: Akira Nukada, Yasuhiko Ogata, Toshio Endo, Satoshi MatsuokaDocument11 pagesBandwidth Intensive 3-D FFT Kernel For Gpus Using Cuda: Akira Nukada, Yasuhiko Ogata, Toshio Endo, Satoshi MatsuokaaruishawgNo ratings yet
- High Performance Pattern Recognition On GPUDocument6 pagesHigh Performance Pattern Recognition On GPUgco222No ratings yet
- Chapter-2: Literature ReviewDocument11 pagesChapter-2: Literature ReviewPritam SirpotdarNo ratings yet
- Real-Time Approximate and Combined 2D Convolvers FDocument29 pagesReal-Time Approximate and Combined 2D Convolvers Fsyncc500No ratings yet
- Ijaia 040202Document21 pagesIjaia 040202Adam HansenNo ratings yet
- Accelerating Marching Cubes With Graphics HardwareDocument6 pagesAccelerating Marching Cubes With Graphics HardwareGustavo Urquizo RodríguezNo ratings yet
- An Area-Efficient 2-D Convolution Implementation On FPGA For Space ApplicationsDocument6 pagesAn Area-Efficient 2-D Convolution Implementation On FPGA For Space ApplicationsCường Dương QuốcNo ratings yet
- Medical Image Processing On GPUDocument6 pagesMedical Image Processing On GPUBita KazemiNo ratings yet
- PC Project Report LatexDocument11 pagesPC Project Report LatexSahil AsoleNo ratings yet
- Icpp 2014 27Document10 pagesIcpp 2014 27ابراهيم التباعNo ratings yet
- Gpgpu Workshop CudaDocument10 pagesGpgpu Workshop CudaYohannes BekeleNo ratings yet
- Optimizing Memory Usage and Accesses On CUDA-Based Recurrent Pattern Matching Image CompressionDocument16 pagesOptimizing Memory Usage and Accesses On CUDA-Based Recurrent Pattern Matching Image CompressionspavalNo ratings yet
- Journal of Computational Physics: Dimitri Komatitsch, Gordon Erlebacher, Dominik Göddeke, David MichéaDocument23 pagesJournal of Computational Physics: Dimitri Komatitsch, Gordon Erlebacher, Dominik Göddeke, David MichéaJun YanNo ratings yet
- Memory Interference Characterization Between CPUDocument10 pagesMemory Interference Characterization Between CPUGary Ryan DonovanNo ratings yet
- Use of Reconfigurable FPGA For Image ProcessingDocument5 pagesUse of Reconfigurable FPGA For Image ProcessingParvathy S ParvathyNo ratings yet
- Accelerating Large Graph Algorithms On The GPU Using CUDADocument12 pagesAccelerating Large Graph Algorithms On The GPU Using CUDAMaks MržekNo ratings yet
- Side-Channel Power Analysis of A GPU AES Implementation: Chao Luo, Yunsi Fei, Pei Luo, Saoni Mukherjee, David KaeliDocument8 pagesSide-Channel Power Analysis of A GPU AES Implementation: Chao Luo, Yunsi Fei, Pei Luo, Saoni Mukherjee, David KaeliAnupam DasNo ratings yet
- Parallel Data Mining Techniques On GraphDocument26 pagesParallel Data Mining Techniques On GraphbadboydhbkNo ratings yet
- Christen 07Document8 pagesChristen 07bernasekNo ratings yet
- Parallelization of The PY3D Monocular Visual Odometry AlgorithmDocument7 pagesParallelization of The PY3D Monocular Visual Odometry AlgorithmDionata Nunes Elisa MassenaNo ratings yet
- Ijisa V11 N5 3Document9 pagesIjisa V11 N5 3RajeshNo ratings yet
- Efficient Acceleration of Asymmetric Cryptography On Graphics HardwareDocument17 pagesEfficient Acceleration of Asymmetric Cryptography On Graphics HardwareDomenico ArgenzianoNo ratings yet
- A Low-Power, High-Speed DCT Architecture For Image Compression: Principle and ImplementationDocument6 pagesA Low-Power, High-Speed DCT Architecture For Image Compression: Principle and ImplementationPrapulla Kumar RNo ratings yet
