Download as pdf or txt
You might also like
- Unit 31 Statistics For ManagementAssignment 1 (LO1 - LOs) 1Document3 pagesUnit 31 Statistics For ManagementAssignment 1 (LO1 - LOs) 1H A0% (1)
- Business Analytics Using SASDocument117 pagesBusiness Analytics Using SASsujit9100% (5)
- E. O. WilsonDocument10 pagesE. O. Wilsoncdla14No ratings yet
- M16 M4 Service Rifle FamiliarizationDocument16 pagesM16 M4 Service Rifle FamiliarizationAnonymous mcJZ1wVX89No ratings yet
- Method Statement For Installation of Wiring DevicesDocument6 pagesMethod Statement For Installation of Wiring DevicesMohammed Mujeeb Ali Fathaan100% (2)
- Bolt Tightening ProcedureDocument6 pagesBolt Tightening Procedureal arabiNo ratings yet
- CPI2010 Short Method enDocument1 pageCPI2010 Short Method enypodvysotskiyNo ratings yet
- Shah Thompson Transparency International CpiDocument53 pagesShah Thompson Transparency International CpiHelder JohnsonNo ratings yet
- 2019 CPI MethodologyDocument29 pages2019 CPI MethodologyAbdullah shah khavreenNo ratings yet
- CorruptionDocument6 pagesCorruptionVELE YAAR VINESNo ratings yet
- Indeks Perspesi Korupsi 2013Document15 pagesIndeks Perspesi Korupsi 2013Bambang AriyantoNo ratings yet
- Corruption Perception Index 2003: January 2004Document16 pagesCorruption Perception Index 2003: January 2004EmmaNo ratings yet
- Corruption Perceptions Index 2011 Full Source Description Sources Included in The CPI 2011Document18 pagesCorruption Perceptions Index 2011 Full Source Description Sources Included in The CPI 2011Manish VermaNo ratings yet
- UK Home Office: 2005-10-14 Grading Methods 1Document12 pagesUK Home Office: 2005-10-14 Grading Methods 1UK_HomeOfficeNo ratings yet
- Credit Risk and Financial Integration: An Application of Network AnalysisDocument3 pagesCredit Risk and Financial Integration: An Application of Network AnalysiskamransNo ratings yet
- ILO Modelled Estimates 2019Document18 pagesILO Modelled Estimates 2019anshulpatel0608No ratings yet
- Measurement GER NER GPI - Version 1.0Document8 pagesMeasurement GER NER GPI - Version 1.0Wouter RijneveldNo ratings yet
- تقرير حول وضع ليبيا في مؤشر مدركات 2015 انجليزيDocument13 pagesتقرير حول وضع ليبيا في مؤشر مدركات 2015 انجليزيYahia Mustafa AlfazaziNo ratings yet
- GP Long Version 2023-2024 - 2nd Q (Jul To Sep) - Long VersionDocument187 pagesGP Long Version 2023-2024 - 2nd Q (Jul To Sep) - Long VersionJim Buti Jim Buti MohlalaNo ratings yet
- CPI 2009 Methodology Long enDocument10 pagesCPI 2009 Methodology Long enwinniepooh310No ratings yet
- Artikel Ilmiah Kelompok 4 Statistika Dan ParametrikaDocument16 pagesArtikel Ilmiah Kelompok 4 Statistika Dan ParametrikaFrancis Raphael SendaloNo ratings yet
- Correlation Sudan Mariuxi CastroDocument14 pagesCorrelation Sudan Mariuxi CastroLitopez YepezNo ratings yet
- Global Integrity Index: Click Here To DownloadDocument4 pagesGlobal Integrity Index: Click Here To DownloadAdministración GubernamentalNo ratings yet
- Chapter Three Final 1Document8 pagesChapter Three Final 1Syiera Fella'sNo ratings yet
- 2021 ComplianceLine Hotline Benchmark ReportDocument46 pages2021 ComplianceLine Hotline Benchmark ReporttabitaNo ratings yet
- Edu - Irs 1Document7 pagesEdu - Irs 1Wouter RijneveldNo ratings yet
- Icitsi2014 Submission 55Document5 pagesIcitsi2014 Submission 55kasarung28No ratings yet
- Impact of Corruption On Economic GrowthDocument8 pagesImpact of Corruption On Economic GrowthHamzah Bhatti100% (2)
- Political Risk, Economic Risk and Financial Risk: Claude B. ErbDocument20 pagesPolitical Risk, Economic Risk and Financial Risk: Claude B. ErbShwetha HvNo ratings yet
- Fazekas Corruption IndexDocument29 pagesFazekas Corruption IndexPaola Gomez BolañosNo ratings yet
- Gov Matters 5 No AnnexDocument45 pagesGov Matters 5 No AnnexLaura McMilliganNo ratings yet
- WHO - HMN HIS Tools To Support GFR10 - Template For Costing The HIS GapDocument202 pagesWHO - HMN HIS Tools To Support GFR10 - Template For Costing The HIS GapHarumNo ratings yet
