Download as pdf or txt
You might also like
- Risk Assessment For Cross-Contamination in Solid Dosage Form Manufacturing FacilitiesDocument5 pagesRisk Assessment For Cross-Contamination in Solid Dosage Form Manufacturing Facilitiesanandhra2010No ratings yet
- Simple LPRDocument9 pagesSimple LPRapi-26400509100% (1)
- A320 Aerodynamics StudyDocument7 pagesA320 Aerodynamics StudyGourav DasNo ratings yet
- S130 - Peças PDFDocument525 pagesS130 - Peças PDFtiago100% (1)
- Marker Detection For Augmented Reality Applications: Martin HirzerDocument27 pagesMarker Detection For Augmented Reality Applications: Martin HirzerSarra JmailNo ratings yet
- ARTag, A Fiducial Marker System Using Digital TechniquesDocument7 pagesARTag, A Fiducial Marker System Using Digital TechniquesGcmarshall82No ratings yet
- Barcode PaperDocument6 pagesBarcode PaperTrixe Mavell Perez ManzanoNo ratings yet
- R Eal T Ime L Icense P Late R Ecognition S YstemDocument5 pagesR Eal T Ime L Icense P Late R Ecognition S YstemIvánPortillaNo ratings yet
- EE368: Digital Image Processing Project Report: Ian Downes Downes@stanford - EduDocument6 pagesEE368: Digital Image Processing Project Report: Ian Downes Downes@stanford - EduMohit GuptaNo ratings yet
- Visual Product Identification For Blind: 1.3 FeaturesDocument20 pagesVisual Product Identification For Blind: 1.3 FeaturesNetisbbNo ratings yet
- Garrido Jurado 2014Document14 pagesGarrido Jurado 2014Bob SanchezNo ratings yet
- Android Based Visual Product Identification For The BlindDocument20 pagesAndroid Based Visual Product Identification For The BlindNetisbbNo ratings yet
- Efficient Decoding of Blurred, Pitched, & Scratched Barcode ImagesDocument6 pagesEfficient Decoding of Blurred, Pitched, & Scratched Barcode ImagesYasmin BarrettoNo ratings yet
- Automatic Indian Vehicle License Plate RecognitionDocument4 pagesAutomatic Indian Vehicle License Plate Recognitionmyk259No ratings yet
- 7 III March 2019Document7 pages7 III March 2019mohammedjafferdxmjNo ratings yet
- Traffic Sign Detection PaperDocument24 pagesTraffic Sign Detection PaperMax UgrekhelidzeNo ratings yet
- A Distributed Canny Edge Detector and Its Implementation On F PGADocument5 pagesA Distributed Canny Edge Detector and Its Implementation On F PGAInternational Journal of computational Engineering research (IJCER)No ratings yet
- EE368 Project: Visual Code Marker Detection Through Geometric Feature RecognitionDocument9 pagesEE368 Project: Visual Code Marker Detection Through Geometric Feature RecognitiondewddudeNo ratings yet
- Literature Survey On Image Segmentation and Shape Analysis For Road-Sign RecognitionDocument4 pagesLiterature Survey On Image Segmentation and Shape Analysis For Road-Sign RecognitionInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Iris V9Document26 pagesIris V9arakhalNo ratings yet
- AprilTag 2 Efficient and Robust Fiducial DetectionDocument6 pagesAprilTag 2 Efficient and Robust Fiducial Detectionعبد العزيز سمرةNo ratings yet
- Feature Extraction For Autonomous Ro Bot Navigation in Urban Environme NtsDocument8 pagesFeature Extraction For Autonomous Ro Bot Navigation in Urban Environme NtsDouglas IsraelNo ratings yet