- Programming GPU Clusters With Shared Memory Abstraction in SoftwareDocument8 pagesProgramming GPU Clusters With Shared Memory Abstraction in SoftwarePisit MakpaisitNo ratings yet
- Im Improving Memory Proving Space Utilization in Multi-Core Embedded Systems Using Task RecomputationDocument9 pagesIm Improving Memory Proving Space Utilization in Multi-Core Embedded Systems Using Task RecomputationijcsnNo ratings yet
- A Dual-Core High-Performance Processor For Elliptic Curve Cryptography in GFP Over Generic Weierstrass CurvesDocument5 pagesA Dual-Core High-Performance Processor For Elliptic Curve Cryptography in GFP Over Generic Weierstrass Curvespsathishkumar1232544No ratings yet
- Water Entry Energy TransferDocument20 pagesWater Entry Energy TransferPrapanch NairNo ratings yet
- Efficient Hybrid Topology Optimization Using GPUDocument23 pagesEfficient Hybrid Topology Optimization Using GPUMd MehtabNo ratings yet
- Jimaging 05 00016Document22 pagesJimaging 05 00016vn7196No ratings yet
- Low Dynamic Range Discrete Cosine Transform LDRDCT For Highperformance JPEG Image Compressionvisual ComputerDocument26 pagesLow Dynamic Range Discrete Cosine Transform LDRDCT For Highperformance JPEG Image Compressionvisual ComputerHelder NevesNo ratings yet
- Scherl07 IOTDocument10 pagesScherl07 IOTSuresh K KrishnasamyNo ratings yet
- Ijaret: International Journal of Advanced Research in Engineering and Technology (Ijaret)Document9 pagesIjaret: International Journal of Advanced Research in Engineering and Technology (Ijaret)IAEME PublicationNo ratings yet
- 2019 - Scalable - Hardware-Based - On-Board - Processing - For - Run-Time - Adaptive - Lossless - Hyperspectral - CompressionDocument9 pages2019 - Scalable - Hardware-Based - On-Board - Processing - For - Run-Time - Adaptive - Lossless - Hyperspectral - CompressionSaru 2002No ratings yet
- GPU KhoruzhenkoDocument5 pagesGPU KhoruzhenkoOlhaNo ratings yet
- Characterizing The Execution Dynamics of GPGPU ApplicationsDocument5 pagesCharacterizing The Execution Dynamics of GPGPU ApplicationsagcarNo ratings yet
- Ieee 05486259Document6 pagesIeee 05486259Abolfazl MazloomiNo ratings yet
- Final Project Report MRI ReconstructionDocument19 pagesFinal Project Report MRI ReconstructionGokul SubramaniNo ratings yet
- 8 Things You Should Know About GPGPU Technology: Q&A With TACC Research ScientistsDocument2 pages8 Things You Should Know About GPGPU Technology: Q&A With TACC Research ScientistsAshish SharmaNo ratings yet
- ACEMD GpugridDocument9 pagesACEMD GpugriddDSniperNo ratings yet
- Cuda Review 1Document13 pagesCuda Review 1JESSEMANNo ratings yet
- Parallel Implementation of Sobel Filter Using CUDADocument4 pagesParallel Implementation of Sobel Filter Using CUDAabed81No ratings yet
- Mics2010 Submission 13Document12 pagesMics2010 Submission 13Materi MikomNo ratings yet
- An FPGA-Based Solution For A Graph Neural Network AcceleratorDocument9 pagesAn FPGA-Based Solution For A Graph Neural Network Acceleratorjohn BronsonNo ratings yet
- High-Performance Terrain Rendering Using Hardware TessellationDocument8 pagesHigh-Performance Terrain Rendering Using Hardware TessellationlijiebugNo ratings yet
- 2021 ICPR FASSDNetDocument8 pages2021 ICPR FASSDNetsimonfxNo ratings yet
- p17 TristramDocument10 pagesp17 TristramEd Gar YundaNo ratings yet
