Download as pdf or txt
You might also like
- Ae Test Bank This Is Applied Econometrics TestbankDocument134 pagesAe Test Bank This Is Applied Econometrics TestbankThư Nguyễn100% (1)
- Ucchista Ganapati Sadhana - Navarna (9 Lettered) MantraDocument17 pagesUcchista Ganapati Sadhana - Navarna (9 Lettered) Mantraakshay patri50% (2)
- Ucchista Ganapati Sadhana - Navarna (9 Lettered) MantraDocument17 pagesUcchista Ganapati Sadhana - Navarna (9 Lettered) Mantraakshay patri50% (2)
- Chapter 3Document26 pagesChapter 3Renukadevi Rpt33% (3)
- Stat 255 Supplement 2011 FallDocument78 pagesStat 255 Supplement 2011 Fallgoofbooter100% (1)
- Chap2 Discrete DistributionsDocument22 pagesChap2 Discrete Distributionsgocipa7145No ratings yet
- Non Parametric Density EstimationDocument4 pagesNon Parametric Density Estimationzeze1No ratings yet
- Notes04 PDFDocument16 pagesNotes04 PDFFaris BasilNo ratings yet
- Engineering Uncertainty NotesDocument15 pagesEngineering Uncertainty NotesKaren Chong YapNo ratings yet
- Random Variables and Probability Distributions: Chapter ThreeDocument14 pagesRandom Variables and Probability Distributions: Chapter Threegreenday3No ratings yet
- Notes100 ch4Document52 pagesNotes100 ch4sfluk2No ratings yet
- Nadaraya-Watson Teoria PDFDocument9 pagesNadaraya-Watson Teoria PDFLUIS FABIAN URREGO SANCHEZNo ratings yet
- Multivariat Kernel RegressionDocument3 pagesMultivariat Kernel RegressionPartho SarkarNo ratings yet
- Functional AnalysisDocument96 pagesFunctional AnalysistimcantangoNo ratings yet
- Chapter 4Document36 pagesChapter 4Sumedh KakdeNo ratings yet
- Matrices All of Whose Principal Submatrices of Som 1995 Linear Algebra and IDocument85 pagesMatrices All of Whose Principal Submatrices of Som 1995 Linear Algebra and IvahidNo ratings yet
- Information Theory For Single-User Systems With Arbitrary Statistical MemoryDocument111 pagesInformation Theory For Single-User Systems With Arbitrary Statistical MemoryTao-Wei HuangNo ratings yet
- Chapter OneDocument46 pagesChapter OneOmotayo Abayomi100% (1)
- 03 - Random Variables 1Document15 pages03 - Random Variables 1park miruNo ratings yet
- Simon Shaw Bayes TheoryDocument72 pagesSimon Shaw Bayes TheoryKosKal89No ratings yet
- Lecture Notes On Pattern Recognition and Image ProcessingDocument24 pagesLecture Notes On Pattern Recognition and Image ProcessingManojNo ratings yet
- STAT3006 Lecture Notes 2021 Aug8 2021Document110 pagesSTAT3006 Lecture Notes 2021 Aug8 2021DomMMKNo ratings yet
- Estimating PDF'S, Means, Variances: 1 Exp 1: Estimated PDF/CDF Plots From DataDocument12 pagesEstimating PDF'S, Means, Variances: 1 Exp 1: Estimated PDF/CDF Plots From DataShaimaa El SayedNo ratings yet
- Lab4 DensityDocument6 pagesLab4 DensityChoker JoyNo ratings yet
- 3.2.3 Newton's Divided Difference Interpolation: Lagrange Method Has The Following WeaknessesDocument31 pages3.2.3 Newton's Divided Difference Interpolation: Lagrange Method Has The Following WeaknessesKhairulNo ratings yet
- B5a: Techniques of Applied Mathematics: Derek E. Moulton Based On Notes by Andreas M Unch November 21, 2013Document59 pagesB5a: Techniques of Applied Mathematics: Derek E. Moulton Based On Notes by Andreas M Unch November 21, 2013Raja RamNo ratings yet
- ReportDocument37 pagesReportanjan samantaNo ratings yet
