
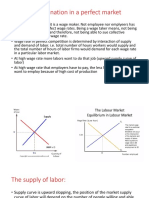
MIT14 03F10 Lec01 02
MIT14 03F10 Lec01 02
You might also like
- Module 1Document62 pagesModule 1Linly KeomahavongNo ratings yet
- Marginal Productivity TheoryDocument5 pagesMarginal Productivity TheoryPranjal BariNo ratings yet
- Chapter 18: The Markets For The Factors of Production Lecture Notes Learning ObjectivesDocument9 pagesChapter 18: The Markets For The Factors of Production Lecture Notes Learning ObjectivesGuru DeepNo ratings yet
- Unit No. VI Factor PricingDocument11 pagesUnit No. VI Factor PricingMuhammad Yasir IqbalNo ratings yet
- Learning Objective: Concept of Wages and Marginal Productivity Theory of LabourDocument3 pagesLearning Objective: Concept of Wages and Marginal Productivity Theory of LabourRohitPatialNo ratings yet
- Economia Tema 5Document8 pagesEconomia Tema 5Javier RubiolsNo ratings yet
- Chapter 6Document8 pagesChapter 6Kotryna RudelytėNo ratings yet
- The Labor Market: DemandDocument11 pagesThe Labor Market: DemandAnonymous GQXLOjndTbNo ratings yet
- Macroeconomics 1 - Chapter FiveDocument38 pagesMacroeconomics 1 - Chapter FiveBiruk YidnekachewNo ratings yet
- ch03 Sum PDFDocument14 pagesch03 Sum PDFOona NiallNo ratings yet
- Assignment: University of GujratDocument7 pagesAssignment: University of GujratJehangir AkramNo ratings yet
- Frictions in The Labour MarketDocument26 pagesFrictions in The Labour MarketNana Pauline Mukwangu100% (1)
- 3.3 Use of Marginal Revenue and Marginal Cost in Determining Work ForceDocument7 pages3.3 Use of Marginal Revenue and Marginal Cost in Determining Work ForceFoisal Mahmud RownakNo ratings yet
- Macro Lecture Notes - EPICDocument51 pagesMacro Lecture Notes - EPICJonny Schuman100% (1)
- Marginal Productivity Theory of WagesDocument3 pagesMarginal Productivity Theory of WagesSuhas KandeNo ratings yet
- Marginal Productivity Theory of Distribution: Definitions, Assumptions, Explanation!Document9 pagesMarginal Productivity Theory of Distribution: Definitions, Assumptions, Explanation!khalidaNo ratings yet
- Wage Determination in A Perfect MarketDocument21 pagesWage Determination in A Perfect MarketjamalNo ratings yet
- Theory of DistributionDocument37 pagesTheory of DistributionGETinTOthE SySteMNo ratings yet
- PS1 2012 SolutionDocument14 pagesPS1 2012 Solutionandrewlyzer100% (2)
- Learning Objective: Introduction To Theory of Factor PricingDocument5 pagesLearning Objective: Introduction To Theory of Factor PricingRohitPatialNo ratings yet
- Macro LL Chapter 3Document37 pagesMacro LL Chapter 3muzeferuzNo ratings yet
- The Cyclical Behavior of Equilibrium Unemployment and Vacancies RevisitedDocument24 pagesThe Cyclical Behavior of Equilibrium Unemployment and Vacancies RevisitedmonoNo ratings yet
- Aggregate Supply and The Short-Run Tradeoff Between Inflation and UnemploymentDocument23 pagesAggregate Supply and The Short-Run Tradeoff Between Inflation and UnemploymentdanniNo ratings yet
- Minimum Wages For Ronald Mcdonald Monopsonies A Theory of Monopsonistic CompetitionDocument18 pagesMinimum Wages For Ronald Mcdonald Monopsonies A Theory of Monopsonistic CompetitionSmriti SaxenaNo ratings yet
- Mankiw Chapter 14Document12 pagesMankiw Chapter 14Mina SkyNo ratings yet
- Macro 3Document9 pagesMacro 3Rajesh GargNo ratings yet
