Download as doc, pdf, or txt
You might also like
- Multiple Choice: Circle One Answer For Each Question. Transfer All You Answer To The Attached Answer Sheet and Email Back To Me On April 16Document3 pagesMultiple Choice: Circle One Answer For Each Question. Transfer All You Answer To The Attached Answer Sheet and Email Back To Me On April 16Joshua RamirezNo ratings yet
- Unit 5Document16 pagesUnit 5Nimmati Satheesh KannanNo ratings yet
- Huffman Codes: Spanning TreeDocument6 pagesHuffman Codes: Spanning TreeBhartiya NagrikNo ratings yet
- Modu 4 (Aad)Document37 pagesModu 4 (Aad)PonnuNo ratings yet
- Name 1: - Drexel Username 1Document4 pagesName 1: - Drexel Username 1Bao DangNo ratings yet
- Module 5Document41 pagesModule 5cbgopinathNo ratings yet
- Daa Module 6Document17 pagesDaa Module 6dunduNo ratings yet
- Advanced Algorithms Course. Lecture Notes. Part 4: Using Linear Programming For Approximation AlgorithmsDocument5 pagesAdvanced Algorithms Course. Lecture Notes. Part 4: Using Linear Programming For Approximation AlgorithmsKasapaNo ratings yet
- One Marks-4Document7 pagesOne Marks-4jashtiyamini72No ratings yet
- EditorialDocument5 pagesEditorialTahamid Hasan.No ratings yet
- Daa Unit Vi NotesDocument15 pagesDaa Unit Vi NotesPoorvaNo ratings yet
- Mcs 031 qns2 Image: Travelling Salesman Problem Previous PostDocument5 pagesMcs 031 qns2 Image: Travelling Salesman Problem Previous PostUmesh sharmaNo ratings yet
- Lab 1 ENDocument9 pagesLab 1 EN266619No ratings yet
- Daa Unit 3Document22 pagesDaa Unit 3Rahul GusainNo ratings yet
- Set Cover ProblemDocument5 pagesSet Cover ProblemJose guiteerrzNo ratings yet
- Problem Set 5Document4 pagesProblem Set 5Yash VarunNo ratings yet
- 18CS42 - Module 5Document52 pages18CS42 - Module 5dreamforya03No ratings yet
- Algorithms: CSE 202 - Final Examination: March 2015Document5 pagesAlgorithms: CSE 202 - Final Examination: March 2015ballechaseNo ratings yet
- Dynamic ProgrammingDocument12 pagesDynamic ProgrammingM.A rajaNo ratings yet
- Theorist's Toolkit Lecture 12: Semindefinite Programs and Tightening RelaxationsDocument4 pagesTheorist's Toolkit Lecture 12: Semindefinite Programs and Tightening RelaxationsJeremyKunNo ratings yet
- Chapter 7Document11 pagesChapter 7Dandu Kalyan VarmaNo ratings yet
- Improved Approximation Algorithms For The Vertex Cover Problem in Graphs and HypergraphsDocument16 pagesImproved Approximation Algorithms For The Vertex Cover Problem in Graphs and HypergraphsRitika JohriNo ratings yet
- Constraint Satisfaction ProblemDocument9 pagesConstraint Satisfaction ProblemswapsjagNo ratings yet
- 9.1 Cook-Levin TheoremDocument7 pages9.1 Cook-Levin TheoremMatthew JenkinsNo ratings yet
- Factorial Design SelectionDocument12 pagesFactorial Design SelectionAkhil KhajuriaNo ratings yet
- Constraint Satisfaction ProblemDocument10 pagesConstraint Satisfaction ProblemSwapniltrinityNo ratings yet
- Algo - Mod9 - Dynamic Programming MethodDocument51 pagesAlgo - Mod9 - Dynamic Programming MethodISSAM HAMADNo ratings yet
- Operation ResearchDocument10 pagesOperation Researchkawaljeet_singhNo ratings yet
- Reductions: Designing Algorithms Proving Limits Classifying Problems NP-completenessDocument50 pagesReductions: Designing Algorithms Proving Limits Classifying Problems NP-completenessuebecsNo ratings yet
- DAA Unit 5Document14 pagesDAA Unit 5hari karanNo ratings yet
- Randomized AlgorithmsDocument12 pagesRandomized AlgorithmsRaji PillaiNo ratings yet
