
Exploring Trace Transform For Robust Human Action Recognition - G. Goudelis2013
Exploring Trace Transform For Robust Human Action Recognition - G. Goudelis2013
You might also like
- NTRN15DA.1 (6500 R12.6 PhotonicLayerGuide) Issue1Document646 pagesNTRN15DA.1 (6500 R12.6 PhotonicLayerGuide) Issue1Tariq EhsanNo ratings yet
- Fitness Action Recognition Based On MediapipeDocument8 pagesFitness Action Recognition Based On MediapipeBouhafs AbdelkaderNo ratings yet
- A Systematic Review of Network Protocol Fuzzing TechniquesDocument6 pagesA Systematic Review of Network Protocol Fuzzing Techniqueszuoyuan peng100% (1)
- Detecting 0dayDocument8 pagesDetecting 0daycharly36No ratings yet
- Blockchain Based Intelligent Vehicle Data Sharing FrameworkDocument4 pagesBlockchain Based Intelligent Vehicle Data Sharing FrameworkAli AliNo ratings yet
- Bayesian Latent Class Analysis Tutorial Li2018Document23 pagesBayesian Latent Class Analysis Tutorial Li2018Dom DeSiciliaNo ratings yet
- Action Recognition From Video UsingDocument16 pagesAction Recognition From Video UsingManju YcNo ratings yet
- Sun Human Action Recognition ICCV 2015 PaperDocument9 pagesSun Human Action Recognition ICCV 2015 PaperMohit KumarNo ratings yet
- Automatic Detection and Analysis of Player Action in Moving Background Sports Video Sequences-MwzDocument14 pagesAutomatic Detection and Analysis of Player Action in Moving Background Sports Video Sequences-Mwzjulio perezNo ratings yet
- Human Activity Recognition From VideoDocument24 pagesHuman Activity Recognition From Videobhagyashri1982No ratings yet
- Detecting Malware in Portable Executable Files Using Machine Learning ApproachDocument7 pagesDetecting Malware in Portable Executable Files Using Machine Learning ApproachAIRCC - IJNSANo ratings yet
- Android Malware Detection Using Machine LearningDocument4 pagesAndroid Malware Detection Using Machine LearningvanishabollaNo ratings yet
- Malware Detection & Prevention in Android Mobile by Using Significant Permission Identification & Machine LearningDocument8 pagesMalware Detection & Prevention in Android Mobile by Using Significant Permission Identification & Machine LearningIJRASETPublicationsNo ratings yet
- Detecting State Changes of Indoor Everyday Objects Using Wi-Fi Channel State Information. 2017Document28 pagesDetecting State Changes of Indoor Everyday Objects Using Wi-Fi Channel State Information. 2017Pavel SchukinNo ratings yet
- Robotics Chapter 5 - Robot VisionDocument7 pagesRobotics Chapter 5 - Robot Visiontutorfelix777No ratings yet
- Unit 5 Computer SecurityDocument12 pagesUnit 5 Computer SecurityPauline TorionNo ratings yet
- Malware Detection Using Machine Learning PDFDocument8 pagesMalware Detection Using Machine Learning PDFWatthanasak JeamwatthanachaiNo ratings yet
- Human Action Recognition Using 4W1H andDocument5 pagesHuman Action Recognition Using 4W1H andhusnaNo ratings yet
- Neural Networks PDFDocument89 pagesNeural Networks PDFIkshwakNo ratings yet
- 7.fog Computing Mitigating Insider Data Theft Attacks in The Cloud PDFDocument4 pages7.fog Computing Mitigating Insider Data Theft Attacks in The Cloud PDFpNo ratings yet
- East West Institute of Technology: An Improved Approach For Fire Detection Using Deep Learning ModelsDocument21 pagesEast West Institute of Technology: An Improved Approach For Fire Detection Using Deep Learning ModelsDeepuNo ratings yet
- Journal of Medical Systems-Security and Privacy Issues in Wireless SensorDocument10 pagesJournal of Medical Systems-Security and Privacy Issues in Wireless Sensormarisa.yuste08No ratings yet
- Report About Neural Network For Image ClassificationDocument51 pagesReport About Neural Network For Image ClassificationVivek Singh ChaudharyNo ratings yet
- Arbib, M A (2005) From Monkey-Like Action Recognition To Human Language An Evolutionary Framework For Neurolinguistics Behavioral and Brain SciencesDocument60 pagesArbib, M A (2005) From Monkey-Like Action Recognition To Human Language An Evolutionary Framework For Neurolinguistics Behavioral and Brain Sciencesnbj65813No ratings yet
