
Learning Planning Operators by Observation and Practice Xuemei Wang
Learning Planning Operators by Observation and Practice Xuemei Wang
You might also like
- The Magical Diaries of Ethel ArcherDocument7 pagesThe Magical Diaries of Ethel Archerleeghancock100% (1)
- ISO 45001 2018 UpdatedDocument44 pagesISO 45001 2018 UpdatedSagar Shah100% (4)
- TED Books - Beyond The Hole in The Wall - Discover The Power of Self-Organized Learning - Sugata Mitra.2012Document87 pagesTED Books - Beyond The Hole in The Wall - Discover The Power of Self-Organized Learning - Sugata Mitra.2012vialav100% (4)
- A Table Lookup Scheme For Fuzzy Logic Based Model Identification Applied To Time Series PredictionDocument8 pagesA Table Lookup Scheme For Fuzzy Logic Based Model Identification Applied To Time Series PredictionArifaldy SatriadiNo ratings yet
- A Method For Pondering Plans in Autonomous Intelligent SystemsDocument7 pagesA Method For Pondering Plans in Autonomous Intelligent SystemsCosme Fula NitoNo ratings yet
- Session 05 - Paper 77Document10 pagesSession 05 - Paper 77Nicholas DawsonNo ratings yet
- Unit 1 Question With Answer2Document9 pagesUnit 1 Question With Answer2Abhishek GoyalNo ratings yet
- 2011-Leon Teaching A RobotbDocument8 pages2011-Leon Teaching A RobotbfarhadNo ratings yet
- Main 1Document8 pagesMain 1munera4350No ratings yet
- Paper 32-A New Automatic Method To Adjust Parameters For Object RecognitionDocument5 pagesPaper 32-A New Automatic Method To Adjust Parameters For Object RecognitionEditor IJACSANo ratings yet
- Agent Based SimulationDocument9 pagesAgent Based SimulationMichael CorselloNo ratings yet
- AIES Notes: Intelligent Agents (Lecture 2) : Topics of Lecture OneDocument11 pagesAIES Notes: Intelligent Agents (Lecture 2) : Topics of Lecture OneTIS ArNo ratings yet
- Autonomous Reinforcement Learning-BioloidDocument7 pagesAutonomous Reinforcement Learning-Bioloiddarkot1234No ratings yet
- A Method To Analyse Operator ActivityDocument6 pagesA Method To Analyse Operator ActivityBhavaNo ratings yet
- Implementation of Regression Testing Using Fuzzy Logic: Volume 2, Issue 4, April 2013Document3 pagesImplementation of Regression Testing Using Fuzzy Logic: Volume 2, Issue 4, April 2013International Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Using Temporal Checkers For Functional Coverage: Avi Ziv IBM Research Lab in Haifa Haifa University Haifa, 31905 IsraelDocument6 pagesUsing Temporal Checkers For Functional Coverage: Avi Ziv IBM Research Lab in Haifa Haifa University Haifa, 31905 IsraelSamNo ratings yet
- Haigh&Veloso (1999) LearningSituationDependentRules (ROGUE)Document6 pagesHaigh&Veloso (1999) LearningSituationDependentRules (ROGUE)Kasey OwensNo ratings yet
- R19 It Iii Year 1 Semester Design and Analysis of Algorithms Unit 1Document39 pagesR19 It Iii Year 1 Semester Design and Analysis of Algorithms Unit 1KaarletNo ratings yet
- Intelligent Information Retrieval: Submitted By: Deeksha Parsediya 13/pit/003 (ISR)Document17 pagesIntelligent Information Retrieval: Submitted By: Deeksha Parsediya 13/pit/003 (ISR)dixhapNo ratings yet
- 23 Some New Directions in Robot Problem Solving: R. E. Fikes, P. E. Hart and N. J. NilssonDocument26 pages23 Some New Directions in Robot Problem Solving: R. E. Fikes, P. E. Hart and N. J. NilssonVjay NarainNo ratings yet
- A Case Study: Application of Basicmost in A Lock'S AssemblyDocument7 pagesA Case Study: Application of Basicmost in A Lock'S AssemblysunitmhasadeNo ratings yet
- BDI Agents: From Theory To Practice: Proceedings of The First International Conference On Multi-Agent Systems (ICMAS-95)Document14 pagesBDI Agents: From Theory To Practice: Proceedings of The First International Conference On Multi-Agent Systems (ICMAS-95)al86203No ratings yet
