
Business Analytics and Operations Research
Business Analytics and Operations Research
You might also like
- National Council For Interior Design Qualification (NCIDQ) Exam Study GuideDocument20 pagesNational Council For Interior Design Qualification (NCIDQ) Exam Study GuideMcRee Learning Center100% (1)
- Exam in Statistics #2 - BusinessDocument2 pagesExam in Statistics #2 - BusinessOverland-X Philippines100% (1)
- Action Research ProposalDocument3 pagesAction Research ProposalAiv Ylanan89% (9)
- Apollo Personality Test Training CourseDocument2 pagesApollo Personality Test Training CourseMegan RamsayNo ratings yet
- A-008550-1624688646968-80386-Unit 34 - System Analysis and Design.Document103 pagesA-008550-1624688646968-80386-Unit 34 - System Analysis and Design.Hansi Ranasinghe100% (1)
- AI For Analytics: Written By: Brooke LynchDocument12 pagesAI For Analytics: Written By: Brooke LynchPera PericNo ratings yet
- The Awareness Level of Senior High School Student in Applying Occupational Health and Safety ProcedureDocument20 pagesThe Awareness Level of Senior High School Student in Applying Occupational Health and Safety ProcedureWilliam GarciaNo ratings yet
- Philippine Guidelines On Periodic Health Examination (PHEx) PDFDocument25 pagesPhilippine Guidelines On Periodic Health Examination (PHEx) PDFLinius CruzNo ratings yet
- Ug Special TermDocument40 pagesUg Special TermRegina SamsonNo ratings yet
- Vision MandateDocument7 pagesVision MandateJade Sanico BaculantaNo ratings yet
- Alfa Beta DailybkuplDocument1,369 pagesAlfa Beta DailybkuplCardoso PenhaNo ratings yet
- Weighted Preferences in Evolutionary Multi-Objective OptimizationDocument10 pagesWeighted Preferences in Evolutionary Multi-Objective Optimizationmehmetkartal19No ratings yet
- CitiGroup On TrendFollowingDocument49 pagesCitiGroup On TrendFollowingGabNo ratings yet
- Lecture 7 - 2023 (1-55, 66-68)Document69 pagesLecture 7 - 2023 (1-55, 66-68)saad ansariNo ratings yet
- Bond Yields and Prices: Reference: Chapter 17Document30 pagesBond Yields and Prices: Reference: Chapter 17RosaNo ratings yet
- 01.1 Plan Lineal Canal, Cesar MarzoDocument3 pages01.1 Plan Lineal Canal, Cesar MarzoAlejandro MarquezNo ratings yet
- Sparse Linear RegressionDocument45 pagesSparse Linear Regressiongifom43181No ratings yet
- Assess For Credit RatingDocument12 pagesAssess For Credit RatingbagirNo ratings yet
- New Wave Capital Management FundDocument5 pagesNew Wave Capital Management FundAleksandar DendaNo ratings yet
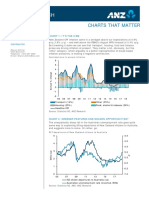
- Charts That Matter - 19 October 2018Document5 pagesCharts That Matter - 19 October 2018JustinC.PaoliniNo ratings yet
- P03 HeteroskedastikDocument27 pagesP03 Heteroskedastikdilafara152No ratings yet
- This Work Is Licensed Under The Creative Commons Attribution-Noncommercial 3.0 Singapore LicenseDocument24 pagesThis Work Is Licensed Under The Creative Commons Attribution-Noncommercial 3.0 Singapore LicenseFrancesco ZucchettoNo ratings yet
- PNRA Panera Bread 2016 Annual Shareholder PresentationDocument46 pagesPNRA Panera Bread 2016 Annual Shareholder PresentationAla BasterNo ratings yet
- Performance Analysis of R. N. Spinning Mills Limited.Document10 pagesPerformance Analysis of R. N. Spinning Mills Limited.Axis StyleNo ratings yet
- Lect7 Math231Document29 pagesLect7 Math231Qasim RafiNo ratings yet
- Intermediate Financial Management 12th Edition Brigham Solutions Manual DownloadDocument46 pagesIntermediate Financial Management 12th Edition Brigham Solutions Manual DownloadPreston Warfield100% (30)
