Download as pdf or txt
You might also like
- Clinical Handbook of Yamamoto New Scalp AcupunctureDocument262 pagesClinical Handbook of Yamamoto New Scalp AcupunctureJoni100% (1)
- Thorns in The Heart - A Christian's Guide To Dealing With AddictionDocument194 pagesThorns in The Heart - A Christian's Guide To Dealing With Addictionjuan nadalNo ratings yet
- Science No. 6 - The Use of Electronics & Electricity - Chapter 6 - Www-Bibliotecapleyades-NetDocument18 pagesScience No. 6 - The Use of Electronics & Electricity - Chapter 6 - Www-Bibliotecapleyades-NetGovernment-Slave-4-UNo ratings yet
- Armaturi Profile PVCDocument53 pagesArmaturi Profile PVCstoian andreiNo ratings yet
- Sleep Medicine Reviews: Mark S. Blumberg, Alan M. PlumeauDocument9 pagesSleep Medicine Reviews: Mark S. Blumberg, Alan M. PlumeauBruno SteinNo ratings yet
- The Idea of The Brain Matthew CobbDocument2 pagesThe Idea of The Brain Matthew CobblaurakaiohNo ratings yet
- Neural Network ReportDocument27 pagesNeural Network ReportSiddharth PatelNo ratings yet
- Descubriendo El CerebroDocument3 pagesDescubriendo El CerebroledzelesteNo ratings yet
- Neural NetworksDocument104 pagesNeural NetworksSingam Giridhar Kumar ReddyNo ratings yet
- Artificial Neural Networks - Utec AiDocument13 pagesArtificial Neural Networks - Utec AiBregy Esteban Malpartida RamosNo ratings yet
- Brain Chip: Dept - of CSE/SSCE/2016Document25 pagesBrain Chip: Dept - of CSE/SSCE/2016vidyvidyasharadha44No ratings yet
- Vincent EstradaDocument8 pagesVincent Estradaapi-311716276No ratings yet
- Dept. of CSEDocument29 pagesDept. of CSEKarthik VanamNo ratings yet
- Brain ChipsDocument37 pagesBrain Chipsgeetanjali vermaNo ratings yet
- Technical SeminarDocument3 pagesTechnical Seminarvamshi krishnaNo ratings yet
- My DLunit 2 FRM TXTDocument18 pagesMy DLunit 2 FRM TXTVali BhashaNo ratings yet
- Entropy 24 00665Document25 pagesEntropy 24 00665walter stiersNo ratings yet
- Objectives: Objectives 1-1 History 1-2 Applications 1-5 Biological Inspiration 1-8 Further Reading 1-10Document12 pagesObjectives: Objectives 1-1 History 1-2 Applications 1-5 Biological Inspiration 1-8 Further Reading 1-10aa801990100% (1)
- Zador (2019) Innate LearningDocument7 pagesZador (2019) Innate LearningTom SlistsNo ratings yet
- Brain ChipsDocument29 pagesBrain Chipskannan_bal90826088% (24)
- Presented By: Nirmal.K.Thomas S7B, 26Document17 pagesPresented By: Nirmal.K.Thomas S7B, 26Nirmal ThomasNo ratings yet
- Brain Chip Technology: Ece Aec 1Document23 pagesBrain Chip Technology: Ece Aec 1Krishna VeniNo ratings yet
- Neural NetworksDocument36 pagesNeural NetworksSivaNo ratings yet
- Summary Ultrastructural Mapping of Neural Circuitry 4 10 14Document3 pagesSummary Ultrastructural Mapping of Neural Circuitry 4 10 14api-192489685No ratings yet
- Bluebrainppt 1Document16 pagesBluebrainppt 1komalNo ratings yet
- $abeel Butt Bsse02161053 Section - B Faculty of Computer Science, University of LahoreDocument21 pages$abeel Butt Bsse02161053 Section - B Faculty of Computer Science, University of LahoreSabeel ButtNo ratings yet
- Research Papers On Blue BrainDocument8 pagesResearch Papers On Blue Braincakvaw0q100% (1)
- Neural NetworkDocument89 pagesNeural NetworkSwati Saini50% (2)
- Alessandro E Villa Włodzisław Duch Péter Érdi Francesco Masulli Günther Palm Artificial Neural Networks and Machine Learning - ICANN 2012 - 22nd International ConferenceDocument611 pagesAlessandro E Villa Włodzisław Duch Péter Érdi Francesco Masulli Günther Palm Artificial Neural Networks and Machine Learning - ICANN 2012 - 22nd International ConferenceVladimir Claros RocabadoNo ratings yet
- BCI EssayDocument3 pagesBCI EssayShawnNo ratings yet
- An Artificial Neural Networ1Document1 pageAn Artificial Neural Networ1Manoj SreeramNo ratings yet
- BCI Versus NeuroprostheticsDocument5 pagesBCI Versus NeuroprostheticsdhenumehtaNo ratings yet