- Comparison of Edge Detectors: Ayaz Akram, Asad IsmailDocument9 pagesComparison of Edge Detectors: Ayaz Akram, Asad IsmailRamSharmaNo ratings yet
- SimpleLPR PDFDocument9 pagesSimpleLPR PDFBarack ObamaNo ratings yet
- Colorimetric CalibrationDocument16 pagesColorimetric CalibrationRoberto RicciNo ratings yet
- An Edge Detection Algorithm Using A Local Distribution: University of Science Technology Avatollahi@,iust - Ac.irDocument4 pagesAn Edge Detection Algorithm Using A Local Distribution: University of Science Technology Avatollahi@,iust - Ac.irravindrapadsalaNo ratings yet
- Automatic Digitization of Large Scale MapsDocument10 pagesAutomatic Digitization of Large Scale MapsAchmad SyafiiNo ratings yet
- MlaaDocument8 pagesMlaacacolukiaNo ratings yet
- 3d Mapping Iser 10 FinalDocument15 pages3d Mapping Iser 10 FinalHieu TranNo ratings yet
- Gudla V Alleru College of Engineering GudlavalleruDocument6 pagesGudla V Alleru College of Engineering GudlavalleruPrasanth KumarNo ratings yet
- Digital Image Processing Project Report PDFDocument6 pagesDigital Image Processing Project Report PDFElsadig OsmanNo ratings yet
- New Approach To Similarity Detection by Combining Technique Three-Patch Local Binary Patterns (TP-LBP) With Support Vector MachineDocument10 pagesNew Approach To Similarity Detection by Combining Technique Three-Patch Local Binary Patterns (TP-LBP) With Support Vector MachineIAES IJAINo ratings yet
- Automatic Traffic Sign Recognition in Digital Images: by John HatzidimosDocument11 pagesAutomatic Traffic Sign Recognition in Digital Images: by John HatzidimosAlexandra AndricaNo ratings yet
- 2004 - Brandão, Menezes de Sequeira, Albuquerque - Multistage Morphology-Based License-Plate Location AlgorithmDocument4 pages2004 - Brandão, Menezes de Sequeira, Albuquerque - Multistage Morphology-Based License-Plate Location AlgorithmManuel Menezes de SequeiraNo ratings yet
- Fast Generation of Video Panorama: International Journal of Emerging Trends & Technology in Computer Science (IJETTCS)Document5 pagesFast Generation of Video Panorama: International Journal of Emerging Trends & Technology in Computer Science (IJETTCS)International Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Paper 1Document7 pagesPaper 1Nishanthan KNo ratings yet
- Apriltag: A Robust and Flexible Visual Fiducial System: Edwin OlsonDocument8 pagesApriltag: A Robust and Flexible Visual Fiducial System: Edwin Olsonsnesh93No ratings yet
- Real-Time Stereo Vision For Urban Traffic Scene UnderstandingDocument6 pagesReal-Time Stereo Vision For Urban Traffic Scene UnderstandingBasilNo ratings yet
- An Autonomous Mobile Robot With A 3D Laser Range Finder For 3D Exploration and Digitalization of Indoor EnvironmentsDocument18 pagesAn Autonomous Mobile Robot With A 3D Laser Range Finder For 3D Exploration and Digitalization of Indoor EnvironmentsCocias AdrianNo ratings yet
- G J E S R: A Review On License Plate Recognition Based Anti Signal Detection SystemDocument7 pagesG J E S R: A Review On License Plate Recognition Based Anti Signal Detection SystemMuhd AmirulNo ratings yet
- An Advanced Canny Edge Detector and Its Implementation On Xilinx FpgaDocument7 pagesAn Advanced Canny Edge Detector and Its Implementation On Xilinx FpgalambanaveenNo ratings yet