- Active Sampling For Accelerated Learning of Performance ModelsDocument5 pagesActive Sampling For Accelerated Learning of Performance Modelsr20incNo ratings yet
- CMUnited 97 Sim - PsDocument9 pagesCMUnited 97 Sim - PsWayan SuardinataNo ratings yet
- Assignment No.: - 2 Ques:1 List The Principles of OOSE With Its Concepts. Ans:1Document11 pagesAssignment No.: - 2 Ques:1 List The Principles of OOSE With Its Concepts. Ans:1Sweta UmraoNo ratings yet
- Aylett Et Al. (1998) - Generating Operating Procedures For Chemical Process PlantsDocument32 pagesAylett Et Al. (1998) - Generating Operating Procedures For Chemical Process Plantsvazzoleralex6884No ratings yet
- ניתוצ תירגול 4 - 2023Document35 pagesניתוצ תירגול 4 - 2023mafiadaniel5No ratings yet
- Evaluation of Teacher'S Performance Using Fuzzylogic TechniquesDocument6 pagesEvaluation of Teacher'S Performance Using Fuzzylogic Techniquessurendiran123No ratings yet
- Paper 2 Fuzzy - Identification - of - Systems - and - Its - Applications - To - Modeling - and - ControlDocument17 pagesPaper 2 Fuzzy - Identification - of - Systems - and - Its - Applications - To - Modeling - and - ControlTanny MalleusNo ratings yet
- tmp3FCD TMPDocument14 pagestmp3FCD TMPFrontiersNo ratings yet
- Using Fuzzy Logic Control in Micro-Controller System: Myat Thu Zar, Thuzar KhinDocument5 pagesUsing Fuzzy Logic Control in Micro-Controller System: Myat Thu Zar, Thuzar KhinRobert Alexander Florez ParedesNo ratings yet
- Fuzzy Model For Optimizing Strategic Decisions Using MatlabDocument13 pagesFuzzy Model For Optimizing Strategic Decisions Using MatlabResearch Cell: An International Journal of Engineering SciencesNo ratings yet
- 18 Ie 22, Experiment 10Document20 pages18 Ie 22, Experiment 10usama khanNo ratings yet
- An Overview of Discrete Event Simulation Methodologies and ImplementationDocument17 pagesAn Overview of Discrete Event Simulation Methodologies and ImplementationMadhuSudhan KrishnamurthyNo ratings yet
- Selvam College of Technology, Namakkal - 03 PH: 9942099122Document22 pagesSelvam College of Technology, Namakkal - 03 PH: 9942099122Ms. M. KAVITHA MARGRET Asst Prof CSENo ratings yet
- Papers Ball and PlateDocument8 pagesPapers Ball and PlateRodriNo ratings yet
- Interactive Design Optimization of Dynamic Systems: C. H. Tseng and J. S. AroraDocument7 pagesInteractive Design Optimization of Dynamic Systems: C. H. Tseng and J. S. AroradddNo ratings yet
- Control System & Fuzzy Logic - Lab Manual - 23 - 24Document55 pagesControl System & Fuzzy Logic - Lab Manual - 23 - 24abhisheknalawade2004No ratings yet
- Schedul StaffDocument9 pagesSchedul StaffAbdellatif CHLIKHANo ratings yet
- KUNWAR ITECH7409Tutorials 09Document6 pagesKUNWAR ITECH7409Tutorials 09li0% (1)
- Structure of Agents in Artificial Intelligence - DailyonesDocument4 pagesStructure of Agents in Artificial Intelligence - DailyonespranavNo ratings yet
- Experiencing With Agapé-Tr: A Simulation Tool For Local Real-Time SchedulingDocument10 pagesExperiencing With Agapé-Tr: A Simulation Tool For Local Real-Time SchedulingGWNo ratings yet
- An Easy To Use Trajectory Optimisation Tool For Launcher DesignDocument8 pagesAn Easy To Use Trajectory Optimisation Tool For Launcher Designperrot louisNo ratings yet
- A 1Document4 pagesA 1milos ajdacicNo ratings yet
- Stock Price Prediction Using Reinforcement LearningDocument6 pagesStock Price Prediction Using Reinforcement Learningankurdey2002.adNo ratings yet
- Aiml 6Document8 pagesAiml 6Suma T KNo ratings yet
