Download as pdf or txt
You might also like
- Bolker Et Al 2009 General Mixed ModelDocument9 pagesBolker Et Al 2009 General Mixed ModelCarlos AndradeNo ratings yet
- The Multivariate Social ScientistDocument14 pagesThe Multivariate Social ScientistTeuku RazyNo ratings yet
- Part 11 Metal Detector Manual PDFDocument24 pagesPart 11 Metal Detector Manual PDFOrlando Melipillan100% (1)
- If Ye Know These Things Ross DrysdaleDocument334 pagesIf Ye Know These Things Ross DrysdaleBernardo Rasimo100% (1)
- Pricing Your Work Corporate and Industrial PhotographyDocument15 pagesPricing Your Work Corporate and Industrial PhotographyManu Mnau MnauNo ratings yet
- Assignment: Muhammad Kamran Khan Dr. Inam UllahDocument12 pagesAssignment: Muhammad Kamran Khan Dr. Inam UllahMuhammad kamran khanNo ratings yet
- Multiple Regression in CBDocument6 pagesMultiple Regression in CBgotcanNo ratings yet
- An Applicationon Multinomial Logistic Regression ModelDocument22 pagesAn Applicationon Multinomial Logistic Regression ModelMee MeeNo ratings yet
- Van Der Maas Et Al 2003 Sudden Transitions in AttitudesDocument28 pagesVan Der Maas Et Al 2003 Sudden Transitions in Attitudesaire.puraNo ratings yet
- FferDocument6 pagesFferlhzNo ratings yet
- SCH Luc HterDocument21 pagesSCH Luc HterlindaNo ratings yet
- Stepwise Model Fitting and Statistical Inference: Turning Noise Into Signal PollutionDocument5 pagesStepwise Model Fitting and Statistical Inference: Turning Noise Into Signal PollutionRifat EldowabNo ratings yet
- An Application On Multinomial Logistic Regression ModelDocument22 pagesAn Application On Multinomial Logistic Regression ModelRidwan Bin AlamNo ratings yet
- Assignment1 PDFDocument49 pagesAssignment1 PDFTahera ParvinNo ratings yet
- The Nature of Regression Analysis: Al Muizzuddin FDocument15 pagesThe Nature of Regression Analysis: Al Muizzuddin FM Arif WicaksonoNo ratings yet
- Multicollinearity Correctionsv3Document2 pagesMulticollinearity Correctionsv3John NkumeNo ratings yet
- Linear RegressionDocument10 pagesLinear RegressionRadhika ShardaNo ratings yet
- Econometrics 2Document27 pagesEconometrics 2Anunay ChoudharyNo ratings yet
- Kwi 017Document8 pagesKwi 017BALEWNo ratings yet
- On The Formulation and Analysis of General Deterministic Structured Population ModelsDocument40 pagesOn The Formulation and Analysis of General Deterministic Structured Population Modelsmompou88No ratings yet
- Multiple Regression Methodology and ApplicationsDocument7 pagesMultiple Regression Methodology and ApplicationsPriyanka V GalagaliNo ratings yet
- Generalized Linear Mixed Models: A Practical Guide For Ecology and EvolutionDocument49 pagesGeneralized Linear Mixed Models: A Practical Guide For Ecology and EvolutionvictorNo ratings yet
- Chapter - Two - Simple Linear Regression - Final EditedDocument28 pagesChapter - Two - Simple Linear Regression - Final Editedsuleymantesfaye10No ratings yet
- Connecting Dynamic Vegetation Models To Data - An Inverse PerspectiveDocument13 pagesConnecting Dynamic Vegetation Models To Data - An Inverse Perspective39gWeilaNo ratings yet
- Ged102 Week 8 WGNDocument5 pagesGed102 Week 8 WGNKyle SumicadNo ratings yet
- Ho - Lca - Latent Class AnalysisDocument8 pagesHo - Lca - Latent Class AnalysisYingChun PatNo ratings yet
- Tugas BiostatDocument24 pagesTugas BiostatOla MjnNo ratings yet
- Using Estimated Linear Mixed: Generalized Linear Models Trajectories From ModelDocument9 pagesUsing Estimated Linear Mixed: Generalized Linear Models Trajectories From Modelikin sodikinNo ratings yet
- Q.1 Explain The Underlying Ideas Behind The Log It Model. Explain On What Grounds Log It Model Is An Improvement Over Linear Probability Model. AnsDocument17 pagesQ.1 Explain The Underlying Ideas Behind The Log It Model. Explain On What Grounds Log It Model Is An Improvement Over Linear Probability Model. AnsBinyamin AlamNo ratings yet