- A Novel Multiple License Plate Extraction Technique For Complex Background in Indian Traffic ConditionsDocument13 pagesA Novel Multiple License Plate Extraction Technique For Complex Background in Indian Traffic ConditionsVighneshwara UpadhyaNo ratings yet
- Anpr Survey IjcaDocument14 pagesAnpr Survey Ijcaprince mehtaNo ratings yet
- Vehicle License Plate Recognition Using Morphology and Neural NetworkDocument7 pagesVehicle License Plate Recognition Using Morphology and Neural NetworkJames MorenoNo ratings yet
- ARTag Rev1marker DetecionDocument4 pagesARTag Rev1marker Detecionpavankumar_sheriNo ratings yet
- Improved Color Edge Detection by Fusion of Hue, PCA & Hybrid CannyDocument8 pagesImproved Color Edge Detection by Fusion of Hue, PCA & Hybrid CannyVijayakumarNo ratings yet
- A New Approach For Stereo Matching Algorithm With Dynamic ProgrammingDocument6 pagesA New Approach For Stereo Matching Algorithm With Dynamic ProgrammingEditor IJRITCCNo ratings yet
- A Single LiDAR-Based Feature Fusion Indoor Localiz PDFDocument19 pagesA Single LiDAR-Based Feature Fusion Indoor Localiz PDFVICTOR PEREZNo ratings yet
- Sensors 18 01294 PDFDocument19 pagesSensors 18 01294 PDFVICTOR PEREZNo ratings yet
- PCB Exposure and Data Matrix Based Job Verification: Adam Marchewka, Ryszard Wocianiec, Jarosław ZdrojewskiDocument8 pagesPCB Exposure and Data Matrix Based Job Verification: Adam Marchewka, Ryszard Wocianiec, Jarosław ZdrojewskiShahrulJamalNo ratings yet
- IpDocument7 pagesIpVinit WadgaonkarNo ratings yet
- 1.Radar-Camera Sensor Fusion Based Object Detection For ... - ThinkMindDocument6 pages1.Radar-Camera Sensor Fusion Based Object Detection For ... - ThinkMindThanh LeNo ratings yet
- Real Time Image Processing Applied To Traffic Queue DDocument12 pagesReal Time Image Processing Applied To Traffic Queue Dshajin2233No ratings yet
- Traffic Sign Detection Using Convolutional Neural Network: TitleDocument15 pagesTraffic Sign Detection Using Convolutional Neural Network: TitlePranav TandonNo ratings yet
- Improved Method For License Plate Recognition For Indian Road ConditionsDocument5 pagesImproved Method For License Plate Recognition For Indian Road ConditionsInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Real Time Myanmar Traffic Sign Recognition System Using HOG and SVMDocument5 pagesReal Time Myanmar Traffic Sign Recognition System Using HOG and SVMEditor IJTSRDNo ratings yet
- Cvpr91-Debby-Paper Segmentation and Grouping of Object Boundaries Using Energy MinimizationDocument15 pagesCvpr91-Debby-Paper Segmentation and Grouping of Object Boundaries Using Energy MinimizationcabrahaoNo ratings yet
- Title - Traffic Sign Detection Using Convolutional Neural NetworkDocument15 pagesTitle - Traffic Sign Detection Using Convolutional Neural NetworkPranav TandonNo ratings yet
- Integrated System For Robot Control Based On Traffic Sign RecognitionDocument6 pagesIntegrated System For Robot Control Based On Traffic Sign RecognitionlambanaveenNo ratings yet
- RANSAC Vs ICP PDFDocument15 pagesRANSAC Vs ICP PDFSaransh Vora100% (1)
- Comparative Analysis of Different Segmentation Techniques For Automatic Number Plate RecognitionDocument4 pagesComparative Analysis of Different Segmentation Techniques For Automatic Number Plate RecognitionerpublicationNo ratings yet
