
2013 SIGMETRICS Heavytails
2013 SIGMETRICS Heavytails
You might also like
- Chapter 9 Drops Dynamics and DaisiesDocument15 pagesChapter 9 Drops Dynamics and DaisiesJAEZAR PHILIP GRAGASINNo ratings yet
- Trip GenerationDocument36 pagesTrip GenerationsatishsajjaNo ratings yet
- IDS2a Data, Science, Data ScienceDocument40 pagesIDS2a Data, Science, Data ScienceT DoNo ratings yet
- CH 04Document80 pagesCH 04kir223No ratings yet
- Introduction To Fuzzy: Diambil Dari Materi Kuliah Oleh: - Weldon A. Lodwick - Gao Xinbo (E.E. Dept., Xidian University)Document26 pagesIntroduction To Fuzzy: Diambil Dari Materi Kuliah Oleh: - Weldon A. Lodwick - Gao Xinbo (E.E. Dept., Xidian University)radifahNo ratings yet
- Unit 3Document33 pagesUnit 3Nandyala Venkanna BabuNo ratings yet
- Sample Paragraphs Essay StandardsDocument20 pagesSample Paragraphs Essay Standardsapi-329175631No ratings yet
- Getting Cyc-Ed About Inference: Christopher CoxDocument23 pagesGetting Cyc-Ed About Inference: Christopher CoxcutithongtinNo ratings yet
- Lyon Normal DistributionsDocument25 pagesLyon Normal DistributionsNav SahiNo ratings yet
- BasicProbDocument13 pagesBasicProbMuhamad Ghufron MusyafaNo ratings yet
- Chapter 1 Overview of Basic Probability TheoryDocument17 pagesChapter 1 Overview of Basic Probability Theoryjared demissieNo ratings yet
- Ref1 6 PDFDocument139 pagesRef1 6 PDFSHR extremeNo ratings yet
- Siti Zaiton - Fuzzy1Document48 pagesSiti Zaiton - Fuzzy1Triana Dian NisaNo ratings yet
- Economic Statistics - Set Theory and Probability For BeginersDocument35 pagesEconomic Statistics - Set Theory and Probability For BeginersPranav SinghNo ratings yet
- Why Do We Assume That Extraterrestrial Life Is CarbonDocument7 pagesWhy Do We Assume That Extraterrestrial Life Is CarbonFernan MadyNo ratings yet
- Session 11 - 12Document15 pagesSession 11 - 12Aakif SajjadNo ratings yet
- UTC2715 - UTS2707 #2 Dynamics & ChaosDocument55 pagesUTC2715 - UTS2707 #2 Dynamics & ChaosChang JingyanNo ratings yet
- Moments A Must Known Statistical Concept For Data ScienceDocument6 pagesMoments A Must Known Statistical Concept For Data ScienceRavi Shankar VermaNo ratings yet
- Skew Ness Kurtosis and MomentsDocument31 pagesSkew Ness Kurtosis and MomentsDr. POONAM KAUSHALNo ratings yet
- Logical SpatiallDocument130 pagesLogical SpatiallRoy C. DomantayNo ratings yet
- Lecture 1 IntroductionDocument34 pagesLecture 1 IntroductionPia MendozaNo ratings yet
- Unit 10Document13 pagesUnit 1016kuldeepgautamNo ratings yet
- Statistic IntroductionDocument68 pagesStatistic IntroductionDeenNo ratings yet
- Lect 6Document23 pagesLect 6steve ogagaNo ratings yet
- Fuzzy LogicDocument95 pagesFuzzy LogicRohitRajNo ratings yet
- PHY 211: Introduction To Quantum Mechanics, Varsha 2009: School of Physics, IISER TVMDocument5 pagesPHY 211: Introduction To Quantum Mechanics, Varsha 2009: School of Physics, IISER TVMAjay KaladharanNo ratings yet
- Chapter I. Random Variables and Probability DistributionsDocument3 pagesChapter I. Random Variables and Probability DistributionsmiraNo ratings yet
- Fundamental Biostatistics Dillon JonesDocument68 pagesFundamental Biostatistics Dillon JoneselodrasNo ratings yet
- DM Week 8 KNN 18042022 104212amDocument41 pagesDM Week 8 KNN 18042022 104212amMuhammad Umer FarooqNo ratings yet
- What Is The Nature of ScienceDocument16 pagesWhat Is The Nature of ScienceAshita NaikNo ratings yet
- Mathematics for MLDocument69 pagesMathematics for MLMeghana VNo ratings yet