- Linear Regression Chap01Document7 pagesLinear Regression Chap01israel14548100% (1)
- GED102 Week 8 WGN (1) (1) (1) (4) (AutoRecovered)Document5 pagesGED102 Week 8 WGN (1) (1) (1) (4) (AutoRecovered)Kyle SumicadNo ratings yet
- Spatial Ecology Mantel TestDocument6 pagesSpatial Ecology Mantel TestrkerstenNo ratings yet
- Jkan 43 154Document11 pagesJkan 43 154Dnyanesh AmbhoreNo ratings yet
- Name: Muhammad Siddique Class: B.Ed. Semester: Fifth Subject: Inferential Statistics Submitted To: Sir Sajid AliDocument6 pagesName: Muhammad Siddique Class: B.Ed. Semester: Fifth Subject: Inferential Statistics Submitted To: Sir Sajid Aliusama aliNo ratings yet
- Robust RegressionDocument7 pagesRobust Regressionharrison9No ratings yet
- General Linear ModelDocument7 pagesGeneral Linear ModelrahmahNo ratings yet
- Regression Analysis With Cross-Sectional DataDocument0 pagesRegression Analysis With Cross-Sectional DataGabriel SimNo ratings yet
- Using SAS To Extend Logistic RegressionDocument8 pagesUsing SAS To Extend Logistic RegressionarijitroyNo ratings yet
- Econometrics ch2Document19 pagesEconometrics ch2rifdah abadiyahNo ratings yet
- Visualizing Interaction Effects: A Proposal For Presentation and InterpretationDocument8 pagesVisualizing Interaction Effects: A Proposal For Presentation and Interpretationhubik38No ratings yet
- Structural Equation ModelingDocument14 pagesStructural Equation ModelingFerra YanuarNo ratings yet
- Ordered Response ModelsDocument15 pagesOrdered Response ModelsSuvamNo ratings yet
- Interpreting Interaction Effects in GeneralizedDocument22 pagesInterpreting Interaction Effects in GeneralizedblackalamzNo ratings yet
- Econometrics ch2Document19 pagesEconometrics ch2Muhammad Hassan KhanNo ratings yet
- By: Domodar N. Gujarati: Prof. M. El-SakkaDocument19 pagesBy: Domodar N. Gujarati: Prof. M. El-SakkaMuhammad Hassan KhanNo ratings yet
- Dissertation Cox RegressionDocument5 pagesDissertation Cox RegressionWhitePaperWritingServicesCanada100% (1)
- Final Term Paper BY Muhammad Umer (18201513-043) Course Title Regression Analysis II Course Code Stat-326 Submitted To Mam Erum Shahzadi Dgree Program/Section Bs Stats - 6Th Department of StatisticsDocument11 pagesFinal Term Paper BY Muhammad Umer (18201513-043) Course Title Regression Analysis II Course Code Stat-326 Submitted To Mam Erum Shahzadi Dgree Program/Section Bs Stats - 6Th Department of StatisticsProf Bilal HassanNo ratings yet
- Nature of Regression AnalysisDocument19 pagesNature of Regression AnalysisjspinkuNo ratings yet
- Data200 W5Document11 pagesData200 W5ashutosh karkiNo ratings yet
- Statistical Test of SignificanceDocument14 pagesStatistical Test of SignificanceRev. Kolawole, John ANo ratings yet
- RESEARCH METHODS LESSON 18 - Multiple RegressionDocument6 pagesRESEARCH METHODS LESSON 18 - Multiple RegressionAlthon JayNo ratings yet
- Bio2 Module 5 - Logistic RegressionDocument19 pagesBio2 Module 5 - Logistic Regressiontamirat hailuNo ratings yet
- Group Work - Econometrics UpdatedDocument22 pagesGroup Work - Econometrics UpdatedBantihun GetahunNo ratings yet
- Logistic Regression Models: Series: Basic Statistics For Busy Clinicians (Vii)Document11 pagesLogistic Regression Models: Series: Basic Statistics For Busy Clinicians (Vii)vato otavNo ratings yet
- MC BreakdownDocument5 pagesMC BreakdownThane SnymanNo ratings yet
- Methods Ecol Evol - 2016 - Muff - Marginal or Conditional Regression Models For Correlated Non Normal DataDocument11 pagesMethods Ecol Evol - 2016 - Muff - Marginal or Conditional Regression Models For Correlated Non Normal DataShakil AhmedNo ratings yet
- Partial Least Squares Regression A TutorialDocument17 pagesPartial Least Squares Regression A Tutorialazhang576100% (1)
