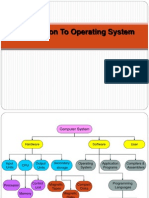
Download as pdf or txt
You might also like
- A Comprehensive Presentation On 'An Analysis of Linux Scalability To Many Cores'Document49 pagesA Comprehensive Presentation On 'An Analysis of Linux Scalability To Many Cores'RomeoTangoNo ratings yet
- Computer Science 146 Computer ArchitectureDocument22 pagesComputer Science 146 Computer ArchitectureharshvNo ratings yet
- 11 MemoryDocument41 pages11 MemoryKhoa PhamNo ratings yet
- Computer Architecture Cache DesignDocument28 pagesComputer Architecture Cache Designprahallad_reddy100% (3)
- Computer Science 146 Computer ArchitectureDocument16 pagesComputer Science 146 Computer ArchitectureharshvNo ratings yet
- Operating Systems and Computer Architecture: Eng. Hector M Lugo-Cordero, MS CIS 4361 Secure OS AdminDocument35 pagesOperating Systems and Computer Architecture: Eng. Hector M Lugo-Cordero, MS CIS 4361 Secure OS Adminalex bascoNo ratings yet
- Computer Science 146 Computer ArchitectureDocument17 pagesComputer Science 146 Computer ArchitectureharshvNo ratings yet
- Cache CoherenceDocument39 pagesCache Coherencevivek srivastavNo ratings yet
- Operating System 4Document33 pagesOperating System 4Seham123123No ratings yet
- Computer Science 146 Computer ArchitectureDocument18 pagesComputer Science 146 Computer ArchitectureharshvNo ratings yet
- Lecture 12: Memory Hierarchy - Cache Optimizations: CSCE 513 Computer ArchitectureDocument69 pagesLecture 12: Memory Hierarchy - Cache Optimizations: CSCE 513 Computer ArchitectureFahim ShaikNo ratings yet
- Cache Coherence: Part 1: Todd C. Mowry CS 740 November 4, 1999Document39 pagesCache Coherence: Part 1: Todd C. Mowry CS 740 November 4, 1999AthreyaNo ratings yet
- Cache Coherence CS433 Spring 2001: Laxmikant KaleDocument22 pagesCache Coherence CS433 Spring 2001: Laxmikant Kalemadhu75No ratings yet
- Caching: File Systems: OutlineDocument25 pagesCaching: File Systems: OutlineSangeetha BajanthriNo ratings yet
- Snooping Cache and Directory Based MultiprocessorsDocument59 pagesSnooping Cache and Directory Based MultiprocessorsSantosh Kumar ChoudharyNo ratings yet
- 1.symmetric and Distributed Shared Memory ArchitecturesDocument29 pages1.symmetric and Distributed Shared Memory Architecturesi_2loveu323579% (19)
- Lecture3 Os SupportDocument20 pagesLecture3 Os SupporthanhndNo ratings yet
- Techniques For Accessing I/O Devices: C.Sc. 131: Systems Architecture C.Sc. 131: Systems ArchitectureDocument6 pagesTechniques For Accessing I/O Devices: C.Sc. 131: Systems Architecture C.Sc. 131: Systems ArchitecturePeter TeohNo ratings yet
- Lecture 19Document20 pagesLecture 19api-3801184No ratings yet
- Caches and MemoryDocument65 pagesCaches and MemoryRupjit ChakrabortyNo ratings yet
- Address Translation, Caches, and TlbsDocument32 pagesAddress Translation, Caches, and TlbskapilhaliNo ratings yet
- Unit 5 (Slides)Document75 pagesUnit 5 (Slides)Keerthana g.krishnanNo ratings yet
- Advanced Computer Architecture-06CS81-Memory Hierarchy DesignDocument18 pagesAdvanced Computer Architecture-06CS81-Memory Hierarchy DesignYutyu YuiyuiNo ratings yet
- Computer Science 246 Computer Architecture: Si 2009 Spring 2009 Harvard UniversityDocument27 pagesComputer Science 246 Computer Architecture: Si 2009 Spring 2009 Harvard Universityrafi skNo ratings yet
- Memory Hierarchy DesignDocument115 pagesMemory Hierarchy Designshivu96No ratings yet
- Lecture 11: Consistency Models: Topics: Sequential Consistency, HW and HW/SW OptimizationsDocument18 pagesLecture 11: Consistency Models: Topics: Sequential Consistency, HW and HW/SW OptimizationsBait Ullah KhanNo ratings yet
- Computer Architecture 1st Semester Spring Session Unit 3Document33 pagesComputer Architecture 1st Semester Spring Session Unit 3mohsinmanzoorNo ratings yet
- Chapter 6Document37 pagesChapter 6shubhamvslaviNo ratings yet
- This Study Resource Was: EC-2 Regular Sample SolutionsDocument3 pagesThis Study Resource Was: EC-2 Regular Sample SolutionsRajesh BhardwajNo ratings yet
- Computer Science 146 Computer ArchitectureDocument19 pagesComputer Science 146 Computer ArchitectureharshvNo ratings yet