- An Efficient Hardware Implementation of Reinforcement Learning: The Q-Learning AlgorithmDocument12 pagesAn Efficient Hardware Implementation of Reinforcement Learning: The Q-Learning AlgorithmNguyễn Hồng NhungNo ratings yet
- An Efficient Hardware Implementation of Reinforcement Learning: The Q-Learning AlgorithmDocument12 pagesAn Efficient Hardware Implementation of Reinforcement Learning: The Q-Learning AlgorithmNguyễn Hồng NhungNo ratings yet
- System Analysis and Modeling: 3.2 Software Requirement SpecificationDocument47 pagesSystem Analysis and Modeling: 3.2 Software Requirement SpecificationGirma GodahegneNo ratings yet
- Document 24Document24 pagesDocument 24akh ajayNo ratings yet
- Layered ControllerDocument25 pagesLayered ControllerJagadeesh MNo ratings yet
- Active Learning For Multi-Task Adaptive FilteringDocument8 pagesActive Learning For Multi-Task Adaptive FilteringZhiqian LuNo ratings yet
- Reinforcement Learning of Non-Markov Decision Processes: Artificial IntelligenceDocument36 pagesReinforcement Learning of Non-Markov Decision Processes: Artificial IntelligenceLiem DaoNo ratings yet
- BTP Final Term Report v3Document26 pagesBTP Final Term Report v3Diptanshu RajanNo ratings yet
- Introduction To orDocument51 pagesIntroduction To orGurinder SinghNo ratings yet
- Behaviors of Real-Time Schedulers Under Resource Modification and A Steady Scheme With Bounded UtilizationDocument16 pagesBehaviors of Real-Time Schedulers Under Resource Modification and A Steady Scheme With Bounded UtilizationdvrsarmaNo ratings yet
- Knowledge-Based Expert System in Traffic Signal Control SystemsDocument9 pagesKnowledge-Based Expert System in Traffic Signal Control SystemsSudi ForFrndzNo ratings yet
- AI in CAPPDocument6 pagesAI in CAPPDhanabal Palanisamy PNo ratings yet
- GROUP-LABORATORY FinalDocument3 pagesGROUP-LABORATORY FinalKuya KimNo ratings yet
- Sliding Mode Methods For Fault Detection and Fault Tolerant ControlDocument12 pagesSliding Mode Methods For Fault Detection and Fault Tolerant ControljopiterNo ratings yet
- Aditi Banking of Management ReportDocument32 pagesAditi Banking of Management ReportPoonam soniNo ratings yet
- Kok&Otros Multi RobotDecisionMakingUsingCoordinationGraphsDocument6 pagesKok&Otros Multi RobotDecisionMakingUsingCoordinationGraphsKasey OwensNo ratings yet
- Haigh&Veloso (1999) LearningSituationDependentRules (ROGUE)Document6 pagesHaigh&Veloso (1999) LearningSituationDependentRules (ROGUE)Kasey OwensNo ratings yet
- Multi-Agent System For Decision Support in Enterprises: Dejan LavbiDocument16 pagesMulti-Agent System For Decision Support in Enterprises: Dejan LavbiKasey OwensNo ratings yet
- Argumentative Deliberation For Autonomous AgentsDocument10 pagesArgumentative Deliberation For Autonomous AgentsKasey OwensNo ratings yet
- LeBaron.B AgentBasedComputationalFinanceDocument26 pagesLeBaron.B AgentBasedComputationalFinanceKasey OwensNo ratings yet
- RL en Espacios Con, Nuos: (Con Diaposi0vas de Ali Nouri)Document23 pagesRL en Espacios Con, Nuos: (Con Diaposi0vas de Ali Nouri)Kasey OwensNo ratings yet
- Owens.J - WhatHistoriansWantFromGISDocument8 pagesOwens.J - WhatHistoriansWantFromGISKasey OwensNo ratings yet
- The Development of Khepera: 1 Starting ConditionsDocument7 pagesThe Development of Khepera: 1 Starting ConditionsKasey OwensNo ratings yet
- Barbara Hayes-Roth: An Architecture For Adaptive Intelligent Systems1Document49 pagesBarbara Hayes-Roth: An Architecture For Adaptive Intelligent Systems1Kasey OwensNo ratings yet
- Integrating Planning and Learning: The PRODIGY ArchitectureDocument39 pagesIntegrating Planning and Learning: The PRODIGY ArchitectureKasey OwensNo ratings yet
- Design Calculation of FrameDocument5 pagesDesign Calculation of FrameUdhasu NayakNo ratings yet