- k2 Attachments CT Lecture 14. Multiple Linear RegressionDocument37 pagesk2 Attachments CT Lecture 14. Multiple Linear Regressionnguyendung0917No ratings yet
- 50 AAPL Buyside PitchbookDocument22 pages50 AAPL Buyside PitchbookAkshay ShaikhNo ratings yet
- Fundamentals of Intelligent Theses: Lecture 5: Quality Figures Chemeng 690ADocument33 pagesFundamentals of Intelligent Theses: Lecture 5: Quality Figures Chemeng 690AWes violaNo ratings yet
- 1Q2020 Fullbook enDocument53 pages1Q2020 Fullbook enVincentNo ratings yet
- Transpek Industry LTDDocument6 pagesTranspek Industry LTDabhishekbasumallick100% (1)
- A General Approach To Sensitivity AnalysisDocument37 pagesA General Approach To Sensitivity AnalysisjimmymorelosNo ratings yet
- 50 AAPL Buyside PitchbookDocument22 pages50 AAPL Buyside PitchbookkamranNo ratings yet
- Soil ParameterDocument3 pagesSoil Parameterhessian123No ratings yet
- CH 04Document24 pagesCH 04PriyankaNo ratings yet
- Luiz Reliability ProjectDocument14 pagesLuiz Reliability ProjectMiro GrulovicNo ratings yet
- Current Ratio:: Current Assets Current LiabilitiesDocument5 pagesCurrent Ratio:: Current Assets Current LiabilitiesshamarjitNo ratings yet
- Number. Level 4. Equivalence. Fractions Decimals Percentages (A)Document1 pageNumber. Level 4. Equivalence. Fractions Decimals Percentages (A)Steve HatolNo ratings yet
- IEQ Oct 2017 PresentationDocument32 pagesIEQ Oct 2017 PresentationnotagoodpasswordoliverNo ratings yet
- The Under and Overestimation of RiskDocument18 pagesThe Under and Overestimation of RiskHhp YmNo ratings yet
- LNG Spot Prices and Long-Term Contracts: Peter R HartleyDocument41 pagesLNG Spot Prices and Long-Term Contracts: Peter R HartleyAhmad NawwarNo ratings yet
- Business Inventories Fell 0.7 Percent in NovemberDocument1 pageBusiness Inventories Fell 0.7 Percent in NovemberInternational Business TimesNo ratings yet
- SDE KultamDocument33 pagesSDE Kultamindira maharaniNo ratings yet
- Case Study: Masa: Hasil AnalisisDocument35 pagesCase Study: Masa: Hasil AnalisisAtikah DarayaniNo ratings yet
- ZOES WB Presentation June17 (1) 2017Document29 pagesZOES WB Presentation June17 (1) 2017Ala BasterNo ratings yet
- The Largest Automobile Scandal in The History !Document21 pagesThe Largest Automobile Scandal in The History !rohitNo ratings yet
- 2020 - 05 Barbon and Buraschi 2020 - Gamma FragilityDocument60 pages2020 - 05 Barbon and Buraschi 2020 - Gamma Fragilitynexxus hcNo ratings yet
- HW3 Managerial FinanceDocument13 pagesHW3 Managerial FinanceAndrew HawkinsNo ratings yet
- Assignements in Corporate FinanceDocument1 pageAssignements in Corporate FinanceshehurinaNo ratings yet
- Expro RBI Expert Group HandbookDocument26 pagesExpro RBI Expert Group HandbookJavier RivasNo ratings yet
- AQR Alternative Thinking Q1 2021 Capital Market Assumptions For Major Asset ClassessDocument16 pagesAQR Alternative Thinking Q1 2021 Capital Market Assumptions For Major Asset ClassessindiaNo ratings yet
- Lbo ModelDocument4 pagesLbo Modelharshalp1212No ratings yet
- An Economist's Guide To Visualizing Data: Jonathan A. SchwabishDocument28 pagesAn Economist's Guide To Visualizing Data: Jonathan A. SchwabishResuf AhmedNo ratings yet
- Lecture 15 - 2024Document40 pagesLecture 15 - 2024Marwan MikdadiNo ratings yet
- Risk and Return Chapter 5Document55 pagesRisk and Return Chapter 5sundas younasNo ratings yet
