Download as pdf or txt
You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5822)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1093)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (852)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (898)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (540)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (349)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (823)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (403)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
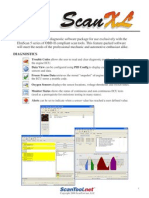
- ELM327 Scan Xl-OverviewDocument5 pagesELM327 Scan Xl-OverviewRoymer Del Corral100% (1)
- Lesson Plan Triangle InequalityDocument4 pagesLesson Plan Triangle Inequalityapi-312579213100% (9)
- Step by Step Guide For PowerpointDocument15 pagesStep by Step Guide For PowerpointHector OliverNo ratings yet
- Presented By, Nidhin P Koshy S7 Ecb Roll No: 32, TKMIT Guided By, Mrs. Rafeekha.M.J Assistant Professor Ece Dept, TkmitDocument29 pagesPresented By, Nidhin P Koshy S7 Ecb Roll No: 32, TKMIT Guided By, Mrs. Rafeekha.M.J Assistant Professor Ece Dept, TkmitTalib GaznayNo ratings yet
- LPG Gas Leakage Detector Using ArduinoDocument6 pagesLPG Gas Leakage Detector Using ArduinoShivam UikeyNo ratings yet
- MAIN Electrical Parts List: Design LOC Sec-Code DescriptionDocument12 pagesMAIN Electrical Parts List: Design LOC Sec-Code DescriptionAndroid Schematics and CircuitsNo ratings yet
- Home Landscape DesignDocument31 pagesHome Landscape DesignEduardson Justo100% (2)
- HAMEL Reinventing Management For The 21st Century VOCAB For LectureDocument7 pagesHAMEL Reinventing Management For The 21st Century VOCAB For LectureAnonymous Bc21pM100% (1)
- BI Apps Parameters Configuration DetailsDocument6 pagesBI Apps Parameters Configuration Detailssatyanarayana NVSNo ratings yet
- Form List of Comparison Supplier (Quotation Analysis)Document4 pagesForm List of Comparison Supplier (Quotation Analysis)Shahir IbrhmNo ratings yet
- IHW20N120R2: Reverse Conducting IGBT With Monolithic Body DiodeDocument12 pagesIHW20N120R2: Reverse Conducting IGBT With Monolithic Body Diodees9857No ratings yet
- Ngconf 2018 - RoutingDocument50 pagesNgconf 2018 - RoutingκβηξκλκξηNo ratings yet
- Js2 Third Term - 2Document87 pagesJs2 Third Term - 2emma adeyemiNo ratings yet
- PL2303 Windows Driver User Manual v1.18.0Document17 pagesPL2303 Windows Driver User Manual v1.18.0Victor Fernando Aires ArrudaNo ratings yet
- Assembly Language Program - Part II: 1. BIOS InterruptDocument2 pagesAssembly Language Program - Part II: 1. BIOS InterruptLAI GUAN HONGNo ratings yet
- Teaching of 808688 Programming With Assembly EmulatorDocument8 pagesTeaching of 808688 Programming With Assembly Emulatordihosid99No ratings yet
- Ivar Aasen Field Development Project - PDQ: 230V Ac Ups Sub-Db 85El0203B - General Arrangement DrawingDocument18 pagesIvar Aasen Field Development Project - PDQ: 230V Ac Ups Sub-Db 85El0203B - General Arrangement DrawingayemyothantNo ratings yet
- VHDL 6 Synthesis With VHDL LeonardoDocument42 pagesVHDL 6 Synthesis With VHDL Leonardoudayraj_mpNo ratings yet
- News - EN Radar Opus UpdateDocument2 pagesNews - EN Radar Opus UpdateghinsavitNo ratings yet
- Brochure RomerDocument2 pagesBrochure RomerlaboratorioNo ratings yet
- Fise de Lucru Litere ManaDocument27 pagesFise de Lucru Litere ManaRoxana Poama-NeagraNo ratings yet
- Data Warehousing and Olap Technology: Manya SethiDocument6 pagesData Warehousing and Olap Technology: Manya SethiAditya DavaleNo ratings yet
- Atlys RM RevcDocument19 pagesAtlys RM RevcCelso Palomino PeñaNo ratings yet
- Multimedia Unit 4Document16 pagesMultimedia Unit 4imdadalidahri06it47No ratings yet
- Devops Enterprise+Continuous+DeliveryDocument14 pagesDevops Enterprise+Continuous+DeliverykasimNo ratings yet
- SAMA APP Overview Specifications (For Tender)Document11 pagesSAMA APP Overview Specifications (For Tender)Malcolm M YaduraNo ratings yet
- Medical Health Care PowerPoint TemplatesDocument48 pagesMedical Health Care PowerPoint TemplatesRomanNo ratings yet
- Multi-Criteria Decision Making (MCDM) Methods and ConceptsDocument11 pagesMulti-Criteria Decision Making (MCDM) Methods and ConceptsHamed TaherdoostNo ratings yet
- Picture Lab Student GuideDocument28 pagesPicture Lab Student Guidefreddy the gamerNo ratings yet
- Design Modeler Evaluation Guide A Quick Tutorial: Ansys, Inc. March, 2005Document91 pagesDesign Modeler Evaluation Guide A Quick Tutorial: Ansys, Inc. March, 2005hosseinidokht86No ratings yet