- Backyard AstronomerDocument10 pagesBackyard AstronomerDr Srinivasan Nenmeli -K100% (1)
- Dcitionary Errors and SolutionsDocument2 pagesDcitionary Errors and SolutionsGaurav MathurNo ratings yet
- 5 Forms of International Business - IbtDocument3 pages5 Forms of International Business - IbtGilbert CastroNo ratings yet
- Project Report "Solidworks" Six Months Software Training Project ReportDocument56 pagesProject Report "Solidworks" Six Months Software Training Project ReportakashNo ratings yet
- Sharmila Ghuge V StateDocument20 pagesSharmila Ghuge V StateBar & BenchNo ratings yet
- IRS Questions QbankDocument2 pagesIRS Questions Qbanktest1qaz100% (1)
- B1 Reading-Gapped Sentences-Addicted To SoapsDocument2 pagesB1 Reading-Gapped Sentences-Addicted To SoapsuriordiziaNo ratings yet
- Ablative Cooling Materials and SystemsDocument84 pagesAblative Cooling Materials and SystemsAerojet Rocketdyne RS-25No ratings yet
- 1000 Manual 0407Document60 pages1000 Manual 0407Dharmesh patelNo ratings yet
- DLL Entrepreneurship June 3-7, 2019Document3 pagesDLL Entrepreneurship June 3-7, 2019Babylyn Imperio100% (2)
- Navputeshankar 35Document1 pageNavputeshankar 35dipakNo ratings yet
- Fantasy Foundry (10032611)Document8 pagesFantasy Foundry (10032611)Oscar Chacon100% (1)
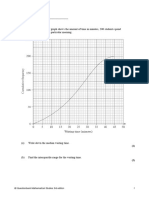
- The Cumulative Frequency Graph Shows The Amount of Time in Minutes, 200 Students Spend Waiting For Their Train On A Particular MorningDocument8 pagesThe Cumulative Frequency Graph Shows The Amount of Time in Minutes, 200 Students Spend Waiting For Their Train On A Particular MorningJonathanNo ratings yet
- Alfaisal University 2021 Summer Session Course Name: Technical English Course Number: ENG 222 Instructor: Danny SalgadoDocument32 pagesAlfaisal University 2021 Summer Session Course Name: Technical English Course Number: ENG 222 Instructor: Danny SalgadoMohamad SabbaghNo ratings yet
- Expression EncoderDocument34 pagesExpression EncoderIvan TašinNo ratings yet
- 9 9 21 367 PDFDocument7 pages9 9 21 367 PDFaihuutran51No ratings yet
- Polarized He Neutron Spin Filters For Neutron Polarization AnalysisDocument55 pagesPolarized He Neutron Spin Filters For Neutron Polarization AnalysisJonathan CuroleNo ratings yet
- High Lift Hydraulic Transmission Jacks "AF25082" "AF50080" "AF100080"Document6 pagesHigh Lift Hydraulic Transmission Jacks "AF25082" "AF50080" "AF100080"Alain DefoeNo ratings yet
- Read The Paragraph Below and Match Each Bold Word To Its MeaningDocument3 pagesRead The Paragraph Below and Match Each Bold Word To Its MeaningNicolas Andrey Villamizar Lozano0% (1)
- Software Testing MCQs SampleDocument18 pagesSoftware Testing MCQs SamplethejashwiniNo ratings yet
- DIC Email Copywriting TemplateDocument5 pagesDIC Email Copywriting TemplateWiktor AntoszNo ratings yet
- Drug & Narcotics: Presented By: A K M Shawkat Islam Additional Director Department of Narcotics ControlDocument38 pagesDrug & Narcotics: Presented By: A K M Shawkat Islam Additional Director Department of Narcotics ControlFarhan ShawkatNo ratings yet
- Ardia Et Al (2018) - Forecasting Risk With Markov-Switching GARCH Models. A Large-Scale Performance StudyDocument15 pagesArdia Et Al (2018) - Forecasting Risk With Markov-Switching GARCH Models. A Large-Scale Performance StudyLuciano BorgoglioNo ratings yet
- New Microsoft Office Word DocumentDocument9 pagesNew Microsoft Office Word DocumentSanthiya SanjeeviNo ratings yet
- Working Paper No. 561 PDFDocument34 pagesWorking Paper No. 561 PDFdilipkumar boinwadNo ratings yet