- 1 - Intro - Biological Neuron and ANNDocument26 pages1 - Intro - Biological Neuron and ANNHani Amany ElisadiNo ratings yet
- Robots: A. The Modern World Is Increasingly Populated by Quasi-IntelligentDocument10 pagesRobots: A. The Modern World Is Increasingly Populated by Quasi-Intelligentchipchip1910No ratings yet
- The Future of the Brain: Essays by the World's Leading NeuroscientistsFrom EverandThe Future of the Brain: Essays by the World's Leading NeuroscientistsRating: 5 out of 5 stars5/5 (1)
- 13 Nicoleneuronsgrowingonsiliconpresentation 141210190403 Conversion Gate02Document13 pages13 Nicoleneuronsgrowingonsiliconpresentation 141210190403 Conversion Gate02EC 06 Adithya Das ANo ratings yet
- Could A Neuroscientist Understand A MicroprocessorDocument15 pagesCould A Neuroscientist Understand A MicroprocessorHenrique JesusNo ratings yet
- Bionics: BY:-Pratik VyasDocument14 pagesBionics: BY:-Pratik VyasHardik KumarNo ratings yet
- Brain Chips: Presented by Akash Srivastava E.C.-3Document24 pagesBrain Chips: Presented by Akash Srivastava E.C.-3Akash SrivastavNo ratings yet
- Neural Networks NotescompiledlandscapeDocument71 pagesNeural Networks NotescompiledlandscapeIanNo ratings yet
- It'S Time To Change The Way We Study The BrainDocument6 pagesIt'S Time To Change The Way We Study The BrainAadya XIIC 18 7109No ratings yet
- 31-34 - Artificial Neural NetworkDocument36 pages31-34 - Artificial Neural NetworkZalak RakholiyaNo ratings yet
- Brain - Inspired Computing: Wozniak Et Al. Yin Et Al. MasquelierDocument5 pagesBrain - Inspired Computing: Wozniak Et Al. Yin Et Al. MasquelierNITHYASREE K RNo ratings yet
- IEE3664-2021 Cap6Document122 pagesIEE3664-2021 Cap6diego Gonzalez ArayaNo ratings yet
- Lessons From The Neighborhood Viewer: Building Innovative Collaborative ApplicationsDocument12 pagesLessons From The Neighborhood Viewer: Building Innovative Collaborative ApplicationspostscriptNo ratings yet
- Brain ChipsDocument24 pagesBrain Chipsadbccbda100% (2)
- Unit 1 Complete NotesDocument44 pagesUnit 1 Complete Notes20bd1a058tNo ratings yet
- Report Brain ChipsDocument18 pagesReport Brain Chipsshaik shaNo ratings yet
- Artificial Neural Networks: Seminar Report OnDocument24 pagesArtificial Neural Networks: Seminar Report OnsudhirpratapsinghratNo ratings yet
- Brain Chips Seminar Report PDFDocument3 pagesBrain Chips Seminar Report PDFPrince TreasureNo ratings yet
- Training Spiking Neural Networks Using Lessons From Deep LearningDocument39 pagesTraining Spiking Neural Networks Using Lessons From Deep Learningvikash sainiNo ratings yet
- Malla Reddy Engineering College: K.AnushaDocument32 pagesMalla Reddy Engineering College: K.AnushaAnusha GupthaNo ratings yet
- Blue Brain - The Future GenerationDocument5 pagesBlue Brain - The Future GenerationApoorva SNo ratings yet
- Book Reviews: Ultimate Computing. Ultimate ComputingDocument2 pagesBook Reviews: Ultimate Computing. Ultimate ComputingLeo RuilovaNo ratings yet
- Advanced Neural ComputersFrom EverandAdvanced Neural ComputersR. EckmillerNo ratings yet
- Siddharth DhimanDocument9 pagesSiddharth DhimansumitNo ratings yet
- Unit 1 NotesDocument14 pagesUnit 1 NotesThor AvengersNo ratings yet
- Brain Chip ReportDocument30 pagesBrain Chip Reportsrikanthkalemla100% (3)
- Neural NetworksDocument51 pagesNeural Networkselamein osmanNo ratings yet
- Fuzzy & Nural NetworkDocument24 pagesFuzzy & Nural NetworkRavi ShankarNo ratings yet
- Blue Brain The Future Generation IJERTCONV3IS30024Document5 pagesBlue Brain The Future Generation IJERTCONV3IS30024Diya JosephNo ratings yet
- Blue Brain The Future Generation IJERTCONV3IS30024Document5 pagesBlue Brain The Future Generation IJERTCONV3IS30024Diya JosephNo ratings yet
- ROBOTSDocument5 pagesROBOTSToàn Nguyễn HữuNo ratings yet
- Latest Research Papers On Blue Brain TechnologyDocument5 pagesLatest Research Papers On Blue Brain Technologyafnhdqfvufitoa100% (1)
- 4 Distance PDFDocument60 pages4 Distance PDFJaved Ahmed LaghariNo ratings yet
