Download as pdf or txt
You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5822)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1093)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (852)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (898)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (540)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (349)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (822)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (403)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- NU - Urban Breach Handbook - TEBCDocument13 pagesNU - Urban Breach Handbook - TEBCiagaruNo ratings yet
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- SampleDocument15 pagesSamplesarthak50% (2)
- AASHTO t99 180Document7 pagesAASHTO t99 180dongpc1No ratings yet
- EDC - Unit 3 FinalDocument118 pagesEDC - Unit 3 FinalDr UmapathyNo ratings yet
- Product GuideDocument52 pagesProduct GuidePham Cao ThanhNo ratings yet
- M&B FootwearDocument2 pagesM&B FootwearVipul KothariNo ratings yet
- Configurando Google Sheet y Pushing BoxDocument23 pagesConfigurando Google Sheet y Pushing BoxRuben RaygosaNo ratings yet
- Cruise Control Repair W123Document8 pagesCruise Control Repair W123Michael RynworthNo ratings yet
- Evertz 7720DAC-A4 1v2 ManualDocument12 pagesEvertz 7720DAC-A4 1v2 ManualErik VahlandNo ratings yet
- Ra Lex Physicians With Advisory2023 Cdo 1Document24 pagesRa Lex Physicians With Advisory2023 Cdo 1mikzhiNo ratings yet
- Department of Information Technology: Question Bank TE IT AY-22-23 Sem VI Module 04: Clustering & Outlier AnalysisDocument4 pagesDepartment of Information Technology: Question Bank TE IT AY-22-23 Sem VI Module 04: Clustering & Outlier AnalysisAnurag SinghNo ratings yet
- LANE DEPARTURE WARNING SYSTEM (LDW) l200Document4 pagesLANE DEPARTURE WARNING SYSTEM (LDW) l200Miguel RomoNo ratings yet
- Classification of CementDocument7 pagesClassification of CementMonzer HussainNo ratings yet
- NCE-T HCIA LectureDocument95 pagesNCE-T HCIA LectureSayed Rahim NaderiNo ratings yet
- Backbone JSDocument4 pagesBackbone JSShantha Moorthy0% (1)
- Example For Decision Making CriteriaDocument5 pagesExample For Decision Making CriteriaArly Kurt TorresNo ratings yet
- How The Internet Has Afffected My Life (Essay)Document2 pagesHow The Internet Has Afffected My Life (Essay)Syafiyah Binti Mohamad Basri TESL-0619No ratings yet
- Assignment AnsDocument6 pagesAssignment AnsVAIGESWARI A/P MANIAM STUDENTNo ratings yet
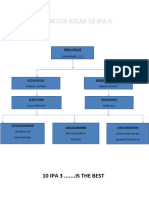
- Struktur Kelas 10 Ipa 3Document17 pagesStruktur Kelas 10 Ipa 3Okvie AjaNo ratings yet
- Faktor-Faktor Yang Berhubungan Dengan Kejadian Luka Dekubitus Akibat Penggunaan Alat Medis Di Ruang PicuDocument11 pagesFaktor-Faktor Yang Berhubungan Dengan Kejadian Luka Dekubitus Akibat Penggunaan Alat Medis Di Ruang PicuChensya SouisaNo ratings yet
- Aire Acondicionado Iveco DailyDocument1 pageAire Acondicionado Iveco DailyjasogtiNo ratings yet
- Rustys 3inch Lift Kit Installation RK-300SP-XJDocument2 pagesRustys 3inch Lift Kit Installation RK-300SP-XJnorthernscribdNo ratings yet
- Serial Number Range: From SN 2575 To 9153Document214 pagesSerial Number Range: From SN 2575 To 9153Rigoberto Rodríguez(Power Gen, S.A)No ratings yet
- Kaugaliang Pilipino Quarter 3 Week 2Document20 pagesKaugaliang Pilipino Quarter 3 Week 2Linegevan IacgarNo ratings yet
- Part 1 - Clinical Manual - January 2018 - Version 8.0Document260 pagesPart 1 - Clinical Manual - January 2018 - Version 8.0AbhishekNo ratings yet
- Socio Lecture PPT 2Document330 pagesSocio Lecture PPT 2Bhenjo Hernandez BaronaNo ratings yet
- Ecs2602 Tests Bank 1Document107 pagesEcs2602 Tests Bank 1wycliff brancNo ratings yet
- Voila User ManualDocument79 pagesVoila User ManualKristen HammerNo ratings yet
- Coco Fire Indonesa - Anu 2021Document20 pagesCoco Fire Indonesa - Anu 2021Abizard Niaga UtamaNo ratings yet
- Huawei V1 R3 Upgrade GuideDocument67 pagesHuawei V1 R3 Upgrade GuideMahmoud RiadNo ratings yet