- Explainable Artificial Intelligence Applications IDocument38 pagesExplainable Artificial Intelligence Applications IMini MNo ratings yet
- A Deep Learning Approach For Network Intrusion Detection SystemDocument6 pagesA Deep Learning Approach For Network Intrusion Detection SystemHero NakamuraNo ratings yet
- Mtech Ai MLDocument19 pagesMtech Ai MLAnju Chandran TNo ratings yet
- Chicago Crime (2013) Analysis Using Pig and Visualization Using RDocument61 pagesChicago Crime (2013) Analysis Using Pig and Visualization Using RSaurabh SharmaNo ratings yet
- Survey On Fake Image Detection Using Image ProcessingDocument5 pagesSurvey On Fake Image Detection Using Image ProcessingShaletXavierNo ratings yet
- Intrusion Detection System in Software Defined Networks Using Machine Learning and Deep Learning Technique-A Comprehensive SurveyDocument48 pagesIntrusion Detection System in Software Defined Networks Using Machine Learning and Deep Learning Technique-A Comprehensive SurveySumod SundarNo ratings yet
- Gesture Controlled WheelchairDocument22 pagesGesture Controlled Wheelchairsairam saiNo ratings yet
- Social Distancing and Face Mask Detection Using Deep LearningDocument7 pagesSocial Distancing and Face Mask Detection Using Deep LearningInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- 3D Convolutional Neural Networks For Human Action RecognitionDocument11 pages3D Convolutional Neural Networks For Human Action RecognitionaditriadiNo ratings yet
- Human Action RecognitionDocument14 pagesHuman Action RecognitionSHREE SANJAI D V 20ISR047No ratings yet
- 2 Convolutional Neural Network For Image ClassificationDocument6 pages2 Convolutional Neural Network For Image ClassificationKompruch BenjaputharakNo ratings yet
- A Review of Network Traffic Analysis and Prediction TechniquesDocument22 pagesA Review of Network Traffic Analysis and Prediction TechniquesPatrick GelardNo ratings yet
- Brain Tumor Classification Using Machine Learning Mixed ApproachDocument8 pagesBrain Tumor Classification Using Machine Learning Mixed ApproachIJRASETPublicationsNo ratings yet
- Introduction To Deep LearningDocument34 pagesIntroduction To Deep LearningShivam KumarNo ratings yet
- PRJT RepoDocument50 pagesPRJT RepoRajesh RaiNo ratings yet
- Real Time Bangladeshi License Plate Detection & Recognition: Submitted byDocument25 pagesReal Time Bangladeshi License Plate Detection & Recognition: Submitted byHomaira AlamNo ratings yet
- Deep Learning Report Waqas PDFDocument16 pagesDeep Learning Report Waqas PDFMohammad Waqas Moin SheikhNo ratings yet
- Concealed Weapon Detection Using Digital Image ProcessingDocument11 pagesConcealed Weapon Detection Using Digital Image Processinganishalex050% (2)
- Index: Optical Fiber Light Sources Light Detectors Packaging: Aseembly and Transceivers VcselDocument26 pagesIndex: Optical Fiber Light Sources Light Detectors Packaging: Aseembly and Transceivers VcselPooja Bhandari100% (1)
- A Review of Deep Learning Methods and Applications For PDFDocument14 pagesA Review of Deep Learning Methods and Applications For PDFershadNo ratings yet
- Mini Project: Helmet Detection and License Plate Number RecognitionDocument14 pagesMini Project: Helmet Detection and License Plate Number RecognitionS m Datacare100% (1)
- DenseNet For Brain Tumor Classification in MRI ImagesDocument9 pagesDenseNet For Brain Tumor Classification in MRI ImagesInternational Journal of Innovative Science and Research Technology100% (1)
- Presentation From December 12, 2000 Dinner MeetingDocument26 pagesPresentation From December 12, 2000 Dinner MeetingincosewmaNo ratings yet
- Design and Implementation of A Mini-Size Search Robot PDFDocument4 pagesDesign and Implementation of A Mini-Size Search Robot PDFsrcembeddedNo ratings yet
- Advanced Driver Assistance System For Drivers Using Machine Learning and Artificial Intelligence TechniquesDocument10 pagesAdvanced Driver Assistance System For Drivers Using Machine Learning and Artificial Intelligence TechniquesIJRASETPublicationsNo ratings yet