- ACA Unit-5Document54 pagesACA Unit-5mannanabdulsattarNo ratings yet
- Memory Hierarchy Design-AcaDocument15 pagesMemory Hierarchy Design-AcaGuruCharan SinghNo ratings yet
- Memory Part IIDocument56 pagesMemory Part IIRonald FerrufinoNo ratings yet
- Today: I/O Systems!: Shared by Multiple Devices. A Device Port Typically Consisting of 4 RegistersDocument14 pagesToday: I/O Systems!: Shared by Multiple Devices. A Device Port Typically Consisting of 4 RegistersBình NguyênNo ratings yet
- General Principles of Pipelining: Andrew Warfield CS313Document25 pagesGeneral Principles of Pipelining: Andrew Warfield CS313NishanthoraNo ratings yet
- Shared Memory MultiprocessorsDocument45 pagesShared Memory MultiprocessorsSushma Rani VatekarNo ratings yet
- 2.2 DD2356 ThreadsDocument22 pages2.2 DD2356 ThreadsDaniel AraújoNo ratings yet
- CDA3101 L01 Introduction MSSDocument20 pagesCDA3101 L01 Introduction MSSRosemond FabienNo ratings yet
- Session Level Yapp Handout PDFDocument27 pagesSession Level Yapp Handout PDFCharles G GalaxyaanNo ratings yet
- Cs 6461 Computer Architecture Lecture 11Document51 pagesCs 6461 Computer Architecture Lecture 11闫麟阁No ratings yet
- Operating System ConceptsDocument116 pagesOperating System ConceptsVivek278100% (3)
- Chapter 7Document97 pagesChapter 7K S Sanath KashyapNo ratings yet
- I/O Interfaces and I/O BussesDocument31 pagesI/O Interfaces and I/O Bussesah chongNo ratings yet
- 2015Sp CS61C L16 Kavs Caches3Document25 pages2015Sp CS61C L16 Kavs Caches3MaiDungNo ratings yet
- Snooping vs. Directory Based Coherency: Professor David A. Patterson Computer Science 252 Fall 1996Document59 pagesSnooping vs. Directory Based Coherency: Professor David A. Patterson Computer Science 252 Fall 1996ReniNo ratings yet
- Unit-5 Part1Document85 pagesUnit-5 Part1himateja mygopulaNo ratings yet
- Lec13 MultiprocessorsDocument69 pagesLec13 MultiprocessorsdoomachaleyNo ratings yet
- Embedded Systems Design: Pipelining and Instruction SchedulingDocument48 pagesEmbedded Systems Design: Pipelining and Instruction SchedulingMisbah Sajid ChaudhryNo ratings yet
- EE (CE) 6304 Computer Architecture Lecture #2 (8/28/13)Document35 pagesEE (CE) 6304 Computer Architecture Lecture #2 (8/28/13)Vishal MehtaNo ratings yet
- Lec4 1Document33 pagesLec4 1ASHI KOTHARINo ratings yet
- rh442 NotesDocument26 pagesrh442 Notesindrajitnandi8161No ratings yet
- Week 5 DiscussionDocument38 pagesWeek 5 DiscussionSiri Varshitha Reddy LingareddyNo ratings yet
- Hints For Computer System Design: Butler W. LampsonDocument16 pagesHints For Computer System Design: Butler W. LampsonsushmsnNo ratings yet
- Unit - 1 Microprocessor ArchitectureDocument52 pagesUnit - 1 Microprocessor ArchitectureSasidhar NagisettyNo ratings yet
- Cache PerformanceDocument41 pagesCache PerformanceDebashis DasNo ratings yet
- Directory-Based Cache Coherence Protocols: Interconnection Networks For MultiprocessorsDocument9 pagesDirectory-Based Cache Coherence Protocols: Interconnection Networks For MultiprocessorsAmey KulkarniNo ratings yet
- EECS 150 - Components and Design Techniques For Digital SystemsDocument38 pagesEECS 150 - Components and Design Techniques For Digital SystemsNirneya GuptaNo ratings yet
- Cache Memory - January 2014Document90 pagesCache Memory - January 2014Dare DevilNo ratings yet
- Synchronization: Han Wang CS 3410, Spring 2012Document67 pagesSynchronization: Han Wang CS 3410, Spring 2012vlnNo ratings yet
- Da IDocument1 pageDa IharshvNo ratings yet
- Using The Bitcoin Transaction Graph To Predict The Price of BitcoinDocument8 pagesUsing The Bitcoin Transaction Graph To Predict The Price of BitcoinharshvNo ratings yet
- Computer Science 146 Computer ArchitectureDocument19 pagesComputer Science 146 Computer ArchitectureharshvNo ratings yet
- Computer Science 146 Computer ArchitectureDocument17 pagesComputer Science 146 Computer ArchitectureharshvNo ratings yet
- Computer Science 146 Computer ArchitectureDocument13 pagesComputer Science 146 Computer ArchitectureharshvNo ratings yet
- Computer Science 146 Computer ArchitectureDocument18 pagesComputer Science 146 Computer ArchitectureharshvNo ratings yet