- Electronic Structure Calculations on Graphics Processing Units: From Quantum Chemistry to Condensed Matter PhysicsFrom EverandElectronic Structure Calculations on Graphics Processing Units: From Quantum Chemistry to Condensed Matter PhysicsRoss C. WalkerNo ratings yet
- Nintendo 64 Architecture: Architecture of Consoles: A Practical Analysis, #8From EverandNintendo 64 Architecture: Architecture of Consoles: A Practical Analysis, #8No ratings yet
- Dreamcast Architecture: Architecture of Consoles: A Practical Analysis, #9From EverandDreamcast Architecture: Architecture of Consoles: A Practical Analysis, #9No ratings yet
- Ontogeny of Skull Size and Shape Changes Within A Framework of Biphasic Lifestyle: A Case Study in Six Triturus Species (Amphibia, Salamandridae)Document11 pagesOntogeny of Skull Size and Shape Changes Within A Framework of Biphasic Lifestyle: A Case Study in Six Triturus Species (Amphibia, Salamandridae)mikimaricNo ratings yet
- Paw Patrol Pin The Badge On SkyeDocument5 pagesPaw Patrol Pin The Badge On SkyemikimaricNo ratings yet
- Lecture 2: Transformations and Histograms: H (K) Number of Pixels Whose Shade Equals K (U (I, J) K)Document12 pagesLecture 2: Transformations and Histograms: H (K) Number of Pixels Whose Shade Equals K (U (I, J) K)mikimaricNo ratings yet
- Karhunen-Loève Transform - KLT: Jankees Van Der Poel D.Sc. Student, Mechanical EngineeringDocument70 pagesKarhunen-Loève Transform - KLT: Jankees Van Der Poel D.Sc. Student, Mechanical EngineeringmikimaricNo ratings yet
- A Review On Neural Network-Based Image Segmentation TechniquesDocument23 pagesA Review On Neural Network-Based Image Segmentation TechniquesmikimaricNo ratings yet
- Convol 3 D 16 BitDocument14 pagesConvol 3 D 16 BitmikimaricNo ratings yet
- An Adaptive K-Means Clustering Algorithm For Breast Image SegmentationDocument4 pagesAn Adaptive K-Means Clustering Algorithm For Breast Image SegmentationmikimaricNo ratings yet
- Swath An Thir A KumarDocument120 pagesSwath An Thir A KumarmikimaricNo ratings yet
- Daily Routine Part 2: 18th January Prep - School Teacher: Mrs - Henda Level: 7th FormDocument1 pageDaily Routine Part 2: 18th January Prep - School Teacher: Mrs - Henda Level: 7th FormLaura VillamizarNo ratings yet
- Pricesing Procedure SAP MMDocument4 pagesPricesing Procedure SAP MMramakrishnaNo ratings yet
- Instalación DVWADocument14 pagesInstalación DVWAAlumno: Luis González HormigoNo ratings yet
- Summer Industrial Internship Programme-2016Document13 pagesSummer Industrial Internship Programme-2016ramjiNo ratings yet
- Listening MODULE 4Document52 pagesListening MODULE 4Gracille AbrahamNo ratings yet
- Active To Passive CHARTDocument2 pagesActive To Passive CHARTAndrea Mészáros KadelkaNo ratings yet
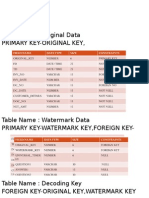
- Table Name: Original Data Primary Key-Original Key, Foreign Key-Invoice No, DC - NoDocument4 pagesTable Name: Original Data Primary Key-Original Key, Foreign Key-Invoice No, DC - Noanand_gsoft3603No ratings yet
- Part One - The Covenants With Abraham, Moses, and IsraelDocument32 pagesPart One - The Covenants With Abraham, Moses, and IsraelAlvin Cardona0% (1)
- ZubairDocument2 pagesZubairMuhammad SaadNo ratings yet
- English File Elementary - Unit 6 - RevisionDocument6 pagesEnglish File Elementary - Unit 6 - RevisionPia MauroNo ratings yet
