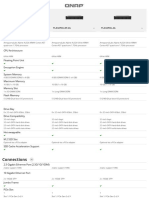
Download as xls, pdf, or txt
You might also like
- DIALux Evo ManualDocument92 pagesDIALux Evo ManualIngenieroSinTitulo100% (1)
- Cheat SheetDocument1 pageCheat SheetJan AertsNo ratings yet
- CUDA Occupancy CalculatorDocument44 pagesCUDA Occupancy CalculatorLaury SofyNo ratings yet
- B Odyssey XproDocument10 pagesB Odyssey Xprocharles.cnNo ratings yet
- The Brain Behind The ComputingDocument4 pagesThe Brain Behind The ComputingkarmaNo ratings yet
- CUDA Occupancy CalculatorDocument26 pagesCUDA Occupancy CalculatorMarko MileticNo ratings yet
- Memory 4GB Memory 4GB: Memory Used in A ZoneDocument2 pagesMemory 4GB Memory 4GB: Memory Used in A ZoneSladur BgNo ratings yet
- Solving High-Speed Memory Interface Challenges With Low-Cost FpgasDocument10 pagesSolving High-Speed Memory Interface Challenges With Low-Cost Fpgaslhari_04No ratings yet
- ECE448 Lecture19 MemoryDocument54 pagesECE448 Lecture19 MemoryNaimish BabariyaNo ratings yet
- Lec3 - Cache and Memory SystemDocument18 pagesLec3 - Cache and Memory SystemVăn Nam NgôNo ratings yet
- Controller Scalability MatrixDocument5 pagesController Scalability MatrixDaniel ManguiaNo ratings yet
- DC 22630 0256 H00a 010CB BBBBDocument3 pagesDC 22630 0256 H00a 010CB BBBBLe Van ThanhNo ratings yet
- Index: Power Quotient International Co., LTDDocument73 pagesIndex: Power Quotient International Co., LTDSsr ShaNo ratings yet
- Features Pin Assignment: DS2432 1k-Bit Protected 1-Wire EEPROM With SHA-1 EngineDocument31 pagesFeatures Pin Assignment: DS2432 1k-Bit Protected 1-Wire EEPROM With SHA-1 EngineFariasNo ratings yet
- Infineon-S25FL512S 512 MB (64 MB) 3.0 V SPI Flash Memory-DataSheet-v20 00-ENDocument161 pagesInfineon-S25FL512S 512 MB (64 MB) 3.0 V SPI Flash Memory-DataSheet-v20 00-ENSomeoneNo ratings yet
- EEE 342 Interfacing With 8086Document33 pagesEEE 342 Interfacing With 8086poetanonymous11No ratings yet
- Memory Hierarchy - Ways To Reduce Misses: DAP Spr. 98 ©UCB 1Document23 pagesMemory Hierarchy - Ways To Reduce Misses: DAP Spr. 98 ©UCB 1karthika sudheerNo ratings yet
- Qorivva MPC5500 Minimum Board Requirements: Application NoteDocument49 pagesQorivva MPC5500 Minimum Board Requirements: Application NotefengheNo ratings yet
- HP 3par Support Matrix HP 3par Storeserv 7000/7000C and 10000 HP 3par Os 3.2.1Document9 pagesHP 3par Support Matrix HP 3par Storeserv 7000/7000C and 10000 HP 3par Os 3.2.1Hamed TakafouyanNo ratings yet
- WoW64 Bypassing EMET PDFDocument19 pagesWoW64 Bypassing EMET PDFSatria Ady PradanaNo ratings yet
- MSP430™ FRAMTechnology - HowTo and BestPracticesDocument21 pagesMSP430™ FRAMTechnology - HowTo and BestPractices呂柏勳No ratings yet
- Capacity Number of DRAM Devices: CK RC RFC RASDocument4 pagesCapacity Number of DRAM Devices: CK RC RFC RASRonaldNo ratings yet
- 04 CUDA Fundamental OptimizationDocument30 pages04 CUDA Fundamental OptimizationNagaraj SNo ratings yet