- Chapter I. Random Variables and Probability DistributionsDocument2 pagesChapter I. Random Variables and Probability DistributionsmiraNo ratings yet
- Stat230 Chapter01Document5 pagesStat230 Chapter01Maya Abdul HusseinNo ratings yet
- Mitchell Scientific Religious Belief BDocument82 pagesMitchell Scientific Religious Belief Bmeteoro313No ratings yet
- String Theory Thesis PaperDocument7 pagesString Theory Thesis PaperWendy Belieu100% (2)
- Fuzzy Logic: Abhay Kumar Associate Professor DFT, NIFT, PatnaDocument25 pagesFuzzy Logic: Abhay Kumar Associate Professor DFT, NIFT, PatnaMard GeerNo ratings yet
- Chapter 3 Inductive DeductiveDocument31 pagesChapter 3 Inductive DeductiveNaimNo ratings yet
- Fuzzy Intro and PropertiesDocument72 pagesFuzzy Intro and Propertiesakbar mirzaNo ratings yet
- Handout 1-Foundations of Probability TheoryDocument27 pagesHandout 1-Foundations of Probability Theorylwandle221No ratings yet
- To Infinity and BeyondDocument2 pagesTo Infinity and BeyondKaushalya DebiNo ratings yet
- Lecture 0: Background: Rafael A. Irizarry and Hector Corrada Bravo January 2010Document3 pagesLecture 0: Background: Rafael A. Irizarry and Hector Corrada Bravo January 2010Sridhar SundaramurthyNo ratings yet
- Introduction To Elementary LogicDocument60 pagesIntroduction To Elementary LogicEmi OkayasuNo ratings yet
- How Should Philosophers Interpret Quantum Physics?: BUPS Conference Submission 2Document7 pagesHow Should Philosophers Interpret Quantum Physics?: BUPS Conference Submission 2Fred_MayweatherNo ratings yet
- Topic 5Document33 pagesTopic 5hanna 90No ratings yet
- MAS3301 Bayesian Statistics: M. Farrow School of Mathematics and Statistics Newcastle University Semester 2, 2008-9Document9 pagesMAS3301 Bayesian Statistics: M. Farrow School of Mathematics and Statistics Newcastle University Semester 2, 2008-9SimeonNo ratings yet
- Hyperborean PhysicsDocument98 pagesHyperborean PhysicsotherworksNo ratings yet
- A Mathematical Model For CorruptionDocument42 pagesA Mathematical Model For Corruptionaawwdz zdwwaaNo ratings yet
- An Introduction To Information Theory and Entropy: Tom Carter CSU StanislausDocument139 pagesAn Introduction To Information Theory and Entropy: Tom Carter CSU StanislausAchuthanand MukundanNo ratings yet
- BootstrapDocument32 pagesBootstrapPrajwal S PrakashNo ratings yet
- Ask Me For Random Process: CautionDocument3 pagesAsk Me For Random Process: CautionHudaa EltNo ratings yet
- Engineering Science … You Know More Than You Think: Tales from Playgrounds and Your Own BackyardFrom EverandEngineering Science … You Know More Than You Think: Tales from Playgrounds and Your Own BackyardNo ratings yet
- StatsProb W1Document38 pagesStatsProb W1E L L ENo ratings yet
- Characteristics of Normal DistributionDocument12 pagesCharacteristics of Normal DistributionMuhammad SatriyoNo ratings yet
- Lecture 2 FibonacciDocument50 pagesLecture 2 Fibonacciregien orpillaNo ratings yet
- Uzzy Ogic: Amit Raj Satyal Bigyan Sapkota Krishna Paudyal Simon Shrestha Subash Paudyal 14 February 2012Document54 pagesUzzy Ogic: Amit Raj Satyal Bigyan Sapkota Krishna Paudyal Simon Shrestha Subash Paudyal 14 February 2012Sanjeev Kumar GuptaNo ratings yet
- Foundations of MathematicsDocument148 pagesFoundations of MathematicsAhmad Alhour100% (2)
- Disjoint IndependentDocument22 pagesDisjoint IndependentPrachuriyaNo ratings yet
- LN5 2017Document28 pagesLN5 2017Dwi KuswantoNo ratings yet
- QueueingDocument43 pagesQueueingAtakan KorkmazlarNo ratings yet