- Word Formation - ExercisesDocument2 pagesWord Formation - Exercisesisathomazelli0% (1)
- Some Problems in The Ancient History of The Hinduized States of South-East AsiaDocument15 pagesSome Problems in The Ancient History of The Hinduized States of South-East Asiakutty moneNo ratings yet
- IELTS TEST LISTENING PRACTICE TEST 2.3 AnswerDocument3 pagesIELTS TEST LISTENING PRACTICE TEST 2.3 AnswerTrung VietNo ratings yet
- Position Analysis of Higher-Class Assur Groups byDocument8 pagesPosition Analysis of Higher-Class Assur Groups byPedroNo ratings yet
- Chapter 4 & 5 - Special TopicsDocument15 pagesChapter 4 & 5 - Special TopicsBearish PaleroNo ratings yet
- Limit, Continuity & Differentiability - Gadar 2.0Document109 pagesLimit, Continuity & Differentiability - Gadar 2.0studyforiittomeetbtsNo ratings yet
- 3 Schneider P546 kb4Document190 pages3 Schneider P546 kb4comportNo ratings yet
- Inogen One G5Document29 pagesInogen One G5Petru BotezatuNo ratings yet
- How To Punctuate: by Russell BakerDocument3 pagesHow To Punctuate: by Russell BakerAhmed El-AdawyNo ratings yet
- HOWTO Roadwarrior IPCop and OpenVPN Roadwarrior, Easy As One Two ThreeDocument16 pagesHOWTO Roadwarrior IPCop and OpenVPN Roadwarrior, Easy As One Two ThreeJose Antonio Jerez Caguaripano100% (1)
- 4-RRRS-SAP Comm InstallDocument20 pages4-RRRS-SAP Comm InstallravikanchuNo ratings yet
- Chapter 4 Transport Layer CISCODocument4 pagesChapter 4 Transport Layer CISCOhappy girlNo ratings yet
- HUAWEI BSC6000 V900R008 General Introduction: 2008-05 Security Level: Internal UseDocument32 pagesHUAWEI BSC6000 V900R008 General Introduction: 2008-05 Security Level: Internal UseroobowNo ratings yet
- A Map of Learning Outcomes Primary 1 (Connect) 1 TermDocument3 pagesA Map of Learning Outcomes Primary 1 (Connect) 1 TermAhmed MohamedNo ratings yet
- Dependent Prepositions: Inglés Profesional 2 Marco MezaDocument26 pagesDependent Prepositions: Inglés Profesional 2 Marco MezaElder Paucar RojasNo ratings yet
- "Missing Mass" in Dynamic Analysis - Structural Analysis and Design Wiki - Structural Analysis and Design - Be Communities by Bentley PDFDocument3 pages"Missing Mass" in Dynamic Analysis - Structural Analysis and Design Wiki - Structural Analysis and Design - Be Communities by Bentley PDFchondroc11No ratings yet

































































































Download as pdf or txt
You might also like
- Auditory Verbal+Therapy+Science,+Research+and+Practice+by+Warren+Estabrooks,+Helen+McCaffrey+Morrison,+Karen+MacIver LuxDocument1,052 pagesAuditory Verbal+Therapy+Science,+Research+and+Practice+by+Warren+Estabrooks,+Helen+McCaffrey+Morrison,+Karen+MacIver LuxAndra Hazaparu100% (1)
- LESSON PLAN Listening SpeakingDocument3 pagesLESSON PLAN Listening SpeakingMuhammad Saifullah100% (2)
- SAP Workflow Extended NotificationDocument23 pagesSAP Workflow Extended NotificationNKNo ratings yet
- Eveline Anonymous PDFDocument2 pagesEveline Anonymous PDFJessicaNo ratings yet
- Image Parallel Processing Based On GPU PDFDocument4 pagesImage Parallel Processing Based On GPU PDFEider CarlosNo ratings yet
- A LBM Solver 3D Fluid Simulation On GPUDocument9 pagesA LBM Solver 3D Fluid Simulation On GPUZhe LiNo ratings yet
- Neural Network Implementation Using CUDA and OpenMPDocument7 pagesNeural Network Implementation Using CUDA and OpenMPWinicius FidelisNo ratings yet
