
Interpretation of Water Quality Data by Principal
Interpretation of Water Quality Data by Principal
You might also like
- Homework 3Document7 pagesHomework 3Alexis R. CamargoNo ratings yet
- Divya.v Project Final 1Document41 pagesDivya.v Project Final 1Karthi KeyanNo ratings yet
- Episode 1028: Algal Blooms On Lake SuperiorDocument12 pagesEpisode 1028: Algal Blooms On Lake SuperiorGreat Lakes NowNo ratings yet
- EBX 041 192 - FT - EurobioPlex SARS CoV 2 Multiplex - EN - v4.00 - 20 04 20202 PDFDocument17 pagesEBX 041 192 - FT - EurobioPlex SARS CoV 2 Multiplex - EN - v4.00 - 20 04 20202 PDFAncapc AncapcNo ratings yet
- Read Me GenAlEx 6.41Document10 pagesRead Me GenAlEx 6.41ParkNo ratings yet
- 09931158A Burner System Users Guide PDFDocument128 pages09931158A Burner System Users Guide PDFkariliz15No ratings yet
- Study Set 2Document11 pagesStudy Set 2Ammara RasheedNo ratings yet
- University Paper SolutionsDocument132 pagesUniversity Paper Solutionskane daveNo ratings yet
- Analysis of Variation of Water Quality in Kelani River, Sri LankaDocument6 pagesAnalysis of Variation of Water Quality in Kelani River, Sri LankaIJEAB JournalNo ratings yet
- r7210105 SurveyingDocument4 pagesr7210105 SurveyingsivabharathamurthyNo ratings yet
- Icasi 2018 Sonproceedingve Ozet KitabcigiDocument726 pagesIcasi 2018 Sonproceedingve Ozet KitabcigiIlo Ruiz100% (1)
- Methods of PhytoremediationDocument7 pagesMethods of PhytoremediationIan KirkNo ratings yet
- 4 (Evapotranspiration)Document33 pages4 (Evapotranspiration)Lim Shwe WenNo ratings yet
- Avant-Pays de La Meseta MarocaineDocument7 pagesAvant-Pays de La Meseta MarocaineIMMELOUI MohamedNo ratings yet
- Contact Angle MeasurementsDocument7 pagesContact Angle MeasurementsThoifah MuthohharohNo ratings yet
- Blast Vs FastaDocument3 pagesBlast Vs FastaAhmad Faraz KhanNo ratings yet
- Indice JaccardDocument12 pagesIndice JaccardMelinte AlexandruNo ratings yet
- English2as Project-Noble PriceDocument23 pagesEnglish2as Project-Noble Priceالتداوي بالاعشاب الطبية ببراقيNo ratings yet
- Solution Sheets AcetoorceinDocument1 pageSolution Sheets AcetoorceinsaputraalamNo ratings yet
- Modelling and Mapping of Water Erosion Risk by Application of The GIS and PAP/RAC Guidelines in The Watershed of Oued Zgane (Middle Atlas Morocco)Document17 pagesModelling and Mapping of Water Erosion Risk by Application of The GIS and PAP/RAC Guidelines in The Watershed of Oued Zgane (Middle Atlas Morocco)Oualid HakamNo ratings yet
- PhytoremediationDocument42 pagesPhytoremediationSeroKeretaMasaroWidiarNo ratings yet
- Nano AdsorbantsDocument6 pagesNano AdsorbantsDl Al-aziz0% (1)
- SIAL QPCR Technical Guide PDFDocument42 pagesSIAL QPCR Technical Guide PDFiuventas100% (1)
- Disinfection: University Curriculum Development For Decentralized Wastewater ManagementDocument35 pagesDisinfection: University Curriculum Development For Decentralized Wastewater ManagementLTE002No ratings yet
- Prediction of Performance Efficiency For Wastewater Treatment Plant's Effluent Biochemical Oxygen Demand Using Artificial Neural NetworkDocument11 pagesPrediction of Performance Efficiency For Wastewater Treatment Plant's Effluent Biochemical Oxygen Demand Using Artificial Neural NetworkInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Pressure-Driven Cavitating Flow of Water Through A Sharp-Edged OrificeDocument13 pagesPressure-Driven Cavitating Flow of Water Through A Sharp-Edged OrificeKaushika Rajapaksha PereraNo ratings yet
- Apricot Diseases Diagnostic Key PDFDocument2 pagesApricot Diseases Diagnostic Key PDFkhouchaymiNo ratings yet
- Bio RemediationDocument24 pagesBio RemediationMinhaj HaiderNo ratings yet