- Lag Circuit: Line To Line FaultDocument180 pagesLag Circuit: Line To Line FaultGareth ThomasNo ratings yet


































































































Download as pdf or txt
You might also like
- The Magical Diaries of Ethel ArcherDocument7 pagesThe Magical Diaries of Ethel Archerleeghancock100% (1)
- ISO 45001 2018 UpdatedDocument44 pagesISO 45001 2018 UpdatedSagar Shah100% (4)
- TED Books - Beyond The Hole in The Wall - Discover The Power of Self-Organized Learning - Sugata Mitra.2012Document87 pagesTED Books - Beyond The Hole in The Wall - Discover The Power of Self-Organized Learning - Sugata Mitra.2012vialav100% (4)
- A Table Lookup Scheme For Fuzzy Logic Based Model Identification Applied To Time Series PredictionDocument8 pagesA Table Lookup Scheme For Fuzzy Logic Based Model Identification Applied To Time Series PredictionArifaldy SatriadiNo ratings yet
- A Method For Pondering Plans in Autonomous Intelligent SystemsDocument7 pagesA Method For Pondering Plans in Autonomous Intelligent SystemsCosme Fula NitoNo ratings yet
- Session 05 - Paper 77Document10 pagesSession 05 - Paper 77Nicholas DawsonNo ratings yet
- Unit 1 Question With Answer2Document9 pagesUnit 1 Question With Answer2Abhishek GoyalNo ratings yet
- 2011-Leon Teaching A RobotbDocument8 pages2011-Leon Teaching A RobotbfarhadNo ratings yet
- Main 1Document8 pagesMain 1munera4350No ratings yet
- Paper 32-A New Automatic Method To Adjust Parameters For Object RecognitionDocument5 pagesPaper 32-A New Automatic Method To Adjust Parameters For Object RecognitionEditor IJACSANo ratings yet
- Agent Based SimulationDocument9 pagesAgent Based SimulationMichael CorselloNo ratings yet
- AIES Notes: Intelligent Agents (Lecture 2) : Topics of Lecture OneDocument11 pagesAIES Notes: Intelligent Agents (Lecture 2) : Topics of Lecture OneTIS ArNo ratings yet
- Autonomous Reinforcement Learning-BioloidDocument7 pagesAutonomous Reinforcement Learning-Bioloiddarkot1234No ratings yet
- A Method To Analyse Operator ActivityDocument6 pagesA Method To Analyse Operator ActivityBhavaNo ratings yet
- Implementation of Regression Testing Using Fuzzy Logic: Volume 2, Issue 4, April 2013Document3 pagesImplementation of Regression Testing Using Fuzzy Logic: Volume 2, Issue 4, April 2013International Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Using Temporal Checkers For Functional Coverage: Avi Ziv IBM Research Lab in Haifa Haifa University Haifa, 31905 IsraelDocument6 pagesUsing Temporal Checkers For Functional Coverage: Avi Ziv IBM Research Lab in Haifa Haifa University Haifa, 31905 IsraelSamNo ratings yet
- Haigh&Veloso (1999) LearningSituationDependentRules (ROGUE)Document6 pagesHaigh&Veloso (1999) LearningSituationDependentRules (ROGUE)Kasey OwensNo ratings yet
- R19 It Iii Year 1 Semester Design and Analysis of Algorithms Unit 1Document39 pagesR19 It Iii Year 1 Semester Design and Analysis of Algorithms Unit 1KaarletNo ratings yet
- Intelligent Information Retrieval: Submitted By: Deeksha Parsediya 13/pit/003 (ISR)Document17 pagesIntelligent Information Retrieval: Submitted By: Deeksha Parsediya 13/pit/003 (ISR)dixhapNo ratings yet
- 23 Some New Directions in Robot Problem Solving: R. E. Fikes, P. E. Hart and N. J. NilssonDocument26 pages23 Some New Directions in Robot Problem Solving: R. E. Fikes, P. E. Hart and N. J. NilssonVjay NarainNo ratings yet
- A Case Study: Application of Basicmost in A Lock'S AssemblyDocument7 pagesA Case Study: Application of Basicmost in A Lock'S AssemblysunitmhasadeNo ratings yet
- BDI Agents: From Theory To Practice: Proceedings of The First International Conference On Multi-Agent Systems (ICMAS-95)Document14 pagesBDI Agents: From Theory To Practice: Proceedings of The First International Conference On Multi-Agent Systems (ICMAS-95)al86203No ratings yet