- Binary Search Tree: Reny JoseDocument36 pagesBinary Search Tree: Reny JoseReny JoseNo ratings yet
- Peter Atkins Julio de Paula Ron Friedman Physical Chemistry Quanta (0613-0663)Document51 pagesPeter Atkins Julio de Paula Ron Friedman Physical Chemistry Quanta (0613-0663)Administracion OTIC IVICNo ratings yet
- Unit 5 Problem SetDocument2 pagesUnit 5 Problem SetKaren LuNo ratings yet
- Principles of Parallel Algorithm DesignDocument78 pagesPrinciples of Parallel Algorithm DesignKarthik LaxmikanthNo ratings yet
- 4.-Student Dropout Prediction 2020Document12 pages4.-Student Dropout Prediction 2020Cap Scyte Victor MariscalNo ratings yet
- Numerical Solution of Black-Scholes EquationDocument8 pagesNumerical Solution of Black-Scholes EquationeshariffNo ratings yet
- 6 Image Segmentation CombinedDocument40 pages6 Image Segmentation CombinedMuhammad Zaka Ud DinNo ratings yet
- Assignment 8 Sol ECON3202Document5 pagesAssignment 8 Sol ECON3202yizzy0% (1)
- Analytical and Numerical Methods of Structural AnalysisDocument50 pagesAnalytical and Numerical Methods of Structural AnalysisLuis Montoya100% (1)
- Development of Dental Autoclave Control System Using Fuzzy Logic and Optimized PID AlgorithmDocument8 pagesDevelopment of Dental Autoclave Control System Using Fuzzy Logic and Optimized PID AlgorithmMelanie PowellNo ratings yet
- Lecture 1.2.5 - Relational Model (RM)Document15 pagesLecture 1.2.5 - Relational Model (RM)Annanya JoshiNo ratings yet
- Addition and Subtraction of MatricesDocument3 pagesAddition and Subtraction of MatricesNia RamNo ratings yet
- EN5101 Digital Control Systems: Kalman FilterDocument6 pagesEN5101 Digital Control Systems: Kalman FilterAbdesselem BoulkrouneNo ratings yet
- Numeric in Hydraulic Engineering: Finite Volume Method (FVM)Document48 pagesNumeric in Hydraulic Engineering: Finite Volume Method (FVM)Binaya Raj PandeyNo ratings yet
- Unit-4 Introduction To Data MiningDocument26 pagesUnit-4 Introduction To Data MiningShaheen MondalNo ratings yet
- Quantum Gravity and A Time Operator in Relativistic Quantum MechanicsDocument10 pagesQuantum Gravity and A Time Operator in Relativistic Quantum MechanicsJulian BermudezNo ratings yet
- Linear Functions TestDocument5 pagesLinear Functions Testapi-437363879No ratings yet
- C Programming and Data StructuresDocument5 pagesC Programming and Data StructuresMENAGANo ratings yet
- Array Abstract Data Type in C - Dot Net TutorialsDocument2 pagesArray Abstract Data Type in C - Dot Net TutorialsQuazi Hasnat IrfanNo ratings yet
- Data Structure Mid Exam, Summer 2020Document1 pageData Structure Mid Exam, Summer 2020Ifthakher RahmanNo ratings yet
- Asymptotic Analysis: ObjectivesDocument20 pagesAsymptotic Analysis: ObjectivesKyle DandoyNo ratings yet
- Ch2a Example Root Finding MethodsDocument7 pagesCh2a Example Root Finding MethodsSK. BayzeedNo ratings yet
- Signal Processing I: Sebastián Roldán Vasco Sebastianroldan@itm - Edu.coDocument28 pagesSignal Processing I: Sebastián Roldán Vasco Sebastianroldan@itm - Edu.coDaniela GiraldoNo ratings yet
- T5 Worksheet 5Document6 pagesT5 Worksheet 5ajeesharulkumaranNo ratings yet
- CS F211Document3 pagesCS F211AMOGH SAXENANo ratings yet
- Ask04 - Transportation, Assignment, TransshipmentDocument35 pagesAsk04 - Transportation, Assignment, TransshipmentKame OtokoNo ratings yet
- Data StructureDocument72 pagesData StructureGuruKPO100% (2)
- 1 s2.0 S0010482522005686 MainDocument8 pages1 s2.0 S0010482522005686 MainsamashrafNo ratings yet














































