- GPU QuicksortDocument22 pagesGPU QuicksortKriti JhaNo ratings yet
- CUDA Cuts Fast Graph Cuts On The GPUDocument8 pagesCUDA Cuts Fast Graph Cuts On The GPUas.dcdvfdNo ratings yet
- Research Article: Hybrid MPI and CUDA Parallelization For CFD Applications On Multi-GPU HPC ClustersDocument15 pagesResearch Article: Hybrid MPI and CUDA Parallelization For CFD Applications On Multi-GPU HPC Clusterszhaojie qinNo ratings yet
- Electronics 08 00065Document19 pagesElectronics 08 00065Maryam WaheedNo ratings yet
- GPU ClusterDocument12 pagesGPU ClusterPrashant GuptaNo ratings yet
- Accelerating Large Graph Algorithms On The GPU Using CudaDocument12 pagesAccelerating Large Graph Algorithms On The GPU Using Cudaabc010No ratings yet
- Improving The Performance of A Ray Tracing Algorithm Using A GPUDocument10 pagesImproving The Performance of A Ray Tracing Algorithm Using A GPUŤüšhâř ĶêšãvâñNo ratings yet
- Image Processing Using Fpgas: ImagingDocument4 pagesImage Processing Using Fpgas: ImagingAnonymous s516rsNo ratings yet
- Bandwidth Intensive 3-D FFT Kernel For Gpus Using Cuda: Akira Nukada, Yasuhiko Ogata, Toshio Endo, Satoshi MatsuokaDocument11 pagesBandwidth Intensive 3-D FFT Kernel For Gpus Using Cuda: Akira Nukada, Yasuhiko Ogata, Toshio Endo, Satoshi MatsuokaaruishawgNo ratings yet
- High Performance Pattern Recognition On GPUDocument6 pagesHigh Performance Pattern Recognition On GPUgco222No ratings yet
- Chapter-2: Literature ReviewDocument11 pagesChapter-2: Literature ReviewPritam SirpotdarNo ratings yet
- Real-Time Approximate and Combined 2D Convolvers FDocument29 pagesReal-Time Approximate and Combined 2D Convolvers Fsyncc500No ratings yet
- Ijaia 040202Document21 pagesIjaia 040202Adam HansenNo ratings yet
- Accelerating Marching Cubes With Graphics HardwareDocument6 pagesAccelerating Marching Cubes With Graphics HardwareGustavo Urquizo RodríguezNo ratings yet
- An Area-Efficient 2-D Convolution Implementation On FPGA For Space ApplicationsDocument6 pagesAn Area-Efficient 2-D Convolution Implementation On FPGA For Space ApplicationsCường Dương QuốcNo ratings yet
- Medical Image Processing On GPUDocument6 pagesMedical Image Processing On GPUBita KazemiNo ratings yet
- PC Project Report LatexDocument11 pagesPC Project Report LatexSahil AsoleNo ratings yet
- Icpp 2014 27Document10 pagesIcpp 2014 27ابراهيم التباعNo ratings yet
- Gpgpu Workshop CudaDocument10 pagesGpgpu Workshop CudaYohannes BekeleNo ratings yet
- Optimizing Memory Usage and Accesses On CUDA-Based Recurrent Pattern Matching Image CompressionDocument16 pagesOptimizing Memory Usage and Accesses On CUDA-Based Recurrent Pattern Matching Image CompressionspavalNo ratings yet
- Journal of Computational Physics: Dimitri Komatitsch, Gordon Erlebacher, Dominik Göddeke, David MichéaDocument23 pagesJournal of Computational Physics: Dimitri Komatitsch, Gordon Erlebacher, Dominik Göddeke, David MichéaJun YanNo ratings yet
- Memory Interference Characterization Between CPUDocument10 pagesMemory Interference Characterization Between CPUGary Ryan DonovanNo ratings yet
- Use of Reconfigurable FPGA For Image ProcessingDocument5 pagesUse of Reconfigurable FPGA For Image ProcessingParvathy S ParvathyNo ratings yet
- Accelerating Large Graph Algorithms On The GPU Using CUDADocument12 pagesAccelerating Large Graph Algorithms On The GPU Using CUDAMaks MržekNo ratings yet