- CUDA Memories: GPU Teaching KitDocument36 pagesCUDA Memories: GPU Teaching KitAndy OrtizNo ratings yet
- Cuda Webinars WarpsAndOccupancyDocument14 pagesCuda Webinars WarpsAndOccupancyprameetskNo ratings yet
- Roland Fantom x6Document66 pagesRoland Fantom x6Blair Alward100% (1)
- mx204 DatasheetDocument3 pagesmx204 Datasheeterfan farhannanda2No ratings yet
- 2014 Movicon11 Price List-English-V3Document12 pages2014 Movicon11 Price List-English-V3thamer al-salekNo ratings yet
- Microprocessor CoursePDFDocument31 pagesMicroprocessor CoursePDFahmadzaatariNo ratings yet
- CSC437 Fall2013 Module 5 Buffer Overflow AttacksDocument42 pagesCSC437 Fall2013 Module 5 Buffer Overflow AttacksCarlos E. Velez ArizaNo ratings yet
- 04 Computer Speeds and UnitsDocument13 pages04 Computer Speeds and UnitsHammami SalahNo ratings yet
- Night Fall: Meteor Storm: Tribhuvan University Institute ofDocument8 pagesNight Fall: Meteor Storm: Tribhuvan University Institute ofkisan bistaNo ratings yet
- TS-832PX, TS-832PXU-RP, TS-832PXU Compare Products - QNAPDocument12 pagesTS-832PX, TS-832PXU-RP, TS-832PXU Compare Products - QNAPAkram M. AlmotaaNo ratings yet
- CH05 COA11eDocument43 pagesCH05 COA11ethamltkse183267No ratings yet
- 03 MemoryAddressing ArchitectureTypesDocument9 pages03 MemoryAddressing ArchitectureTypesAhana SahaNo ratings yet
- Báo Giá Server Ibm Tháng 7/2010: Model System x3200 M2 System x3200 M3Document8 pagesBáo Giá Server Ibm Tháng 7/2010: Model System x3200 M2 System x3200 M3tuyensandy1983No ratings yet
- S34ML01G1-Cypress - Semelhante Ao FMND2GO8U3DDocument73 pagesS34ML01G1-Cypress - Semelhante Ao FMND2GO8U3DGuilherme Ribeiro BarbosaNo ratings yet
- Document 233Document11 pagesDocument 233caje_mac6960No ratings yet
- 9600XT 3dmark2005Document29 pages9600XT 3dmark2005eujanroNo ratings yet
- Micron Serial NOR Flash Memory: 3V, Multiple I/O, 4KB Sector Erase N25Q256A FeaturesDocument92 pagesMicron Serial NOR Flash Memory: 3V, Multiple I/O, 4KB Sector Erase N25Q256A FeaturesAENo ratings yet
- Linux On Power/Cell BE Architecture Buffer Overflow VulnerabilitiesDocument57 pagesLinux On Power/Cell BE Architecture Buffer Overflow VulnerabilitiesWedd BukhariNo ratings yet
- Competitive Power Sales Advisor: IBM Power S824 Vs Oracle T5-2Document2 pagesCompetitive Power Sales Advisor: IBM Power S824 Vs Oracle T5-2omarxxokNo ratings yet
- ARM Cortex-A9 MPCoreDocument34 pagesARM Cortex-A9 MPCoreAnoop KumarNo ratings yet
- Memory Segmentation: by Nikhil Kumar Nirt BhopalDocument11 pagesMemory Segmentation: by Nikhil Kumar Nirt BhopalAnindra NallapatiNo ratings yet
- DDA9C16 32 64x72AGDocument27 pagesDDA9C16 32 64x72AGAnonymous oyUAtpKNo ratings yet
- M24256-BW M24256-BR M24256-BF M24256-DR M24256-DF: 256-Kbit Serial I C Bus EEPROMDocument39 pagesM24256-BW M24256-BR M24256-BF M24256-DR M24256-DF: 256-Kbit Serial I C Bus EEPROMJef EspinoNo ratings yet
