Download as pdf or txt
You might also like
- Wiley - Solution Manual To Accompany Volume I of Quantum Mechanics by Cohen-Tannoudji, Diu and LaloË - 978!3!527-41422-2Document2 pagesWiley - Solution Manual To Accompany Volume I of Quantum Mechanics by Cohen-Tannoudji, Diu and LaloË - 978!3!527-41422-2ilmamartinsvenancio0% (2)
- IIT Kanpur Machine Learning End Sem PaperDocument10 pagesIIT Kanpur Machine Learning End Sem PaperJivnesh SandhanNo ratings yet
- Stats216 hw2Document21 pagesStats216 hw2Alex NutkiewiczNo ratings yet
- Sas SurDocument9 pagesSas SurSuryatna Saca DibrataNo ratings yet
- Regression With Qualitative InformationDocument25 pagesRegression With Qualitative InformationajayikayodeNo ratings yet
- Bayesian Analysis of Spatially Autocorrelated Data Spatial Data Analysis in Ecology and Agriculture Using RDocument18 pagesBayesian Analysis of Spatially Autocorrelated Data Spatial Data Analysis in Ecology and Agriculture Using Raletheia_aiehtelaNo ratings yet
- Illustration of Using Excel To Find Maximum Likelihood EstimatesDocument14 pagesIllustration of Using Excel To Find Maximum Likelihood EstimatesRustam MuhammadNo ratings yet
- Logistic Regression (With R) : 1 TheoryDocument15 pagesLogistic Regression (With R) : 1 TheoryrattonxNo ratings yet
- RegressionDocument46 pagesRegressionGiannis GalanakisNo ratings yet
- Assignment On Probit ModelDocument17 pagesAssignment On Probit ModelNidhi KaushikNo ratings yet
- Lab Experiment 4 - AIDocument7 pagesLab Experiment 4 - AIMUHAMMAD FAHEEMNo ratings yet
- ECN102 FNSample IIDocument9 pagesECN102 FNSample IIakinagakiNo ratings yet
- Sta NotesDocument44 pagesSta NotesManshal BrohiNo ratings yet
- R Code For Linear Regression Analysis 1 Way ANOVADocument8 pagesR Code For Linear Regression Analysis 1 Way ANOVAHagos TsegayNo ratings yet
- Diagnostico de ModelosDocument4 pagesDiagnostico de Modeloskhayman.gpNo ratings yet
- EC221 답 지운 것Document99 pagesEC221 답 지운 것이찬호No ratings yet
- Points For Session 4 - UpdatedDocument9 pagesPoints For Session 4 - Updatedpresi_studentNo ratings yet
- Lab 4 Classification v.0Document5 pagesLab 4 Classification v.0rusoNo ratings yet
- Lab 4: Logistic Regression: PSTAT 131/231, Winter 2019Document10 pagesLab 4: Logistic Regression: PSTAT 131/231, Winter 2019vidish laheriNo ratings yet
- Second Course in Statistics Regression Analysis 7th Edition Mendenhall Solutions ManualDocument11 pagesSecond Course in Statistics Regression Analysis 7th Edition Mendenhall Solutions Manualdulcitetutsanz9u100% (20)
- Econometrics I Final Examination Summer Term 2013, July 26, 2013Document9 pagesEconometrics I Final Examination Summer Term 2013, July 26, 2013ECON1717No ratings yet
- Solutions Matlab Mod2Document3 pagesSolutions Matlab Mod2Jorge VicenteNo ratings yet
- Supplement To Chapter 2 - Probability and StatisticsDocument34 pagesSupplement To Chapter 2 - Probability and StatisticstemedebereNo ratings yet
- Rss Grad Diploma Module4 Solutions Specimen B PDFDocument16 pagesRss Grad Diploma Module4 Solutions Specimen B PDFA PirzadaNo ratings yet