- ANPR PowerPointDocument38 pagesANPR PowerPointashishNo ratings yet
- Raster Graphics Editor: Transforming Visual Realities: Mastering Raster Graphics Editors in Computer VisionFrom EverandRaster Graphics Editor: Transforming Visual Realities: Mastering Raster Graphics Editors in Computer VisionNo ratings yet
- Demand FactorDocument37 pagesDemand FactoruddinnadeemNo ratings yet
- Map Info Pro Install GuideDocument77 pagesMap Info Pro Install Guidececil tivaniNo ratings yet
- RTR 1633.30-01-18Document4 pagesRTR 1633.30-01-18LHYT NTUANo ratings yet
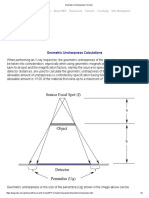
- Geometric Unsharpness FormulaDocument2 pagesGeometric Unsharpness FormulaJayaneela Prawin0% (1)
- Paola SassiDocument21 pagesPaola Sassisehgal91No ratings yet
- Magnet ExtensometerDocument12 pagesMagnet ExtensometerMandalay Pioneer Geoengineering Services (MPGS)No ratings yet
- Red Hat Enterprise Linux OpenStack Platform-7-Introduction To The OpenStack Dashboard-En-USDocument13 pagesRed Hat Enterprise Linux OpenStack Platform-7-Introduction To The OpenStack Dashboard-En-USWaldek ZiębińskiNo ratings yet
- NX OsDocument690 pagesNX OsCCNA classNo ratings yet
- PH8151-Engineering Physics Question Bank-I Semester: Part B Questions Unit I - Properties of Matter Set - 1Document3 pagesPH8151-Engineering Physics Question Bank-I Semester: Part B Questions Unit I - Properties of Matter Set - 1Mohammed RashiqNo ratings yet
- Carbotec TR-PTDocument41 pagesCarbotec TR-PTGuesh Gebrekidan100% (1)
- 12-Exhibit 8 - Subcontractors and Vendors - Offshore Integrated Works - Rev GleDocument6 pages12-Exhibit 8 - Subcontractors and Vendors - Offshore Integrated Works - Rev GleIdara OkopidoNo ratings yet
- Design of 50 MW SolarDocument14 pagesDesign of 50 MW Solarbhargav100% (1)
- ShowtradecertDocument1 pageShowtradecertKartik BejNo ratings yet
- Thermistor Respiratory MonitorDocument25 pagesThermistor Respiratory MonitorBianca ClementeNo ratings yet
- 1 - OverviewDocument17 pages1 - OverviewMuhammad Zain YousafNo ratings yet
- Disk Detainer Picking PDFDocument6 pagesDisk Detainer Picking PDFescher7No ratings yet
- ProposalDocument10 pagesProposalbhaskarNo ratings yet
- Ujian Semester 5 Bing Kelas XiiDocument9 pagesUjian Semester 5 Bing Kelas XiiJunNo ratings yet
- Universal Engines Fast Moving Parts ListsDocument21 pagesUniversal Engines Fast Moving Parts Liststarek ali ahmedNo ratings yet
- Computer SC Specimen QP Class XiDocument7 pagesComputer SC Specimen QP Class XiAshutosh Raj0% (1)
- Unit-5 Maintenance of Hydraulic SystemDocument46 pagesUnit-5 Maintenance of Hydraulic SystemprabhathNo ratings yet
- Bs en 12Document10 pagesBs en 12Alvin BadzNo ratings yet
- Welmec 2Document71 pagesWelmec 2jaruna bNo ratings yet
- CONCRETE IN BIAXIAL CYCLIC COMPRESSION - BuyukozturkDocument16 pagesCONCRETE IN BIAXIAL CYCLIC COMPRESSION - Buyukozturkdmep25No ratings yet
- Check Swing Cast Steel A216 WCB Class 150: Pressure Temperature RatingsDocument2 pagesCheck Swing Cast Steel A216 WCB Class 150: Pressure Temperature Ratingsbreyca4 bcrNo ratings yet
- BS 4206 PDFDocument11 pagesBS 4206 PDFbich100% (1)
- (09-2) - L-ZL (26) 26RG01B.001 PDFDocument1 page(09-2) - L-ZL (26) 26RG01B.001 PDFRaznan RamliNo ratings yet