- 2.2.46. Chromatographic Separation TechniquesDocument5 pages2.2.46. Chromatographic Separation TechniquesFemmes RêveurNo ratings yet
- Molecular Mechanisms of Insecticide ResistanceDocument11 pagesMolecular Mechanisms of Insecticide ResistancejoharijalinasNo ratings yet
- Detection of Integrons in Multidrug Resistant Wound IsolatesDocument7 pagesDetection of Integrons in Multidrug Resistant Wound IsolatesEditor IJTSRDNo ratings yet
- Systematic Bacteriology: The and The Deeply Branching and PhototrophicDocument18 pagesSystematic Bacteriology: The and The Deeply Branching and PhototrophicMuhammad JamalNo ratings yet
- 2013 Exposed GM Covers - OthmanDocument16 pages2013 Exposed GM Covers - OthmanSebas MoraNo ratings yet
- Atmospheric Pollution Paper Sci & Eng.)Document6 pagesAtmospheric Pollution Paper Sci & Eng.)akaj188No ratings yet
- Thesis Lid DrivenDocument145 pagesThesis Lid DrivenEddieq100% (1)
- Standard Procedure For Luminescence Vibrio FischeriDocument14 pagesStandard Procedure For Luminescence Vibrio FischeriCarlos DiazNo ratings yet
- The Benefits of Industrial SymbiosisDocument33 pagesThe Benefits of Industrial Symbiosisrobotrobot13No ratings yet
- Analyse Bacterologique de L EauDocument6 pagesAnalyse Bacterologique de L Eaupeguy diffoNo ratings yet
- Phytodegradation: Figure 1. Destruction of Organic Contaminants by PhytodegradationDocument5 pagesPhytodegradation: Figure 1. Destruction of Organic Contaminants by PhytodegradationChescaMendioroNo ratings yet
- Biocementation and BiocementsDocument30 pagesBiocementation and BiocementscarloscarinelliNo ratings yet
- Bacteria Colony Appearance MorphologyDocument2 pagesBacteria Colony Appearance MorphologyMonique Lopes da SilvaNo ratings yet
- Goodchild - Geographic Information Systems and ScienceDocument13 pagesGoodchild - Geographic Information Systems and ScienceIhkmuyalNo ratings yet
- Antioxidant Properties of Various Solvent Extracts of Total Phenolic Constituents From Three Different Agroclimatic Origins of Drumstick Tree (Moringa Oleifera Lam.) LeavesDocument12 pagesAntioxidant Properties of Various Solvent Extracts of Total Phenolic Constituents From Three Different Agroclimatic Origins of Drumstick Tree (Moringa Oleifera Lam.) LeavesMeiNo ratings yet
- Ultracentrifugation: June 2010Document8 pagesUltracentrifugation: June 2010Nayak Alok RanjanNo ratings yet
- The Titration of Clay MineralsDocument10 pagesThe Titration of Clay MineralsroyamohamadyNo ratings yet
- Boomer and Attwood 2007Document9 pagesBoomer and Attwood 2007Raphael ZilligNo ratings yet
- Biosensors - Analytical DeviceDocument4 pagesBiosensors - Analytical DeviceJournal 4 ResearchNo ratings yet
- How Do You Calculate The Sensitivity in A Voltammetry AnalysisDocument11 pagesHow Do You Calculate The Sensitivity in A Voltammetry AnalysisElbahi DjaalabNo ratings yet
- Kla DeterminationDocument23 pagesKla DeterminationJokanoe LertNo ratings yet
- Boublenza2019 Caroubier AlgérieDocument8 pagesBoublenza2019 Caroubier AlgérieNàzim Jorden100% (1)
- Design of Landfill Daily CellsDocument12 pagesDesign of Landfill Daily CellsKaustav PatnaikNo ratings yet
- 4006oral Solutions, Syrups, & ElixirsDocument83 pages4006oral Solutions, Syrups, & ElixirsOctavio Cardenas OrozcoNo ratings yet
- LC-MSMS (En)Document69 pagesLC-MSMS (En)LựuLiềuLìNo ratings yet
- Nienow 1998 Hydrodynamics in Stirred Bioreactors.Document31 pagesNienow 1998 Hydrodynamics in Stirred Bioreactors.AlbertoNo ratings yet
- NEW Annex 7 Qualification of Mass Spectrometers PDFDocument11 pagesNEW Annex 7 Qualification of Mass Spectrometers PDFParkhomyukNo ratings yet