- Top 4 Models of Aggregate Supply of WagesDocument9 pagesTop 4 Models of Aggregate Supply of WagesSINTAYEHU MARYE TESHOMENo ratings yet
- How Is National Income Distributed To The FactorsDocument26 pagesHow Is National Income Distributed To The FactorsSuruchi SinghNo ratings yet
- Lecture 6 - S21Document7 pagesLecture 6 - S21AsadNo ratings yet
- How Is National Income Distributed To The FactorsDocument26 pagesHow Is National Income Distributed To The FactorsSaurav kumar0% (2)
- Econ Mod 3Document5 pagesEcon Mod 3Akeila ChristopherNo ratings yet
- The Labour Market Demand and SupplyDocument29 pagesThe Labour Market Demand and SupplyNafis SiddiquiNo ratings yet
- Econ Elect BabeDocument5 pagesEcon Elect BabeJm ChuaNo ratings yet
- Value of Marginal ProductDocument5 pagesValue of Marginal ProductMohammad BathishNo ratings yet
- Unit 6 Review SheetDocument10 pagesUnit 6 Review Sheetsydneytomei04No ratings yet
- 3.1 The Macroeconomics of The Labor MarketDocument32 pages3.1 The Macroeconomics of The Labor MarketDutch EthioNo ratings yet
- Theory of DistributionDocument10 pagesTheory of DistributionprudenceNo ratings yet
- EKN 244 2022 CORE Unit 9 For ClickUPDocument40 pagesEKN 244 2022 CORE Unit 9 For ClickUPHappinessNo ratings yet
- Efficiency WagesDocument39 pagesEfficiency WagesunjustvexationNo ratings yet
- Tutorial 6 - EconomicsDocument6 pagesTutorial 6 - EconomicsAbril RodriguezNo ratings yet
- Question BDocument3 pagesQuestion BJe HoeNo ratings yet
- The Market For The Factors of ProductionDocument15 pagesThe Market For The Factors of ProductiondascXCNo ratings yet
- Theories of WagesDocument14 pagesTheories of WagesGracy RengarajNo ratings yet
- TaussigDocument9 pagesTaussigAjeev kumarNo ratings yet
- Basic Microeconomics For Studying MacroDocument6 pagesBasic Microeconomics For Studying MacroMahek AgarwalNo ratings yet
- E-Content PPU - B.A-1 (Eco. Hons) Paper-1 (Micro Economics) - Dr. Anil Nath.Document6 pagesE-Content PPU - B.A-1 (Eco. Hons) Paper-1 (Micro Economics) - Dr. Anil Nath.Manish sumanNo ratings yet
- Unit 9 - The Labour Market - 1.0Document41 pagesUnit 9 - The Labour Market - 1.0maria aghaNo ratings yet
- Unit 9 - The Labour Market - 1.0Document41 pagesUnit 9 - The Labour Market - 1.0maria aghaNo ratings yet
- Profits, Wages & UnemploymentDocument5 pagesProfits, Wages & UnemploymentJack SangNo ratings yet
- Principles of Economics II Homework 4: Dr. Hoang KhieuDocument4 pagesPrinciples of Economics II Homework 4: Dr. Hoang Khieuhonghagiang.forworkNo ratings yet
- 7-Thomas R. Michl - Macroeconomic Theory - A Short Course-M. E. Sharpe Incorporated (2002) - 33-104Document72 pages7-Thomas R. Michl - Macroeconomic Theory - A Short Course-M. E. Sharpe Incorporated (2002) - 33-104falconmariana652No ratings yet
- About Us For The Public Community Development Our Region: ResearchDocument14 pagesAbout Us For The Public Community Development Our Region: ResearchSwati ChaudhariNo ratings yet
- LabourDemand Fall2018Document58 pagesLabourDemand Fall2018rtchuidjangnanaNo ratings yet
- Lecture 11 - Perfect Labour MarketsDocument4 pagesLecture 11 - Perfect Labour MarketsElianne AdeniyiNo ratings yet
- Econ Notes 6Document24 pagesEcon Notes 6Engineers UniqueNo ratings yet
- Chapter 7. Compensation Strategy: External CompetitivenessDocument12 pagesChapter 7. Compensation Strategy: External CompetitivenessAlthon Jay0% (1)