- CHP 1curve FittingDocument21 pagesCHP 1curve FittingAbrar HashmiNo ratings yet
- Chapter 3 - Discrete Radom Variables and Probability DistributionDocument70 pagesChapter 3 - Discrete Radom Variables and Probability DistributionTran Minh Nhut (K17 HCM)No ratings yet
- Differential TopologyDocument74 pagesDifferential TopologyYuang ShiNo ratings yet
- Notes100 ch3Document70 pagesNotes100 ch3sfluk2No ratings yet
- Fa NotesDocument85 pagesFa NotesAngelo OppioNo ratings yet
- 3 Mathematical Statistical ModelsDocument68 pages3 Mathematical Statistical ModelsLeo SolanoNo ratings yet
- Fourier Analysis and Sampling Theory: ReadingDocument10 pagesFourier Analysis and Sampling Theory: Readingessi90No ratings yet
- Risk Analysis For Information and Systems Engineering: INSE 6320 - Week 3Document9 pagesRisk Analysis For Information and Systems Engineering: INSE 6320 - Week 3ALIKNFNo ratings yet
- Bachelor Thesis TS Van Der Ber 1Document25 pagesBachelor Thesis TS Van Der Ber 1Renato GaloisNo ratings yet
- Density EstimationDocument17 pagesDensity EstimationGraciela MarquesNo ratings yet
- SVM & Image Classification.Document22 pagesSVM & Image Classification.Alain Parviz SoltaniNo ratings yet
- Anal QualDocument10 pagesAnal Qualquantum3855No ratings yet
- Image Restoration Using A Knn-Variant of The Mean-Shift: Cesario Vincenzo Angelino, Eric Debreuve, Michel BarlaudDocument4 pagesImage Restoration Using A Knn-Variant of The Mean-Shift: Cesario Vincenzo Angelino, Eric Debreuve, Michel BarlaudBabiez_Popok_7016No ratings yet
- An Introduction To Fuzzy ControlDocument27 pagesAn Introduction To Fuzzy Controldali ramsNo ratings yet
- Discrete MathDocument25 pagesDiscrete MathKhairah A KarimNo ratings yet
- MT427 Notebook 4 Fall 2013/2014: Prepared by Professor Jenny BaglivoDocument27 pagesMT427 Notebook 4 Fall 2013/2014: Prepared by Professor Jenny BaglivoOmar Olvera GNo ratings yet
- CalculusDocument33 pagesCalculusnit_xlriNo ratings yet
- Discrete Random Variables and Probability DistributionsDocument23 pagesDiscrete Random Variables and Probability DistributionsSheikh MisbahNo ratings yet
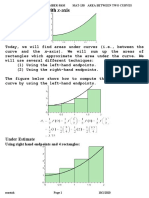
- MAT130.5 (MTM) Handout #8 - Area Between Two Curves, Spring 2020Document25 pagesMAT130.5 (MTM) Handout #8 - Area Between Two Curves, Spring 2020Tasnim Alam Piyash 1731712No ratings yet
- Optimization QFin Lecture NotesDocument33 pagesOptimization QFin Lecture NotesCarlos CadenaNo ratings yet
- Uniform DistDocument4 pagesUniform DistRasull SaimonNo ratings yet
- On Optimal and Data-Based Histograms: Department of Mathematical Sciences, Rice University, Houston, TexasDocument6 pagesOn Optimal and Data-Based Histograms: Department of Mathematical Sciences, Rice University, Houston, Texasoctavinavarro8236No ratings yet
- Random Variable Using MATLABDocument14 pagesRandom Variable Using MATLABomars_engNo ratings yet
- Functional AnalysisDocument93 pagesFunctional Analysisbala_muraliNo ratings yet
- Calc3 4 Vector CalculusDocument34 pagesCalc3 4 Vector CalculusSs SsNo ratings yet
- Univariate Density Estimation by Orthogonal Series: Department of Statistics, Oregon State University, CorvallisDocument8 pagesUnivariate Density Estimation by Orthogonal Series: Department of Statistics, Oregon State University, CorvallisJulio SternNo ratings yet
