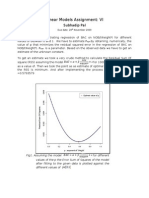
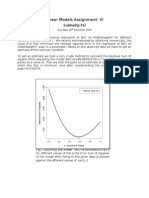
Download as pdf or txt
You might also like
- Stats216 hw3 PDFDocument26 pagesStats216 hw3 PDFAlex NutkiewiczNo ratings yet
- Homework 4Document3 pagesHomework 4João Paulo MilaneziNo ratings yet
- 1 Analytical Part (3 Percent Grade) : + + + 1 N I: y +1 I 1 N I: y 1 IDocument5 pages1 Analytical Part (3 Percent Grade) : + + + 1 N I: y +1 I 1 N I: y 1 IMuhammad Hur RizviNo ratings yet
- Solutions To Chapter 10 ProblemsDocument40 pagesSolutions To Chapter 10 ProblemsCarlos Alfredo H ChNo ratings yet
- Brown and Saunders Chapter 1 Dealing With StatisticsDocument10 pagesBrown and Saunders Chapter 1 Dealing With StatisticsBach Achacoso100% (1)
- Activity 7Document5 pagesActivity 7Sam Sat PatNo ratings yet
- Model SelectionDocument11 pagesModel Selection徐天辰No ratings yet
- Linear Models Assignment: VIDocument7 pagesLinear Models Assignment: VIsubhadippalNo ratings yet
- Programming With R Test 2Document5 pagesProgramming With R Test 2KamranKhan50% (2)
- COL 774: Assignment 2Document3 pagesCOL 774: Assignment 2Aditya KumarNo ratings yet
- MDS 503 2nd Exam - R - Stat - OBDocument3 pagesMDS 503 2nd Exam - R - Stat - OBTesta MestaNo ratings yet
- M.sc. (IT) - Part I Practical ListDocument16 pagesM.sc. (IT) - Part I Practical ListNitu MukundanNo ratings yet
- Ell784 17 AqDocument8 pagesEll784 17 Aqlovlesh royNo ratings yet
- Ell409 AqDocument8 pagesEll409 Aqlovlesh royNo ratings yet
- 18CSO106T Data Analysis Using Open Source Tool: Question BankDocument26 pages18CSO106T Data Analysis Using Open Source Tool: Question BankShivaditya singhNo ratings yet
- Ell784 AqDocument2 pagesEll784 Aqlovlesh royNo ratings yet
- Stat 401B Exam 1 F16-KeyDocument7 pagesStat 401B Exam 1 F16-KeyjuanEs2374pNo ratings yet
- Additional Exercises: C 2005 A. Colin Cameron and Pravin K. Trivedi "Microeconometrics: Methods and Applications"Document5 pagesAdditional Exercises: C 2005 A. Colin Cameron and Pravin K. Trivedi "Microeconometrics: Methods and Applications"Vincenzo AndriettiNo ratings yet
- Data Science - Part II (Cra 4061)Document2 pagesData Science - Part II (Cra 4061)Sarvagya RanjanNo ratings yet
- Question 1 (Linear Regression)Document18 pagesQuestion 1 (Linear Regression)Salton GerardNo ratings yet
- MAS-I Sample QuestionsDocument8 pagesMAS-I Sample QuestionsLau MerchanNo ratings yet
- IML-IITKGP_Assignment 5 SolutionDocument7 pagesIML-IITKGP_Assignment 5 SolutionxplorvarmaNo ratings yet
- Midterm Exam SolutionDocument11 pagesMidterm Exam SolutionShelaRamosNo ratings yet
- 2019 - Introduction To Data Analytics Using RDocument5 pages2019 - Introduction To Data Analytics Using RYeickson Mendoza MartinezNo ratings yet
- MCL 735 - Lab Assignment 4: RD TH THDocument1 pageMCL 735 - Lab Assignment 4: RD TH THRajkishore RajasekarNo ratings yet
- Exercise Sheet 5Document2 pagesExercise Sheet 5SwikNo ratings yet
- Week 5Document9 pagesWeek 5sachinNo ratings yet
- Homework/Assignment: (Chapter 9: Input Modelling)Document11 pagesHomework/Assignment: (Chapter 9: Input Modelling)Lam Vũ HoàngNo ratings yet
- Non LinearityDocument15 pagesNon Linearity徐天辰No ratings yet
- Assignment 1 Measurements and Unceratinities (Answers)Document4 pagesAssignment 1 Measurements and Unceratinities (Answers)panghua tanNo ratings yet