- PyschologyDocument12 pagesPyschologyarfamalik581No ratings yet
- Labor Market and UnemploymentDocument4 pagesLabor Market and Unemploymentjme_pescasioNo ratings yet
- Wages: Compiled by Madhav VermaDocument21 pagesWages: Compiled by Madhav VermamadhavvermaNo ratings yet
- REVIEW QUESTIONS Classical Economics and DepressionDocument5 pagesREVIEW QUESTIONS Classical Economics and Depressionkoorossadighi1No ratings yet
- Lecture Note 8: Applying Consumer Theory To Competitive Markets - The United States Sugar ProgramDocument12 pagesLecture Note 8: Applying Consumer Theory To Competitive Markets - The United States Sugar ProgramThev SightsNo ratings yet
- Lecture Note 1 - Education, Human Capital, and Labor Market SignalingDocument18 pagesLecture Note 1 - Education, Human Capital, and Labor Market SignalingThev SightsNo ratings yet
- Api-304 2Document11 pagesApi-304 2Thev SightsNo ratings yet
- Samsung SCX-3200 SeriesDocument1 pageSamsung SCX-3200 SeriesThev SightsNo ratings yet
- Smart de Frag ReporthDocument689 pagesSmart de Frag ReporthThev SightsNo ratings yet
- Compensation and Its Impact On Motivation Employee S Satisfaction and Employee S PerformanceDocument43 pagesCompensation and Its Impact On Motivation Employee S Satisfaction and Employee S Performanceadhitya JulyanNo ratings yet
- Experiences of Workplace Bullying in Physiotherapy Students On Clinical InternshipsDocument3 pagesExperiences of Workplace Bullying in Physiotherapy Students On Clinical InternshipsAnis MottahedehNo ratings yet
- Chapter 10 v2Document15 pagesChapter 10 v2Sheilamae Sernadilla Gregorio0% (1)
- Downsizing and RightsizingDocument5 pagesDownsizing and RightsizingAbdul Mujeeb KhanNo ratings yet
- Chapter 4: Human Resource Management: Edilvien Queences Khlem Montaña Jasleen Bhullar Varsha Anmoldeep Spoorthi HosamaniDocument19 pagesChapter 4: Human Resource Management: Edilvien Queences Khlem Montaña Jasleen Bhullar Varsha Anmoldeep Spoorthi Hosamanivikas dagarNo ratings yet
- Cavendish Employment LawCard 4ED LawcardsDocument118 pagesCavendish Employment LawCard 4ED LawcardsAmatee Persad100% (1)
- Google S Project Oxygen Do Managers MattDocument6 pagesGoogle S Project Oxygen Do Managers Mattdolly sharmaNo ratings yet
- Tutorial 2 AnswersDocument3 pagesTutorial 2 AnswersKokonokaSayakaNo ratings yet
- Doe Handbook: Chemical ManagementDocument53 pagesDoe Handbook: Chemical ManagementpevdiasNo ratings yet
- Workplace Health and Safety Assessment FormDocument9 pagesWorkplace Health and Safety Assessment Forms9n9No ratings yet
- Manual DFD For Cashiering System Figure 1.1: 1.1 Inquiries of Services and Customer Info 1.3Document1 pageManual DFD For Cashiering System Figure 1.1: 1.1 Inquiries of Services and Customer Info 1.3api-19728830No ratings yet
- RL WolfeDocument2 pagesRL WolfechanduNo ratings yet
- Paper 4.2 Guidance and CounsellingDocument17 pagesPaper 4.2 Guidance and Counsellingkimisakura100% (1)
- Background Investigation Authorization 2017 - CompleteDocument2 pagesBackground Investigation Authorization 2017 - CompleteAdriano GuedesNo ratings yet
- NSRP Form 1 Jobseeker Reg FormDocument2 pagesNSRP Form 1 Jobseeker Reg FormPeter Garga PanalanginNo ratings yet
- Kapro CatalogDocument72 pagesKapro CatalogIsmael 8877No ratings yet