- Active Sampling For Accelerated Learning of Performance ModelsDocument5 pagesActive Sampling For Accelerated Learning of Performance Modelsr20incNo ratings yet
- CMUnited 97 Sim - PsDocument9 pagesCMUnited 97 Sim - PsWayan SuardinataNo ratings yet
- Assignment No.: - 2 Ques:1 List The Principles of OOSE With Its Concepts. Ans:1Document11 pagesAssignment No.: - 2 Ques:1 List The Principles of OOSE With Its Concepts. Ans:1Sweta UmraoNo ratings yet
- Aylett Et Al. (1998) - Generating Operating Procedures For Chemical Process PlantsDocument32 pagesAylett Et Al. (1998) - Generating Operating Procedures For Chemical Process Plantsvazzoleralex6884No ratings yet
- ניתוצ תירגול 4 - 2023Document35 pagesניתוצ תירגול 4 - 2023mafiadaniel5No ratings yet
- Evaluation of Teacher'S Performance Using Fuzzylogic TechniquesDocument6 pagesEvaluation of Teacher'S Performance Using Fuzzylogic Techniquessurendiran123No ratings yet
- Paper 2 Fuzzy - Identification - of - Systems - and - Its - Applications - To - Modeling - and - ControlDocument17 pagesPaper 2 Fuzzy - Identification - of - Systems - and - Its - Applications - To - Modeling - and - ControlTanny MalleusNo ratings yet
- tmp3FCD TMPDocument14 pagestmp3FCD TMPFrontiersNo ratings yet
- Using Fuzzy Logic Control in Micro-Controller System: Myat Thu Zar, Thuzar KhinDocument5 pagesUsing Fuzzy Logic Control in Micro-Controller System: Myat Thu Zar, Thuzar KhinRobert Alexander Florez ParedesNo ratings yet
- Fuzzy Model For Optimizing Strategic Decisions Using MatlabDocument13 pagesFuzzy Model For Optimizing Strategic Decisions Using MatlabResearch Cell: An International Journal of Engineering SciencesNo ratings yet
- 18 Ie 22, Experiment 10Document20 pages18 Ie 22, Experiment 10usama khanNo ratings yet
- An Overview of Discrete Event Simulation Methodologies and ImplementationDocument17 pagesAn Overview of Discrete Event Simulation Methodologies and ImplementationMadhuSudhan KrishnamurthyNo ratings yet
- Selvam College of Technology, Namakkal - 03 PH: 9942099122Document22 pagesSelvam College of Technology, Namakkal - 03 PH: 9942099122Ms. M. KAVITHA MARGRET Asst Prof CSENo ratings yet
- Papers Ball and PlateDocument8 pagesPapers Ball and PlateRodriNo ratings yet
- Interactive Design Optimization of Dynamic Systems: C. H. Tseng and J. S. AroraDocument7 pagesInteractive Design Optimization of Dynamic Systems: C. H. Tseng and J. S. AroradddNo ratings yet
- Control System & Fuzzy Logic - Lab Manual - 23 - 24Document55 pagesControl System & Fuzzy Logic - Lab Manual - 23 - 24abhisheknalawade2004No ratings yet
- Schedul StaffDocument9 pagesSchedul StaffAbdellatif CHLIKHANo ratings yet
- KUNWAR ITECH7409Tutorials 09Document6 pagesKUNWAR ITECH7409Tutorials 09li0% (1)
- Structure of Agents in Artificial Intelligence - DailyonesDocument4 pagesStructure of Agents in Artificial Intelligence - DailyonespranavNo ratings yet
- Experiencing With Agapé-Tr: A Simulation Tool For Local Real-Time SchedulingDocument10 pagesExperiencing With Agapé-Tr: A Simulation Tool For Local Real-Time SchedulingGWNo ratings yet
- An Easy To Use Trajectory Optimisation Tool For Launcher DesignDocument8 pagesAn Easy To Use Trajectory Optimisation Tool For Launcher Designperrot louisNo ratings yet
- A 1Document4 pagesA 1milos ajdacicNo ratings yet
- Stock Price Prediction Using Reinforcement LearningDocument6 pagesStock Price Prediction Using Reinforcement Learningankurdey2002.adNo ratings yet
- Aiml 6Document8 pagesAiml 6Suma T KNo ratings yet