- Cs - 502 F-T Subjective by Vu - ToperDocument18 pagesCs - 502 F-T Subjective by Vu - Topermirza adeelNo ratings yet
- Assignment - 1 AIM: Implement A Approach For Any Suitable Application. ObjectiveDocument17 pagesAssignment - 1 AIM: Implement A Approach For Any Suitable Application. ObjectiveTECOA136TejasJadhavNo ratings yet
- The Design and Analysis of Approximation Algorithms: Facility Location As A Case StudyDocument13 pagesThe Design and Analysis of Approximation Algorithms: Facility Location As A Case StudyVaibhav AcharyaNo ratings yet
- Chen1996A Class of Smoothing Functions For Nonlinear and MixedDocument42 pagesChen1996A Class of Smoothing Functions For Nonlinear and MixedKhaled BeheryNo ratings yet
- Algo Prev Year Solution 2019 and 2018Document23 pagesAlgo Prev Year Solution 2019 and 2018Md. Abdur RoufNo ratings yet
- Greedy Method MaterialDocument16 pagesGreedy Method MaterialAmaranatha Reddy PNo ratings yet
- Unit - VDocument22 pagesUnit - VJit Agg100% (1)
- Variable Neighborhood Search For The Probabilistic Satisfiability ProblemDocument6 pagesVariable Neighborhood Search For The Probabilistic Satisfiability Problemsk8888888No ratings yet
- Linear Programing NotesDocument7 pagesLinear Programing NotesPrerana SachanNo ratings yet
- COMP3010 Lab4 TheoryDocument3 pagesCOMP3010 Lab4 TheoryDũng MinhNo ratings yet
- Rod Cutting EducativeDocument6 pagesRod Cutting EducativeGonzaloAlbertoGaticaOsorioNo ratings yet
- 1 Hw6 SolutionsDocument8 pages1 Hw6 SolutionsdavejaiNo ratings yet
- 16 Linear Programming (November 29, December 1) : Confusingly, Some Authors Call This Standard FormDocument8 pages16 Linear Programming (November 29, December 1) : Confusingly, Some Authors Call This Standard FormYe MyatNo ratings yet
- The K-Centrum Multi-Facility Location Problem: Arie TamirDocument15 pagesThe K-Centrum Multi-Facility Location Problem: Arie TamirJoyNo ratings yet
- APProximation ProblemDocument25 pagesAPProximation ProblemShreyas SatardekarNo ratings yet
- Unit 3 - Analysis and Design of Algorithm - WWW - Rgpvnotes.inDocument11 pagesUnit 3 - Analysis and Design of Algorithm - WWW - Rgpvnotes.indixitraghav25No ratings yet
- Corner Point SolutionDocument2 pagesCorner Point SolutionRahulRajRanaNo ratings yet
- Solutions/Hints For The Problems: 1. Traffic Safe City (Points: 300)Document6 pagesSolutions/Hints For The Problems: 1. Traffic Safe City (Points: 300)arundobriyalNo ratings yet
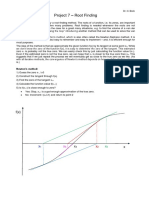
- Project 7 - Root Finding: Newton's MethodDocument4 pagesProject 7 - Root Finding: Newton's Methodhannan1993No ratings yet
- 05 Unit5Document10 pages05 Unit5John ArthurNo ratings yet
- Problem Set Sample: InstructionsDocument4 pagesProblem Set Sample: InstructionsballechaseNo ratings yet
- Semidef Prog 2Document9 pagesSemidef Prog 2Sérgio MonteiroNo ratings yet
- DAA MaterialDocument12 pagesDAA MaterialdagiNo ratings yet
- Daa2020 Tutorial 04Document2 pagesDaa2020 Tutorial 04KamalNo ratings yet
- DddssDocument5 pagesDddssPrakhar RajputNo ratings yet
- S. Wagon - Think GThink Globally Act Locallylobally Act LocallyDocument26 pagesS. Wagon - Think GThink Globally Act Locallylobally Act Locallyproteas26No ratings yet
- What Is Difference Between Backtracking and Branch and Bound MethodDocument4 pagesWhat Is Difference Between Backtracking and Branch and Bound MethodMahi On D Rockzz67% (3)
- Wolfe's AlgorithmDocument16 pagesWolfe's AlgorithmolivergergeljNo ratings yet
- A-level Maths Revision: Cheeky Revision ShortcutsFrom EverandA-level Maths Revision: Cheeky Revision ShortcutsRating: 3.5 out of 5 stars3.5/5 (8)