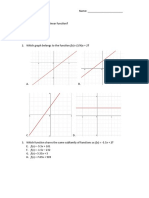











Download as pdf or txt
You might also like
- Chapter 9 Drops Dynamics and DaisiesDocument15 pagesChapter 9 Drops Dynamics and DaisiesJAEZAR PHILIP GRAGASINNo ratings yet
- Trip GenerationDocument36 pagesTrip GenerationsatishsajjaNo ratings yet
- IDS2a Data, Science, Data ScienceDocument40 pagesIDS2a Data, Science, Data ScienceT DoNo ratings yet
- CH 04Document80 pagesCH 04kir223No ratings yet
- Introduction To Fuzzy: Diambil Dari Materi Kuliah Oleh: - Weldon A. Lodwick - Gao Xinbo (E.E. Dept., Xidian University)Document26 pagesIntroduction To Fuzzy: Diambil Dari Materi Kuliah Oleh: - Weldon A. Lodwick - Gao Xinbo (E.E. Dept., Xidian University)radifahNo ratings yet
- Unit 3Document33 pagesUnit 3Nandyala Venkanna BabuNo ratings yet
- Sample Paragraphs Essay StandardsDocument20 pagesSample Paragraphs Essay Standardsapi-329175631No ratings yet
- Getting Cyc-Ed About Inference: Christopher CoxDocument23 pagesGetting Cyc-Ed About Inference: Christopher CoxcutithongtinNo ratings yet
- Lyon Normal DistributionsDocument25 pagesLyon Normal DistributionsNav SahiNo ratings yet
- BasicProbDocument13 pagesBasicProbMuhamad Ghufron MusyafaNo ratings yet
- Chapter 1 Overview of Basic Probability TheoryDocument17 pagesChapter 1 Overview of Basic Probability Theoryjared demissieNo ratings yet
- Ref1 6 PDFDocument139 pagesRef1 6 PDFSHR extremeNo ratings yet
- Siti Zaiton - Fuzzy1Document48 pagesSiti Zaiton - Fuzzy1Triana Dian NisaNo ratings yet
- Economic Statistics - Set Theory and Probability For BeginersDocument35 pagesEconomic Statistics - Set Theory and Probability For BeginersPranav SinghNo ratings yet
- Why Do We Assume That Extraterrestrial Life Is CarbonDocument7 pagesWhy Do We Assume That Extraterrestrial Life Is CarbonFernan MadyNo ratings yet
- Session 11 - 12Document15 pagesSession 11 - 12Aakif SajjadNo ratings yet
- UTC2715 - UTS2707 #2 Dynamics & ChaosDocument55 pagesUTC2715 - UTS2707 #2 Dynamics & ChaosChang JingyanNo ratings yet
- Moments A Must Known Statistical Concept For Data ScienceDocument6 pagesMoments A Must Known Statistical Concept For Data ScienceRavi Shankar VermaNo ratings yet
- Skew Ness Kurtosis and MomentsDocument31 pagesSkew Ness Kurtosis and MomentsDr. POONAM KAUSHALNo ratings yet
- Logical SpatiallDocument130 pagesLogical SpatiallRoy C. DomantayNo ratings yet
- Lecture 1 IntroductionDocument34 pagesLecture 1 IntroductionPia MendozaNo ratings yet
- Unit 10Document13 pagesUnit 1016kuldeepgautamNo ratings yet
- Statistic IntroductionDocument68 pagesStatistic IntroductionDeenNo ratings yet
- Lect 6Document23 pagesLect 6steve ogagaNo ratings yet
- Fuzzy LogicDocument95 pagesFuzzy LogicRohitRajNo ratings yet
- PHY 211: Introduction To Quantum Mechanics, Varsha 2009: School of Physics, IISER TVMDocument5 pagesPHY 211: Introduction To Quantum Mechanics, Varsha 2009: School of Physics, IISER TVMAjay KaladharanNo ratings yet
- Chapter I. Random Variables and Probability DistributionsDocument3 pagesChapter I. Random Variables and Probability DistributionsmiraNo ratings yet
- Fundamental Biostatistics Dillon JonesDocument68 pagesFundamental Biostatistics Dillon JoneselodrasNo ratings yet
- DM Week 8 KNN 18042022 104212amDocument41 pagesDM Week 8 KNN 18042022 104212amMuhammad Umer FarooqNo ratings yet
- What Is The Nature of ScienceDocument16 pagesWhat Is The Nature of ScienceAshita NaikNo ratings yet
- Mathematics for MLDocument69 pagesMathematics for MLMeghana VNo ratings yet