- Math Honours: Machine Learning & Deep Learning (Still Under Developpement)Document11 pagesMath Honours: Machine Learning & Deep Learning (Still Under Developpement)Zelkif NjamenNo ratings yet
- Multicollinearity Assignment April 5Document10 pagesMulticollinearity Assignment April 5Zeinm KhenNo ratings yet
- Simple Regression Model: Erbil Technology InstituteDocument9 pagesSimple Regression Model: Erbil Technology Institutemhamadhawlery16No ratings yet
- A. Collinearity Diagnostics of Binary Logistic Regression ModelDocument16 pagesA. Collinearity Diagnostics of Binary Logistic Regression ModelJUAN DAVID SALAZAR ARIASNo ratings yet
- A Weak Convergence Approach to the Theory of Large DeviationsFrom EverandA Weak Convergence Approach to the Theory of Large DeviationsRating: 4 out of 5 stars4/5 (1)
- UntitledDocument2 pagesUntitledelleNo ratings yet
- Measurement of Thermal Conductivity: Engineering Properties of Biological Materials and Food Quality 3 (2+1)Document17 pagesMeasurement of Thermal Conductivity: Engineering Properties of Biological Materials and Food Quality 3 (2+1)Mel CapalunganNo ratings yet
- Case-Study & Lessons From Nokia DownfallDocument2 pagesCase-Study & Lessons From Nokia Downfallromesh911100% (1)
- ASTM D8210 - 19bDocument13 pagesASTM D8210 - 19bmancjaNo ratings yet
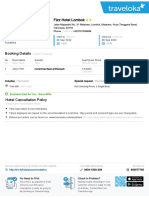
- Muhammad Fauzi-855677765-Fizz Hotel Lombok-HOTEL - STANDALONEDocument1 pageMuhammad Fauzi-855677765-Fizz Hotel Lombok-HOTEL - STANDALONEMuhammad Fauzi AndriansyahNo ratings yet
- Quiz For Western Lit.Document25 pagesQuiz For Western Lit.donnie4workingNo ratings yet
- Dsm-5 Icd-10 HandoutDocument107 pagesDsm-5 Icd-10 HandoutAakanksha Verma100% (1)
- Roadmgraybox Ds Oc AeDocument6 pagesRoadmgraybox Ds Oc Aemcclaink06No ratings yet
- EEET423L Final ProjectDocument7 pagesEEET423L Final ProjectAlan ReyesNo ratings yet
- Empower B2 Unit 10 QuizDocument2 pagesEmpower B2 Unit 10 QuizGuidance Teuku Nyak Arif Fatih Bilingual SchoolNo ratings yet
- 115 Ballard Tommelein 2021 LPS Benchmark 2020 2Document125 pages115 Ballard Tommelein 2021 LPS Benchmark 2020 2ATDNo ratings yet
- Bydf3 ElectricDocument61 pagesBydf3 ElectricIvan Avila100% (1)
- Azosprilum 2Document24 pagesAzosprilum 2Dipti PriyaNo ratings yet
- Ricardo Moreira Da Silva Baylina - Artistic Research ReportDocument65 pagesRicardo Moreira Da Silva Baylina - Artistic Research ReportEsteve CostaNo ratings yet
- Telegram DocumeDocument21 pagesTelegram Documemilli birhanuNo ratings yet
- CGF FPC Palm Oil RoadmapDocument31 pagesCGF FPC Palm Oil RoadmapnamasayanazlyaNo ratings yet
- Emmanuel Levinas - God, Death, and TimeDocument308 pagesEmmanuel Levinas - God, Death, and Timeissamagician100% (3)
- GEO01 - CO1.2 - Introduction To Earth Science (Geology)Document14 pagesGEO01 - CO1.2 - Introduction To Earth Science (Geology)Ghia PalarcaNo ratings yet
- March 16 - IM Processors DigiTimesDocument5 pagesMarch 16 - IM Processors DigiTimesRyanNo ratings yet
- Adamco BIFDocument2 pagesAdamco BIFMhie DazaNo ratings yet
- Maunakea Brochure C SEED and L Acoustics CreationsDocument6 pagesMaunakea Brochure C SEED and L Acoustics Creationsmlaouhi MajedNo ratings yet
- The Price of SilenceDocument9 pagesThe Price of Silencewamu885100% (1)
- Lec 1 Introduction Slides 1 20 MergedDocument153 pagesLec 1 Introduction Slides 1 20 MergedNeeraj VarmaNo ratings yet
- L550 19MY MB XC-EN V1j DX PDFDocument88 pagesL550 19MY MB XC-EN V1j DX PDFAnonymous gMgeQl1SndNo ratings yet
- sn74hct138 PDFDocument21 pagessn74hct138 PDFpabloNo ratings yet
- Ballistic - August September 2021Document168 pagesBallistic - August September 2021andrewrowe100% (2)
- A Study On Financial Performance of Selected Public and Private Sector Banks - A Comparative AnalysisDocument3 pagesA Study On Financial Performance of Selected Public and Private Sector Banks - A Comparative AnalysisVarun NagarNo ratings yet