- Side-Channel Power Analysis of A GPU AES Implementation: Chao Luo, Yunsi Fei, Pei Luo, Saoni Mukherjee, David KaeliDocument8 pagesSide-Channel Power Analysis of A GPU AES Implementation: Chao Luo, Yunsi Fei, Pei Luo, Saoni Mukherjee, David KaeliAnupam DasNo ratings yet
- Parallel Data Mining Techniques On GraphDocument26 pagesParallel Data Mining Techniques On GraphbadboydhbkNo ratings yet
- Christen 07Document8 pagesChristen 07bernasekNo ratings yet
- Parallelization of The PY3D Monocular Visual Odometry AlgorithmDocument7 pagesParallelization of The PY3D Monocular Visual Odometry AlgorithmDionata Nunes Elisa MassenaNo ratings yet
- Ijisa V11 N5 3Document9 pagesIjisa V11 N5 3RajeshNo ratings yet
- Efficient Acceleration of Asymmetric Cryptography On Graphics HardwareDocument17 pagesEfficient Acceleration of Asymmetric Cryptography On Graphics HardwareDomenico ArgenzianoNo ratings yet
- A Low-Power, High-Speed DCT Architecture For Image Compression: Principle and ImplementationDocument6 pagesA Low-Power, High-Speed DCT Architecture For Image Compression: Principle and ImplementationPrapulla Kumar RNo ratings yet
- Programming GPU Clusters With Shared Memory Abstraction in SoftwareDocument8 pagesProgramming GPU Clusters With Shared Memory Abstraction in SoftwarePisit MakpaisitNo ratings yet
- Im Improving Memory Proving Space Utilization in Multi-Core Embedded Systems Using Task RecomputationDocument9 pagesIm Improving Memory Proving Space Utilization in Multi-Core Embedded Systems Using Task RecomputationijcsnNo ratings yet
- A Dual-Core High-Performance Processor For Elliptic Curve Cryptography in GFP Over Generic Weierstrass CurvesDocument5 pagesA Dual-Core High-Performance Processor For Elliptic Curve Cryptography in GFP Over Generic Weierstrass Curvespsathishkumar1232544No ratings yet
- Water Entry Energy TransferDocument20 pagesWater Entry Energy TransferPrapanch NairNo ratings yet
- Efficient Hybrid Topology Optimization Using GPUDocument23 pagesEfficient Hybrid Topology Optimization Using GPUMd MehtabNo ratings yet
- Jimaging 05 00016Document22 pagesJimaging 05 00016vn7196No ratings yet
- Low Dynamic Range Discrete Cosine Transform LDRDCT For Highperformance JPEG Image Compressionvisual ComputerDocument26 pagesLow Dynamic Range Discrete Cosine Transform LDRDCT For Highperformance JPEG Image Compressionvisual ComputerHelder NevesNo ratings yet
- Scherl07 IOTDocument10 pagesScherl07 IOTSuresh K KrishnasamyNo ratings yet
- Ijaret: International Journal of Advanced Research in Engineering and Technology (Ijaret)Document9 pagesIjaret: International Journal of Advanced Research in Engineering and Technology (Ijaret)IAEME PublicationNo ratings yet
- 2019 - Scalable - Hardware-Based - On-Board - Processing - For - Run-Time - Adaptive - Lossless - Hyperspectral - CompressionDocument9 pages2019 - Scalable - Hardware-Based - On-Board - Processing - For - Run-Time - Adaptive - Lossless - Hyperspectral - CompressionSaru 2002No ratings yet
- GPU KhoruzhenkoDocument5 pagesGPU KhoruzhenkoOlhaNo ratings yet
- Characterizing The Execution Dynamics of GPGPU ApplicationsDocument5 pagesCharacterizing The Execution Dynamics of GPGPU ApplicationsagcarNo ratings yet
- Ieee 05486259Document6 pagesIeee 05486259Abolfazl MazloomiNo ratings yet