- Fake News Detetcion PPT 2023Document25 pagesFake News Detetcion PPT 2023Srilekha RajakumaranNo ratings yet
- Spectre PDFDocument16 pagesSpectre PDFdarezzo.guidoNo ratings yet
- Deep Learning Based Convolutional Neural Networks (DLCNN) On Classification Algorithm To Detect The Brain Turnor Diseases Using MRI and CT Scan ImagesDocument8 pagesDeep Learning Based Convolutional Neural Networks (DLCNN) On Classification Algorithm To Detect The Brain Turnor Diseases Using MRI and CT Scan ImagesInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Convolutional Neural NetworksDocument13 pagesConvolutional Neural NetworksSrikanth YadavNo ratings yet
- cs42 PROJECT REPORTDocument17 pagescs42 PROJECT REPORTWaqar AHMADNo ratings yet
- 1WiFiSenseSurvey CSUR19Document35 pages1WiFiSenseSurvey CSUR19JohnNo ratings yet
- Wood Identification Using Convolutional Neural NetworksDocument4 pagesWood Identification Using Convolutional Neural NetworksezekillNo ratings yet
- Detection and Tracking of Drones Using Artificial Intelligence Techniques - A SurveyDocument7 pagesDetection and Tracking of Drones Using Artificial Intelligence Techniques - A SurveyIJAR JOURNALNo ratings yet
- Bio Molecular Computing: C C C CDocument11 pagesBio Molecular Computing: C C C CSpandana ReddyNo ratings yet
- Hybrid Neural NetworkDocument13 pagesHybrid Neural NetworkbalashivasriNo ratings yet
- Project ReportDocument8 pagesProject Reportramakant.savranNo ratings yet
- A Deep Learning Gated Architecture For UGV Navigation Robust To SensorDocument18 pagesA Deep Learning Gated Architecture For UGV Navigation Robust To SensorOscar Ramos SotoNo ratings yet
- Compositional Game Theory, CompositionallyDocument17 pagesCompositional Game Theory, CompositionallyDom DeSiciliaNo ratings yet
- Weighted Co LimitsDocument6 pagesWeighted Co LimitsDom DeSiciliaNo ratings yet
- Formula One 2 Vec - F1 PredictorDocument6 pagesFormula One 2 Vec - F1 PredictorDom DeSiciliaNo ratings yet
- Algorithms, Games, and Evolution: SI TextDocument4 pagesAlgorithms, Games, and Evolution: SI TextDom DeSiciliaNo ratings yet
- Bayesian Statistics For Data Science - Towards Data ScienceDocument7 pagesBayesian Statistics For Data Science - Towards Data ScienceDom DeSiciliaNo ratings yet
- Support Vector Machines: 1 OutlineDocument19 pagesSupport Vector Machines: 1 OutlineDom DeSiciliaNo ratings yet
- Predicting Musical Sophistication From Music Listening Behaviors: A Preliminary StudyDocument2 pagesPredicting Musical Sophistication From Music Listening Behaviors: A Preliminary StudyDom DeSiciliaNo ratings yet
- Private Machine Learning in Tensorflow Using Secure ComputationDocument6 pagesPrivate Machine Learning in Tensorflow Using Secure ComputationDom DeSiciliaNo ratings yet
- Gregory Colvin Information Management Research: Exception Safe Smart PointersDocument2 pagesGregory Colvin Information Management Research: Exception Safe Smart PointersDom DeSiciliaNo ratings yet
- Active Network Vision and Reality: Lessons From A Capsule-Based SystemDocument16 pagesActive Network Vision and Reality: Lessons From A Capsule-Based SystemDom DeSiciliaNo ratings yet
- Notes On Mean Embeddings and Covariance Operators: Arthur Gretton February 24, 2015Document15 pagesNotes On Mean Embeddings and Covariance Operators: Arthur Gretton February 24, 2015Dom DeSiciliaNo ratings yet
- Integrating Security in A Large Distributed SystemDocument34 pagesIntegrating Security in A Large Distributed SystemsushmsnNo ratings yet
- Compe o Cellu Tomata U Les: T Ition F Lar Au RDocument12 pagesCompe o Cellu Tomata U Les: T Ition F Lar Au RDom DeSiciliaNo ratings yet
- Satya Ieeetc Coda 1990Document13 pagesSatya Ieeetc Coda 1990Dom DeSiciliaNo ratings yet
- Furt Evidence For Randomness In: Compl SystemsDocument6 pagesFurt Evidence For Randomness In: Compl SystemsDom DeSiciliaNo ratings yet
- Computer96 PsDocument26 pagesComputer96 PsDom DeSiciliaNo ratings yet