- A11 IndustryInputs Module4Document5 pagesA11 IndustryInputs Module4Ranga SenthilNo ratings yet
- Continuation To StocksDocument53 pagesContinuation To StocksTahaNo ratings yet
- Assessment of Assumptions in SLR:: There Is A Real Linear Relationship Between The Mean Response andDocument6 pagesAssessment of Assumptions in SLR:: There Is A Real Linear Relationship Between The Mean Response andKhushbakht BalochNo ratings yet
- Beverage Trends AnalysisDocument49 pagesBeverage Trends AnalysisCarlosNo ratings yet
- 2018 Roche RD ReportDocument27 pages2018 Roche RD ReportsyedNo ratings yet
- Dividend Practices of Islamic Banks in Bangladesh (Shariah Compliances) by Hasan Asif SouravDocument21 pagesDividend Practices of Islamic Banks in Bangladesh (Shariah Compliances) by Hasan Asif SouravHasan Asif SouravNo ratings yet
- Chapter 5Document82 pagesChapter 5MUHAMMAD IMRAN HAKIM BIN SULAIMAN STUDENTNo ratings yet
- Chuchu's AssignmentDocument26 pagesChuchu's AssignmentamirNo ratings yet
- Chapter 24. Tool Kit For Portfolio Theory, Asset Pricing Models, and Behavioral FinanceDocument22 pagesChapter 24. Tool Kit For Portfolio Theory, Asset Pricing Models, and Behavioral Financetreeken2No ratings yet
- Frenchay Dysarthria Assessment: What's New?Document28 pagesFrenchay Dysarthria Assessment: What's New?srigiriaslp12No ratings yet
- What Is Popdev? - Nimfa OgenaDocument41 pagesWhat Is Popdev? - Nimfa OgenaMulat Pinoy-Kabataan News NetworkNo ratings yet
- Rational Investing with Ratios: Implementing Ratios with Enterprise Value and Behavioral FinanceFrom EverandRational Investing with Ratios: Implementing Ratios with Enterprise Value and Behavioral FinanceNo ratings yet
- D Ata Science In: PracticeDocument7 pagesD Ata Science In: PracticeShadowfax_u0% (1)
- Google, FB in ChinaDocument4 pagesGoogle, FB in ChinaShadowfax_uNo ratings yet
- 1 Mongolia A Cultural Portrait UsingDocument9 pages1 Mongolia A Cultural Portrait UsingShadowfax_uNo ratings yet
- Business Ethics 10 2016-10-27 Competition Ethics E2Document14 pagesBusiness Ethics 10 2016-10-27 Competition Ethics E2Shadowfax_uNo ratings yet
- Consent Form For Thesis Instruction: Applicant SignatureDocument1 pageConsent Form For Thesis Instruction: Applicant SignatureShadowfax_uNo ratings yet
- Impact of Total Quality Management and Service Quality in The Banking SectorDocument5 pagesImpact of Total Quality Management and Service Quality in The Banking SectorShadowfax_uNo ratings yet
- A Model of Tourism Destination Brand Equity The Case of Wine Tourism Destinations in SpainDocument13 pagesA Model of Tourism Destination Brand Equity The Case of Wine Tourism Destinations in SpainShadowfax_uNo ratings yet
- Sta4853 12printDocument3 pagesSta4853 12printShadowfax_uNo ratings yet
- 2012 KPMG Nigeria Banking Industry Customer Satisfaction Survey Final PDFDocument32 pages2012 KPMG Nigeria Banking Industry Customer Satisfaction Survey Final PDFShadowfax_uNo ratings yet
- Example Arm A EstimationDocument6 pagesExample Arm A EstimationShadowfax_uNo ratings yet
- Reynolds03 JSSC Vol38no9 Pp1555-1560 ADirectConvReceiverICforWCDMAMobileSystemsDocument6 pagesReynolds03 JSSC Vol38no9 Pp1555-1560 ADirectConvReceiverICforWCDMAMobileSystemsTom BlattnerNo ratings yet
- Megawatt-Frequency: ProblemDocument15 pagesMegawatt-Frequency: ProblemSudhir KumarNo ratings yet
- CardozoDocument12 pagesCardozoAman Dheer KapoorNo ratings yet
- Adhikari Grad - Msu 0128N 15526Document66 pagesAdhikari Grad - Msu 0128N 15526Tce Shikin100% (1)
