Download as pdf or txt
You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5822)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1093)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (852)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (898)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (540)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (349)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (823)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (403)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Work Load Management: WLM Dynamic and Static Configuration PropertiesDocument11 pagesWork Load Management: WLM Dynamic and Static Configuration PropertiesNIROD BARANNo ratings yet
- Oracle 9i - Database Supporting Recovery Manager - RMAN - Student GuideDocument330 pagesOracle 9i - Database Supporting Recovery Manager - RMAN - Student Guidesrav2010No ratings yet
- EVlink Smart Wallbox - EVB1A22P4RIDocument3 pagesEVlink Smart Wallbox - EVB1A22P4RIrustemagNo ratings yet
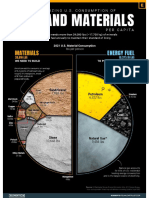
- The Minerals Needed To Maintain Our Standard of LivingDocument1 pageThe Minerals Needed To Maintain Our Standard of LivingrustemagNo ratings yet
- QUESTIONNAIRE CSN AcquéreurDocument213 pagesQUESTIONNAIRE CSN AcquéreurrustemagNo ratings yet
- Boeing Reports Fourth-Quarter ResultsDocument14 pagesBoeing Reports Fourth-Quarter ResultsrustemagNo ratings yet
- CS5984 Final ReportDocument57 pagesCS5984 Final ReportrustemagNo ratings yet
- ProjectName - Storage - Firebase ConsoleDocument1 pageProjectName - Storage - Firebase ConsolerustemagNo ratings yet
- EU User Consent Policy - Company - GoogleDocument2 pagesEU User Consent Policy - Company - GooglerustemagNo ratings yet
- Complete ExampleDocument5 pagesComplete ExamplerustemagNo ratings yet
- Brokering Code of ConductDocument7 pagesBrokering Code of ConductrustemagNo ratings yet
- Tableau Executive Summary PDFDocument5 pagesTableau Executive Summary PDFShiva CHNo ratings yet
- Chapter 3 Topic - 5Document13 pagesChapter 3 Topic - 5VENKATESHWARLUNo ratings yet
- GuinobatanDocument74 pagesGuinobatanAngelika CalingasanNo ratings yet
- Global Certificate in Data ScienceDocument11 pagesGlobal Certificate in Data ScienceAkshay SehgalNo ratings yet
- DB2 Interview QuestionsDocument2 pagesDB2 Interview QuestionsPrem KumarNo ratings yet
- Mobile Database Management System 3Document17 pagesMobile Database Management System 3Nilotpal SahariahNo ratings yet
- Bda Aiml Note Unit 1Document14 pagesBda Aiml Note Unit 1viswakranthipalagiriNo ratings yet
- Rebellabs SQL Cheat Sheeasdasdasd55555555Document1 pageRebellabs SQL Cheat Sheeasdasdasd55555555cuevaNo ratings yet
- Sreeja Big Data ResumeDocument6 pagesSreeja Big Data ResumeMohammad AliNo ratings yet
- Data Base Vs Data Ware HouseDocument29 pagesData Base Vs Data Ware HouseDevotees AddaNo ratings yet
- Hdfs Lab WorkDocument2 pagesHdfs Lab WorkRoni VincentNo ratings yet
- Advanced Eclat Algorithm For Frequent Itemsets GenerationDocument19 pagesAdvanced Eclat Algorithm For Frequent Itemsets GenerationSabaniNo ratings yet
- Oracle DBADocument25 pagesOracle DBAAvinash SinghNo ratings yet
- Carrier Objective: Shiva Kumar Vadde Mobile No: +91 - 7090853921Document5 pagesCarrier Objective: Shiva Kumar Vadde Mobile No: +91 - 7090853921Sankar SaripalliNo ratings yet
- Facility Details For CitizenDocument156 pagesFacility Details For CitizenAhana ChatterjeeNo ratings yet
- Creating An ODI Project and Interface - ODI11gDocument25 pagesCreating An ODI Project and Interface - ODI11gPedro ResendeNo ratings yet
- Using Source Code Repositories: Clearcase ArchitectureDocument16 pagesUsing Source Code Repositories: Clearcase Architecturedhaval khuntNo ratings yet
- Rdbms and SQL NotesDocument58 pagesRdbms and SQL NotesLakshit VedantNo ratings yet
- 11B-Survey of Database SystemsDocument32 pages11B-Survey of Database SystemsCristiano RonaldoNo ratings yet
- Palawan Official List of CandidatesDocument5 pagesPalawan Official List of CandidatesRalph John Dingal BalansagNo ratings yet
- Online Examination System Project ReportDocument43 pagesOnline Examination System Project Reporthumnaharoon0% (1)
- Data Warehousing and Data Mining - Thara - M.Tech CseDocument11 pagesData Warehousing and Data Mining - Thara - M.Tech CsethilagaNo ratings yet
- 1ST Term .SSS2 Data ProcessingDocument22 pages1ST Term .SSS2 Data Processingsamuel joshuaNo ratings yet
- GGODBDocument288 pagesGGODBpush5No ratings yet
- Open Text Email Archiving - Management For Lotus Notes 9.7.5 Installation GuideDocument127 pagesOpen Text Email Archiving - Management For Lotus Notes 9.7.5 Installation GuideLucNo ratings yet
- DDE-Module 7 - CataloguingDocument7 pagesDDE-Module 7 - CataloguingBitchoseNo ratings yet
- 5 427 Zamak Duše PDFDocument427 pages5 427 Zamak Duše PDFDragutin PetrićNo ratings yet
- Postgresql Vs Mysql Vs Db2 Vs MSSQL Vs OracleDocument5 pagesPostgresql Vs Mysql Vs Db2 Vs MSSQL Vs OracleHernan David RengifoNo ratings yet