- A Novel Method of Compressing Speech With Higher BandwidtDocument12 pagesA Novel Method of Compressing Speech With Higher Bandwidtshaikshaa007100% (2)
- Linear ProgrammingDocument63 pagesLinear ProgrammingVance KangNo ratings yet
- Heuristic SearchDocument51 pagesHeuristic SearchJubair Ahmed BarbhuiyaNo ratings yet
- Performance Analysis of Various Fuzzy Clustering Algorithms: A ReviewDocument12 pagesPerformance Analysis of Various Fuzzy Clustering Algorithms: A ReviewTri Fara MeliniaNo ratings yet
- Portfolio Optimization Using Particle Swarm OptimizationDocument6 pagesPortfolio Optimization Using Particle Swarm OptimizationJMNo ratings yet
- Lab Report 3 - Digital To Analog ConvertersDocument7 pagesLab Report 3 - Digital To Analog ConvertersMelaku NegussieNo ratings yet
- Forward-Backward AlgorithmDocument8 pagesForward-Backward AlgorithmBill PetrieNo ratings yet
- Corrections For Frequency, Amplitude and Phase in A Fast Fourier Transform of A Harmonic SignalDocument11 pagesCorrections For Frequency, Amplitude and Phase in A Fast Fourier Transform of A Harmonic SignalIgnacio Daniel Tomasov SilvaNo ratings yet
- CS 202-Data Structures-Dr - Ihsan Ayyub QaziDocument2 pagesCS 202-Data Structures-Dr - Ihsan Ayyub QaziZia AzamNo ratings yet
- RecursionDocument9 pagesRecursionMada BaskoroNo ratings yet
- Sde Sheet (Core) :: Vjera4/EditDocument12 pagesSde Sheet (Core) :: Vjera4/Editsohil khattarNo ratings yet
- A General Framework of High-Performance Machine LeDocument26 pagesA General Framework of High-Performance Machine LeMahdi MahnazNo ratings yet
- Title of The Paper (Use Title Style) : Original Article Original Article Original ArticleDocument5 pagesTitle of The Paper (Use Title Style) : Original Article Original Article Original ArticleMuhammad Mushlih ElhafidNo ratings yet
- Solution of Difference Equations Using The ZDocument2 pagesSolution of Difference Equations Using The ZshivamucekNo ratings yet
- Soluciones A Ejercicios de ADADocument8 pagesSoluciones A Ejercicios de ADAvirybattenNo ratings yet
- R Mals ChainsDocument9 pagesR Mals ChainsNadim AizaraniNo ratings yet
- 04 RecursionDocument21 pages04 RecursionRazan AbabNo ratings yet
- 15-2 The Hamming Code: Check BitsDocument3 pages15-2 The Hamming Code: Check BitshaiqalNo ratings yet
- ClassvacDocument14 pagesClassvacنبيل يحييNo ratings yet
- PerceptronDocument26 pagesPerceptronSimmon ShajiNo ratings yet
- Open Methods Secant Method: AlgorithmDocument5 pagesOpen Methods Secant Method: Algorithmbeena saleemNo ratings yet
- CENTRAL DIFFERENCE INTERPOLATION FORMULA Exercises With SolutionDocument3 pagesCENTRAL DIFFERENCE INTERPOLATION FORMULA Exercises With Solutiongil tabionNo ratings yet
- HW2 SolnDocument8 pagesHW2 SolnJun KangNo ratings yet
- Homework 5 SolutionsDocument4 pagesHomework 5 SolutionsSuresh kumarNo ratings yet
- 01033055Document4 pages01033055D'Armi StefanoNo ratings yet
- Nonlinear Least Squares Problems: This Lecture Is Based On The Book P. C. Hansen, V. Pereyra and G. SchererDocument20 pagesNonlinear Least Squares Problems: This Lecture Is Based On The Book P. C. Hansen, V. Pereyra and G. SchererMeriska ApriliadaraNo ratings yet
- Part 1.2. Back PropagationDocument30 pagesPart 1.2. Back PropagationViệt HoàngNo ratings yet
- Homework For Module 4 Part 2 PDFDocument7 pagesHomework For Module 4 Part 2 PDFbita younesian100% (2)
- DWDM Unit-5Document52 pagesDWDM Unit-5Arun kumar SomaNo ratings yet