- Phonopy Tips 2014Document48 pagesPhonopy Tips 2014anibrataNo ratings yet
- Hinotek FP640 Flamephotometer ManualDocument17 pagesHinotek FP640 Flamephotometer ManualKader SmailiNo ratings yet
- Manual 5800 Agilent ICP-OESDocument66 pagesManual 5800 Agilent ICP-OESdqrocha_ifamNo ratings yet
- Modeling of The Bacterial Growth Curve.Document7 pagesModeling of The Bacterial Growth Curve.Adrian Bermudez LoeraNo ratings yet
- Protein Purification HandbookDocument94 pagesProtein Purification HandbookDolphingNo ratings yet
- Slab Planar: Charged Species Migration Rate Electric FieldDocument15 pagesSlab Planar: Charged Species Migration Rate Electric FieldEng Leng LeeNo ratings yet
- Deü Mühendislik Fakültesi Fen Ve Mühendislik DergisiDocument12 pagesDeü Mühendislik Fakültesi Fen Ve Mühendislik DergisiDomingos BernardoNo ratings yet
- Spss Şeref KalaycıDocument6 pagesSpss Şeref KalaycıNes HanNo ratings yet
- X X X X N X N: 1. Discuss/define Three Measures of Central TendencyDocument7 pagesX X X X N X N: 1. Discuss/define Three Measures of Central TendencyPandurang ThatkarNo ratings yet
- Stress and GPA: Analysis of The Initial Administration of A New Instrument For Measuring Stress and Its Relationship To College GPADocument25 pagesStress and GPA: Analysis of The Initial Administration of A New Instrument For Measuring Stress and Its Relationship To College GPAPandurang ThatkarNo ratings yet
- Responses Week2Document2 pagesResponses Week2Pandurang ThatkarNo ratings yet
- OThompson Wk5AssgnOThompson CorrectedDocument12 pagesOThompson Wk5AssgnOThompson CorrectedPandurang ThatkarNo ratings yet
- Field-Scale Monitoring of The Long-Term Impact and Sustainability of Drainage Water Reuse On The West Side of California's San Joaquin ValleyDocument12 pagesField-Scale Monitoring of The Long-Term Impact and Sustainability of Drainage Water Reuse On The West Side of California's San Joaquin ValleyPandurang ThatkarNo ratings yet
- Omar Thompson Week2 Discussion1Document2 pagesOmar Thompson Week2 Discussion1Pandurang ThatkarNo ratings yet
- New Data Internet UsageDocument6 pagesNew Data Internet UsagePandurang ThatkarNo ratings yet
- Regression Analysis ANOVA Results SS DF MS F PDocument4 pagesRegression Analysis ANOVA Results SS DF MS F PPandurang ThatkarNo ratings yet
- Q.1 From The Histogram, We Observe That The Rod Diameter Is Approximately Normally DistributedDocument5 pagesQ.1 From The Histogram, We Observe That The Rod Diameter Is Approximately Normally DistributedPandurang ThatkarNo ratings yet
- Generating A Binomial Distribution With Parameters N 10 and P 0.63Document4 pagesGenerating A Binomial Distribution With Parameters N 10 and P 0.63Pandurang ThatkarNo ratings yet
- Question: Is The Graduation Rate Higher at Hbcus or Non-Hbcus For Women Compared To Men?Document5 pagesQuestion: Is The Graduation Rate Higher at Hbcus or Non-Hbcus For Women Compared To Men?Pandurang ThatkarNo ratings yet
- Homework 2Document4 pagesHomework 2Pandurang ThatkarNo ratings yet
- Discussion Week 6: Williams, 1998)Document2 pagesDiscussion Week 6: Williams, 1998)Pandurang ThatkarNo ratings yet
- Discussion Week2:: For Texture Classification," 3rd International Workshop On Texture Analysis and SynthesisDocument1 pageDiscussion Week2:: For Texture Classification," 3rd International Workshop On Texture Analysis and SynthesisPandurang ThatkarNo ratings yet
- CorrectionsDocument4 pagesCorrectionsPandurang ThatkarNo ratings yet
- Parental Attitude Research Instrument: Attitude An Approach To Use QuestionnairesDocument6 pagesParental Attitude Research Instrument: Attitude An Approach To Use QuestionnairesMaya MayaNo ratings yet
