
Backup Excerpt 5.0 Mysql
Backup Excerpt 5.0 Mysql
You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5835)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1093)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (852)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (903)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (541)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (350)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (824)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (405)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- Unit 4 Notes PDFDocument27 pagesUnit 4 Notes PDFBef100% (2)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- SELECT Last - Name, Job - Id, Salary AS Sal From Employees True/FalseDocument3 pagesSELECT Last - Name, Job - Id, Salary AS Sal From Employees True/FalseZara sutoNo ratings yet
- Software and System Quality: Assignment # 2Document2 pagesSoftware and System Quality: Assignment # 2komalNo ratings yet
- Modeler - Customer PresentationDocument111 pagesModeler - Customer Presentationvendetta6546No ratings yet
- Database Group AssignmentDocument34 pagesDatabase Group Assignmentbudhah282No ratings yet
- Prelim Lab Exam - Database Manage SystemsDocument5 pagesPrelim Lab Exam - Database Manage SystemsKenneth Allen CagandaNo ratings yet
- Hasura BasicsDocument89 pagesHasura BasicstrungtrungkangNo ratings yet
- CP264 A8 AssignmentDocument3 pagesCP264 A8 AssignmentKimara DesantoNo ratings yet
- Embedding SQL Server 2008 Express in An Application - Microsoft Learn PDFDocument36 pagesEmbedding SQL Server 2008 Express in An Application - Microsoft Learn PDFÂngelo Afonso Sebastião BarataNo ratings yet
- DataStage Tip For Beginners - Parallel Lookup TypesDocument6 pagesDataStage Tip For Beginners - Parallel Lookup Typessathishreddy9867No ratings yet
- deVCBAdMRRKlQgQHTHUSAw - Course 1 Week 4 Glossary - DA Terms and Definitions 1Document4 pagesdeVCBAdMRRKlQgQHTHUSAw - Course 1 Week 4 Glossary - DA Terms and Definitions 1Nguyen Hoang Ngoc HaNo ratings yet
- Tibco Pallets1Document28 pagesTibco Pallets1Ask SatwaliyaNo ratings yet
- 3PAR DISK MatrixDocument6 pages3PAR DISK MatrixShaun PhelpsNo ratings yet
- Restore CommandDocument6 pagesRestore CommandRajeshNo ratings yet
- Master Data Management Use CaseDocument1 pageMaster Data Management Use Casekoizak3No ratings yet
- BLANK - SEMrush On-Page SEO Template - Make A Copy To EditDocument287 pagesBLANK - SEMrush On-Page SEO Template - Make A Copy To Editsantosh kumar0% (1)
- Aberdeen Research Report Big Data AnalyticsDocument11 pagesAberdeen Research Report Big Data AnalyticsRosie3k90% (1)
- Settings ProviderDocument42 pagesSettings ProviderDiana MartinezNo ratings yet
- Adding New Drives To Unixware 7 SystemDocument7 pagesAdding New Drives To Unixware 7 SystemCalwyn BaldwinNo ratings yet
- Usb Dsc5 ManualDocument20 pagesUsb Dsc5 ManualEsteban Delgado MonteroNo ratings yet
- Nebra Helium Miner EMMC SD UpgradeDocument8 pagesNebra Helium Miner EMMC SD UpgradeCarlos CandelaNo ratings yet
- Data Structures NotesDocument2 pagesData Structures NotesIeuan MorrisNo ratings yet
- Storage For DBAsDocument575 pagesStorage For DBAskarmjit09No ratings yet
- Database Foundations 3-3: Normalization and Business Rules PracticesDocument5 pagesDatabase Foundations 3-3: Normalization and Business Rules Practiceslalit sharmaNo ratings yet
- Single Sign On - ServiceNowDocument7 pagesSingle Sign On - ServiceNowammuluNo ratings yet
- 154 - DM Bok 2: 2.2.1.2.1 Analyze Information RequirementsDocument157 pages154 - DM Bok 2: 2.2.1.2.1 Analyze Information Requirementsalexander acostaNo ratings yet
- Create SQLserver LoginDocument3 pagesCreate SQLserver LogintebikachewNo ratings yet
- Deepanshi Dube Gaurav Kalra SakshiDocument32 pagesDeepanshi Dube Gaurav Kalra SakshiNishkam ChoudhryNo ratings yet
- AWS Certified SysOps Administrator Associate - Sample QuestionsDocument9 pagesAWS Certified SysOps Administrator Associate - Sample QuestionsAngga Alpa WibowoNo ratings yet
- MS Power BI - 2 DaysDocument3 pagesMS Power BI - 2 DaysSmriti ShahNo ratings yet





























