- Computer Science 146 Computer ArchitectureDocument16 pagesComputer Science 146 Computer ArchitectureharshvNo ratings yet
- Computer Science 146 Computer ArchitectureDocument18 pagesComputer Science 146 Computer ArchitectureharshvNo ratings yet
- Computer Science 146 Computer ArchitectureDocument22 pagesComputer Science 146 Computer ArchitectureharshvNo ratings yet
- Computer Science 146 Computer ArchitectureDocument52 pagesComputer Science 146 Computer ArchitectureharshvNo ratings yet
- Trends in Big Data AnalyticsDocument13 pagesTrends in Big Data Analyticsguru9anandNo ratings yet
- Multiprocessing Wiki 20150330Document96 pagesMultiprocessing Wiki 20150330christian.chabrerieNo ratings yet
- Grad MSC AcsDocument4 pagesGrad MSC AcsAsh 666No ratings yet
- UntitledDocument1 pageUntitledGopinath BalamuruganNo ratings yet
- William Stallings Computer Organization and Architecture 10 EditionDocument33 pagesWilliam Stallings Computer Organization and Architecture 10 EditionkrtxbNo ratings yet
- Chameleon Chips Full ReportDocument40 pagesChameleon Chips Full Reporttejaswi_manthena05No ratings yet
- HPC Unit 3Document31 pagesHPC Unit 3Sudha PalaniNo ratings yet
- Dlau Major Project ReportDocument38 pagesDlau Major Project ReportcvrrkumariNo ratings yet
- CA Notes Chapter1Document28 pagesCA Notes Chapter1Nithyan NithyaNo ratings yet
- Characteristics Multi ProcessorsDocument7 pagesCharacteristics Multi ProcessorsRajiv Kumar SharmaNo ratings yet
- OpenACC Course 2018 Week 1Document54 pagesOpenACC Course 2018 Week 1xuhaffgNo ratings yet
- Fast BVH Construction On GpusDocument11 pagesFast BVH Construction On GpusMuhammed MRMNo ratings yet
- Resource ManagerDocument9 pagesResource ManagerVishnusivathej PotukanumaNo ratings yet
- 1.4-Parallel Computer ArchitectureDocument22 pages1.4-Parallel Computer ArchitectureChetan SolankiNo ratings yet
- Distributed SystemDocument76 pagesDistributed SystemTulipNo ratings yet
- Shared Memory Multiprocessors: Logical Design and Software InteractionsDocument107 pagesShared Memory Multiprocessors: Logical Design and Software Interactionsfariha2002No ratings yet
- Discrete Element MethodsDocument564 pagesDiscrete Element Methodschingon987100% (8)
- 05 CC - Complete Notes - Er. Loknath RegmiDocument81 pages05 CC - Complete Notes - Er. Loknath RegmiAnoo ShresthaNo ratings yet
- Pipeline and VectorDocument29 pagesPipeline and VectorGâgäñ LøhîăNo ratings yet
- COA Lesson Plan - ModifiedDocument3 pagesCOA Lesson Plan - Modifiedmdzakir_hussainNo ratings yet
- Object Recognition in Aerial ImagesDocument9 pagesObject Recognition in Aerial ImagesJunaid AkramNo ratings yet
- A Cluster Computer and Its ArchitectureDocument3 pagesA Cluster Computer and Its ArchitecturePratik SharmaNo ratings yet
- Real Time Moving Human Detection Using HOG and Fourier Descriptor Based On CUDA ImplementationDocument16 pagesReal Time Moving Human Detection Using HOG and Fourier Descriptor Based On CUDA Implementationsayadi fatmaNo ratings yet
- Chapter 3 Parallel and Pipelined Processing: 1 ECE734 VLSI Arrays For Digital Signal ProcessingDocument13 pagesChapter 3 Parallel and Pipelined Processing: 1 ECE734 VLSI Arrays For Digital Signal ProcessingM Madan GopalNo ratings yet
- Understanding The Impact of Multi-Core Architecture in Cluster Computing: A Case Study With Intel Dual-Core SystemDocument8 pagesUnderstanding The Impact of Multi-Core Architecture in Cluster Computing: A Case Study With Intel Dual-Core SystemhfarrukhnNo ratings yet
- 1.symmetric and Distributed Shared Memory ArchitecturesDocument29 pages1.symmetric and Distributed Shared Memory Architecturesi_2loveu323579% (19)
- Vedic MultiplierDocument65 pagesVedic MultiplierKrishnaraoMane100% (1)
- A Guide To Advanced Functional VerificationDocument208 pagesA Guide To Advanced Functional VerificationMohammad Seemab AslamNo ratings yet
- OS - Unit 1 - NotesDocument15 pagesOS - Unit 1 - Notestanay282004guptaNo ratings yet
- Sanjay - High Performance DSP ArchitecturesDocument38 pagesSanjay - High Performance DSP Architecturesapi-3827000No ratings yet