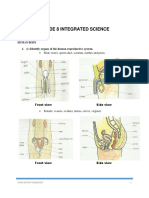
Download as pdf or txt
You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5835)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1093)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (852)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (903)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (541)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (350)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (824)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (405)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Ch17Answers PDFDocument11 pagesCh17Answers PDFalbert601873% (15)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Soon He Shall Come-Score - and - PartsDocument29 pagesSoon He Shall Come-Score - and - PartsKasman Kasonde MumbaNo ratings yet
- 07 0620 0971 Ext Teacher ChecklistDocument2 pages07 0620 0971 Ext Teacher ChecklistKasman Kasonde MumbaNo ratings yet
- Elements, Compounds and Chemical EquationsDocument11 pagesElements, Compounds and Chemical EquationsKasman Kasonde MumbaNo ratings yet
- African Hymn CollectionDocument169 pagesAfrican Hymn CollectionKasman Kasonde MumbaNo ratings yet
- New Apostolic Church: Divine Service GuideDocument28 pagesNew Apostolic Church: Divine Service GuideKasman Kasonde MumbaNo ratings yet
- Integrated Science 8 & 9 FinalDocument54 pagesIntegrated Science 8 & 9 FinalKasman Kasonde MumbaNo ratings yet
- Matter and Kinetic TheoryDocument21 pagesMatter and Kinetic TheoryKasman Kasonde MumbaNo ratings yet
- Blood Typing and Blood GeneticsDocument21 pagesBlood Typing and Blood GeneticsKasman Kasonde MumbaNo ratings yet
- Atomic Structure Power PointDocument144 pagesAtomic Structure Power PointKasman Kasonde MumbaNo ratings yet
- Holy Spirit, Fount of God's LoveDocument27 pagesHoly Spirit, Fount of God's LoveKasman Kasonde MumbaNo ratings yet
- Sunday School Action Plan For 2017 S/N Activity Venue Tiime Target GroupDocument3 pagesSunday School Action Plan For 2017 S/N Activity Venue Tiime Target GroupKasman Kasonde MumbaNo ratings yet
- African Joy Newsletter3rd Ed Oct 2010Document8 pagesAfrican Joy Newsletter3rd Ed Oct 2010Kasman Kasonde MumbaNo ratings yet
- Negative Effect of Globalization On Education?: Already ExistsDocument2 pagesNegative Effect of Globalization On Education?: Already ExistsKasman Kasonde MumbaNo ratings yet
- Rubric Protein Synthesis Flow ChartDocument1 pageRubric Protein Synthesis Flow ChartJohn OsborneNo ratings yet
- IB Biology B Form and Function pt1Document22 pagesIB Biology B Form and Function pt1rellomharazNo ratings yet
- AminesDocument7 pagesAminesLevirisa ManamtamNo ratings yet
- The New Central Dogma of Molecular Biology: March 2020Document33 pagesThe New Central Dogma of Molecular Biology: March 2020Angelina KobanNo ratings yet
- Pharmacology II 3rd Pharm D Question BankDocument10 pagesPharmacology II 3rd Pharm D Question BankSreya SanilNo ratings yet
- Q Bank Biochemistry: Every Chapter Every Important Question Marks DistributionDocument25 pagesQ Bank Biochemistry: Every Chapter Every Important Question Marks DistributionHK Nova Chiu100% (1)
- 1history of Genetics 1Document8 pages1history of Genetics 1Catherine Noynay RaagasNo ratings yet
- Gustavo Maroni-An Atlas of Drosophila Genes - Sequences and Molecular Features (1993)Document428 pagesGustavo Maroni-An Atlas of Drosophila Genes - Sequences and Molecular Features (1993)AngelinaNo ratings yet
- CH 7 Nucleic AcidsDocument8 pagesCH 7 Nucleic AcidsInes Ait Si SelmiNo ratings yet
- IGNOU-Ph.D. All TopicsDocument83 pagesIGNOU-Ph.D. All Topicsmr.suvarn764ssNo ratings yet
- CHapter 14Document10 pagesCHapter 14alaskamofoNo ratings yet
- Expt. 7 Nucleic Acid WorksheetDocument9 pagesExpt. 7 Nucleic Acid WorksheetMary Ella Mae PilaNo ratings yet
- Protein SynthesisDocument7 pagesProtein SynthesisCreznin YapNo ratings yet
- B. Tech. Biotech Syllabus MDUDocument51 pagesB. Tech. Biotech Syllabus MDUVineet50% (4)
- Chapter 11 Gene ExpressionDocument17 pagesChapter 11 Gene ExpressionAllyssa Mae ClorionNo ratings yet
- Chapter 6 XamideaDocument64 pagesChapter 6 Xamideakeren spamzNo ratings yet
- TranslationDocument20 pagesTranslationSherilyn MutoNo ratings yet
- Science10 Q3 Week4Document22 pagesScience10 Q3 Week4Samad Recca T. NatividadNo ratings yet
- Chapter 15 BIO 1510Document34 pagesChapter 15 BIO 1510Chachi CNo ratings yet
- CBSE Board Class 12 Biology Question Paper Solutions 2023Document19 pagesCBSE Board Class 12 Biology Question Paper Solutions 2023「M24๛ BEAST」No ratings yet
- From Gene To Protein: For Campbell Biology, Ninth EditionDocument75 pagesFrom Gene To Protein: For Campbell Biology, Ninth EditionFENo ratings yet
- Lesson 4-7: Molecular Structure of DNA, RNA, and Proteins: Rhoda S.R. Cayanan, RPH, LPTDocument75 pagesLesson 4-7: Molecular Structure of DNA, RNA, and Proteins: Rhoda S.R. Cayanan, RPH, LPTKarma Akira100% (1)
- Genetics ProblemsDocument50 pagesGenetics ProblemsTasneem Sweedan100% (1)
- B SC - Hons-Biotechnology PDFDocument42 pagesB SC - Hons-Biotechnology PDFsantosh_dhandeNo ratings yet
- Bio Eoc Review PacketDocument29 pagesBio Eoc Review Packetapi-267855902No ratings yet
- Nucleic Acids - DNA and RNADocument53 pagesNucleic Acids - DNA and RNATom Anthony TonguiaNo ratings yet
- Bio 118 (Fall 2007) SyllabusDocument2 pagesBio 118 (Fall 2007) Syllabusjwong87800No ratings yet
- Cells ReviewerDocument3 pagesCells ReviewerIvy LumapacNo ratings yet
- GeneticsDocument55 pagesGeneticsJonathan Carlisle CheungNo ratings yet