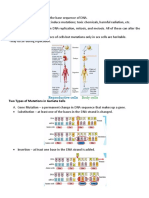
Download as docx, pdf, or txt
You might also like
- Oncogenes and Tumour Suppressor GenesDocument59 pagesOncogenes and Tumour Suppressor GenesXutjie FairdianaNo ratings yet
- C8e 24 Test BankDocument27 pagesC8e 24 Test BankSpencer MartinNo ratings yet
- BIO301 Current SolvedDocument4 pagesBIO301 Current SolvedHorain KhanNo ratings yet
- Genetics and Genomics For Nursing 1st Edition Kenner Test Bank 1Document36 pagesGenetics and Genomics For Nursing 1st Edition Kenner Test Bank 1hollyclarkebfaoejwrny100% (32)
- DNA Mutation and RepairDocument8 pagesDNA Mutation and RepairShaimaa EmadNo ratings yet
- Genotoxicity Project 1Document46 pagesGenotoxicity Project 1Vivek DNo ratings yet
- Chap. 5 Molecular Genetic Techniques: TopicsDocument28 pagesChap. 5 Molecular Genetic Techniques: TopicsanushkaNo ratings yet
- Homework 5 Chapt 13, 14, 15, 16, 17Document7 pagesHomework 5 Chapt 13, 14, 15, 16, 17ButterlesstoastNo ratings yet
- Polymorphism Introduction AymanDocument39 pagesPolymorphism Introduction AymanBasma Adel KhattabNo ratings yet
- Homework 5 Chapt 13, 14, 15, 16, 17 AnswersDocument11 pagesHomework 5 Chapt 13, 14, 15, 16, 17 AnswersButterlesstoastNo ratings yet
- Proteins Can Be Classified Into Two Broad TypesDocument19 pagesProteins Can Be Classified Into Two Broad TypesHelmi ZztNo ratings yet
- GRP 2 GeneticsDocument28 pagesGRP 2 GeneticsPaolo NaguitNo ratings yet
- 16 Genetic Mutations-S PDFDocument7 pages16 Genetic Mutations-S PDFHelp Me Study TutoringNo ratings yet
- What Is A Point MutationDocument6 pagesWhat Is A Point MutationDesi Steve JobsNo ratings yet
- Mutation and Genetic Variation: DR - Baraa Maraqa MD General PediatricianDocument41 pagesMutation and Genetic Variation: DR - Baraa Maraqa MD General Pediatriciananwar jabariNo ratings yet
- G-12 Biology, 3.4 MutationsDocument5 pagesG-12 Biology, 3.4 MutationsYohannes NigussieNo ratings yet
- 8 Approaches To Random MutagenesisDocument12 pages8 Approaches To Random Mutagenesischavi1310No ratings yet
- Muta GenesisDocument8 pagesMuta GenesisMuhammad_maadaniNo ratings yet
- MCB 104 - Quiz 1 Combined Answer Key PDFDocument5 pagesMCB 104 - Quiz 1 Combined Answer Key PDFazgaray7No ratings yet
- Nature of GeneDocument6 pagesNature of GeneAli JuttNo ratings yet
- Gene Expression and Genetics: MutationDocument23 pagesGene Expression and Genetics: Mutationprimal100% (1)
- Inbound 891828475094209013Document4 pagesInbound 891828475094209013Francine Allyson M. BlazaNo ratings yet
- Unitach 2 L 4Document16 pagesUnitach 2 L 4api-346504003No ratings yet
- Mutations and Their Implications: Omotade OO Institute of Child Health College of Medicine University of IbadanDocument41 pagesMutations and Their Implications: Omotade OO Institute of Child Health College of Medicine University of IbadanOlascholarNo ratings yet
- Transposon MutationDocument22 pagesTransposon Mutationrmk56270No ratings yet
- Garvan Institute of Medical Research - Genetics RefreshnerDocument17 pagesGarvan Institute of Medical Research - Genetics RefreshnerLuisaReyesNo ratings yet
- Loss-Of-Function, Gain-Of-Function and Dominant-Negative Mutations Have Profoundly Different Effects On Protein StructureDocument15 pagesLoss-Of-Function, Gain-Of-Function and Dominant-Negative Mutations Have Profoundly Different Effects On Protein StructurearagaoNo ratings yet