- Exam 1 Spring 2023 DonaldDocument8 pagesExam 1 Spring 2023 DonaldGeoffrey WuNo ratings yet
- Multinomial Logistic Regression - Spss Data Analysis ExamplesDocument1 pageMultinomial Logistic Regression - Spss Data Analysis ExamplesSuravi MalingaNo ratings yet
- Cheat Sheet FinalDocument7 pagesCheat Sheet Finalkookmasteraj100% (2)
- TutorialDocument11 pagesTutorialAkbarMuammarNo ratings yet
- Regression Analysis: Kriti Bardhan Gupta Kriti@iiml - Ac.inDocument16 pagesRegression Analysis: Kriti Bardhan Gupta Kriti@iiml - Ac.inPavan PearliNo ratings yet
- Assignment R New 1Document26 pagesAssignment R New 1Sohel RanaNo ratings yet
- Final ExamDocument2 pagesFinal ExamMeliha Paloš100% (1)
- EcotrixDocument8 pagesEcotrixzuhanshaikNo ratings yet
- Vcd4 Handout 2x2Document20 pagesVcd4 Handout 2x2juntujuntuNo ratings yet
- Ps6sol Fa13 PDFDocument15 pagesPs6sol Fa13 PDFchan chadoNo ratings yet
- Appendix Nonlinear RegressionDocument5 pagesAppendix Nonlinear RegressionSanjay KumarNo ratings yet
- Solutionbank S1: Edexcel AS and A Level Modular MathematicsDocument23 pagesSolutionbank S1: Edexcel AS and A Level Modular MathematicsTechKMHNo ratings yet
- StudyQuestions Regression (Logarithms)Document21 pagesStudyQuestions Regression (Logarithms)master8875No ratings yet
- IGNOU MBA MS - 08 Solved Assignments 2011Document12 pagesIGNOU MBA MS - 08 Solved Assignments 2011Manoj SharmaNo ratings yet
- Statbis TutorDocument7 pagesStatbis TutorFidelis Permana SidiNo ratings yet
- Simple Regression Model FittingDocument5 pagesSimple Regression Model FittingAparna SinghNo ratings yet
- 2015 Preparatory Notes: Australian Chemistry Olympiad (Acho)Document44 pages2015 Preparatory Notes: Australian Chemistry Olympiad (Acho)kevNo ratings yet
- A Review of Basic Statistical Concepts: Answers To Problems and Cases 1Document94 pagesA Review of Basic Statistical Concepts: Answers To Problems and Cases 1Terry ReynaldoNo ratings yet
- DS 432 Assignment I 2020Document7 pagesDS 432 Assignment I 2020sristi agrawalNo ratings yet
- Topic 1 Numerical MeasureDocument11 pagesTopic 1 Numerical MeasureNedal AbuzwidaNo ratings yet
- Homework Index: To See If The Questions Have Been Changed, or If You Are Required To Use Different Data or ExamplesDocument86 pagesHomework Index: To See If The Questions Have Been Changed, or If You Are Required To Use Different Data or ExamplesasNo ratings yet
- Parameter EstimationDocument24 pagesParameter EstimationMina Arya100% (1)
- Braun Bootstrap2012 PDFDocument63 pagesBraun Bootstrap2012 PDFJoe OgleNo ratings yet
- UNIT 3 Dimentionality Problems and Nonparametic Pattern ClassificationDocument18 pagesUNIT 3 Dimentionality Problems and Nonparametic Pattern ClassificationKalyanNo ratings yet
- Multinomial Logistic Regression Models: Newsom Psy 525/625 Categorical Data Analysis, Spring 2021 1Document5 pagesMultinomial Logistic Regression Models: Newsom Psy 525/625 Categorical Data Analysis, Spring 2021 1Deo TuremeNo ratings yet
- TA ZC142 Computer Programming Date: 16/01/2013Document41 pagesTA ZC142 Computer Programming Date: 16/01/2013rajpd28No ratings yet