- Leadership Style and Its Impact On Employee PerformanceDocument15 pagesLeadership Style and Its Impact On Employee PerformanceSophia Illescas GallardoNo ratings yet
- Industrial Needs On English Skills of New Employees: A SurveyDocument13 pagesIndustrial Needs On English Skills of New Employees: A Surveyonly humanNo ratings yet
- Chapter - Ii Review of Related LiteratureDocument28 pagesChapter - Ii Review of Related LiteratureAmrit VallahNo ratings yet
- G Power ManualDocument78 pagesG Power ManualLavinia Stupariu100% (1)
- Estimating IBNR Claims Reserves For General InsuraDocument20 pagesEstimating IBNR Claims Reserves For General InsuraWael TrabelsiNo ratings yet
- Thomas-Fiering Model For The Sequential Generation of Stream FlowDocument26 pagesThomas-Fiering Model For The Sequential Generation of Stream Flowyahya100% (3)
- SPPU Solved Question Papers MCQ Unit 5Document18 pagesSPPU Solved Question Papers MCQ Unit 5Anonymous XTL7o0tGo90% (2)
- Code STAT Course DetailsDocument49 pagesCode STAT Course Detailsfazalulbasit9796No ratings yet
- Mss 202 Practice 19-20Document2 pagesMss 202 Practice 19-20fayinminu oluwaniyiNo ratings yet
- Curriculum OF Botany: BS (4-YEAR)Document91 pagesCurriculum OF Botany: BS (4-YEAR)Abas92No ratings yet
- Optimising Sampling Techniques and Estimating Sampling Variance of Fleece Quality Attributes in AlpacasDocument12 pagesOptimising Sampling Techniques and Estimating Sampling Variance of Fleece Quality Attributes in AlpacasRenato Jesus Cordova GarciaNo ratings yet
- Panel Ecmiic2Document57 pagesPanel Ecmiic2wjimenez1938No ratings yet
- Spss ExercisesDocument13 pagesSpss Exercisesishfaq khan315No ratings yet
- Risk Identification & MeasurementDocument24 pagesRisk Identification & Measurementvmtripathi0967% (3)
- Effectiveness of Jacobson'S Progressive Muscle Relaxation (JPMR) Technique On Social Anxiety Among High School Adolescents in A Selected School of Udupi District, Karnataka StateDocument5 pagesEffectiveness of Jacobson'S Progressive Muscle Relaxation (JPMR) Technique On Social Anxiety Among High School Adolescents in A Selected School of Udupi District, Karnataka StateSidharth PraveenNo ratings yet
- Word-Patterns and Story-Shapes: The Statistical Analysis of Narrative StyleDocument10 pagesWord-Patterns and Story-Shapes: The Statistical Analysis of Narrative StyleAdemar JúniorNo ratings yet
- Basics of Multivariate NormalDocument46 pagesBasics of Multivariate NormalSayan GuptaNo ratings yet
- Correlations For Swelling Pressure From PI PL ResultsDocument65 pagesCorrelations For Swelling Pressure From PI PL ResultsSheril ChandraboseNo ratings yet
- Statistics For Business and Economics: Bab 14Document31 pagesStatistics For Business and Economics: Bab 14baloNo ratings yet
- Correlation and RegressionDocument11 pagesCorrelation and RegressiongdayanandamNo ratings yet
- Chen 2015 The Correlations Between Learner Autonomy and TheDocument15 pagesChen 2015 The Correlations Between Learner Autonomy and The20202 ENG114A08No ratings yet
- ReportDocument13 pagesReportshubham rathiNo ratings yet
- Factors Affecting Accuracy of Pre-Tender Cost Estimate PDFDocument9 pagesFactors Affecting Accuracy of Pre-Tender Cost Estimate PDFyash shahNo ratings yet
- Effect of Glass Ceiling On The Performance of Women Employees in Service SectorDocument8 pagesEffect of Glass Ceiling On The Performance of Women Employees in Service SectorMuhammad Shehroz HirajNo ratings yet
- Balance Vs Unbalance BidDocument7 pagesBalance Vs Unbalance BidBhanuNo ratings yet
- Predicting FCC Catalyst Particle DensityDocument6 pagesPredicting FCC Catalyst Particle Densityrameshkarthik810No ratings yet








