- Chapter I. Random Variables and Probability DistributionsDocument2 pagesChapter I. Random Variables and Probability DistributionsmiraNo ratings yet
- Stat230 Chapter01Document5 pagesStat230 Chapter01Maya Abdul HusseinNo ratings yet
- Mitchell Scientific Religious Belief BDocument82 pagesMitchell Scientific Religious Belief Bmeteoro313No ratings yet
- String Theory Thesis PaperDocument7 pagesString Theory Thesis PaperWendy Belieu100% (2)
- Fuzzy Logic: Abhay Kumar Associate Professor DFT, NIFT, PatnaDocument25 pagesFuzzy Logic: Abhay Kumar Associate Professor DFT, NIFT, PatnaMard GeerNo ratings yet
- Chapter 3 Inductive DeductiveDocument31 pagesChapter 3 Inductive DeductiveNaimNo ratings yet
- Fuzzy Intro and PropertiesDocument72 pagesFuzzy Intro and Propertiesakbar mirzaNo ratings yet
- Handout 1-Foundations of Probability TheoryDocument27 pagesHandout 1-Foundations of Probability Theorylwandle221No ratings yet
- To Infinity and BeyondDocument2 pagesTo Infinity and BeyondKaushalya DebiNo ratings yet
- Lecture 0: Background: Rafael A. Irizarry and Hector Corrada Bravo January 2010Document3 pagesLecture 0: Background: Rafael A. Irizarry and Hector Corrada Bravo January 2010Sridhar SundaramurthyNo ratings yet
- Introduction To Elementary LogicDocument60 pagesIntroduction To Elementary LogicEmi OkayasuNo ratings yet
- How Should Philosophers Interpret Quantum Physics?: BUPS Conference Submission 2Document7 pagesHow Should Philosophers Interpret Quantum Physics?: BUPS Conference Submission 2Fred_MayweatherNo ratings yet
- Topic 5Document33 pagesTopic 5hanna 90No ratings yet
- MAS3301 Bayesian Statistics: M. Farrow School of Mathematics and Statistics Newcastle University Semester 2, 2008-9Document9 pagesMAS3301 Bayesian Statistics: M. Farrow School of Mathematics and Statistics Newcastle University Semester 2, 2008-9SimeonNo ratings yet
- Hyperborean PhysicsDocument98 pagesHyperborean PhysicsotherworksNo ratings yet
- A Mathematical Model For CorruptionDocument42 pagesA Mathematical Model For Corruptionaawwdz zdwwaaNo ratings yet
- An Introduction To Information Theory and Entropy: Tom Carter CSU StanislausDocument139 pagesAn Introduction To Information Theory and Entropy: Tom Carter CSU StanislausAchuthanand MukundanNo ratings yet
- BootstrapDocument32 pagesBootstrapPrajwal S PrakashNo ratings yet
- Ask Me For Random Process: CautionDocument3 pagesAsk Me For Random Process: CautionHudaa EltNo ratings yet
- Engineering Science … You Know More Than You Think: Tales from Playgrounds and Your Own BackyardFrom EverandEngineering Science … You Know More Than You Think: Tales from Playgrounds and Your Own BackyardNo ratings yet
- StatsProb W1Document38 pagesStatsProb W1E L L ENo ratings yet
- Characteristics of Normal DistributionDocument12 pagesCharacteristics of Normal DistributionMuhammad SatriyoNo ratings yet
- Lecture 2 FibonacciDocument50 pagesLecture 2 Fibonacciregien orpillaNo ratings yet
- Uzzy Ogic: Amit Raj Satyal Bigyan Sapkota Krishna Paudyal Simon Shrestha Subash Paudyal 14 February 2012Document54 pagesUzzy Ogic: Amit Raj Satyal Bigyan Sapkota Krishna Paudyal Simon Shrestha Subash Paudyal 14 February 2012Sanjeev Kumar GuptaNo ratings yet
- Foundations of MathematicsDocument148 pagesFoundations of MathematicsAhmad Alhour100% (2)
- Disjoint IndependentDocument22 pagesDisjoint IndependentPrachuriyaNo ratings yet
- LN5 2017Document28 pagesLN5 2017Dwi KuswantoNo ratings yet
- QueueingDocument43 pagesQueueingAtakan KorkmazlarNo ratings yet