- Chapter 3 MethodologyDocument11 pagesChapter 3 Methodologyassignment helpNo ratings yet
- UK Home Office: Aud0303Document20 pagesUK Home Office: Aud0303UK_HomeOfficeNo ratings yet
- Paper 30-Financial Statement Fraud Detection Using Text MiningDocument3 pagesPaper 30-Financial Statement Fraud Detection Using Text MiningEditor IJACSANo ratings yet
- Abo Chapter Three UsefulDocument8 pagesAbo Chapter Three UsefulAkanni Lateef ONo ratings yet
- Conducting Data Audits and Service Audits and Service ReviewsDocument13 pagesConducting Data Audits and Service Audits and Service ReviewsGurava ReddyNo ratings yet
- Chapter IIIDocument4 pagesChapter IIIDilip MargamNo ratings yet
- Corruption N Public Investment N GrowthDocument24 pagesCorruption N Public Investment N GrowthAditi SharmaNo ratings yet
- COMPAS Risk & Need Assessment System: Selected Questions Posed by Inquiring AgenciesDocument11 pagesCOMPAS Risk & Need Assessment System: Selected Questions Posed by Inquiring AgenciesYoshua HamashiachNo ratings yet
- ReportDocument13 pagesReportIsac JuniorNo ratings yet
- 3is Interpretation of Quantitative DataDocument13 pages3is Interpretation of Quantitative Dataabueza54No ratings yet
- Chapter 1 - Statistics in ManagementDocument20 pagesChapter 1 - Statistics in Managementtmakgalemele05No ratings yet
- Data Quality AssesmentDocument8 pagesData Quality AssesmentThích Ngồi KhôngNo ratings yet
- Chapter ThreeDocument5 pagesChapter ThreeHenry BitrusNo ratings yet
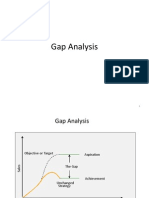
- Gap, ETOP Analyses, BSCDocument28 pagesGap, ETOP Analyses, BSCniaz11788No ratings yet
- Predictive Modelling of Crime Dataset Using Data MiningDocument16 pagesPredictive Modelling of Crime Dataset Using Data MiningLewis TorresNo ratings yet
- WEF - The Global Competitiveness Report 2019-630-641Document12 pagesWEF - The Global Competitiveness Report 2019-630-641tiikaaNo ratings yet
- Collating Datasets: Cross Sectional, Panel and Time Series DataDocument18 pagesCollating Datasets: Cross Sectional, Panel and Time Series DataAbijeet SinghNo ratings yet
- 7 Types of Statistical Analysis TechniquesDocument7 pages7 Types of Statistical Analysis Techniques211095907No ratings yet
- ICRG MethodologyDocument20 pagesICRG MethodologyMahmud HasanNo ratings yet
- ICRG MethodologyDocument20 pagesICRG MethodologyAvijit Bhowmick AviNo ratings yet
- Finance Risk Analytics - Priyanka Sharma - Business ReportDocument49 pagesFinance Risk Analytics - Priyanka Sharma - Business ReportPriyanka SharmaNo ratings yet
- Metodologie IMD XDocument9 pagesMetodologie IMD XAnonymous qz5pEMh44No ratings yet
- Catch Me If You Can: Improving The Scope and Accuracy of Fraud PredictionDocument54 pagesCatch Me If You Can: Improving The Scope and Accuracy of Fraud PredictionDian IslamiyatiNo ratings yet
- G20 Set MethodologyDocument22 pagesG20 Set MethodologymsriramcaNo ratings yet
- Hdr2014 Faq Hdi enDocument7 pagesHdr2014 Faq Hdi ennguyen khanh trinhNo ratings yet
- KPI Template HSEDocument3 pagesKPI Template HSEpyuditya75% (8)
- Fraud Analytics 2022Document11 pagesFraud Analytics 2022farai charekaNo ratings yet
- Big Data for Beginners: Book 2 - An Introduction to the Data Analysis, Visualization, Integration, Interoperability, Governance and EthicsFrom EverandBig Data for Beginners: Book 2 - An Introduction to the Data Analysis, Visualization, Integration, Interoperability, Governance and EthicsNo ratings yet
- Statistical Analysis and Decision Making Using Microsoft ExcelFrom EverandStatistical Analysis and Decision Making Using Microsoft ExcelRating: 5 out of 5 stars5/5 (1)
- Overview Of Bayesian Approach To Statistical Methods: SoftwareFrom EverandOverview Of Bayesian Approach To Statistical Methods: SoftwareNo ratings yet