- LEEA-039a Accreditation Scheme Appendix 1Document25 pagesLEEA-039a Accreditation Scheme Appendix 1Deepu Ravikumar50% (2)
- Greenland Overseas Brochure PDFDocument36 pagesGreenland Overseas Brochure PDFNoman HossainNo ratings yet
- The Impact of Workplace Bullying On Work: PerformanceDocument11 pagesThe Impact of Workplace Bullying On Work: PerformanceNasrun Abd ManafNo ratings yet
- 中文成語英文對照Document34 pages中文成語英文對照alexandralynnNo ratings yet
- Manigandan 407267 OLDocument3 pagesManigandan 407267 OLSHAHULNo ratings yet
- Relevant Costing ConceptsDocument7 pagesRelevant Costing ConceptsAngel Lilly100% (1)
- HRM ProjectDocument29 pagesHRM ProjectJainam shahNo ratings yet
- GIP-Badging Request Form STM 2023 - Bambang - Irfan Odot - FachruraridDocument1 pageGIP-Badging Request Form STM 2023 - Bambang - Irfan Odot - FachruraridYuan DikaNo ratings yet
- G.R. No. 233413, June 17, 2019 Celiar. Atienza, Petitioner, V. Noel Sacramento Saluta, Respondent. Decision REYES, J. JR., J.: The Facts and The CaseDocument8 pagesG.R. No. 233413, June 17, 2019 Celiar. Atienza, Petitioner, V. Noel Sacramento Saluta, Respondent. Decision REYES, J. JR., J.: The Facts and The CaseVina LangidenNo ratings yet
- Employment Verification Form AppDocument1 pageEmployment Verification Form AppCoordinador DicNo ratings yet
- Introduction To Organizational BehaviorDocument24 pagesIntroduction To Organizational BehaviorPrincess Melanie MelendezNo ratings yet
- Bec Communication Activities PDFDocument27 pagesBec Communication Activities PDFgilmoltoNo ratings yet
- History of Pakistan Textile IndustryDocument3 pagesHistory of Pakistan Textile IndustryZee QasimNo ratings yet





























































































Download as pdf or txt
You might also like
- Module 1Document62 pagesModule 1Linly KeomahavongNo ratings yet
- Marginal Productivity TheoryDocument5 pagesMarginal Productivity TheoryPranjal BariNo ratings yet
- Chapter 18: The Markets For The Factors of Production Lecture Notes Learning ObjectivesDocument9 pagesChapter 18: The Markets For The Factors of Production Lecture Notes Learning ObjectivesGuru DeepNo ratings yet
- Unit No. VI Factor PricingDocument11 pagesUnit No. VI Factor PricingMuhammad Yasir IqbalNo ratings yet
- Learning Objective: Concept of Wages and Marginal Productivity Theory of LabourDocument3 pagesLearning Objective: Concept of Wages and Marginal Productivity Theory of LabourRohitPatialNo ratings yet
- Economia Tema 5Document8 pagesEconomia Tema 5Javier RubiolsNo ratings yet
- Chapter 6Document8 pagesChapter 6Kotryna RudelytėNo ratings yet
- The Labor Market: DemandDocument11 pagesThe Labor Market: DemandAnonymous GQXLOjndTbNo ratings yet
- Macroeconomics 1 - Chapter FiveDocument38 pagesMacroeconomics 1 - Chapter FiveBiruk YidnekachewNo ratings yet
- ch03 Sum PDFDocument14 pagesch03 Sum PDFOona NiallNo ratings yet
- Assignment: University of GujratDocument7 pagesAssignment: University of GujratJehangir AkramNo ratings yet
- Frictions in The Labour MarketDocument26 pagesFrictions in The Labour MarketNana Pauline Mukwangu100% (1)
- 3.3 Use of Marginal Revenue and Marginal Cost in Determining Work ForceDocument7 pages3.3 Use of Marginal Revenue and Marginal Cost in Determining Work ForceFoisal Mahmud RownakNo ratings yet