- 11MA Meek PDFDocument7 pages11MA Meek PDFHenry BarriosNo ratings yet
- Research On Kano Model Based On Online Comment Data Mining: Huaming Song Chao ChenDocument7 pagesResearch On Kano Model Based On Online Comment Data Mining: Huaming Song Chao ChenshitalNo ratings yet
- Analysis of VarianceDocument5 pagesAnalysis of VarianceAshis LambaNo ratings yet
- Tip #2 - How To Turn A Note Into A ParagraphDocument1 pageTip #2 - How To Turn A Note Into A ParagraphJoel TrogeNo ratings yet
- ConceptattainmentDocument2 pagesConceptattainmentapi-239512266100% (2)
- Resume Rajkiran Updated - GenDocument4 pagesResume Rajkiran Updated - GenRaj KiranNo ratings yet
- Format No 7 RSOP Final ReportDocument2 pagesFormat No 7 RSOP Final ReportMelissa MillerNo ratings yet
- An Assesment On The Impact of Converting Used Paper Into Flower Vase For Grade 12 Abm Students at Bestlink College of The Philippines S.Y. 2019-2020Document59 pagesAn Assesment On The Impact of Converting Used Paper Into Flower Vase For Grade 12 Abm Students at Bestlink College of The Philippines S.Y. 2019-2020Jay Ar DadiroNo ratings yet
- Adaptive Performance Teacher 3Document13 pagesAdaptive Performance Teacher 3Indah CahyaaNo ratings yet
- Constantinides 2006Document33 pagesConstantinides 2006Cristian ReyesNo ratings yet
- Spatial Analysis of Human Population Distribution and Growth in Marinduque Island, PhilippinesDocument3 pagesSpatial Analysis of Human Population Distribution and Growth in Marinduque Island, PhilippinesMarinela DaumarNo ratings yet
- Venn DiagramDocument2 pagesVenn DiagramVelley Jay Casawitan100% (9)
- chw3m Outline 2015Document3 pageschw3m Outline 2015api-267090186No ratings yet
- A Transportation Management SystemDocument2 pagesA Transportation Management SystemQuinie MoralesNo ratings yet
- Principals' Con Ict Resolution Strategies and Teachers' Job Effectiveness in Public Secondary Schools in Akwa Ibom State, NigeriaDocument7 pagesPrincipals' Con Ict Resolution Strategies and Teachers' Job Effectiveness in Public Secondary Schools in Akwa Ibom State, NigeriaCristiana AmarieiNo ratings yet
- Volatility RegimeDocument202 pagesVolatility RegimeDaniele Rubinetti100% (1)


































































































Download as pdf or txt
You might also like
- National Council For Interior Design Qualification (NCIDQ) Exam Study GuideDocument20 pagesNational Council For Interior Design Qualification (NCIDQ) Exam Study GuideMcRee Learning Center100% (1)
- Exam in Statistics #2 - BusinessDocument2 pagesExam in Statistics #2 - BusinessOverland-X Philippines100% (1)
- Action Research ProposalDocument3 pagesAction Research ProposalAiv Ylanan89% (9)
- Apollo Personality Test Training CourseDocument2 pagesApollo Personality Test Training CourseMegan RamsayNo ratings yet
- A-008550-1624688646968-80386-Unit 34 - System Analysis and Design.Document103 pagesA-008550-1624688646968-80386-Unit 34 - System Analysis and Design.Hansi Ranasinghe100% (1)
- AI For Analytics: Written By: Brooke LynchDocument12 pagesAI For Analytics: Written By: Brooke LynchPera PericNo ratings yet
- The Awareness Level of Senior High School Student in Applying Occupational Health and Safety ProcedureDocument20 pagesThe Awareness Level of Senior High School Student in Applying Occupational Health and Safety ProcedureWilliam GarciaNo ratings yet
- Philippine Guidelines On Periodic Health Examination (PHEx) PDFDocument25 pagesPhilippine Guidelines On Periodic Health Examination (PHEx) PDFLinius CruzNo ratings yet