- Quiz1 Solutions Quiz 1 SolnDocument7 pagesQuiz1 Solutions Quiz 1 Solnhasna.nafirNo ratings yet
- Bisection MethodDocument20 pagesBisection MethodAnonymous J8phVjlxPxNo ratings yet
- Tugas Ridho 2.100-2.102Document9 pagesTugas Ridho 2.100-2.102Feby MutiaNo ratings yet
- Quiz Feedback 1Document5 pagesQuiz Feedback 1ashutosh karkiNo ratings yet
- Mid Term UmtDocument4 pagesMid Term Umtfazalulbasit9796No ratings yet
- Lab 01 Bisection Regula-Falsi and Newton-RaphsonDocument12 pagesLab 01 Bisection Regula-Falsi and Newton-RaphsonUmair Ali ShahNo ratings yet
- Multinomial Logistic Regression - R Data Analysis Examples - IDRE StatsDocument8 pagesMultinomial Logistic Regression - R Data Analysis Examples - IDRE StatsDina NadhirahNo ratings yet
- Perspectives On System IdentificationDocument13 pagesPerspectives On System Identificationsahar100% (1)
- Essentials of Statistics 4th Edition Triola Solutions ManualDocument29 pagesEssentials of Statistics 4th Edition Triola Solutions ManualDebraFloresotzax100% (11)
- Experimental Design Capt 1Document19 pagesExperimental Design Capt 1vsuarezf2732No ratings yet
- DOE Course Part 14Document21 pagesDOE Course Part 14vsuarezf2732No ratings yet
- PoissonDocument1 pagePoissonvsuarezf2732No ratings yet
- GEEDocument76 pagesGEEvsuarezf2732No ratings yet
- Table 1 (A) : Number of Holdings, Operated Area and Average Size of Holdings - All Social GroupsDocument3 pagesTable 1 (A) : Number of Holdings, Operated Area and Average Size of Holdings - All Social Groupsvsuarezf2732No ratings yet
- Matrix Genetics RDocument28 pagesMatrix Genetics Rvsuarezf2732No ratings yet
- Linear ProgrammingDocument26 pagesLinear Programmingvsuarezf2732100% (1)
- Qualitative MethodsDocument7 pagesQualitative Methodsvsuarezf2732No ratings yet
- OFC Farmer Science SurveyDocument107 pagesOFC Farmer Science Surveyvsuarezf2732No ratings yet
- LNS2 Paper 3 Slides London FINALDocument19 pagesLNS2 Paper 3 Slides London FINALvsuarezf2732No ratings yet
- Journal of Statistical SoftwareDocument10 pagesJournal of Statistical Softwarevsuarezf2732No ratings yet
- TransposeDocument1 pageTransposevsuarezf2732No ratings yet
- Extracting Intraday Price Quotes From TAQ Database in WRDS Using SASDocument7 pagesExtracting Intraday Price Quotes From TAQ Database in WRDS Using SASvsuarezf2732No ratings yet
- Dwl-7100ap Qig en UkDocument7 pagesDwl-7100ap Qig en Ukvsuarezf2732No ratings yet
- An Introduction To GUI Programming Using RDocument25 pagesAn Introduction To GUI Programming Using Rvsuarezf2732No ratings yet
- HP Consumibles LaserDocument9 pagesHP Consumibles Laservsuarezf2732No ratings yet
- Delhi University Notes 2ND Semester Real NalysisDocument18 pagesDelhi University Notes 2ND Semester Real NalysisSanjeev Shukla75% (4)
- The Four TemperamentsDocument3 pagesThe Four TemperamentsAlina RNo ratings yet
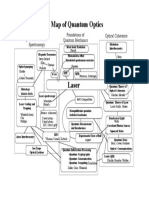
- Map of Quantum Optics PDFDocument1 pageMap of Quantum Optics PDFInuk YouNo ratings yet
- MMW M6 Check-In-Activity2Document3 pagesMMW M6 Check-In-Activity2Romyelle AmparoNo ratings yet