- Mutations: Types and Causes: Mutations Are Recessive or DominantDocument4 pagesMutations: Types and Causes: Mutations Are Recessive or DominantUsman MaukNo ratings yet
- Vogelstein Nm1087Document11 pagesVogelstein Nm1087Misha30No ratings yet
- Detailed Notes On Module 6 643fd17912a86 PDFDocument16 pagesDetailed Notes On Module 6 643fd17912a86 PDFTanisha PatelNo ratings yet
- Insights New111Document13 pagesInsights New111cassidy conchaNo ratings yet
- Heredity g10Document15 pagesHeredity g10Lucille SagayoNo ratings yet
- Chapter 14 Mutation and CancerDocument43 pagesChapter 14 Mutation and CancerCharlieHuangNo ratings yet
- TMP 60 B5Document26 pagesTMP 60 B5FrontiersNo ratings yet
- Hox Genes: Natural SelectionDocument4 pagesHox Genes: Natural SelectionMishti2No ratings yet
- CHROMOSOMAL MUTATION LectureDocument5 pagesCHROMOSOMAL MUTATION Lecturejeffersonmanalo787No ratings yet
- DNA Mutation and RepairDocument47 pagesDNA Mutation and Repairmoha666rNo ratings yet
- Chromatin Modi Cations and Their FunctionDocument13 pagesChromatin Modi Cations and Their FunctionualigolNo ratings yet
- Ch450 and Ch451: Biochemistry - Defining Life at The Molecular LevelDocument19 pagesCh450 and Ch451: Biochemistry - Defining Life at The Molecular LevelHasan AnandaNo ratings yet
- Correct Answer:: Alcohol Acetaldehyde Acetic AcidDocument5 pagesCorrect Answer:: Alcohol Acetaldehyde Acetic AcidTom TsouNo ratings yet
- Genetic ExpressionsDocument6 pagesGenetic ExpressionsRobertaNo ratings yet
- DNA Repair Mechanisms and Gametogenesis: ReviewDocument9 pagesDNA Repair Mechanisms and Gametogenesis: ReviewGabriel RibeiroNo ratings yet
- 13,3 MutationsDocument6 pages13,3 MutationsSanaa SamkoNo ratings yet
- Assignment # 01Document3 pagesAssignment # 01Daniyal ArifNo ratings yet
- Note: Topic Presentation 8 Will Be Your Guide in Answering This Activity. Answers: Gene ADocument5 pagesNote: Topic Presentation 8 Will Be Your Guide in Answering This Activity. Answers: Gene AKezel AtangenNo ratings yet
- Answers To End-of-Chapter Questions - Brooker Et Al ARIS SiteDocument4 pagesAnswers To End-of-Chapter Questions - Brooker Et Al ARIS SiteSharyproNo ratings yet
- Mutation Screenun April June 2015 2 GenevistaDocument4 pagesMutation Screenun April June 2015 2 GenevistaDivya MattaNo ratings yet
- Imprinting DisordersDocument19 pagesImprinting Disorderssenuberh13No ratings yet
- TMP 3Document3 pagesTMP 3FrontiersNo ratings yet
- BIOLABDocument4 pagesBIOLABerosNo ratings yet
- Molecular BiologyDocument44 pagesMolecular BiologyYasmin BalochNo ratings yet
- Chapter 7: Genetics Lesson 4: MutationsDocument8 pagesChapter 7: Genetics Lesson 4: Mutationssudhu sudsNo ratings yet
- CH 5Document97 pagesCH 5jaraulabelleNo ratings yet
- Chapter 7 - Mechanisms of Cell DeathDocument22 pagesChapter 7 - Mechanisms of Cell DeathCynthia Lopes100% (1)
- What Causes DNA Mutations?: B.6.E Identify and Illustrate Changes in DNA and Evaluate The Significance of These ChangesDocument6 pagesWhat Causes DNA Mutations?: B.6.E Identify and Illustrate Changes in DNA and Evaluate The Significance of These ChangesHayeon LeeNo ratings yet
- Name: Ricki Elaine Dalipe Sched: Wed 1-6pmDocument4 pagesName: Ricki Elaine Dalipe Sched: Wed 1-6pmZeid ZiedNo ratings yet