- UMTS Call Capacity Calculator: by Carames Miguel & Koessler Bernhard (Updated For Sectors/carriers, 23nov04, Jon Kromer)Document12 pagesUMTS Call Capacity Calculator: by Carames Miguel & Koessler Bernhard (Updated For Sectors/carriers, 23nov04, Jon Kromer)Anonymous g8YR8b9No ratings yet
- Controller SpecificationsDocument8 pagesController SpecificationsXuân QuỳnhNo ratings yet
- ch01 IntroductionDocument29 pagesch01 IntroductionHASHIR KHANNo ratings yet
- HCS12 Controller-1Document6 pagesHCS12 Controller-1HaxfNo ratings yet
- MD5F1GQ4UAYIGDocument32 pagesMD5F1GQ4UAYIGmirage0706No ratings yet
- GDC2014 Code ClinicDocument148 pagesGDC2014 Code ClinicBibek KunduNo ratings yet
- CS252 Graduate Computer Architecture Caches and Memory Systems IDocument49 pagesCS252 Graduate Computer Architecture Caches and Memory Systems Ijamal4uNo ratings yet
- 05 Lec Memory - ArchitecturesDocument40 pages05 Lec Memory - Architecturesmujtabaiftikhar156No ratings yet
- Ultrascale Fpga Product Selection Guide PDFDocument12 pagesUltrascale Fpga Product Selection Guide PDFAfortunatovNo ratings yet
- Dell Midrange SizerDocument4 pagesDell Midrange SizerBobNo ratings yet
- 4Bcs504: Microprocessors: Module-I: IntroductionDocument60 pages4Bcs504: Microprocessors: Module-I: IntroductionDr. Parameswaran TNo ratings yet
- ST72324Bxx: 8-Bit MCU, 3.8 To 5.5 V Operating Range With 8 To 32 Kbyte Flash/ROM, 10-Bit ADC, 4 Timers, SPI, SCIDocument188 pagesST72324Bxx: 8-Bit MCU, 3.8 To 5.5 V Operating Range With 8 To 32 Kbyte Flash/ROM, 10-Bit ADC, 4 Timers, SPI, SCIgustavoNo ratings yet
- Stm32f446ret6 PDFDocument202 pagesStm32f446ret6 PDFNguyen Trong NghiaNo ratings yet
- COA Assignment 2Document2 pagesCOA Assignment 2satwikshukla2004No ratings yet
- Oracle Systems Portfolio FY19Document27 pagesOracle Systems Portfolio FY19Rochdi BouzaienNo ratings yet
- Dismantle Checklist: NO. Item Code Item Description Quantity Remarks 1 Core ItemDocument2 pagesDismantle Checklist: NO. Item Code Item Description Quantity Remarks 1 Core ItemMahbub UzzamanNo ratings yet
- Rawlbolt: Shield Anchor Loose BoltDocument2 pagesRawlbolt: Shield Anchor Loose BoltBappy IslamNo ratings yet
- Badger Range Guard Wet Chemical Cylinder Assemblies: FeaturesDocument4 pagesBadger Range Guard Wet Chemical Cylinder Assemblies: FeaturesLee WenjianNo ratings yet
- SM VRF SystemsDocument332 pagesSM VRF SystemsNatalia Beglet100% (1)
- Serial and Ethernet Connection Protocols: Ac500 Eco PLCDocument8 pagesSerial and Ethernet Connection Protocols: Ac500 Eco PLCHitesh PanigrahiNo ratings yet
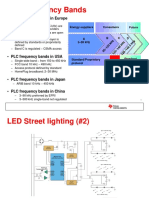
- PLC Frequency Bands in EuropeDocument6 pagesPLC Frequency Bands in EuropeartovolastiNo ratings yet
- 4WCF Installation Manual EnUS 85392978955Document56 pages4WCF Installation Manual EnUS 85392978955Ahmed YousryNo ratings yet
- 2 1Document21 pages2 1المهندسوليدالطويلNo ratings yet