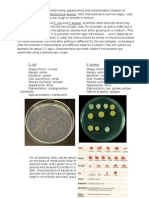






























































Download as pdf or txt
You might also like
- Homework 3Document7 pagesHomework 3Alexis R. CamargoNo ratings yet
- Divya.v Project Final 1Document41 pagesDivya.v Project Final 1Karthi KeyanNo ratings yet
- Episode 1028: Algal Blooms On Lake SuperiorDocument12 pagesEpisode 1028: Algal Blooms On Lake SuperiorGreat Lakes NowNo ratings yet
- EBX 041 192 - FT - EurobioPlex SARS CoV 2 Multiplex - EN - v4.00 - 20 04 20202 PDFDocument17 pagesEBX 041 192 - FT - EurobioPlex SARS CoV 2 Multiplex - EN - v4.00 - 20 04 20202 PDFAncapc AncapcNo ratings yet
- Read Me GenAlEx 6.41Document10 pagesRead Me GenAlEx 6.41ParkNo ratings yet
- 09931158A Burner System Users Guide PDFDocument128 pages09931158A Burner System Users Guide PDFkariliz15No ratings yet
- Study Set 2Document11 pagesStudy Set 2Ammara RasheedNo ratings yet
- University Paper SolutionsDocument132 pagesUniversity Paper Solutionskane daveNo ratings yet
- Analysis of Variation of Water Quality in Kelani River, Sri LankaDocument6 pagesAnalysis of Variation of Water Quality in Kelani River, Sri LankaIJEAB JournalNo ratings yet
- r7210105 SurveyingDocument4 pagesr7210105 SurveyingsivabharathamurthyNo ratings yet
- Icasi 2018 Sonproceedingve Ozet KitabcigiDocument726 pagesIcasi 2018 Sonproceedingve Ozet KitabcigiIlo Ruiz100% (1)
- Methods of PhytoremediationDocument7 pagesMethods of PhytoremediationIan KirkNo ratings yet
- 4 (Evapotranspiration)Document33 pages4 (Evapotranspiration)Lim Shwe WenNo ratings yet
- Avant-Pays de La Meseta MarocaineDocument7 pagesAvant-Pays de La Meseta MarocaineIMMELOUI MohamedNo ratings yet
- Contact Angle MeasurementsDocument7 pagesContact Angle MeasurementsThoifah MuthohharohNo ratings yet
- Blast Vs FastaDocument3 pagesBlast Vs FastaAhmad Faraz KhanNo ratings yet
- Indice JaccardDocument12 pagesIndice JaccardMelinte AlexandruNo ratings yet
- English2as Project-Noble PriceDocument23 pagesEnglish2as Project-Noble Priceالتداوي بالاعشاب الطبية ببراقيNo ratings yet
- Solution Sheets AcetoorceinDocument1 pageSolution Sheets AcetoorceinsaputraalamNo ratings yet
- Modelling and Mapping of Water Erosion Risk by Application of The GIS and PAP/RAC Guidelines in The Watershed of Oued Zgane (Middle Atlas Morocco)Document17 pagesModelling and Mapping of Water Erosion Risk by Application of The GIS and PAP/RAC Guidelines in The Watershed of Oued Zgane (Middle Atlas Morocco)Oualid HakamNo ratings yet
- PhytoremediationDocument42 pagesPhytoremediationSeroKeretaMasaroWidiarNo ratings yet
- Nano AdsorbantsDocument6 pagesNano AdsorbantsDl Al-aziz0% (1)
- SIAL QPCR Technical Guide PDFDocument42 pagesSIAL QPCR Technical Guide PDFiuventas100% (1)
- Disinfection: University Curriculum Development For Decentralized Wastewater ManagementDocument35 pagesDisinfection: University Curriculum Development For Decentralized Wastewater ManagementLTE002No ratings yet
- Prediction of Performance Efficiency For Wastewater Treatment Plant's Effluent Biochemical Oxygen Demand Using Artificial Neural NetworkDocument11 pagesPrediction of Performance Efficiency For Wastewater Treatment Plant's Effluent Biochemical Oxygen Demand Using Artificial Neural NetworkInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Pressure-Driven Cavitating Flow of Water Through A Sharp-Edged OrificeDocument13 pagesPressure-Driven Cavitating Flow of Water Through A Sharp-Edged OrificeKaushika Rajapaksha PereraNo ratings yet
- Apricot Diseases Diagnostic Key PDFDocument2 pagesApricot Diseases Diagnostic Key PDFkhouchaymiNo ratings yet