- S S.A.E: Infrastructure & Cities Sector - Smart Grid DivisionDocument33 pagesS S.A.E: Infrastructure & Cities Sector - Smart Grid DivisionJaved Ahmed LaghariNo ratings yet
- 1 s2.0 S1364032112006983 Main PDFDocument15 pages1 s2.0 S1364032112006983 Main PDFJaved Ahmed LaghariNo ratings yet
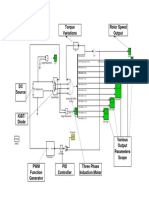
- Torque Variations Rotor Speed Output: Three - Phase Asynchronous MachineDocument1 pageTorque Variations Rotor Speed Output: Three - Phase Asynchronous MachineJaved Ahmed LaghariNo ratings yet
- 3-O FaultDocument15 pages3-O FaultJaved Ahmed LaghariNo ratings yet
- Energy Choices: A Guide To Facts and PerspectivesDocument54 pagesEnergy Choices: A Guide To Facts and PerspectivesJaved Ahmed LaghariNo ratings yet
- Experiment 6 Perunit Calculations and Impedance DiagramsDocument3 pagesExperiment 6 Perunit Calculations and Impedance DiagramsJaved Ahmed LaghariNo ratings yet
- 2023 11 Brain HeartDocument5 pages2023 11 Brain HeartRoberto PradaNo ratings yet
- The Essential Guide To Brain Tumors PDFDocument43 pagesThe Essential Guide To Brain Tumors PDFA Farid WajdyNo ratings yet
- Transformational Guided ImageryDocument29 pagesTransformational Guided ImagerySerene In100% (2)
- Physiology of Memory and LearningDocument48 pagesPhysiology of Memory and LearningWahyoe PoeshNo ratings yet
- Trends of Neuromarketing Metric AnalysisDocument16 pagesTrends of Neuromarketing Metric Analysismanoj kumar DasNo ratings yet
- OMara Shane 2019 in Praise of Walking The New Science of How We Walk and Why Its Good For UsDocument8 pagesOMara Shane 2019 in Praise of Walking The New Science of How We Walk and Why Its Good For Uspandujb213No ratings yet
- Positive Emotions in EducationDocument15 pagesPositive Emotions in Educationmanuel alvarezNo ratings yet
- Midbrain PDFDocument35 pagesMidbrain PDFGjvbNo ratings yet
- Bacs5361 201801Document8 pagesBacs5361 201801Carl DarcyNo ratings yet
- Instincts, Subtypes, or Instinctual Variants As Defined in Enneagram LiteratureDocument3 pagesInstincts, Subtypes, or Instinctual Variants As Defined in Enneagram LiteratureVivian LuNo ratings yet
- Type of Psychology: Learning: Psychology Ivan Petrovich PavlovDocument7 pagesType of Psychology: Learning: Psychology Ivan Petrovich Pavlovjose roque farfan100% (1)
- Biological PsychologyDocument4 pagesBiological PsychologyLouie Mae SantosNo ratings yet
- Module 4 Psychological PerspectiveDocument7 pagesModule 4 Psychological PerspectiveKaye CarbonelNo ratings yet
- Commonlit - Why It S Time To Lay The Stereotype of The Teen Brain To Rest - Student PDFDocument6 pagesCommonlit - Why It S Time To Lay The Stereotype of The Teen Brain To Rest - Student PDFHoàngAnhNo ratings yet
- Relationships/Apollo ArtemisDocument4 pagesRelationships/Apollo ArtemisMoon5627No ratings yet
- BC 08 2005 Play and The Regulation of Aggression. Devel Orig AggressDocument25 pagesBC 08 2005 Play and The Regulation of Aggression. Devel Orig Aggressmacplenty50% (2)
- Evidence OneDocument21 pagesEvidence Oneapi-253013067No ratings yet
- Accelerated LearninigDocument1 pageAccelerated LearninigsuperspeedlearningNo ratings yet
- Interstellar SpaceshipDocument84 pagesInterstellar SpaceshipLawrence ZeitlinNo ratings yet
- Cerebrospinal Fluid Flow - Anatomy and Functions - KenhubDocument8 pagesCerebrospinal Fluid Flow - Anatomy and Functions - KenhubSajal SahaNo ratings yet
- Soal Un 2021Document9 pagesSoal Un 2021JamsulNo ratings yet
- R. Hassler, H. Stephan (Eds.) - Evolution of The ForebrainDocument472 pagesR. Hassler, H. Stephan (Eds.) - Evolution of The ForebrainGregori JacksonNo ratings yet
- Bodily SelfDocument22 pagesBodily SelfGaetano CaliendoNo ratings yet
- Psychology Myers 10e MidtermDocument6 pagesPsychology Myers 10e Midtermgettin_online1404No ratings yet
- Neural Control and Coordination Grade 11Document30 pagesNeural Control and Coordination Grade 11Dr. Remya RanjithNo ratings yet