- Linear Models Assignment: VI: Subhadip PalDocument6 pagesLinear Models Assignment: VI: Subhadip PalsubhadippalNo ratings yet
- Advanced - Linear RegressionDocument57 pagesAdvanced - Linear RegressionArjun KhoslaNo ratings yet
- Gujarat Technological UniversityDocument2 pagesGujarat Technological UniversitySejal YadavNo ratings yet
- Final 2002Document18 pagesFinal 2002Muhammad MurtazaNo ratings yet
- MIT18 05S14 ps9 PDFDocument3 pagesMIT18 05S14 ps9 PDFMd CassimNo ratings yet
- SVM in R (David Meyer)Document8 pagesSVM in R (David Meyer)alexa_sherpyNo ratings yet
- Week10 KNN PracticalDocument4 pagesWeek10 KNN Practicalseerungen jordiNo ratings yet
- Assignment 3 (Sol.) : Introduction To Machine Learning Prof. B. RavindranDocument8 pagesAssignment 3 (Sol.) : Introduction To Machine Learning Prof. B. RavindranThrilling MeherabNo ratings yet
- CP Ec02 2020-21Document3 pagesCP Ec02 2020-21202118bt064No ratings yet
- Model-Based Clustering: o K o KDocument6 pagesModel-Based Clustering: o K o KyellowNo ratings yet
- DS3 Lab7Document3 pagesDS3 Lab7ShikharNo ratings yet
- cs230exam_spr21Document16 pagescs230exam_spr21toluei.s29No ratings yet
- 18MAT7531Document5 pages18MAT7531murageshadahalli8No ratings yet
- Lfakjo 30 Uf 2 Ofu 092 JieowDocument6 pagesLfakjo 30 Uf 2 Ofu 092 Jieowjoseph.zhao.zhao.zhaoNo ratings yet
- OS HW10 IrakliDiasamidzeDocument5 pagesOS HW10 IrakliDiasamidzemisho ujeraNo ratings yet
- IGNOU MCS-011 Previous Years QuestionsDocument64 pagesIGNOU MCS-011 Previous Years QuestionssanjubalumailNo ratings yet
- Mission 154 Cross Validation TakeawaysDocument3 pagesMission 154 Cross Validation TakeawaysRajachandra VoodigaNo ratings yet
- 1 RegressionDocument4 pages1 RegressionAgustin AgustinNo ratings yet
- Assignment 4: Introduction To Machine Learning Prof. B. RavindranDocument2 pagesAssignment 4: Introduction To Machine Learning Prof. B. RavindranVijayramasamyNo ratings yet
- SVM Assignment ABA Course To Be Returned With Your AnswersDocument10 pagesSVM Assignment ABA Course To Be Returned With Your AnswersNabeel MohammadNo ratings yet
- CIS 520, Machine Learning, Fall 2015: Assignment 2 Due: Friday, September 18th, 11:59pm (Via Turnin)Document3 pagesCIS 520, Machine Learning, Fall 2015: Assignment 2 Due: Friday, September 18th, 11:59pm (Via Turnin)DiDo Mohammed AbdullaNo ratings yet
- Cs230exam spr21 SolnDocument21 pagesCs230exam spr21 SolnMOHAMMADNo ratings yet
- Quiz1 Solutions Quiz 1 SolnDocument7 pagesQuiz1 Solutions Quiz 1 Solnhasna.nafirNo ratings yet
- 5.2 Miscellaneous TopicsDocument4 pages5.2 Miscellaneous TopicsRajaNo ratings yet
- Quiz3 With SolutionsDocument6 pagesQuiz3 With SolutionsPityshNo ratings yet
- Efficient Net B0Document4 pagesEfficient Net B0NavyaNo ratings yet
- ML MCQ 1Document5 pagesML MCQ 1Mks KhanNo ratings yet
- Lecture Slides-Week9,10Document66 pagesLecture Slides-Week9,10moazzam kianiNo ratings yet
- Wa0006.Document4 pagesWa0006.geeta sreeNo ratings yet
- Stat 371 Ass#1Document2 pagesStat 371 Ass#1live2smile89No ratings yet
- Wiley Royal Statistical SocietyDocument5 pagesWiley Royal Statistical SocietyCristian Rodrigo Ubal NúñezNo ratings yet
- Chapter 3Document36 pagesChapter 3asdasdasd122No ratings yet
- Operating DensityDocument8 pagesOperating DensityEnriqueGDNo ratings yet