- An Efficient Hardware Implementation of Reinforcement Learning: The Q-Learning AlgorithmDocument12 pagesAn Efficient Hardware Implementation of Reinforcement Learning: The Q-Learning AlgorithmNguyễn Hồng NhungNo ratings yet
- An Efficient Hardware Implementation of Reinforcement Learning: The Q-Learning AlgorithmDocument12 pagesAn Efficient Hardware Implementation of Reinforcement Learning: The Q-Learning AlgorithmNguyễn Hồng NhungNo ratings yet
- System Analysis and Modeling: 3.2 Software Requirement SpecificationDocument47 pagesSystem Analysis and Modeling: 3.2 Software Requirement SpecificationGirma GodahegneNo ratings yet
- Document 24Document24 pagesDocument 24akh ajayNo ratings yet
- Layered ControllerDocument25 pagesLayered ControllerJagadeesh MNo ratings yet
- Active Learning For Multi-Task Adaptive FilteringDocument8 pagesActive Learning For Multi-Task Adaptive FilteringZhiqian LuNo ratings yet
- Reinforcement Learning of Non-Markov Decision Processes: Artificial IntelligenceDocument36 pagesReinforcement Learning of Non-Markov Decision Processes: Artificial IntelligenceLiem DaoNo ratings yet
- BTP Final Term Report v3Document26 pagesBTP Final Term Report v3Diptanshu RajanNo ratings yet
- Introduction To orDocument51 pagesIntroduction To orGurinder SinghNo ratings yet
- Behaviors of Real-Time Schedulers Under Resource Modification and A Steady Scheme With Bounded UtilizationDocument16 pagesBehaviors of Real-Time Schedulers Under Resource Modification and A Steady Scheme With Bounded UtilizationdvrsarmaNo ratings yet
- Knowledge-Based Expert System in Traffic Signal Control SystemsDocument9 pagesKnowledge-Based Expert System in Traffic Signal Control SystemsSudi ForFrndzNo ratings yet
- AI in CAPPDocument6 pagesAI in CAPPDhanabal Palanisamy PNo ratings yet
- GROUP-LABORATORY FinalDocument3 pagesGROUP-LABORATORY FinalKuya KimNo ratings yet
- Sliding Mode Methods For Fault Detection and Fault Tolerant ControlDocument12 pagesSliding Mode Methods For Fault Detection and Fault Tolerant ControljopiterNo ratings yet
- Aditi Banking of Management ReportDocument32 pagesAditi Banking of Management ReportPoonam soniNo ratings yet
- Kok&Otros Multi RobotDecisionMakingUsingCoordinationGraphsDocument6 pagesKok&Otros Multi RobotDecisionMakingUsingCoordinationGraphsKasey OwensNo ratings yet
- Haigh&Veloso (1999) LearningSituationDependentRules (ROGUE)Document6 pagesHaigh&Veloso (1999) LearningSituationDependentRules (ROGUE)Kasey OwensNo ratings yet
- Multi-Agent System For Decision Support in Enterprises: Dejan LavbiDocument16 pagesMulti-Agent System For Decision Support in Enterprises: Dejan LavbiKasey OwensNo ratings yet
- Argumentative Deliberation For Autonomous AgentsDocument10 pagesArgumentative Deliberation For Autonomous AgentsKasey OwensNo ratings yet
- LeBaron.B AgentBasedComputationalFinanceDocument26 pagesLeBaron.B AgentBasedComputationalFinanceKasey OwensNo ratings yet
- RL en Espacios Con, Nuos: (Con Diaposi0vas de Ali Nouri)Document23 pagesRL en Espacios Con, Nuos: (Con Diaposi0vas de Ali Nouri)Kasey OwensNo ratings yet
- Owens.J - WhatHistoriansWantFromGISDocument8 pagesOwens.J - WhatHistoriansWantFromGISKasey OwensNo ratings yet
- The Development of Khepera: 1 Starting ConditionsDocument7 pagesThe Development of Khepera: 1 Starting ConditionsKasey OwensNo ratings yet
- Barbara Hayes-Roth: An Architecture For Adaptive Intelligent Systems1Document49 pagesBarbara Hayes-Roth: An Architecture For Adaptive Intelligent Systems1Kasey OwensNo ratings yet
- Integrating Planning and Learning: The PRODIGY ArchitectureDocument39 pagesIntegrating Planning and Learning: The PRODIGY ArchitectureKasey OwensNo ratings yet