- Bio RemediationDocument24 pagesBio RemediationMinhaj HaiderNo ratings yet
- 2.2.46. Chromatographic Separation TechniquesDocument5 pages2.2.46. Chromatographic Separation TechniquesFemmes RêveurNo ratings yet
- Molecular Mechanisms of Insecticide ResistanceDocument11 pagesMolecular Mechanisms of Insecticide ResistancejoharijalinasNo ratings yet
- Detection of Integrons in Multidrug Resistant Wound IsolatesDocument7 pagesDetection of Integrons in Multidrug Resistant Wound IsolatesEditor IJTSRDNo ratings yet
- Systematic Bacteriology: The and The Deeply Branching and PhototrophicDocument18 pagesSystematic Bacteriology: The and The Deeply Branching and PhototrophicMuhammad JamalNo ratings yet
- 2013 Exposed GM Covers - OthmanDocument16 pages2013 Exposed GM Covers - OthmanSebas MoraNo ratings yet
- Atmospheric Pollution Paper Sci & Eng.)Document6 pagesAtmospheric Pollution Paper Sci & Eng.)akaj188No ratings yet
- Thesis Lid DrivenDocument145 pagesThesis Lid DrivenEddieq100% (1)
- Standard Procedure For Luminescence Vibrio FischeriDocument14 pagesStandard Procedure For Luminescence Vibrio FischeriCarlos DiazNo ratings yet
- The Benefits of Industrial SymbiosisDocument33 pagesThe Benefits of Industrial Symbiosisrobotrobot13No ratings yet
- Analyse Bacterologique de L EauDocument6 pagesAnalyse Bacterologique de L Eaupeguy diffoNo ratings yet
- Phytodegradation: Figure 1. Destruction of Organic Contaminants by PhytodegradationDocument5 pagesPhytodegradation: Figure 1. Destruction of Organic Contaminants by PhytodegradationChescaMendioroNo ratings yet
- Biocementation and BiocementsDocument30 pagesBiocementation and BiocementscarloscarinelliNo ratings yet
- Bacteria Colony Appearance MorphologyDocument2 pagesBacteria Colony Appearance MorphologyMonique Lopes da SilvaNo ratings yet
- Goodchild - Geographic Information Systems and ScienceDocument13 pagesGoodchild - Geographic Information Systems and ScienceIhkmuyalNo ratings yet
- Antioxidant Properties of Various Solvent Extracts of Total Phenolic Constituents From Three Different Agroclimatic Origins of Drumstick Tree (Moringa Oleifera Lam.) LeavesDocument12 pagesAntioxidant Properties of Various Solvent Extracts of Total Phenolic Constituents From Three Different Agroclimatic Origins of Drumstick Tree (Moringa Oleifera Lam.) LeavesMeiNo ratings yet
- Ultracentrifugation: June 2010Document8 pagesUltracentrifugation: June 2010Nayak Alok RanjanNo ratings yet
- The Titration of Clay MineralsDocument10 pagesThe Titration of Clay MineralsroyamohamadyNo ratings yet
- Boomer and Attwood 2007Document9 pagesBoomer and Attwood 2007Raphael ZilligNo ratings yet
- Biosensors - Analytical DeviceDocument4 pagesBiosensors - Analytical DeviceJournal 4 ResearchNo ratings yet
- How Do You Calculate The Sensitivity in A Voltammetry AnalysisDocument11 pagesHow Do You Calculate The Sensitivity in A Voltammetry AnalysisElbahi DjaalabNo ratings yet
- Kla DeterminationDocument23 pagesKla DeterminationJokanoe LertNo ratings yet
- Boublenza2019 Caroubier AlgérieDocument8 pagesBoublenza2019 Caroubier AlgérieNàzim Jorden100% (1)
- Design of Landfill Daily CellsDocument12 pagesDesign of Landfill Daily CellsKaustav PatnaikNo ratings yet
- 4006oral Solutions, Syrups, & ElixirsDocument83 pages4006oral Solutions, Syrups, & ElixirsOctavio Cardenas OrozcoNo ratings yet
- LC-MSMS (En)Document69 pagesLC-MSMS (En)LựuLiềuLìNo ratings yet
- Nienow 1998 Hydrodynamics in Stirred Bioreactors.Document31 pagesNienow 1998 Hydrodynamics in Stirred Bioreactors.AlbertoNo ratings yet
- NEW Annex 7 Qualification of Mass Spectrometers PDFDocument11 pagesNEW Annex 7 Qualification of Mass Spectrometers PDFParkhomyukNo ratings yet