- Accurate Forecasting Determines Inventory Levels in The Supply Chain - Continuous ReplenishmentDocument54 pagesAccurate Forecasting Determines Inventory Levels in The Supply Chain - Continuous ReplenishmentHimawan TanNo ratings yet
- Predicting Diamond Price: 2 Step MethodDocument17 pagesPredicting Diamond Price: 2 Step MethodSarajit Poddar100% (1)
- Whey Protein Nitrogen Index A21aDocument6 pagesWhey Protein Nitrogen Index A21aDinesh Kumar BansalNo ratings yet
- TQM - Statistical Process ControlDocument93 pagesTQM - Statistical Process ControlAjitNo ratings yet
- Colina Math Weeks 11 12Document16 pagesColina Math Weeks 11 12Lucius MoonstarNo ratings yet
- ASTMC403 Setting TimeDocument7 pagesASTMC403 Setting TimeGabriel Lim100% (2)
- 2.1 Cows ..2 2.2 Pits .4 2.3 Chaos .5Document23 pages2.1 Cows ..2 2.2 Pits .4 2.3 Chaos .5AntonNo ratings yet
- Unit 5 Exploratory Data Analysis (EDA)Document41 pagesUnit 5 Exploratory Data Analysis (EDA)Shamie Singh100% (1)
- Assessment of Coastal Erosion Vulnerability Around Midnapur-Balasore Coast, Eastern India Using Integrated Remote Sensing and GIS TechniquesDocument12 pagesAssessment of Coastal Erosion Vulnerability Around Midnapur-Balasore Coast, Eastern India Using Integrated Remote Sensing and GIS TechniqueskowsilaxNo ratings yet
- Journal of Hydrology: Jamaludin Suhaila, Abdul Aziz Jemain, Muhammad Fauzee Hamdan, Wan Zawiah Wan ZinDocument10 pagesJournal of Hydrology: Jamaludin Suhaila, Abdul Aziz Jemain, Muhammad Fauzee Hamdan, Wan Zawiah Wan ZinBeatriz Cobo RodriguezNo ratings yet
- ANN in Labour ProductivityDocument12 pagesANN in Labour ProductivityEmmanuel okelloNo ratings yet
- Scheduled Overtime and Labor Productivity - Quantitative AnalysisDocument15 pagesScheduled Overtime and Labor Productivity - Quantitative AnalysisKhaled AbdelbakiNo ratings yet
- UntitledDocument2 pagesUntitledDawn LightNo ratings yet
- Goodness of Fit Negative Binomial Regression StataDocument3 pagesGoodness of Fit Negative Binomial Regression StataKarenNo ratings yet
- MV600 ReginDocument3 pagesMV600 ReginBudi PrayitnoNo ratings yet
- Stats Data and Models Canadian 1st Edition de Veaux Test BankDocument47 pagesStats Data and Models Canadian 1st Edition de Veaux Test Bankbarbarariddledsporabefn100% (13)
- Shrinkage and Atterberg Limits in Relation To Other Properties of Principal Soil Types in IsraelDocument19 pagesShrinkage and Atterberg Limits in Relation To Other Properties of Principal Soil Types in Israelbkollarou9632No ratings yet
- Research Paper Using Multiple Regression AnalysisDocument8 pagesResearch Paper Using Multiple Regression Analysisegzfj0nwNo ratings yet
- An Analysis of Attributes Affecting Urban Open Space Design and Their Environmental ImplicationsDocument11 pagesAn Analysis of Attributes Affecting Urban Open Space Design and Their Environmental Implicationsbru.ferNo ratings yet
- PercentagesDocument92 pagesPercentagesSolisterADVNo ratings yet
- R Rec P.838 2 200304 S!!PDF eDocument5 pagesR Rec P.838 2 200304 S!!PDF eNhư Nhí NhốNo ratings yet
- Demand ForecastingDocument14 pagesDemand ForecastingsanthoshNo ratings yet
- Census of India 1911, BaluchistanDocument333 pagesCensus of India 1911, BaluchistanSheikh Masood Zaman Mandokhail100% (3)
- AML AfterMid MergedDocument389 pagesAML AfterMid Mergedshruti katareNo ratings yet