- Recovery Management in Quicksilver: Vol. 6, No. 1, February 1968, Pages 82-108Document27 pagesRecovery Management in Quicksilver: Vol. 6, No. 1, February 1968, Pages 82-108Dom DeSiciliaNo ratings yet
- An Overview of The Spring SystemDocument10 pagesAn Overview of The Spring SystemDom DeSiciliaNo ratings yet
- Ast Putationofa C A: F Com D Ditive Ell U Lar UtomataDocument6 pagesAst Putationofa C A: F Com D Ditive Ell U Lar UtomataDom DeSiciliaNo ratings yet
- Cell Automaton Public Ryptosystem: U Lar - Key CDocument6 pagesCell Automaton Public Ryptosystem: U Lar - Key CDom DeSiciliaNo ratings yet
- ITEC255 Chapter3 (Part1) With ExplanationsDocument29 pagesITEC255 Chapter3 (Part1) With ExplanationsyawahabNo ratings yet
- S32G2RSERDESRMDocument990 pagesS32G2RSERDESRMteenjustmeNo ratings yet
- Katalog Produktsii Sepa. Katalog ProduktsiiDocument60 pagesKatalog Produktsii Sepa. Katalog Produktsiihafssakhan504No ratings yet
- The Surface/Bulk Micromachining (SBM) Process: A New Method For Fabricating Released MEMS in Single Crystal SiliconDocument8 pagesThe Surface/Bulk Micromachining (SBM) Process: A New Method For Fabricating Released MEMS in Single Crystal SiliconAnton JohnNo ratings yet
- OWASP Guia de Referencia RápidaDocument20 pagesOWASP Guia de Referencia Rápidamarco20142014No ratings yet
- ERLPhase USB Driver InstructionsDocument9 pagesERLPhase USB Driver InstructionscacobecoNo ratings yet
- Banking Wallet iOS App UIDocument5 pagesBanking Wallet iOS App UIOluwaseun AjiboyeNo ratings yet
- Salesforce DeveloperDocument4 pagesSalesforce DeveloperMOHAMMED ABDUL AZEEMNo ratings yet
- XML Based Attacks: Daniel TomescuDocument25 pagesXML Based Attacks: Daniel TomescudevilNo ratings yet
- Convolutional Neural Networks For Malware ClassificationDocument100 pagesConvolutional Neural Networks For Malware ClassificationUDAYAKUMAR100% (1)
- A3 Alpha Meter 2008Document2 pagesA3 Alpha Meter 2008rodelNo ratings yet
- Introduction To Desktop PublishingDocument12 pagesIntroduction To Desktop Publishingddeksha pariharNo ratings yet
- Thickness Sander PlansDocument5 pagesThickness Sander Plansnarie0% (1)
- Isov Relnotes PDFDocument16 pagesIsov Relnotes PDFYvan SoteloNo ratings yet
- TenSteps Troubleshooting WiFiDocument23 pagesTenSteps Troubleshooting WiFiShyam BhavsarNo ratings yet
- Eve Online Region Map PDFDocument2 pagesEve Online Region Map PDFJohnnyNo ratings yet
- Making Custom Masks With GimpDocument3 pagesMaking Custom Masks With GimpStefani ByrdNo ratings yet
- Resetting A Lost Administrator PasswordDocument4 pagesResetting A Lost Administrator PasswordAmr BasyounyNo ratings yet
- Scep ClientDocument40 pagesScep ClientVaibhav SrivastavaNo ratings yet
- The Diy Smart SawDocument178 pagesThe Diy Smart SawEduardo Hassin RodriguesNo ratings yet
- TICK Software ReportsDocument52 pagesTICK Software ReportsSaurabh PurwarNo ratings yet
- AWS Certified Solutions Architect Professional-Exam Guide en 1.2Document3 pagesAWS Certified Solutions Architect Professional-Exam Guide en 1.2Vadapalli Venkata Ramana MurthyNo ratings yet
- Autodesk Software License Agreement WorldwideDocument13 pagesAutodesk Software License Agreement WorldwidetruthmagNo ratings yet
- E Procurement PDFDocument13 pagesE Procurement PDFvimalmakadiaNo ratings yet
- Density Based Traffic Light Controller: Sophia Delsi R Sinthuja RDocument17 pagesDensity Based Traffic Light Controller: Sophia Delsi R Sinthuja Rhamed razaNo ratings yet
- Cyber Crime in IndiaDocument26 pagesCyber Crime in Indiariteshjain07100% (1)
- Profibus With FBP: Achieve Everything With Fewer ComponentsDocument12 pagesProfibus With FBP: Achieve Everything With Fewer ComponentsAnonymous allFud2pjfNo ratings yet
- Concise and Effective Procedure Writing - The Scripted Flowchart ProcessDocument5 pagesConcise and Effective Procedure Writing - The Scripted Flowchart ProcessBenouna FertNo ratings yet
- InfoSphere CDC IBM I - Installation PDFDocument16 pagesInfoSphere CDC IBM I - Installation PDFDileepkumar JangaNo ratings yet


































































