- Introduction To Business Statistics Through R Software: SoftwareFrom EverandIntroduction To Business Statistics Through R Software: SoftwareNo ratings yet
- Historical BackgroundDocument10 pagesHistorical Backgroundcdla14No ratings yet
- How To Get Your Ex Lover BackDocument43 pagesHow To Get Your Ex Lover BackZsuzsanna VáriNo ratings yet
- Waiting For - SupermanDocument6 pagesWaiting For - Supermancdla14No ratings yet
- (GUIDE) Link2SD For Dummies - Samsung Galaxy Young - Xda-DevelopersDocument10 pages(GUIDE) Link2SD For Dummies - Samsung Galaxy Young - Xda-Developerscdla14No ratings yet
- Nti Backup User's ManualDocument47 pagesNti Backup User's Manualcdla14No ratings yet
- MT6573 Android ScatterDocument1 pageMT6573 Android Scattercdla14No ratings yet
- Two (2) Years (U.S. and Latin America) Standard Limited Warranty ("Limited Warranty") For Toshiba Branded Accessories and ElectronicsDocument6 pagesTwo (2) Years (U.S. and Latin America) Standard Limited Warranty ("Limited Warranty") For Toshiba Branded Accessories and Electronicscdla14No ratings yet
- Kim Mirasol Resume Updated 15octDocument1 pageKim Mirasol Resume Updated 15octKim Alexis MirasolNo ratings yet
- Terrain Underground Broch July 201376Document32 pagesTerrain Underground Broch July 201376wmcNo ratings yet
- Manual On Quality Assurance For KhadiDocument189 pagesManual On Quality Assurance For KhadiManas DasNo ratings yet
- AB0001Document11 pagesAB0001SMNo ratings yet
- Python Installation InstructionsDocument4 pagesPython Installation InstructionswasslifeNo ratings yet
- TrainDocument3 pagesTrainanshul sharmaNo ratings yet
- Cooling Water Systems FundamentalsDocument13 pagesCooling Water Systems FundamentalsAlfonso José García Laguna100% (3)
- 2022 Fenix Product CatalogDocument62 pages2022 Fenix Product CatalogsachinumaryeNo ratings yet
- Reference TG - Cable ScheduleDocument21 pagesReference TG - Cable Scheduleerkamlakar2234No ratings yet
- Week8-Done Justifications PDFDocument2 pagesWeek8-Done Justifications PDFlvrevathiNo ratings yet
- Better Decision Making With Proper Business Intelligence PDFDocument7 pagesBetter Decision Making With Proper Business Intelligence PDFMuhammad KhoiruddinNo ratings yet
- SAP Ariba Spend AnalyticsDocument4 pagesSAP Ariba Spend Analyticshamza0% (1)
- Descriptive StatisticsDocument3 pagesDescriptive StatisticsCarla CarlaNo ratings yet
- Polytechnic University of The Philippines Sta. Mesa, ManilaDocument8 pagesPolytechnic University of The Philippines Sta. Mesa, ManilaAce RubiaNo ratings yet
- Ichiro Product CatalogueDocument24 pagesIchiro Product CatalogueduwiNo ratings yet
- JHD162A LCD CodeDocument3 pagesJHD162A LCD CodeAnkit Daftery100% (3)
- Earthquake Engineering - Course OutlineDocument19 pagesEarthquake Engineering - Course OutlineChristopher Paladio100% (1)
- Science Technology and Society: International School of Technology, Arts and Culinary of Davao City INCDocument83 pagesScience Technology and Society: International School of Technology, Arts and Culinary of Davao City INCLore StefanNo ratings yet
- Group 2 Major Component: 1. Main PumpDocument11 pagesGroup 2 Major Component: 1. Main PumpHậu MinhNo ratings yet
- 11th Assessment Scheme Model PaperDocument19 pages11th Assessment Scheme Model PaperMushtaqAnsariNo ratings yet
- Concrete KerbsDocument9 pagesConcrete Kerbsnswain76No ratings yet
- Basic Mechanical Engg. Assigenment No. 2Document1 pageBasic Mechanical Engg. Assigenment No. 2niyatisonimgNo ratings yet
- Army Chemical Review #1 (2002)Document52 pagesArmy Chemical Review #1 (2002)Reid Kirby100% (1)
- 09flying Models September 1981Document84 pages09flying Models September 1981Walter Gutierrez100% (1)
- 8 Esl Topics Quiz ComputersDocument2 pages8 Esl Topics Quiz ComputersAnamaria Stuparu PădurețuNo ratings yet
- HV65T 100T Preamp - REVEDocument1 pageHV65T 100T Preamp - REVESzabo Mihai-PaulNo ratings yet
- Vivace KB34S 1 WE G3Document3 pagesVivace KB34S 1 WE G3Fu'ad PurnomoNo ratings yet