- Macro Lecture Notes - EPICDocument51 pagesMacro Lecture Notes - EPICJonny Schuman100% (1)
- Marginal Productivity Theory of WagesDocument3 pagesMarginal Productivity Theory of WagesSuhas KandeNo ratings yet
- Marginal Productivity Theory of Distribution: Definitions, Assumptions, Explanation!Document9 pagesMarginal Productivity Theory of Distribution: Definitions, Assumptions, Explanation!khalidaNo ratings yet
- Wage Determination in A Perfect MarketDocument21 pagesWage Determination in A Perfect MarketjamalNo ratings yet
- Theory of DistributionDocument37 pagesTheory of DistributionGETinTOthE SySteMNo ratings yet
- PS1 2012 SolutionDocument14 pagesPS1 2012 Solutionandrewlyzer100% (2)
- Learning Objective: Introduction To Theory of Factor PricingDocument5 pagesLearning Objective: Introduction To Theory of Factor PricingRohitPatialNo ratings yet
- Macro LL Chapter 3Document37 pagesMacro LL Chapter 3muzeferuzNo ratings yet
- The Cyclical Behavior of Equilibrium Unemployment and Vacancies RevisitedDocument24 pagesThe Cyclical Behavior of Equilibrium Unemployment and Vacancies RevisitedmonoNo ratings yet
- Aggregate Supply and The Short-Run Tradeoff Between Inflation and UnemploymentDocument23 pagesAggregate Supply and The Short-Run Tradeoff Between Inflation and UnemploymentdanniNo ratings yet
- Minimum Wages For Ronald Mcdonald Monopsonies A Theory of Monopsonistic CompetitionDocument18 pagesMinimum Wages For Ronald Mcdonald Monopsonies A Theory of Monopsonistic CompetitionSmriti SaxenaNo ratings yet
- Mankiw Chapter 14Document12 pagesMankiw Chapter 14Mina SkyNo ratings yet
- Macro 3Document9 pagesMacro 3Rajesh GargNo ratings yet
- Top 4 Models of Aggregate Supply of WagesDocument9 pagesTop 4 Models of Aggregate Supply of WagesSINTAYEHU MARYE TESHOMENo ratings yet
- How Is National Income Distributed To The FactorsDocument26 pagesHow Is National Income Distributed To The FactorsSuruchi SinghNo ratings yet
- Lecture 6 - S21Document7 pagesLecture 6 - S21AsadNo ratings yet
- How Is National Income Distributed To The FactorsDocument26 pagesHow Is National Income Distributed To The FactorsSaurav kumar0% (2)
- Econ Mod 3Document5 pagesEcon Mod 3Akeila ChristopherNo ratings yet
- The Labour Market Demand and SupplyDocument29 pagesThe Labour Market Demand and SupplyNafis SiddiquiNo ratings yet
- Econ Elect BabeDocument5 pagesEcon Elect BabeJm ChuaNo ratings yet
- Value of Marginal ProductDocument5 pagesValue of Marginal ProductMohammad BathishNo ratings yet
- Unit 6 Review SheetDocument10 pagesUnit 6 Review Sheetsydneytomei04No ratings yet
- 3.1 The Macroeconomics of The Labor MarketDocument32 pages3.1 The Macroeconomics of The Labor MarketDutch EthioNo ratings yet
- Theory of DistributionDocument10 pagesTheory of DistributionprudenceNo ratings yet
- EKN 244 2022 CORE Unit 9 For ClickUPDocument40 pagesEKN 244 2022 CORE Unit 9 For ClickUPHappinessNo ratings yet
- Efficiency WagesDocument39 pagesEfficiency WagesunjustvexationNo ratings yet
- Tutorial 6 - EconomicsDocument6 pagesTutorial 6 - EconomicsAbril RodriguezNo ratings yet
- Question BDocument3 pagesQuestion BJe HoeNo ratings yet
- The Market For The Factors of ProductionDocument15 pagesThe Market For The Factors of ProductiondascXCNo ratings yet
- Theories of WagesDocument14 pagesTheories of WagesGracy RengarajNo ratings yet
