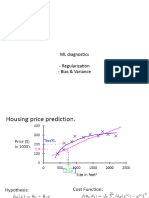
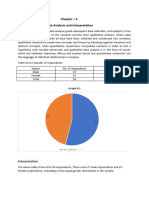
Download as pdf or txt
You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5834)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1093)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (852)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (903)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (541)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (350)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (824)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (405)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Business Studies Marketing NotesDocument13 pagesBusiness Studies Marketing Notesjackmalouf100% (1)
- Advance Statistics Business ReportDocument15 pagesAdvance Statistics Business ReportNagarajan ThandayuthamNo ratings yet
- 2013 The Psychology Research Handbook - A Guide For Graduate Students and Research AssistantsDocument537 pages2013 The Psychology Research Handbook - A Guide For Graduate Students and Research AssistantsNafiqotut Thoyyibah KholilNo ratings yet
- CustomerChurn AssignmentDocument15 pagesCustomerChurn AssignmentMalavika R Kumar100% (3)
- 10th Prelims 1st Stage 2022 Question Paper With Answer Key 1Document17 pages10th Prelims 1st Stage 2022 Question Paper With Answer Key 1Sreenath MuraliNo ratings yet
- 10th Prelims Stage 5 Question Paper & Answer KeyDocument15 pages10th Prelims Stage 5 Question Paper & Answer KeySreenath MuraliNo ratings yet
- 10th Prelims Phase 4 Question Paper With Answer KeyDocument15 pages10th Prelims Phase 4 Question Paper With Answer KeySreenath MuraliNo ratings yet
- 10th Level Preliminary Phase 3 Question & Ans MarkedDocument17 pages10th Level Preliminary Phase 3 Question & Ans MarkedSreenath MuraliNo ratings yet
- 10th Prelims Phase 2 Question Paper With Answer MarkedDocument15 pages10th Prelims Phase 2 Question Paper With Answer MarkedSreenath MuraliNo ratings yet
- A Comprehensive Review On Intrusion Detection SystemsDocument4 pagesA Comprehensive Review On Intrusion Detection SystemsSreenath MuraliNo ratings yet
- Thesis Sales ForcastingDocument43 pagesThesis Sales ForcastingHainsley EdwardsNo ratings yet
- 4 Analytics Concepts Every Manager Should Understand: Amy GalloDocument6 pages4 Analytics Concepts Every Manager Should Understand: Amy GallosheetalNo ratings yet
- Chapter 2 Proses Riset PemasaranDocument24 pagesChapter 2 Proses Riset PemasaranKrisna WiraNo ratings yet
- Financial Management of Public HospitalsDocument222 pagesFinancial Management of Public HospitalsPrince T Kwanda100% (1)
- Interview QuestionsDocument13 pagesInterview QuestionsPrakash ChandraNo ratings yet
- Bias-Variance Trade-OffDocument28 pagesBias-Variance Trade-OffRoudra ChakrabortyNo ratings yet
- Chapter 1.1 Industry ProfileDocument50 pagesChapter 1.1 Industry ProfileLikith C RNo ratings yet
- 125.785 Module 2.2Document95 pages125.785 Module 2.2Abhishek P BenjaminNo ratings yet
- 2.5 Scatter Plots and Line of Best FitDocument2 pages2.5 Scatter Plots and Line of Best FitkcarveyNo ratings yet
- How To Check ANOVA Assumptions - StatologyDocument12 pagesHow To Check ANOVA Assumptions - StatologyYaiza PGNo ratings yet
- Linear Regression: Scikit-LearnDocument3 pagesLinear Regression: Scikit-LearnsripathiNo ratings yet
- Real Statistics Examples Part 2Document1,110 pagesReal Statistics Examples Part 2heydar ruffa taufiqNo ratings yet
- MBA WBUT SyllabusDocument56 pagesMBA WBUT SyllabusVinod DhoundiyalNo ratings yet
- One Sample T-TestDocument2 pagesOne Sample T-TestPrashant SinghNo ratings yet
- Complete Randomized Design (CRD)Document22 pagesComplete Randomized Design (CRD)Donah Arquero100% (1)
- BUSI 410 Business Analytics: Module 25: Store24 (A) - Managing Employee RetentionDocument20 pagesBUSI 410 Business Analytics: Module 25: Store24 (A) - Managing Employee RetentionsnehalNo ratings yet
- Impact of IT Leadership On Transformation of The Role of IT in An Organization: Case Study of The Directorate General of TaxesDocument6 pagesImpact of IT Leadership On Transformation of The Role of IT in An Organization: Case Study of The Directorate General of TaxesHaldamir YavetilNo ratings yet
- Lession 13 - Data - VisualizationDocument18 pagesLession 13 - Data - Visualizationchi.nguyenNo ratings yet
- Chapter 4Document23 pagesChapter 4ImrannkhanNo ratings yet
- Final File of ResearchDocument23 pagesFinal File of Researchレー ジョン ダラムピネスNo ratings yet
- Lecture 3. Part 1 - Regression AnalysisDocument21 pagesLecture 3. Part 1 - Regression AnalysisRichelle PausangNo ratings yet
- Baed-Rsch2122 Inquiries, Investigations and Immersion: Week 11-20 By: Marygenkie 100% LegitDocument9 pagesBaed-Rsch2122 Inquiries, Investigations and Immersion: Week 11-20 By: Marygenkie 100% LegitTARA MAKAPOY REACTION50% (2)
- What Is Quantitaive ResearchDocument2 pagesWhat Is Quantitaive ResearchGerwin Elsisura AldianoNo ratings yet
- Step WiseDocument31 pagesStep WiseWayanne MorrisNo ratings yet
- Practical No - 01: Aim: Data Collection, Data Curation and Management For Unstructured Data (Nosql) Using Apache CouchdbDocument79 pagesPractical No - 01: Aim: Data Collection, Data Curation and Management For Unstructured Data (Nosql) Using Apache Couchdbyagyesh trivediNo ratings yet