- Final Project Report MRI ReconstructionDocument19 pagesFinal Project Report MRI ReconstructionGokul SubramaniNo ratings yet
- 8 Things You Should Know About GPGPU Technology: Q&A With TACC Research ScientistsDocument2 pages8 Things You Should Know About GPGPU Technology: Q&A With TACC Research ScientistsAshish SharmaNo ratings yet
- ACEMD GpugridDocument9 pagesACEMD GpugriddDSniperNo ratings yet
- Cuda Review 1Document13 pagesCuda Review 1JESSEMANNo ratings yet
- Parallel Implementation of Sobel Filter Using CUDADocument4 pagesParallel Implementation of Sobel Filter Using CUDAabed81No ratings yet
- Mics2010 Submission 13Document12 pagesMics2010 Submission 13Materi MikomNo ratings yet
- An FPGA-Based Solution For A Graph Neural Network AcceleratorDocument9 pagesAn FPGA-Based Solution For A Graph Neural Network Acceleratorjohn BronsonNo ratings yet
- High-Performance Terrain Rendering Using Hardware TessellationDocument8 pagesHigh-Performance Terrain Rendering Using Hardware TessellationlijiebugNo ratings yet
- 2021 ICPR FASSDNetDocument8 pages2021 ICPR FASSDNetsimonfxNo ratings yet
- p17 TristramDocument10 pagesp17 TristramEd Gar YundaNo ratings yet
- Electronic Structure Calculations on Graphics Processing Units: From Quantum Chemistry to Condensed Matter PhysicsFrom EverandElectronic Structure Calculations on Graphics Processing Units: From Quantum Chemistry to Condensed Matter PhysicsRoss C. WalkerNo ratings yet
- Nintendo 64 Architecture: Architecture of Consoles: A Practical Analysis, #8From EverandNintendo 64 Architecture: Architecture of Consoles: A Practical Analysis, #8No ratings yet
- Dreamcast Architecture: Architecture of Consoles: A Practical Analysis, #9From EverandDreamcast Architecture: Architecture of Consoles: A Practical Analysis, #9No ratings yet
- Ontogeny of Skull Size and Shape Changes Within A Framework of Biphasic Lifestyle: A Case Study in Six Triturus Species (Amphibia, Salamandridae)Document11 pagesOntogeny of Skull Size and Shape Changes Within A Framework of Biphasic Lifestyle: A Case Study in Six Triturus Species (Amphibia, Salamandridae)mikimaricNo ratings yet
- Paw Patrol Pin The Badge On SkyeDocument5 pagesPaw Patrol Pin The Badge On SkyemikimaricNo ratings yet
- Lecture 2: Transformations and Histograms: H (K) Number of Pixels Whose Shade Equals K (U (I, J) K)Document12 pagesLecture 2: Transformations and Histograms: H (K) Number of Pixels Whose Shade Equals K (U (I, J) K)mikimaricNo ratings yet
- Karhunen-Loève Transform - KLT: Jankees Van Der Poel D.Sc. Student, Mechanical EngineeringDocument70 pagesKarhunen-Loève Transform - KLT: Jankees Van Der Poel D.Sc. Student, Mechanical EngineeringmikimaricNo ratings yet
- A Review On Neural Network-Based Image Segmentation TechniquesDocument23 pagesA Review On Neural Network-Based Image Segmentation TechniquesmikimaricNo ratings yet
- Convol 3 D 16 BitDocument14 pagesConvol 3 D 16 BitmikimaricNo ratings yet
- An Adaptive K-Means Clustering Algorithm For Breast Image SegmentationDocument4 pagesAn Adaptive K-Means Clustering Algorithm For Breast Image SegmentationmikimaricNo ratings yet
- Swath An Thir A KumarDocument120 pagesSwath An Thir A KumarmikimaricNo ratings yet
- Daily Routine Part 2: 18th January Prep - School Teacher: Mrs - Henda Level: 7th FormDocument1 pageDaily Routine Part 2: 18th January Prep - School Teacher: Mrs - Henda Level: 7th FormLaura VillamizarNo ratings yet