- First Pass Master Tag PDFDocument14 pagesFirst Pass Master Tag PDFmusarraf172No ratings yet
- Huawei UA5000 Series Access Network, View Huawei UA5000, Huawei Product Details From Shanghai Chu Cheng Information Technology Co., Ltd. On AlibabaDocument4 pagesHuawei UA5000 Series Access Network, View Huawei UA5000, Huawei Product Details From Shanghai Chu Cheng Information Technology Co., Ltd. On AlibabaR.s. Félix100% (1)
- Find Files Faster - How To Organize Files and FoldersDocument21 pagesFind Files Faster - How To Organize Files and FoldersShahrir100% (1)
- 2. სუსტი დენების განმარტებითი ბარათი PDFDocument3 pages2. სუსტი დენების განმარტებითი ბარათი PDFLevan MetreveliNo ratings yet
- Pvh131 141 Variable Disp Piston Pump 11 Design PLL - 1444Document9 pagesPvh131 141 Variable Disp Piston Pump 11 Design PLL - 1444Agus Yulfizar100% (1)
- Quick Coupling Festo WTH SafetyDocument24 pagesQuick Coupling Festo WTH SafetyFaisal RifkiansyahNo ratings yet
- Introduction To Java Applet Programming: Chapter ObjectivesDocument6 pagesIntroduction To Java Applet Programming: Chapter ObjectivesKaushal PandeyNo ratings yet
- Difference Between Cache Memory and RegisterDocument2 pagesDifference Between Cache Memory and RegisterKhaled HossainNo ratings yet
- Dynamic Stress Analysis of A Bus SystemsDocument10 pagesDynamic Stress Analysis of A Bus SystemstomekzawistowskiNo ratings yet
- Exsite Series Explosionproof Power Module: InstallationDocument16 pagesExsite Series Explosionproof Power Module: InstallationMohammed ElsayedNo ratings yet
- E1 ManagerDocument23 pagesE1 ManagershahidbaghNo ratings yet
- Master Thesis - Observer Based Fault Detection in DC-DC Power Converter - Levin - KieranDocument97 pagesMaster Thesis - Observer Based Fault Detection in DC-DC Power Converter - Levin - KieranhieuhuechNo ratings yet
- Servo Magazine 2010-12 Building The Arduino Bof PDFDocument72 pagesServo Magazine 2010-12 Building The Arduino Bof PDFMichael LeydarNo ratings yet
- ThinkPad T460 Platform SpecificationsDocument1 pageThinkPad T460 Platform SpecificationswirabelskiaNo ratings yet
- INTEGRATION, The VLSI Journal: Arkadiy Morgenshtein, Viacheslav Yuzhaninov, Alexey Kovshilovsky, Alexander FishDocument9 pagesINTEGRATION, The VLSI Journal: Arkadiy Morgenshtein, Viacheslav Yuzhaninov, Alexey Kovshilovsky, Alexander FishPooja VermaNo ratings yet
- hw2s MfokDocument2 pageshw2s MfokKhalid TeslaNo ratings yet
- Delphi Telematics BrochureDocument6 pagesDelphi Telematics BrochureIván Blanco FernándezNo ratings yet
- FPT University OSG202Document8 pagesFPT University OSG202thinh nguyenNo ratings yet
- 10G GPON FTTH Solution PosterDocument1 page10G GPON FTTH Solution PosterSergiu SergiuNo ratings yet
- Installation Instructions: CD200D Digital Ignition System Form CD200D II 4-17Document32 pagesInstallation Instructions: CD200D Digital Ignition System Form CD200D II 4-17RICARDO MAMANI GARCIANo ratings yet