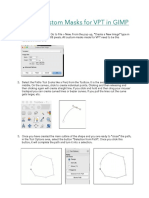












Download as pdf or txt
You might also like
- NTRN15DA.1 (6500 R12.6 PhotonicLayerGuide) Issue1Document646 pagesNTRN15DA.1 (6500 R12.6 PhotonicLayerGuide) Issue1Tariq EhsanNo ratings yet
- Fitness Action Recognition Based On MediapipeDocument8 pagesFitness Action Recognition Based On MediapipeBouhafs AbdelkaderNo ratings yet
- A Systematic Review of Network Protocol Fuzzing TechniquesDocument6 pagesA Systematic Review of Network Protocol Fuzzing Techniqueszuoyuan peng100% (1)
- Detecting 0dayDocument8 pagesDetecting 0daycharly36No ratings yet
- Blockchain Based Intelligent Vehicle Data Sharing FrameworkDocument4 pagesBlockchain Based Intelligent Vehicle Data Sharing FrameworkAli AliNo ratings yet
- Bayesian Latent Class Analysis Tutorial Li2018Document23 pagesBayesian Latent Class Analysis Tutorial Li2018Dom DeSiciliaNo ratings yet
- Action Recognition From Video UsingDocument16 pagesAction Recognition From Video UsingManju YcNo ratings yet
- Sun Human Action Recognition ICCV 2015 PaperDocument9 pagesSun Human Action Recognition ICCV 2015 PaperMohit KumarNo ratings yet
- Automatic Detection and Analysis of Player Action in Moving Background Sports Video Sequences-MwzDocument14 pagesAutomatic Detection and Analysis of Player Action in Moving Background Sports Video Sequences-Mwzjulio perezNo ratings yet
- Human Activity Recognition From VideoDocument24 pagesHuman Activity Recognition From Videobhagyashri1982No ratings yet
- Detecting Malware in Portable Executable Files Using Machine Learning ApproachDocument7 pagesDetecting Malware in Portable Executable Files Using Machine Learning ApproachAIRCC - IJNSANo ratings yet
- Android Malware Detection Using Machine LearningDocument4 pagesAndroid Malware Detection Using Machine LearningvanishabollaNo ratings yet
- Malware Detection & Prevention in Android Mobile by Using Significant Permission Identification & Machine LearningDocument8 pagesMalware Detection & Prevention in Android Mobile by Using Significant Permission Identification & Machine LearningIJRASETPublicationsNo ratings yet
- Detecting State Changes of Indoor Everyday Objects Using Wi-Fi Channel State Information. 2017Document28 pagesDetecting State Changes of Indoor Everyday Objects Using Wi-Fi Channel State Information. 2017Pavel SchukinNo ratings yet
- Robotics Chapter 5 - Robot VisionDocument7 pagesRobotics Chapter 5 - Robot Visiontutorfelix777No ratings yet
- Unit 5 Computer SecurityDocument12 pagesUnit 5 Computer SecurityPauline TorionNo ratings yet
- Malware Detection Using Machine Learning PDFDocument8 pagesMalware Detection Using Machine Learning PDFWatthanasak JeamwatthanachaiNo ratings yet
- Human Action Recognition Using 4W1H andDocument5 pagesHuman Action Recognition Using 4W1H andhusnaNo ratings yet
- Neural Networks PDFDocument89 pagesNeural Networks PDFIkshwakNo ratings yet
- 7.fog Computing Mitigating Insider Data Theft Attacks in The Cloud PDFDocument4 pages7.fog Computing Mitigating Insider Data Theft Attacks in The Cloud PDFpNo ratings yet
- East West Institute of Technology: An Improved Approach For Fire Detection Using Deep Learning ModelsDocument21 pagesEast West Institute of Technology: An Improved Approach For Fire Detection Using Deep Learning ModelsDeepuNo ratings yet
- Journal of Medical Systems-Security and Privacy Issues in Wireless SensorDocument10 pagesJournal of Medical Systems-Security and Privacy Issues in Wireless Sensormarisa.yuste08No ratings yet
- Report About Neural Network For Image ClassificationDocument51 pagesReport About Neural Network For Image ClassificationVivek Singh ChaudharyNo ratings yet
- Arbib, M A (2005) From Monkey-Like Action Recognition To Human Language An Evolutionary Framework For Neurolinguistics Behavioral and Brain SciencesDocument60 pagesArbib, M A (2005) From Monkey-Like Action Recognition To Human Language An Evolutionary Framework For Neurolinguistics Behavioral and Brain Sciencesnbj65813No ratings yet