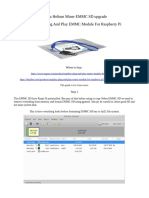









Download as pdf or txt
You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5835)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1093)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (852)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (903)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (541)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (350)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (824)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (405)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- Unit 4 Notes PDFDocument27 pagesUnit 4 Notes PDFBef100% (2)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- SELECT Last - Name, Job - Id, Salary AS Sal From Employees True/FalseDocument3 pagesSELECT Last - Name, Job - Id, Salary AS Sal From Employees True/FalseZara sutoNo ratings yet
- Software and System Quality: Assignment # 2Document2 pagesSoftware and System Quality: Assignment # 2komalNo ratings yet
- Modeler - Customer PresentationDocument111 pagesModeler - Customer Presentationvendetta6546No ratings yet
- Database Group AssignmentDocument34 pagesDatabase Group Assignmentbudhah282No ratings yet
- Prelim Lab Exam - Database Manage SystemsDocument5 pagesPrelim Lab Exam - Database Manage SystemsKenneth Allen CagandaNo ratings yet
- Hasura BasicsDocument89 pagesHasura BasicstrungtrungkangNo ratings yet
- CP264 A8 AssignmentDocument3 pagesCP264 A8 AssignmentKimara DesantoNo ratings yet
- Embedding SQL Server 2008 Express in An Application - Microsoft Learn PDFDocument36 pagesEmbedding SQL Server 2008 Express in An Application - Microsoft Learn PDFÂngelo Afonso Sebastião BarataNo ratings yet
- DataStage Tip For Beginners - Parallel Lookup TypesDocument6 pagesDataStage Tip For Beginners - Parallel Lookup Typessathishreddy9867No ratings yet
- deVCBAdMRRKlQgQHTHUSAw - Course 1 Week 4 Glossary - DA Terms and Definitions 1Document4 pagesdeVCBAdMRRKlQgQHTHUSAw - Course 1 Week 4 Glossary - DA Terms and Definitions 1Nguyen Hoang Ngoc HaNo ratings yet
- Tibco Pallets1Document28 pagesTibco Pallets1Ask SatwaliyaNo ratings yet
- 3PAR DISK MatrixDocument6 pages3PAR DISK MatrixShaun PhelpsNo ratings yet
- Restore CommandDocument6 pagesRestore CommandRajeshNo ratings yet
- Master Data Management Use CaseDocument1 pageMaster Data Management Use Casekoizak3No ratings yet
- BLANK - SEMrush On-Page SEO Template - Make A Copy To EditDocument287 pagesBLANK - SEMrush On-Page SEO Template - Make A Copy To Editsantosh kumar0% (1)
- Aberdeen Research Report Big Data AnalyticsDocument11 pagesAberdeen Research Report Big Data AnalyticsRosie3k90% (1)
- Settings ProviderDocument42 pagesSettings ProviderDiana MartinezNo ratings yet
- Adding New Drives To Unixware 7 SystemDocument7 pagesAdding New Drives To Unixware 7 SystemCalwyn BaldwinNo ratings yet
- Usb Dsc5 ManualDocument20 pagesUsb Dsc5 ManualEsteban Delgado MonteroNo ratings yet
- Nebra Helium Miner EMMC SD UpgradeDocument8 pagesNebra Helium Miner EMMC SD UpgradeCarlos CandelaNo ratings yet
- Data Structures NotesDocument2 pagesData Structures NotesIeuan MorrisNo ratings yet
- Storage For DBAsDocument575 pagesStorage For DBAskarmjit09No ratings yet
- Database Foundations 3-3: Normalization and Business Rules PracticesDocument5 pagesDatabase Foundations 3-3: Normalization and Business Rules Practiceslalit sharmaNo ratings yet
- Single Sign On - ServiceNowDocument7 pagesSingle Sign On - ServiceNowammuluNo ratings yet
- 154 - DM Bok 2: 2.2.1.2.1 Analyze Information RequirementsDocument157 pages154 - DM Bok 2: 2.2.1.2.1 Analyze Information Requirementsalexander acostaNo ratings yet
- Create SQLserver LoginDocument3 pagesCreate SQLserver LogintebikachewNo ratings yet
- Deepanshi Dube Gaurav Kalra SakshiDocument32 pagesDeepanshi Dube Gaurav Kalra SakshiNishkam ChoudhryNo ratings yet
- AWS Certified SysOps Administrator Associate - Sample QuestionsDocument9 pagesAWS Certified SysOps Administrator Associate - Sample QuestionsAngga Alpa WibowoNo ratings yet
- MS Power BI - 2 DaysDocument3 pagesMS Power BI - 2 DaysSmriti ShahNo ratings yet