- Pricesing Procedure SAP MMDocument4 pagesPricesing Procedure SAP MMramakrishnaNo ratings yet
- Instalación DVWADocument14 pagesInstalación DVWAAlumno: Luis González HormigoNo ratings yet
- Summer Industrial Internship Programme-2016Document13 pagesSummer Industrial Internship Programme-2016ramjiNo ratings yet
- Listening MODULE 4Document52 pagesListening MODULE 4Gracille AbrahamNo ratings yet
- Active To Passive CHARTDocument2 pagesActive To Passive CHARTAndrea Mészáros KadelkaNo ratings yet
- Table Name: Original Data Primary Key-Original Key, Foreign Key-Invoice No, DC - NoDocument4 pagesTable Name: Original Data Primary Key-Original Key, Foreign Key-Invoice No, DC - Noanand_gsoft3603No ratings yet
- Part One - The Covenants With Abraham, Moses, and IsraelDocument32 pagesPart One - The Covenants With Abraham, Moses, and IsraelAlvin Cardona0% (1)
- ZubairDocument2 pagesZubairMuhammad SaadNo ratings yet
- English File Elementary - Unit 6 - RevisionDocument6 pagesEnglish File Elementary - Unit 6 - RevisionPia MauroNo ratings yet
- Word Formation - ExercisesDocument2 pagesWord Formation - Exercisesisathomazelli0% (1)
- Some Problems in The Ancient History of The Hinduized States of South-East AsiaDocument15 pagesSome Problems in The Ancient History of The Hinduized States of South-East Asiakutty moneNo ratings yet
- IELTS TEST LISTENING PRACTICE TEST 2.3 AnswerDocument3 pagesIELTS TEST LISTENING PRACTICE TEST 2.3 AnswerTrung VietNo ratings yet
- Position Analysis of Higher-Class Assur Groups byDocument8 pagesPosition Analysis of Higher-Class Assur Groups byPedroNo ratings yet
- Chapter 4 & 5 - Special TopicsDocument15 pagesChapter 4 & 5 - Special TopicsBearish PaleroNo ratings yet
- Limit, Continuity & Differentiability - Gadar 2.0Document109 pagesLimit, Continuity & Differentiability - Gadar 2.0studyforiittomeetbtsNo ratings yet
- 3 Schneider P546 kb4Document190 pages3 Schneider P546 kb4comportNo ratings yet
- Inogen One G5Document29 pagesInogen One G5Petru BotezatuNo ratings yet
- How To Punctuate: by Russell BakerDocument3 pagesHow To Punctuate: by Russell BakerAhmed El-AdawyNo ratings yet
- HOWTO Roadwarrior IPCop and OpenVPN Roadwarrior, Easy As One Two ThreeDocument16 pagesHOWTO Roadwarrior IPCop and OpenVPN Roadwarrior, Easy As One Two ThreeJose Antonio Jerez Caguaripano100% (1)
- 4-RRRS-SAP Comm InstallDocument20 pages4-RRRS-SAP Comm InstallravikanchuNo ratings yet
- Chapter 4 Transport Layer CISCODocument4 pagesChapter 4 Transport Layer CISCOhappy girlNo ratings yet
- HUAWEI BSC6000 V900R008 General Introduction: 2008-05 Security Level: Internal UseDocument32 pagesHUAWEI BSC6000 V900R008 General Introduction: 2008-05 Security Level: Internal UseroobowNo ratings yet
- A Map of Learning Outcomes Primary 1 (Connect) 1 TermDocument3 pagesA Map of Learning Outcomes Primary 1 (Connect) 1 TermAhmed MohamedNo ratings yet
- Dependent Prepositions: Inglés Profesional 2 Marco MezaDocument26 pagesDependent Prepositions: Inglés Profesional 2 Marco MezaElder Paucar RojasNo ratings yet
- "Missing Mass" in Dynamic Analysis - Structural Analysis and Design Wiki - Structural Analysis and Design - Be Communities by Bentley PDFDocument3 pages"Missing Mass" in Dynamic Analysis - Structural Analysis and Design Wiki - Structural Analysis and Design - Be Communities by Bentley PDFchondroc11No ratings yet