- Explainable Artificial Intelligence Applications IDocument38 pagesExplainable Artificial Intelligence Applications IMini MNo ratings yet
- A Deep Learning Approach For Network Intrusion Detection SystemDocument6 pagesA Deep Learning Approach For Network Intrusion Detection SystemHero NakamuraNo ratings yet
- Mtech Ai MLDocument19 pagesMtech Ai MLAnju Chandran TNo ratings yet
- Chicago Crime (2013) Analysis Using Pig and Visualization Using RDocument61 pagesChicago Crime (2013) Analysis Using Pig and Visualization Using RSaurabh SharmaNo ratings yet
- Survey On Fake Image Detection Using Image ProcessingDocument5 pagesSurvey On Fake Image Detection Using Image ProcessingShaletXavierNo ratings yet
- Intrusion Detection System in Software Defined Networks Using Machine Learning and Deep Learning Technique-A Comprehensive SurveyDocument48 pagesIntrusion Detection System in Software Defined Networks Using Machine Learning and Deep Learning Technique-A Comprehensive SurveySumod SundarNo ratings yet
- Gesture Controlled WheelchairDocument22 pagesGesture Controlled Wheelchairsairam saiNo ratings yet
- Social Distancing and Face Mask Detection Using Deep LearningDocument7 pagesSocial Distancing and Face Mask Detection Using Deep LearningInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- 3D Convolutional Neural Networks For Human Action RecognitionDocument11 pages3D Convolutional Neural Networks For Human Action RecognitionaditriadiNo ratings yet
- Human Action RecognitionDocument14 pagesHuman Action RecognitionSHREE SANJAI D V 20ISR047No ratings yet
- 2 Convolutional Neural Network For Image ClassificationDocument6 pages2 Convolutional Neural Network For Image ClassificationKompruch BenjaputharakNo ratings yet
- A Review of Network Traffic Analysis and Prediction TechniquesDocument22 pagesA Review of Network Traffic Analysis and Prediction TechniquesPatrick GelardNo ratings yet
- Brain Tumor Classification Using Machine Learning Mixed ApproachDocument8 pagesBrain Tumor Classification Using Machine Learning Mixed ApproachIJRASETPublicationsNo ratings yet
- Introduction To Deep LearningDocument34 pagesIntroduction To Deep LearningShivam KumarNo ratings yet
- PRJT RepoDocument50 pagesPRJT RepoRajesh RaiNo ratings yet
- Real Time Bangladeshi License Plate Detection & Recognition: Submitted byDocument25 pagesReal Time Bangladeshi License Plate Detection & Recognition: Submitted byHomaira AlamNo ratings yet
- Deep Learning Report Waqas PDFDocument16 pagesDeep Learning Report Waqas PDFMohammad Waqas Moin SheikhNo ratings yet
- Concealed Weapon Detection Using Digital Image ProcessingDocument11 pagesConcealed Weapon Detection Using Digital Image Processinganishalex050% (2)
- Index: Optical Fiber Light Sources Light Detectors Packaging: Aseembly and Transceivers VcselDocument26 pagesIndex: Optical Fiber Light Sources Light Detectors Packaging: Aseembly and Transceivers VcselPooja Bhandari100% (1)
- A Review of Deep Learning Methods and Applications For PDFDocument14 pagesA Review of Deep Learning Methods and Applications For PDFershadNo ratings yet
- Mini Project: Helmet Detection and License Plate Number RecognitionDocument14 pagesMini Project: Helmet Detection and License Plate Number RecognitionS m Datacare100% (1)
- DenseNet For Brain Tumor Classification in MRI ImagesDocument9 pagesDenseNet For Brain Tumor Classification in MRI ImagesInternational Journal of Innovative Science and Research Technology100% (1)
- Presentation From December 12, 2000 Dinner MeetingDocument26 pagesPresentation From December 12, 2000 Dinner MeetingincosewmaNo ratings yet
- Design and Implementation of A Mini-Size Search Robot PDFDocument4 pagesDesign and Implementation of A Mini-Size Search Robot PDFsrcembeddedNo ratings yet
- Advanced Driver Assistance System For Drivers Using Machine Learning and Artificial Intelligence TechniquesDocument10 pagesAdvanced Driver Assistance System For Drivers Using Machine Learning and Artificial Intelligence TechniquesIJRASETPublicationsNo ratings yet