- Phonopy Tips 2014Document48 pagesPhonopy Tips 2014anibrataNo ratings yet
- Hinotek FP640 Flamephotometer ManualDocument17 pagesHinotek FP640 Flamephotometer ManualKader SmailiNo ratings yet
- Manual 5800 Agilent ICP-OESDocument66 pagesManual 5800 Agilent ICP-OESdqrocha_ifamNo ratings yet
- Modeling of The Bacterial Growth Curve.Document7 pagesModeling of The Bacterial Growth Curve.Adrian Bermudez LoeraNo ratings yet
- Protein Purification HandbookDocument94 pagesProtein Purification HandbookDolphingNo ratings yet
- Slab Planar: Charged Species Migration Rate Electric FieldDocument15 pagesSlab Planar: Charged Species Migration Rate Electric FieldEng Leng LeeNo ratings yet
- Deü Mühendislik Fakültesi Fen Ve Mühendislik DergisiDocument12 pagesDeü Mühendislik Fakültesi Fen Ve Mühendislik DergisiDomingos BernardoNo ratings yet
- Spss Şeref KalaycıDocument6 pagesSpss Şeref KalaycıNes HanNo ratings yet
- X X X X N X N: 1. Discuss/define Three Measures of Central TendencyDocument7 pagesX X X X N X N: 1. Discuss/define Three Measures of Central TendencyPandurang ThatkarNo ratings yet
- Stress and GPA: Analysis of The Initial Administration of A New Instrument For Measuring Stress and Its Relationship To College GPADocument25 pagesStress and GPA: Analysis of The Initial Administration of A New Instrument For Measuring Stress and Its Relationship To College GPAPandurang ThatkarNo ratings yet
- Responses Week2Document2 pagesResponses Week2Pandurang ThatkarNo ratings yet
- OThompson Wk5AssgnOThompson CorrectedDocument12 pagesOThompson Wk5AssgnOThompson CorrectedPandurang ThatkarNo ratings yet
- Field-Scale Monitoring of The Long-Term Impact and Sustainability of Drainage Water Reuse On The West Side of California's San Joaquin ValleyDocument12 pagesField-Scale Monitoring of The Long-Term Impact and Sustainability of Drainage Water Reuse On The West Side of California's San Joaquin ValleyPandurang ThatkarNo ratings yet
- Omar Thompson Week2 Discussion1Document2 pagesOmar Thompson Week2 Discussion1Pandurang ThatkarNo ratings yet
- New Data Internet UsageDocument6 pagesNew Data Internet UsagePandurang ThatkarNo ratings yet
- Regression Analysis ANOVA Results SS DF MS F PDocument4 pagesRegression Analysis ANOVA Results SS DF MS F PPandurang ThatkarNo ratings yet
- Q.1 From The Histogram, We Observe That The Rod Diameter Is Approximately Normally DistributedDocument5 pagesQ.1 From The Histogram, We Observe That The Rod Diameter Is Approximately Normally DistributedPandurang ThatkarNo ratings yet
- Generating A Binomial Distribution With Parameters N 10 and P 0.63Document4 pagesGenerating A Binomial Distribution With Parameters N 10 and P 0.63Pandurang ThatkarNo ratings yet
- Question: Is The Graduation Rate Higher at Hbcus or Non-Hbcus For Women Compared To Men?Document5 pagesQuestion: Is The Graduation Rate Higher at Hbcus or Non-Hbcus For Women Compared To Men?Pandurang ThatkarNo ratings yet
- Homework 2Document4 pagesHomework 2Pandurang ThatkarNo ratings yet
- Discussion Week 6: Williams, 1998)Document2 pagesDiscussion Week 6: Williams, 1998)Pandurang ThatkarNo ratings yet
- Discussion Week2:: For Texture Classification," 3rd International Workshop On Texture Analysis and SynthesisDocument1 pageDiscussion Week2:: For Texture Classification," 3rd International Workshop On Texture Analysis and SynthesisPandurang ThatkarNo ratings yet
- CorrectionsDocument4 pagesCorrectionsPandurang ThatkarNo ratings yet
- Parental Attitude Research Instrument: Attitude An Approach To Use QuestionnairesDocument6 pagesParental Attitude Research Instrument: Attitude An Approach To Use QuestionnairesMaya MayaNo ratings yet