- Biomedical Basis of Disease NotesDocument20 pagesBiomedical Basis of Disease Notesteganswann2004No ratings yet
- AQA Biology A-Level: Topic 8: The Control of Gene ExpressionDocument9 pagesAQA Biology A-Level: Topic 8: The Control of Gene ExpressionsamNo ratings yet
- Gene MutationDocument22 pagesGene MutationMahrose NawazNo ratings yet
- Genetic DiseasesDocument28 pagesGenetic DiseasesdmorcfNo ratings yet
- Evolution - WikipediaDocument51 pagesEvolution - WikipediagenshaoxNo ratings yet
- Perspectives: Overcoming Challenges and Dogmas To Understand The Functions of PseudogenesDocument11 pagesPerspectives: Overcoming Challenges and Dogmas To Understand The Functions of Pseudogenesİzem DevecioğluNo ratings yet
- AutisminreviewDocument7 pagesAutisminreviewErsya Muslih AnshoriNo ratings yet
- Chromosomal Rearrangements 1Document52 pagesChromosomal Rearrangements 1Angel TaylorNo ratings yet
- Mutation and Its TypesDocument21 pagesMutation and Its TypesDr.Noman AsgharNo ratings yet
- Dna ST N FXNDocument11 pagesDna ST N FXNJyoti JoshiNo ratings yet
- How Genomes EvolveDocument21 pagesHow Genomes EvolveMahmood-S ChoudheryNo ratings yet
- Microduplication of xp22.31Document4 pagesMicroduplication of xp22.31Roberth SanchezNo ratings yet
- Science: Quarter 3 - Module 5Document29 pagesScience: Quarter 3 - Module 5Amara ValleNo ratings yet
- AMP CancerDocument20 pagesAMP Cancerprateek bhatiaNo ratings yet
- MutationDocument52 pagesMutationIlovecats AndmeNo ratings yet
- Genetics - CMIDocument177 pagesGenetics - CMI7ett_100% (1)
- Mutations NotesDocument4 pagesMutations NotesYukiichris Lam0% (1)
- Ch4 Lecture SlidesDocument34 pagesCh4 Lecture SlidesJad AwadNo ratings yet
- Down's Syndrome Invetigsatory ProjectDocument23 pagesDown's Syndrome Invetigsatory ProjectKrithishNo ratings yet
- MYB Transcription Factor Families in Rice and ArabidopsisDocument19 pagesMYB Transcription Factor Families in Rice and ArabidopsisshivaNo ratings yet
- Types of MutationsDocument64 pagesTypes of MutationsI'm Cracked100% (1)
- Science Reviewer MutationDocument4 pagesScience Reviewer MutationTalao, Angelie Rei S.No ratings yet
- Archaeogenetics Module CambridgeDocument5 pagesArchaeogenetics Module Cambridgejg282No ratings yet
- MutationDocument24 pagesMutationVivion JacobNo ratings yet
- Alvin Ip PDFDocument68 pagesAlvin Ip PDFmochkurniawanNo ratings yet
- A Bountiful Harvest: Genomic Insights Into Crop Domestication PhenotypesDocument27 pagesA Bountiful Harvest: Genomic Insights Into Crop Domestication PhenotypesAndresNo ratings yet
- 6 MUTATION LatestDocument67 pages6 MUTATION LatesthashimNo ratings yet
- Guardant360 A0771104 v1 FinalDocument6 pagesGuardant360 A0771104 v1 FinaltraveltreatsteluguNo ratings yet
- Microduplicación de SíndromesDocument13 pagesMicroduplicación de SíndromesDiana ToroNo ratings yet
- Review The Origins of Genome Architecture PDFDocument3 pagesReview The Origins of Genome Architecture PDFMatiasNo ratings yet
- FISH-MLPA-Array Based Detection For 18q DeletionDocument8 pagesFISH-MLPA-Array Based Detection For 18q DeletionladybieibiNo ratings yet
- Ibervillea SonoraeDocument7 pagesIbervillea SonoraesandraNo ratings yet
- Chapter 23 - Population GeneticsDocument99 pagesChapter 23 - Population GeneticsscribblerofnonsenseNo ratings yet