- A Tutorial on ν-Support Vector Machines: 1 An Introductory ExampleDocument29 pagesA Tutorial on ν-Support Vector Machines: 1 An Introductory Exampleaxeman113No ratings yet
- Topic 2 Part III PDFDocument30 pagesTopic 2 Part III PDFChris MastersNo ratings yet
- Statistical Models in SimulationDocument32 pagesStatistical Models in SimulationwoyesoNo ratings yet
- Report4 Density Estimation AllDocument63 pagesReport4 Density Estimation AllJohnNo ratings yet
- Adaptive Filtering For Medical Image Based On 3-Order Tensor FieldDocument4 pagesAdaptive Filtering For Medical Image Based On 3-Order Tensor FieldmiusayNo ratings yet
- Characteristic Functions in The Prob Package: G. Jay Kerns November 1, 2009Document13 pagesCharacteristic Functions in The Prob Package: G. Jay Kerns November 1, 2009raydonalNo ratings yet
- Lecture 2: Image Processing Review, Neighbors, Connected Components, and DistanceDocument7 pagesLecture 2: Image Processing Review, Neighbors, Connected Components, and DistanceWilliam MartinezNo ratings yet
- Lecture 4Document45 pagesLecture 4Joe OgleNo ratings yet
- CHP24 - VLSI HandbookDocument10 pagesCHP24 - VLSI Handbookfeki2607No ratings yet
- Nonparametric InferenceDocument16 pagesNonparametric Inferenceakshay patriNo ratings yet
- Aghori Mantra EngDocument7 pagesAghori Mantra Engakshay patriNo ratings yet
- MA Econometrics II: Midterm 2019: Instructor: Bipasha Maity Ashoka University Spring Semester 2019 March 13, 2019Document2 pagesMA Econometrics II: Midterm 2019: Instructor: Bipasha Maity Ashoka University Spring Semester 2019 March 13, 2019akshay patriNo ratings yet
- EconomicsDocument3 pagesEconomicsakshay patriNo ratings yet
- Dehasta-Devata-cakra StrotraDocument4 pagesDehasta-Devata-cakra Strotraakshay patri100% (1)
- Notes 2 Differentiated ProductsDocument25 pagesNotes 2 Differentiated Productsakshay patriNo ratings yet
- Trailokya Kali Mohana Kavacha UpadesahDocument7 pagesTrailokya Kali Mohana Kavacha Upadesahakshay patriNo ratings yet
- 108 Names English Ucchista Ganapati SanskritDocument5 pages108 Names English Ucchista Ganapati Sanskritakshay patriNo ratings yet
- The Pathless Path To Immortality: Dadaji & Shakti (C) Jan Bailey 1999Document8 pagesThe Pathless Path To Immortality: Dadaji & Shakti (C) Jan Bailey 1999akshay patriNo ratings yet
- Ucchista Ganapati SahasranamaDocument16 pagesUcchista Ganapati Sahasranamaakshay patriNo ratings yet
- Sri Kirata Varahi StotramDocument12 pagesSri Kirata Varahi Stotramakshay patriNo ratings yet
- Ucchista Ganapati SahasranamaDocument16 pagesUcchista Ganapati Sahasranamaakshay patriNo ratings yet
- Ucchista Ganapati AshtotramDocument22 pagesUcchista Ganapati Ashtotramakshay patriNo ratings yet
- CMPSOmit PDFDocument12 pagesCMPSOmit PDFakshay patriNo ratings yet
- YuyuuyyuDocument283 pagesYuyuuyyuakshay patriNo ratings yet
- S# Student NameDocument3 pagesS# Student Nameakshay patriNo ratings yet
- Homework 1 ProfDocument2 pagesHomework 1 Profakshay patriNo ratings yet
- Shuttle Schedule - Monday To Thursday: Jahangirpuri Campus Campus Jahangirpuri Departure Arrival Departure ArrivalDocument2 pagesShuttle Schedule - Monday To Thursday: Jahangirpuri Campus Campus Jahangirpuri Departure Arrival Departure Arrivalakshay patriNo ratings yet