- TaussigDocument9 pagesTaussigAjeev kumarNo ratings yet
- Basic Microeconomics For Studying MacroDocument6 pagesBasic Microeconomics For Studying MacroMahek AgarwalNo ratings yet
- E-Content PPU - B.A-1 (Eco. Hons) Paper-1 (Micro Economics) - Dr. Anil Nath.Document6 pagesE-Content PPU - B.A-1 (Eco. Hons) Paper-1 (Micro Economics) - Dr. Anil Nath.Manish sumanNo ratings yet
- Unit 9 - The Labour Market - 1.0Document41 pagesUnit 9 - The Labour Market - 1.0maria aghaNo ratings yet
- Unit 9 - The Labour Market - 1.0Document41 pagesUnit 9 - The Labour Market - 1.0maria aghaNo ratings yet
- Profits, Wages & UnemploymentDocument5 pagesProfits, Wages & UnemploymentJack SangNo ratings yet
- Principles of Economics II Homework 4: Dr. Hoang KhieuDocument4 pagesPrinciples of Economics II Homework 4: Dr. Hoang Khieuhonghagiang.forworkNo ratings yet
- 7-Thomas R. Michl - Macroeconomic Theory - A Short Course-M. E. Sharpe Incorporated (2002) - 33-104Document72 pages7-Thomas R. Michl - Macroeconomic Theory - A Short Course-M. E. Sharpe Incorporated (2002) - 33-104falconmariana652No ratings yet
- About Us For The Public Community Development Our Region: ResearchDocument14 pagesAbout Us For The Public Community Development Our Region: ResearchSwati ChaudhariNo ratings yet
- LabourDemand Fall2018Document58 pagesLabourDemand Fall2018rtchuidjangnanaNo ratings yet
- Lecture 11 - Perfect Labour MarketsDocument4 pagesLecture 11 - Perfect Labour MarketsElianne AdeniyiNo ratings yet
- Econ Notes 6Document24 pagesEcon Notes 6Engineers UniqueNo ratings yet
- Chapter 7. Compensation Strategy: External CompetitivenessDocument12 pagesChapter 7. Compensation Strategy: External CompetitivenessAlthon Jay0% (1)
- PyschologyDocument12 pagesPyschologyarfamalik581No ratings yet
- Labor Market and UnemploymentDocument4 pagesLabor Market and Unemploymentjme_pescasioNo ratings yet
- Wages: Compiled by Madhav VermaDocument21 pagesWages: Compiled by Madhav VermamadhavvermaNo ratings yet
- REVIEW QUESTIONS Classical Economics and DepressionDocument5 pagesREVIEW QUESTIONS Classical Economics and Depressionkoorossadighi1No ratings yet
- Lecture Note 8: Applying Consumer Theory To Competitive Markets - The United States Sugar ProgramDocument12 pagesLecture Note 8: Applying Consumer Theory To Competitive Markets - The United States Sugar ProgramThev SightsNo ratings yet
- Lecture Note 1 - Education, Human Capital, and Labor Market SignalingDocument18 pagesLecture Note 1 - Education, Human Capital, and Labor Market SignalingThev SightsNo ratings yet
- Api-304 2Document11 pagesApi-304 2Thev SightsNo ratings yet
- Samsung SCX-3200 SeriesDocument1 pageSamsung SCX-3200 SeriesThev SightsNo ratings yet
- Smart de Frag ReporthDocument689 pagesSmart de Frag ReporthThev SightsNo ratings yet
- Compensation and Its Impact On Motivation Employee S Satisfaction and Employee S PerformanceDocument43 pagesCompensation and Its Impact On Motivation Employee S Satisfaction and Employee S Performanceadhitya JulyanNo ratings yet
- Experiences of Workplace Bullying in Physiotherapy Students On Clinical InternshipsDocument3 pagesExperiences of Workplace Bullying in Physiotherapy Students On Clinical InternshipsAnis MottahedehNo ratings yet
- Chapter 10 v2Document15 pagesChapter 10 v2Sheilamae Sernadilla Gregorio0% (1)