- Nuraini Wikanti (22016026) - Independent Learning 5Document5 pagesNuraini Wikanti (22016026) - Independent Learning 5nuraini wikantiNo ratings yet
- Finals Demeterio and Panganiban II 12Document20 pagesFinals Demeterio and Panganiban II 12Jha Jha CaLvezNo ratings yet
- Chi-Square Test: Amaresh Baranwal - 2021301073 Pratham Maner - 2021301074Document14 pagesChi-Square Test: Amaresh Baranwal - 2021301073 Pratham Maner - 2021301074Ash KNo ratings yet
- INGLISHDocument4 pagesINGLISHsahard castilloNo ratings yet
- The Modes of Natural SelectionDocument4 pagesThe Modes of Natural SelectionYam YamNo ratings yet
- Face Negotiation Theory (Stella Ting-Toomey) - SimplifiedDocument3 pagesFace Negotiation Theory (Stella Ting-Toomey) - SimplifiedRajesh Cheemalakonda100% (1)
- PyCon 2015 - Bayesian Statistics Made SimpleDocument145 pagesPyCon 2015 - Bayesian Statistics Made SimpleJay Mj100% (4)
- Broken Symmetry PDFDocument2 pagesBroken Symmetry PDFKimMmMmNo ratings yet
- Grand Canonical EnsembleDocument15 pagesGrand Canonical EnsembleRian AshariNo ratings yet
- Qutrit Quantum Computer With Trapped Ions: NOT XOR XORDocument7 pagesQutrit Quantum Computer With Trapped Ions: NOT XOR XORcristian_masterNo ratings yet
- 18 - Irreducible Tensor Operators and The Wigner-Eckart Theorem PDFDocument30 pages18 - Irreducible Tensor Operators and The Wigner-Eckart Theorem PDFUltrazordNo ratings yet
- The Lagrangian, in General Is The Function Of: T and Q Q Q Q Q QDocument19 pagesThe Lagrangian, in General Is The Function Of: T and Q Q Q Q Q QGAURAV PANDEYNo ratings yet
- The Decay of Western Civilization: Double Relaxed Darwinian SelectionDocument45 pagesThe Decay of Western Civilization: Double Relaxed Darwinian SelectiongwernNo ratings yet
- Eg 1Document5 pagesEg 1jestamilNo ratings yet
- ReviewDocument7 pagesReviewSamra ButtNo ratings yet
- Analysis of VarianceDocument45 pagesAnalysis of Varianceaman.ace0701No ratings yet
- Photoelectric Effect: Figure 1: Constituents of The Atom A. Photoelectric EffectDocument5 pagesPhotoelectric Effect: Figure 1: Constituents of The Atom A. Photoelectric EffectMahnoor SiddiqiNo ratings yet
- Documento para DescargarDocument1 pageDocumento para DescargarMatias Jimenez AlbaladejoNo ratings yet
- HW 2 CHAP 2 - YepezDocument9 pagesHW 2 CHAP 2 - YepezElviraNo ratings yet
- Quiz SolutionsDocument6 pagesQuiz SolutionsVikas SinghNo ratings yet
- The Einstein-Myth and The Crisis in Modern PhysicsDocument17 pagesThe Einstein-Myth and The Crisis in Modern PhysicsLuis Gerardo Escandon AlcazarNo ratings yet
- Homework 3Document5 pagesHomework 3Ngọc ÁnhNo ratings yet
- What's Done Cannot Be Undone: TASI Lectures On Non-Invertible SymmetryDocument93 pagesWhat's Done Cannot Be Undone: TASI Lectures On Non-Invertible SymmetryKaio PhillipNo ratings yet
- Relativistic Correction On GPS Satellite (13 Points) Part A. Single Accelerated Particle (2.8 Points)Document3 pagesRelativistic Correction On GPS Satellite (13 Points) Part A. Single Accelerated Particle (2.8 Points)Khongor DamdinbayarNo ratings yet
- BLACK HOLES Final DraftDocument2 pagesBLACK HOLES Final DrafttejareddyNo ratings yet