Download as pdf or txt
You might also like
- Beech 1900 ManualDocument2 pagesBeech 1900 ManualAlmir Rodrigues0% (2)
- VLSI Interview QuestionsDocument7 pagesVLSI Interview QuestionsVlsi GuruNo ratings yet
- ZamZam Water by Dr. EmotoDocument3 pagesZamZam Water by Dr. Emotohadjeas83% (6)
- Philip Merlan, From Platonism To NeoplatonismDocument267 pagesPhilip Merlan, From Platonism To NeoplatonismAnonymous fgaljTd100% (1)
- Chippewa Park Master Plan ReportDocument28 pagesChippewa Park Master Plan ReportinforumdocsNo ratings yet
- Lec18-Static BRANCH PREDICTION VLIWDocument40 pagesLec18-Static BRANCH PREDICTION VLIWi_2loveu3235No ratings yet
- 2.advanced Compiler Support For ILPDocument16 pages2.advanced Compiler Support For ILPThyaga Rajan100% (1)
- Computer Science 146 Computer ArchitectureDocument22 pagesComputer Science 146 Computer ArchitectureharshvNo ratings yet
- CS6461 - Computer Architecture Fall 2016 Adapted From Professor Stephen Kaisler's SlidesDocument71 pagesCS6461 - Computer Architecture Fall 2016 Adapted From Professor Stephen Kaisler's Slides闫麟阁No ratings yet
- Topic2c Ss DynamicschedulingDocument94 pagesTopic2c Ss DynamicschedulingCalam1tousNo ratings yet
- ACA Unit 8 Hardware and Software For VLIW and EPIC Notes - Unit 8Document35 pagesACA Unit 8 Hardware and Software For VLIW and EPIC Notes - Unit 8Kedar KulkarniNo ratings yet
- EEF011 Computer Architecture 計算機結構: Exploiting Instruction-Level Parallelism with Software ApproachesDocument40 pagesEEF011 Computer Architecture 計算機結構: Exploiting Instruction-Level Parallelism with Software Approachesi_2loveu32350% (1)
- Unit Ii Program Design and Analysis: - Software Components. - Representations of Programs. - Assembly and LinkingDocument60 pagesUnit Ii Program Design and Analysis: - Software Components. - Representations of Programs. - Assembly and LinkingRahul SharmaNo ratings yet
- Unit IIDocument84 pagesUnit IISenthil RajNo ratings yet
- CSE 820 Graduate Computer Architecture Week 5 - Instruction Level ParallelismDocument38 pagesCSE 820 Graduate Computer Architecture Week 5 - Instruction Level ParallelismkbkkrNo ratings yet
- About Scan D Flip FlopsDocument11 pagesAbout Scan D Flip FlopsAishwarya TapadiyaNo ratings yet
- ch09 Morris ManoDocument15 pagesch09 Morris ManoYogita Negi RawatNo ratings yet
- Embedded Systems Design: Pipelining and Instruction SchedulingDocument48 pagesEmbedded Systems Design: Pipelining and Instruction SchedulingMisbah Sajid ChaudhryNo ratings yet
- Designing An Instruction Set: Handouts: Lecture Notes, Lab 4, PS4 SolutionsDocument28 pagesDesigning An Instruction Set: Handouts: Lecture Notes, Lab 4, PS4 Solutionsabybaby79No ratings yet
- Computer Science 146 Computer ArchitectureDocument18 pagesComputer Science 146 Computer ArchitectureharshvNo ratings yet
- U. Wisconsin CS/ECE 752 Advanced Computer Architecture IDocument74 pagesU. Wisconsin CS/ECE 752 Advanced Computer Architecture Igautamd07No ratings yet
- Chapter Four The Processor: Datapath and ControlDocument45 pagesChapter Four The Processor: Datapath and ControlOsama AlqahtaniNo ratings yet
- Computer Organization: An Introduction To RISC Hardware: 6.1 An Overview of PipeliningDocument12 pagesComputer Organization: An Introduction To RISC Hardware: 6.1 An Overview of PipeliningAmrendra Kumar MishraNo ratings yet
- Systemverilog - CodingDocument39 pagesSystemverilog - CodingV SharmaNo ratings yet
- Computer Architecture LU Lab Notes/Assignments: Wpuffits@mail - Tuwien.ac - atDocument15 pagesComputer Architecture LU Lab Notes/Assignments: Wpuffits@mail - Tuwien.ac - atአንድነት togetherNo ratings yet
- Cs2106 1516s2 Midterm SolutionDocument16 pagesCs2106 1516s2 Midterm SolutionReynard ArdianNo ratings yet
- CAunitiiiDocument36 pagesCAunitiiiKishore Arun KumarNo ratings yet
- VLSI PD Question BankDocument26 pagesVLSI PD Question BankSparkIntellect100% (3)
- Tuesday, October 31, 2023 10:53 PM: Discuss, The Schemes For Dealing With The Pipeline Stalls Caused by Branch HazardsDocument7 pagesTuesday, October 31, 2023 10:53 PM: Discuss, The Schemes For Dealing With The Pipeline Stalls Caused by Branch Hazardskrahul74714No ratings yet