- Downsizing and RightsizingDocument5 pagesDownsizing and RightsizingAbdul Mujeeb KhanNo ratings yet
- Chapter 4: Human Resource Management: Edilvien Queences Khlem Montaña Jasleen Bhullar Varsha Anmoldeep Spoorthi HosamaniDocument19 pagesChapter 4: Human Resource Management: Edilvien Queences Khlem Montaña Jasleen Bhullar Varsha Anmoldeep Spoorthi Hosamanivikas dagarNo ratings yet
- Cavendish Employment LawCard 4ED LawcardsDocument118 pagesCavendish Employment LawCard 4ED LawcardsAmatee Persad100% (1)
- Google S Project Oxygen Do Managers MattDocument6 pagesGoogle S Project Oxygen Do Managers Mattdolly sharmaNo ratings yet
- Tutorial 2 AnswersDocument3 pagesTutorial 2 AnswersKokonokaSayakaNo ratings yet
- Doe Handbook: Chemical ManagementDocument53 pagesDoe Handbook: Chemical ManagementpevdiasNo ratings yet
- Workplace Health and Safety Assessment FormDocument9 pagesWorkplace Health and Safety Assessment Forms9n9No ratings yet
- Manual DFD For Cashiering System Figure 1.1: 1.1 Inquiries of Services and Customer Info 1.3Document1 pageManual DFD For Cashiering System Figure 1.1: 1.1 Inquiries of Services and Customer Info 1.3api-19728830No ratings yet
- RL WolfeDocument2 pagesRL WolfechanduNo ratings yet
- Paper 4.2 Guidance and CounsellingDocument17 pagesPaper 4.2 Guidance and Counsellingkimisakura100% (1)
- Background Investigation Authorization 2017 - CompleteDocument2 pagesBackground Investigation Authorization 2017 - CompleteAdriano GuedesNo ratings yet
- NSRP Form 1 Jobseeker Reg FormDocument2 pagesNSRP Form 1 Jobseeker Reg FormPeter Garga PanalanginNo ratings yet
- Kapro CatalogDocument72 pagesKapro CatalogIsmael 8877No ratings yet
- LEEA-039a Accreditation Scheme Appendix 1Document25 pagesLEEA-039a Accreditation Scheme Appendix 1Deepu Ravikumar50% (2)
- Greenland Overseas Brochure PDFDocument36 pagesGreenland Overseas Brochure PDFNoman HossainNo ratings yet
- The Impact of Workplace Bullying On Work: PerformanceDocument11 pagesThe Impact of Workplace Bullying On Work: PerformanceNasrun Abd ManafNo ratings yet
- 中文成語英文對照Document34 pages中文成語英文對照alexandralynnNo ratings yet
- Manigandan 407267 OLDocument3 pagesManigandan 407267 OLSHAHULNo ratings yet
- Relevant Costing ConceptsDocument7 pagesRelevant Costing ConceptsAngel Lilly100% (1)
- HRM ProjectDocument29 pagesHRM ProjectJainam shahNo ratings yet
- GIP-Badging Request Form STM 2023 - Bambang - Irfan Odot - FachruraridDocument1 pageGIP-Badging Request Form STM 2023 - Bambang - Irfan Odot - FachruraridYuan DikaNo ratings yet
- G.R. No. 233413, June 17, 2019 Celiar. Atienza, Petitioner, V. Noel Sacramento Saluta, Respondent. Decision REYES, J. JR., J.: The Facts and The CaseDocument8 pagesG.R. No. 233413, June 17, 2019 Celiar. Atienza, Petitioner, V. Noel Sacramento Saluta, Respondent. Decision REYES, J. JR., J.: The Facts and The CaseVina LangidenNo ratings yet
- Employment Verification Form AppDocument1 pageEmployment Verification Form AppCoordinador DicNo ratings yet
- Introduction To Organizational BehaviorDocument24 pagesIntroduction To Organizational BehaviorPrincess Melanie MelendezNo ratings yet
- Bec Communication Activities PDFDocument27 pagesBec Communication Activities PDFgilmoltoNo ratings yet
- History of Pakistan Textile IndustryDocument3 pagesHistory of Pakistan Textile IndustryZee QasimNo ratings yet