- Leadership Style and Its Impact On Employee PerformanceDocument15 pagesLeadership Style and Its Impact On Employee PerformanceSophia Illescas GallardoNo ratings yet
- Industrial Needs On English Skills of New Employees: A SurveyDocument13 pagesIndustrial Needs On English Skills of New Employees: A Surveyonly humanNo ratings yet
- Chapter - Ii Review of Related LiteratureDocument28 pagesChapter - Ii Review of Related LiteratureAmrit VallahNo ratings yet
- G Power ManualDocument78 pagesG Power ManualLavinia Stupariu100% (1)
- Estimating IBNR Claims Reserves For General InsuraDocument20 pagesEstimating IBNR Claims Reserves For General InsuraWael TrabelsiNo ratings yet
- Thomas-Fiering Model For The Sequential Generation of Stream FlowDocument26 pagesThomas-Fiering Model For The Sequential Generation of Stream Flowyahya100% (3)
- SPPU Solved Question Papers MCQ Unit 5Document18 pagesSPPU Solved Question Papers MCQ Unit 5Anonymous XTL7o0tGo90% (2)
- Code STAT Course DetailsDocument49 pagesCode STAT Course Detailsfazalulbasit9796No ratings yet
- Mss 202 Practice 19-20Document2 pagesMss 202 Practice 19-20fayinminu oluwaniyiNo ratings yet
- Curriculum OF Botany: BS (4-YEAR)Document91 pagesCurriculum OF Botany: BS (4-YEAR)Abas92No ratings yet
- Optimising Sampling Techniques and Estimating Sampling Variance of Fleece Quality Attributes in AlpacasDocument12 pagesOptimising Sampling Techniques and Estimating Sampling Variance of Fleece Quality Attributes in AlpacasRenato Jesus Cordova GarciaNo ratings yet
- Panel Ecmiic2Document57 pagesPanel Ecmiic2wjimenez1938No ratings yet
- Spss ExercisesDocument13 pagesSpss Exercisesishfaq khan315No ratings yet
- Risk Identification & MeasurementDocument24 pagesRisk Identification & Measurementvmtripathi0967% (3)
- Effectiveness of Jacobson'S Progressive Muscle Relaxation (JPMR) Technique On Social Anxiety Among High School Adolescents in A Selected School of Udupi District, Karnataka StateDocument5 pagesEffectiveness of Jacobson'S Progressive Muscle Relaxation (JPMR) Technique On Social Anxiety Among High School Adolescents in A Selected School of Udupi District, Karnataka StateSidharth PraveenNo ratings yet
- Word-Patterns and Story-Shapes: The Statistical Analysis of Narrative StyleDocument10 pagesWord-Patterns and Story-Shapes: The Statistical Analysis of Narrative StyleAdemar JúniorNo ratings yet
- Basics of Multivariate NormalDocument46 pagesBasics of Multivariate NormalSayan GuptaNo ratings yet
- Correlations For Swelling Pressure From PI PL ResultsDocument65 pagesCorrelations For Swelling Pressure From PI PL ResultsSheril ChandraboseNo ratings yet
- Statistics For Business and Economics: Bab 14Document31 pagesStatistics For Business and Economics: Bab 14baloNo ratings yet
- Correlation and RegressionDocument11 pagesCorrelation and RegressiongdayanandamNo ratings yet
- Chen 2015 The Correlations Between Learner Autonomy and TheDocument15 pagesChen 2015 The Correlations Between Learner Autonomy and The20202 ENG114A08No ratings yet
- ReportDocument13 pagesReportshubham rathiNo ratings yet
- Factors Affecting Accuracy of Pre-Tender Cost Estimate PDFDocument9 pagesFactors Affecting Accuracy of Pre-Tender Cost Estimate PDFyash shahNo ratings yet
- Effect of Glass Ceiling On The Performance of Women Employees in Service SectorDocument8 pagesEffect of Glass Ceiling On The Performance of Women Employees in Service SectorMuhammad Shehroz HirajNo ratings yet
- Balance Vs Unbalance BidDocument7 pagesBalance Vs Unbalance BidBhanuNo ratings yet
- Predicting FCC Catalyst Particle DensityDocument6 pagesPredicting FCC Catalyst Particle Densityrameshkarthik810No ratings yet