- Instruction Level Parallelism: PipeliningDocument6 pagesInstruction Level Parallelism: PipeliningkbkkrNo ratings yet
- Cs2106 1617s1 Midterm SolutionDocument13 pagesCs2106 1617s1 Midterm SolutionReynard ArdianNo ratings yet
- Introduction To Advanced PipeliningDocument64 pagesIntroduction To Advanced PipeliningNoman Ali ShahNo ratings yet
- 13) Ilp1 PDFDocument85 pages13) Ilp1 PDFAnoushka SaraswatNo ratings yet
- Ca CT2Document4 pagesCa CT2krahul74714No ratings yet
- Aca Midsem2011 Question PaperDocument1 pageAca Midsem2011 Question PaperKartik MakkarNo ratings yet
- Parallel Programming Platforms: Alexandre David 1.2.05Document30 pagesParallel Programming Platforms: Alexandre David 1.2.05Priya PatelNo ratings yet
- OS Midterm SolutionDocument4 pagesOS Midterm SolutionRofaelEmil100% (2)
- Questions With AnswersDocument22 pagesQuestions With AnswersYuva SathiyamoorthyNo ratings yet
- Assignment 3Document4 pagesAssignment 3anoopaman5No ratings yet
- 4 Hspice TutorialDocument134 pages4 Hspice Tutorialspiderman86No ratings yet
- List Scheduling Review: The Ideal Scheduling Outcome: Hardware ResourcesDocument7 pagesList Scheduling Review: The Ideal Scheduling Outcome: Hardware ResourcesKennethDelaCruzNo ratings yet
- Compiler Techniques For Exposing ILPDocument18 pagesCompiler Techniques For Exposing ILPDivya RadhakrishnanNo ratings yet
- Synthesis and Place & Route: CS/ECE 6710 Tool SuiteDocument48 pagesSynthesis and Place & Route: CS/ECE 6710 Tool SuitekammohNo ratings yet
- CMP4011 T2 PORT1 Main 2023-24Document8 pagesCMP4011 T2 PORT1 Main 2023-24herocreeperbrplaysNo ratings yet
- Slides 12Document24 pagesSlides 12Charu PrasharNo ratings yet
- Pipelining and Instruction Level Parallelism: 5 Steps of MIPS DatapathDocument12 pagesPipelining and Instruction Level Parallelism: 5 Steps of MIPS DatapathNgat SkyNo ratings yet
- Verilog Interview QuestionsDocument7 pagesVerilog Interview QuestionsVishal K SrivastavaNo ratings yet
- SBFspot V3 Quick Reference Linux EN 1 0Document15 pagesSBFspot V3 Quick Reference Linux EN 1 0cadoragoNo ratings yet
- Mips ImplementationDocument47 pagesMips ImplementationJEEVANANTHAM GNo ratings yet
- Challenging Multi CoresDocument27 pagesChallenging Multi CoresPaul CockshottNo ratings yet
- Hardware-Software Interface: - Code TranslationDocument47 pagesHardware-Software Interface: - Code TranslationMax ViznerNo ratings yet
- 4 1.soc EncounterDocument181 pages4 1.soc Encounterachew911No ratings yet
- Lect14 4upDocument8 pagesLect14 4upUppala SudheerNo ratings yet
- Class15 Floatpt-Handout PDFDocument18 pagesClass15 Floatpt-Handout PDFPavan BeharaNo ratings yet
- CAQA5e ch3Document45 pagesCAQA5e ch3Jameem AhamedNo ratings yet
- Architecture 2020Document10 pagesArchitecture 2020honey arguellesNo ratings yet
- Data Dependences and HazardsDocument24 pagesData Dependences and Hazardssshekh28374No ratings yet
- Superscalar and VLIW ArchitecturesDocument35 pagesSuperscalar and VLIW ArchitecturesNusrat Mary ChowdhuryNo ratings yet
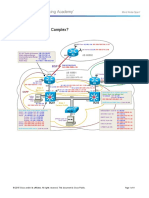
- CCNPv7.1 TSHOOT Lab10-1 Complex StudentDocument11 pagesCCNPv7.1 TSHOOT Lab10-1 Complex StudentJimNo ratings yet
- EE (CE) 6304 Computer Architecture Lecture #2 (8/28/13)Document35 pagesEE (CE) 6304 Computer Architecture Lecture #2 (8/28/13)Vishal MehtaNo ratings yet
- Recursion and ImplementationDocument30 pagesRecursion and ImplementationRohan HazraNo ratings yet
- Relational Database Index Design and the Optimizers: DB2, Oracle, SQL Server, et al.From EverandRelational Database Index Design and the Optimizers: DB2, Oracle, SQL Server, et al.Rating: 5 out of 5 stars5/5 (1)
- Using The Bitcoin Transaction Graph To Predict The Price of BitcoinDocument8 pagesUsing The Bitcoin Transaction Graph To Predict The Price of BitcoinharshvNo ratings yet
- Da IDocument1 pageDa IharshvNo ratings yet
- Computer Science 146 Computer ArchitectureDocument19 pagesComputer Science 146 Computer ArchitectureharshvNo ratings yet