- Fake News Detetcion PPT 2023Document25 pagesFake News Detetcion PPT 2023Srilekha RajakumaranNo ratings yet
- Spectre PDFDocument16 pagesSpectre PDFdarezzo.guidoNo ratings yet
- Deep Learning Based Convolutional Neural Networks (DLCNN) On Classification Algorithm To Detect The Brain Turnor Diseases Using MRI and CT Scan ImagesDocument8 pagesDeep Learning Based Convolutional Neural Networks (DLCNN) On Classification Algorithm To Detect The Brain Turnor Diseases Using MRI and CT Scan ImagesInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Convolutional Neural NetworksDocument13 pagesConvolutional Neural NetworksSrikanth YadavNo ratings yet
- cs42 PROJECT REPORTDocument17 pagescs42 PROJECT REPORTWaqar AHMADNo ratings yet
- 1WiFiSenseSurvey CSUR19Document35 pages1WiFiSenseSurvey CSUR19JohnNo ratings yet
- Wood Identification Using Convolutional Neural NetworksDocument4 pagesWood Identification Using Convolutional Neural NetworksezekillNo ratings yet
- Detection and Tracking of Drones Using Artificial Intelligence Techniques - A SurveyDocument7 pagesDetection and Tracking of Drones Using Artificial Intelligence Techniques - A SurveyIJAR JOURNALNo ratings yet
- Bio Molecular Computing: C C C CDocument11 pagesBio Molecular Computing: C C C CSpandana ReddyNo ratings yet
- Hybrid Neural NetworkDocument13 pagesHybrid Neural NetworkbalashivasriNo ratings yet
- Project ReportDocument8 pagesProject Reportramakant.savranNo ratings yet
- A Deep Learning Gated Architecture For UGV Navigation Robust To SensorDocument18 pagesA Deep Learning Gated Architecture For UGV Navigation Robust To SensorOscar Ramos SotoNo ratings yet
- Compositional Game Theory, CompositionallyDocument17 pagesCompositional Game Theory, CompositionallyDom DeSiciliaNo ratings yet
- Weighted Co LimitsDocument6 pagesWeighted Co LimitsDom DeSiciliaNo ratings yet
- Formula One 2 Vec - F1 PredictorDocument6 pagesFormula One 2 Vec - F1 PredictorDom DeSiciliaNo ratings yet
- Algorithms, Games, and Evolution: SI TextDocument4 pagesAlgorithms, Games, and Evolution: SI TextDom DeSiciliaNo ratings yet
- Bayesian Statistics For Data Science - Towards Data ScienceDocument7 pagesBayesian Statistics For Data Science - Towards Data ScienceDom DeSiciliaNo ratings yet
- Support Vector Machines: 1 OutlineDocument19 pagesSupport Vector Machines: 1 OutlineDom DeSiciliaNo ratings yet
- Predicting Musical Sophistication From Music Listening Behaviors: A Preliminary StudyDocument2 pagesPredicting Musical Sophistication From Music Listening Behaviors: A Preliminary StudyDom DeSiciliaNo ratings yet
- Private Machine Learning in Tensorflow Using Secure ComputationDocument6 pagesPrivate Machine Learning in Tensorflow Using Secure ComputationDom DeSiciliaNo ratings yet
- Gregory Colvin Information Management Research: Exception Safe Smart PointersDocument2 pagesGregory Colvin Information Management Research: Exception Safe Smart PointersDom DeSiciliaNo ratings yet
- Active Network Vision and Reality: Lessons From A Capsule-Based SystemDocument16 pagesActive Network Vision and Reality: Lessons From A Capsule-Based SystemDom DeSiciliaNo ratings yet
- Notes On Mean Embeddings and Covariance Operators: Arthur Gretton February 24, 2015Document15 pagesNotes On Mean Embeddings and Covariance Operators: Arthur Gretton February 24, 2015Dom DeSiciliaNo ratings yet
- Integrating Security in A Large Distributed SystemDocument34 pagesIntegrating Security in A Large Distributed SystemsushmsnNo ratings yet
- Compe o Cellu Tomata U Les: T Ition F Lar Au RDocument12 pagesCompe o Cellu Tomata U Les: T Ition F Lar Au RDom DeSiciliaNo ratings yet
- Satya Ieeetc Coda 1990Document13 pagesSatya Ieeetc Coda 1990Dom DeSiciliaNo ratings yet
- Furt Evidence For Randomness In: Compl SystemsDocument6 pagesFurt Evidence For Randomness In: Compl SystemsDom DeSiciliaNo ratings yet
- Computer96 PsDocument26 pagesComputer96 PsDom DeSiciliaNo ratings yet