- Design Calculation of FrameDocument5 pagesDesign Calculation of FrameUdhasu NayakNo ratings yet
- Backyard AstronomerDocument10 pagesBackyard AstronomerDr Srinivasan Nenmeli -K100% (1)
- Dcitionary Errors and SolutionsDocument2 pagesDcitionary Errors and SolutionsGaurav MathurNo ratings yet
- 5 Forms of International Business - IbtDocument3 pages5 Forms of International Business - IbtGilbert CastroNo ratings yet
- Project Report "Solidworks" Six Months Software Training Project ReportDocument56 pagesProject Report "Solidworks" Six Months Software Training Project ReportakashNo ratings yet
- Sharmila Ghuge V StateDocument20 pagesSharmila Ghuge V StateBar & BenchNo ratings yet
- IRS Questions QbankDocument2 pagesIRS Questions Qbanktest1qaz100% (1)
- B1 Reading-Gapped Sentences-Addicted To SoapsDocument2 pagesB1 Reading-Gapped Sentences-Addicted To SoapsuriordiziaNo ratings yet
- Ablative Cooling Materials and SystemsDocument84 pagesAblative Cooling Materials and SystemsAerojet Rocketdyne RS-25No ratings yet
- 1000 Manual 0407Document60 pages1000 Manual 0407Dharmesh patelNo ratings yet
- DLL Entrepreneurship June 3-7, 2019Document3 pagesDLL Entrepreneurship June 3-7, 2019Babylyn Imperio100% (2)
- Navputeshankar 35Document1 pageNavputeshankar 35dipakNo ratings yet
- Fantasy Foundry (10032611)Document8 pagesFantasy Foundry (10032611)Oscar Chacon100% (1)
- The Cumulative Frequency Graph Shows The Amount of Time in Minutes, 200 Students Spend Waiting For Their Train On A Particular MorningDocument8 pagesThe Cumulative Frequency Graph Shows The Amount of Time in Minutes, 200 Students Spend Waiting For Their Train On A Particular MorningJonathanNo ratings yet
- Alfaisal University 2021 Summer Session Course Name: Technical English Course Number: ENG 222 Instructor: Danny SalgadoDocument32 pagesAlfaisal University 2021 Summer Session Course Name: Technical English Course Number: ENG 222 Instructor: Danny SalgadoMohamad SabbaghNo ratings yet
- Expression EncoderDocument34 pagesExpression EncoderIvan TašinNo ratings yet
- 9 9 21 367 PDFDocument7 pages9 9 21 367 PDFaihuutran51No ratings yet
- Polarized He Neutron Spin Filters For Neutron Polarization AnalysisDocument55 pagesPolarized He Neutron Spin Filters For Neutron Polarization AnalysisJonathan CuroleNo ratings yet
- High Lift Hydraulic Transmission Jacks "AF25082" "AF50080" "AF100080"Document6 pagesHigh Lift Hydraulic Transmission Jacks "AF25082" "AF50080" "AF100080"Alain DefoeNo ratings yet
- Read The Paragraph Below and Match Each Bold Word To Its MeaningDocument3 pagesRead The Paragraph Below and Match Each Bold Word To Its MeaningNicolas Andrey Villamizar Lozano0% (1)
- Software Testing MCQs SampleDocument18 pagesSoftware Testing MCQs SamplethejashwiniNo ratings yet
- DIC Email Copywriting TemplateDocument5 pagesDIC Email Copywriting TemplateWiktor AntoszNo ratings yet
- Drug & Narcotics: Presented By: A K M Shawkat Islam Additional Director Department of Narcotics ControlDocument38 pagesDrug & Narcotics: Presented By: A K M Shawkat Islam Additional Director Department of Narcotics ControlFarhan ShawkatNo ratings yet
- Ardia Et Al (2018) - Forecasting Risk With Markov-Switching GARCH Models. A Large-Scale Performance StudyDocument15 pagesArdia Et Al (2018) - Forecasting Risk With Markov-Switching GARCH Models. A Large-Scale Performance StudyLuciano BorgoglioNo ratings yet
- New Microsoft Office Word DocumentDocument9 pagesNew Microsoft Office Word DocumentSanthiya SanjeeviNo ratings yet
- Working Paper No. 561 PDFDocument34 pagesWorking Paper No. 561 PDFdilipkumar boinwadNo ratings yet
- Lag Circuit: Line To Line FaultDocument180 pagesLag Circuit: Line To Line FaultGareth ThomasNo ratings yet