- Computer Science 146 Computer ArchitectureDocument17 pagesComputer Science 146 Computer ArchitectureharshvNo ratings yet
- Computer Science 146 Computer ArchitectureDocument18 pagesComputer Science 146 Computer ArchitectureharshvNo ratings yet
- Computer Science 146 Computer ArchitectureDocument17 pagesComputer Science 146 Computer ArchitectureharshvNo ratings yet
- Computer Science 146 Computer ArchitectureDocument16 pagesComputer Science 146 Computer ArchitectureharshvNo ratings yet
- Computer Science 146 Computer ArchitectureDocument18 pagesComputer Science 146 Computer ArchitectureharshvNo ratings yet
- Computer Science 146 Computer ArchitectureDocument22 pagesComputer Science 146 Computer ArchitectureharshvNo ratings yet
- Computer Science 146 Computer ArchitectureDocument52 pagesComputer Science 146 Computer ArchitectureharshvNo ratings yet
- Hazardous Areas - Explosionproof Solenoids: Some HistoryDocument5 pagesHazardous Areas - Explosionproof Solenoids: Some HistoryShahram GhassemiNo ratings yet
- Research Report - Aakanksha MistryDocument19 pagesResearch Report - Aakanksha MistryAakanksha MistryNo ratings yet
- UNITS 1-17 Diagnostic Test 8E (Standard) : You Have ONE HOUR To Complete This TestDocument21 pagesUNITS 1-17 Diagnostic Test 8E (Standard) : You Have ONE HOUR To Complete This TestNayem Hossain HemuNo ratings yet
- Storage Fading of A Commercial 18650 Cell Comprised With NMC LMO Cathode and Graphite AnodeDocument10 pagesStorage Fading of A Commercial 18650 Cell Comprised With NMC LMO Cathode and Graphite AnodeEnrique MachucaNo ratings yet
- Evertz MVP Manual PDFDocument2 pagesEvertz MVP Manual PDFDavidNo ratings yet
- A PDFDocument4 pagesA PDFChandu ThorNo ratings yet
- Automag Industries, Chennai: ISI StandardsDocument2 pagesAutomag Industries, Chennai: ISI Standardsnaga1501No ratings yet
- 1.load Test On DC Shut MotorDocument5 pages1.load Test On DC Shut Motorg3v5No ratings yet
- TraceHeat BrochureDocument13 pagesTraceHeat BrochureIvanNo ratings yet
- Galvafroid Data SheetDocument13 pagesGalvafroid Data SheetAdam HughesNo ratings yet
- Fan Basics and Selection CriteriaDocument6 pagesFan Basics and Selection CriteriaSangamesh WaranNo ratings yet
- 520SL SLB Guide en USDocument2 pages520SL SLB Guide en USBruce CanvasNo ratings yet
- Technological Institute of The Philippines-ManilaDocument17 pagesTechnological Institute of The Philippines-ManilaRoscarl GorospeNo ratings yet
- Tabletop Gaming - Best Games of 2019Document198 pagesTabletop Gaming - Best Games of 2019Paulina Barszez100% (1)
- Timken #1 in Comparison Test:: Tapered Roller Bearings Commonly Used in Agricultural-Type EquipmentDocument2 pagesTimken #1 in Comparison Test:: Tapered Roller Bearings Commonly Used in Agricultural-Type Equipmentapi-89480251No ratings yet
- Measuring Place Attachment: Some Preliminary Results: October 1989Document8 pagesMeasuring Place Attachment: Some Preliminary Results: October 1989LathifahNo ratings yet
- MCO 3 (30/3-3/4/2020) Reinforcement Chapter 2 Part A: Objective QuestionsDocument5 pagesMCO 3 (30/3-3/4/2020) Reinforcement Chapter 2 Part A: Objective QuestionsZalini AbdullahNo ratings yet
- Agribusiness: ExamplesDocument4 pagesAgribusiness: ExamplesAngelo AristizabalNo ratings yet
- Mento - Katalog Master Flo Choke Valves - 17.08.20 - LowDocument37 pagesMento - Katalog Master Flo Choke Valves - 17.08.20 - Lowsherif aymanNo ratings yet
- Type 4536 Oscillator-Divider ICDocument13 pagesType 4536 Oscillator-Divider ICRoscoeDog718No ratings yet
- Private Peaceful EssayDocument7 pagesPrivate Peaceful Essayb6zm3pxh100% (2)
- Roland Robertson - Beyond The Discourse of Globalization PDFDocument14 pagesRoland Robertson - Beyond The Discourse of Globalization PDFCamilaRivasNo ratings yet
- LS10 6clozeDocument1 pageLS10 6clozesinned68No ratings yet
- DER Vol III DrawingDocument50 pagesDER Vol III Drawingdaryl sabadoNo ratings yet
- Bullous PemphigoidDocument21 pagesBullous PemphigoidChe Ainil ZainodinNo ratings yet
- Group Screening Test, English 6Document4 pagesGroup Screening Test, English 6Jayson Alvarez MagnayeNo ratings yet