- Recovery Management in Quicksilver: Vol. 6, No. 1, February 1968, Pages 82-108Document27 pagesRecovery Management in Quicksilver: Vol. 6, No. 1, February 1968, Pages 82-108Dom DeSiciliaNo ratings yet
- An Overview of The Spring SystemDocument10 pagesAn Overview of The Spring SystemDom DeSiciliaNo ratings yet
- Ast Putationofa C A: F Com D Ditive Ell U Lar UtomataDocument6 pagesAst Putationofa C A: F Com D Ditive Ell U Lar UtomataDom DeSiciliaNo ratings yet
- Cell Automaton Public Ryptosystem: U Lar - Key CDocument6 pagesCell Automaton Public Ryptosystem: U Lar - Key CDom DeSiciliaNo ratings yet
- ITEC255 Chapter3 (Part1) With ExplanationsDocument29 pagesITEC255 Chapter3 (Part1) With ExplanationsyawahabNo ratings yet
- S32G2RSERDESRMDocument990 pagesS32G2RSERDESRMteenjustmeNo ratings yet
- Katalog Produktsii Sepa. Katalog ProduktsiiDocument60 pagesKatalog Produktsii Sepa. Katalog Produktsiihafssakhan504No ratings yet
- The Surface/Bulk Micromachining (SBM) Process: A New Method For Fabricating Released MEMS in Single Crystal SiliconDocument8 pagesThe Surface/Bulk Micromachining (SBM) Process: A New Method For Fabricating Released MEMS in Single Crystal SiliconAnton JohnNo ratings yet
- OWASP Guia de Referencia RápidaDocument20 pagesOWASP Guia de Referencia Rápidamarco20142014No ratings yet
- ERLPhase USB Driver InstructionsDocument9 pagesERLPhase USB Driver InstructionscacobecoNo ratings yet
- Banking Wallet iOS App UIDocument5 pagesBanking Wallet iOS App UIOluwaseun AjiboyeNo ratings yet
- Salesforce DeveloperDocument4 pagesSalesforce DeveloperMOHAMMED ABDUL AZEEMNo ratings yet
- XML Based Attacks: Daniel TomescuDocument25 pagesXML Based Attacks: Daniel TomescudevilNo ratings yet
- Convolutional Neural Networks For Malware ClassificationDocument100 pagesConvolutional Neural Networks For Malware ClassificationUDAYAKUMAR100% (1)
- A3 Alpha Meter 2008Document2 pagesA3 Alpha Meter 2008rodelNo ratings yet
- Introduction To Desktop PublishingDocument12 pagesIntroduction To Desktop Publishingddeksha pariharNo ratings yet
- Thickness Sander PlansDocument5 pagesThickness Sander Plansnarie0% (1)
- Isov Relnotes PDFDocument16 pagesIsov Relnotes PDFYvan SoteloNo ratings yet
- TenSteps Troubleshooting WiFiDocument23 pagesTenSteps Troubleshooting WiFiShyam BhavsarNo ratings yet
- Eve Online Region Map PDFDocument2 pagesEve Online Region Map PDFJohnnyNo ratings yet
- Making Custom Masks With GimpDocument3 pagesMaking Custom Masks With GimpStefani ByrdNo ratings yet
- Resetting A Lost Administrator PasswordDocument4 pagesResetting A Lost Administrator PasswordAmr BasyounyNo ratings yet
- Scep ClientDocument40 pagesScep ClientVaibhav SrivastavaNo ratings yet
- The Diy Smart SawDocument178 pagesThe Diy Smart SawEduardo Hassin RodriguesNo ratings yet
- TICK Software ReportsDocument52 pagesTICK Software ReportsSaurabh PurwarNo ratings yet
- AWS Certified Solutions Architect Professional-Exam Guide en 1.2Document3 pagesAWS Certified Solutions Architect Professional-Exam Guide en 1.2Vadapalli Venkata Ramana MurthyNo ratings yet
- Autodesk Software License Agreement WorldwideDocument13 pagesAutodesk Software License Agreement WorldwidetruthmagNo ratings yet
- E Procurement PDFDocument13 pagesE Procurement PDFvimalmakadiaNo ratings yet
- Density Based Traffic Light Controller: Sophia Delsi R Sinthuja RDocument17 pagesDensity Based Traffic Light Controller: Sophia Delsi R Sinthuja Rhamed razaNo ratings yet
- Cyber Crime in IndiaDocument26 pagesCyber Crime in Indiariteshjain07100% (1)
- Profibus With FBP: Achieve Everything With Fewer ComponentsDocument12 pagesProfibus With FBP: Achieve Everything With Fewer ComponentsAnonymous allFud2pjfNo ratings yet
- Concise and Effective Procedure Writing - The Scripted Flowchart ProcessDocument5 pagesConcise and Effective Procedure Writing - The Scripted Flowchart ProcessBenouna FertNo ratings yet
- InfoSphere CDC IBM I - Installation PDFDocument16 pagesInfoSphere CDC IBM I - Installation PDFDileepkumar JangaNo ratings yet