- KTLTCNC EngDocument134 pagesKTLTCNC Enghoctoan343No ratings yet
- Estimation of Parameters of Lomax Distribution by Using Maximum Product Spacings MethodDocument9 pagesEstimation of Parameters of Lomax Distribution by Using Maximum Product Spacings MethodIJRASETPublicationsNo ratings yet
- B) Parameter, Parameter, StatisticDocument4 pagesB) Parameter, Parameter, Statisticapi-262707463No ratings yet
- ML MCQ 1Document5 pagesML MCQ 1Mks KhanNo ratings yet
- One Fourth Labs: Bias and VarianceDocument2 pagesOne Fourth Labs: Bias and VarianceashwinNo ratings yet
- Reporting Uncertainty of Test Results and Use of The Term Measurement Uncertainty in ASTM Test MethodsDocument7 pagesReporting Uncertainty of Test Results and Use of The Term Measurement Uncertainty in ASTM Test MethodsCJPATAGANNo ratings yet
- Maximum Likelihood EstimationDocument8 pagesMaximum Likelihood EstimationSORN CHHANNYNo ratings yet
- Unbiased Estimation of A Sparse Vector in White Gaussian NoiseDocument46 pagesUnbiased Estimation of A Sparse Vector in White Gaussian NoiseMohitRajputNo ratings yet
- StatLec1 5 PDFDocument23 pagesStatLec1 5 PDFKuangye ChenNo ratings yet
- Statistics Objective Questions Part 2Document34 pagesStatistics Objective Questions Part 2ASHUTOSH BISWALNo ratings yet
- Exercises Probability and Statistics: Bruno Tuffin Inria, FranceDocument33 pagesExercises Probability and Statistics: Bruno Tuffin Inria, FrancexandercageNo ratings yet
- Kernel Density EstimationDocument10 pagesKernel Density Estimationjuan camiloNo ratings yet
- The Simple Linear Regression Model: Specification and EstimationDocument66 pagesThe Simple Linear Regression Model: Specification and EstimationMuhammad Ali KhosoNo ratings yet
- BSC Statistics 01Document20 pagesBSC Statistics 01Akshay GoyalNo ratings yet
- Quantitative Mineral Resource Assessments - An Integrated Approach - Donald Singer, W. David MenzieDocument232 pagesQuantitative Mineral Resource Assessments - An Integrated Approach - Donald Singer, W. David MenzieparagjduttaNo ratings yet
- Estimators1 PDFDocument2 pagesEstimators1 PDFHiinoNo ratings yet
- Statistics: Department of Higher Education U.P. Government, LucknowDocument43 pagesStatistics: Department of Higher Education U.P. Government, LucknowTanu AdhikariNo ratings yet
- The Simple Regression ModelDocument61 pagesThe Simple Regression Model张敏然No ratings yet
- ST 1Document2 pagesST 1violist32No ratings yet
- GlossaryDocument31 pagesGlossaryzubairulhassanNo ratings yet
- Chapter 4 SamplingDocument18 pagesChapter 4 SamplingSaruul BoldhuuNo ratings yet
- T2.Statistics Review (Stock & Watson)Document15 pagesT2.Statistics Review (Stock & Watson)Abhishek GuptaNo ratings yet
- Lecture 5 Topic 4 Stat InferenceDocument16 pagesLecture 5 Topic 4 Stat Inferencelondindlovu410No ratings yet
- Fat Tails and (Anti) FragilityDocument101 pagesFat Tails and (Anti) Fragilityjibranqq100% (3)
- Hypothesis Testing - Exercises: 2021 / Ian Soon 1of4Document4 pagesHypothesis Testing - Exercises: 2021 / Ian Soon 1of4fairprice tissueNo ratings yet
- Kriging - Method and ApplicationDocument17 pagesKriging - Method and ApplicationanggitaNo ratings yet
- Apics Cpim Pt+1 Mod+1 SeceDocument33 pagesApics Cpim Pt+1 Mod+1 SeceMohamed HaniNo ratings yet