- Binary Search Tree: Reny JoseDocument36 pagesBinary Search Tree: Reny JoseReny JoseNo ratings yet
- Peter Atkins Julio de Paula Ron Friedman Physical Chemistry Quanta (0613-0663)Document51 pagesPeter Atkins Julio de Paula Ron Friedman Physical Chemistry Quanta (0613-0663)Administracion OTIC IVICNo ratings yet
- Unit 5 Problem SetDocument2 pagesUnit 5 Problem SetKaren LuNo ratings yet
- Principles of Parallel Algorithm DesignDocument78 pagesPrinciples of Parallel Algorithm DesignKarthik LaxmikanthNo ratings yet
- 4.-Student Dropout Prediction 2020Document12 pages4.-Student Dropout Prediction 2020Cap Scyte Victor MariscalNo ratings yet
- Numerical Solution of Black-Scholes EquationDocument8 pagesNumerical Solution of Black-Scholes EquationeshariffNo ratings yet
- 6 Image Segmentation CombinedDocument40 pages6 Image Segmentation CombinedMuhammad Zaka Ud DinNo ratings yet
- Assignment 8 Sol ECON3202Document5 pagesAssignment 8 Sol ECON3202yizzy0% (1)
- Analytical and Numerical Methods of Structural AnalysisDocument50 pagesAnalytical and Numerical Methods of Structural AnalysisLuis Montoya100% (1)
- Development of Dental Autoclave Control System Using Fuzzy Logic and Optimized PID AlgorithmDocument8 pagesDevelopment of Dental Autoclave Control System Using Fuzzy Logic and Optimized PID AlgorithmMelanie PowellNo ratings yet
- Lecture 1.2.5 - Relational Model (RM)Document15 pagesLecture 1.2.5 - Relational Model (RM)Annanya JoshiNo ratings yet
- Addition and Subtraction of MatricesDocument3 pagesAddition and Subtraction of MatricesNia RamNo ratings yet
- EN5101 Digital Control Systems: Kalman FilterDocument6 pagesEN5101 Digital Control Systems: Kalman FilterAbdesselem BoulkrouneNo ratings yet
- Numeric in Hydraulic Engineering: Finite Volume Method (FVM)Document48 pagesNumeric in Hydraulic Engineering: Finite Volume Method (FVM)Binaya Raj PandeyNo ratings yet
- Unit-4 Introduction To Data MiningDocument26 pagesUnit-4 Introduction To Data MiningShaheen MondalNo ratings yet
- Quantum Gravity and A Time Operator in Relativistic Quantum MechanicsDocument10 pagesQuantum Gravity and A Time Operator in Relativistic Quantum MechanicsJulian BermudezNo ratings yet
- Linear Functions TestDocument5 pagesLinear Functions Testapi-437363879No ratings yet
- C Programming and Data StructuresDocument5 pagesC Programming and Data StructuresMENAGANo ratings yet
- Array Abstract Data Type in C - Dot Net TutorialsDocument2 pagesArray Abstract Data Type in C - Dot Net TutorialsQuazi Hasnat IrfanNo ratings yet
- Data Structure Mid Exam, Summer 2020Document1 pageData Structure Mid Exam, Summer 2020Ifthakher RahmanNo ratings yet
- Asymptotic Analysis: ObjectivesDocument20 pagesAsymptotic Analysis: ObjectivesKyle DandoyNo ratings yet
- Ch2a Example Root Finding MethodsDocument7 pagesCh2a Example Root Finding MethodsSK. BayzeedNo ratings yet
- Signal Processing I: Sebastián Roldán Vasco Sebastianroldan@itm - Edu.coDocument28 pagesSignal Processing I: Sebastián Roldán Vasco Sebastianroldan@itm - Edu.coDaniela GiraldoNo ratings yet
- T5 Worksheet 5Document6 pagesT5 Worksheet 5ajeesharulkumaranNo ratings yet
- CS F211Document3 pagesCS F211AMOGH SAXENANo ratings yet
- Ask04 - Transportation, Assignment, TransshipmentDocument35 pagesAsk04 - Transportation, Assignment, TransshipmentKame OtokoNo ratings yet
- Data StructureDocument72 pagesData StructureGuruKPO100% (2)
- 1 s2.0 S0010482522005686 MainDocument8 pages1 s2.0 S0010482522005686 MainsamashrafNo ratings yet