- Ug Special TermDocument40 pagesUg Special TermRegina SamsonNo ratings yet
- Vision MandateDocument7 pagesVision MandateJade Sanico BaculantaNo ratings yet
- Alfa Beta DailybkuplDocument1,369 pagesAlfa Beta DailybkuplCardoso PenhaNo ratings yet
- Weighted Preferences in Evolutionary Multi-Objective OptimizationDocument10 pagesWeighted Preferences in Evolutionary Multi-Objective Optimizationmehmetkartal19No ratings yet
- CitiGroup On TrendFollowingDocument49 pagesCitiGroup On TrendFollowingGabNo ratings yet
- Lecture 7 - 2023 (1-55, 66-68)Document69 pagesLecture 7 - 2023 (1-55, 66-68)saad ansariNo ratings yet
- Bond Yields and Prices: Reference: Chapter 17Document30 pagesBond Yields and Prices: Reference: Chapter 17RosaNo ratings yet
- 01.1 Plan Lineal Canal, Cesar MarzoDocument3 pages01.1 Plan Lineal Canal, Cesar MarzoAlejandro MarquezNo ratings yet
- Sparse Linear RegressionDocument45 pagesSparse Linear Regressiongifom43181No ratings yet
- Assess For Credit RatingDocument12 pagesAssess For Credit RatingbagirNo ratings yet
- New Wave Capital Management FundDocument5 pagesNew Wave Capital Management FundAleksandar DendaNo ratings yet
- Charts That Matter - 19 October 2018Document5 pagesCharts That Matter - 19 October 2018JustinC.PaoliniNo ratings yet
- P03 HeteroskedastikDocument27 pagesP03 Heteroskedastikdilafara152No ratings yet
- This Work Is Licensed Under The Creative Commons Attribution-Noncommercial 3.0 Singapore LicenseDocument24 pagesThis Work Is Licensed Under The Creative Commons Attribution-Noncommercial 3.0 Singapore LicenseFrancesco ZucchettoNo ratings yet
- PNRA Panera Bread 2016 Annual Shareholder PresentationDocument46 pagesPNRA Panera Bread 2016 Annual Shareholder PresentationAla BasterNo ratings yet
- Performance Analysis of R. N. Spinning Mills Limited.Document10 pagesPerformance Analysis of R. N. Spinning Mills Limited.Axis StyleNo ratings yet
- Lect7 Math231Document29 pagesLect7 Math231Qasim RafiNo ratings yet
- Intermediate Financial Management 12th Edition Brigham Solutions Manual DownloadDocument46 pagesIntermediate Financial Management 12th Edition Brigham Solutions Manual DownloadPreston Warfield100% (30)
- k2 Attachments CT Lecture 14. Multiple Linear RegressionDocument37 pagesk2 Attachments CT Lecture 14. Multiple Linear Regressionnguyendung0917No ratings yet
- 50 AAPL Buyside PitchbookDocument22 pages50 AAPL Buyside PitchbookAkshay ShaikhNo ratings yet
- Fundamentals of Intelligent Theses: Lecture 5: Quality Figures Chemeng 690ADocument33 pagesFundamentals of Intelligent Theses: Lecture 5: Quality Figures Chemeng 690AWes violaNo ratings yet
- 1Q2020 Fullbook enDocument53 pages1Q2020 Fullbook enVincentNo ratings yet
- Transpek Industry LTDDocument6 pagesTranspek Industry LTDabhishekbasumallick100% (1)
- A General Approach To Sensitivity AnalysisDocument37 pagesA General Approach To Sensitivity AnalysisjimmymorelosNo ratings yet
- 50 AAPL Buyside PitchbookDocument22 pages50 AAPL Buyside PitchbookkamranNo ratings yet
- Soil ParameterDocument3 pagesSoil Parameterhessian123No ratings yet
- CH 04Document24 pagesCH 04PriyankaNo ratings yet
- Luiz Reliability ProjectDocument14 pagesLuiz Reliability ProjectMiro GrulovicNo ratings yet
- Current Ratio:: Current Assets Current LiabilitiesDocument5 pagesCurrent Ratio:: Current Assets Current LiabilitiesshamarjitNo ratings yet
- Number. Level 4. Equivalence. Fractions Decimals Percentages (A)Document1 pageNumber. Level 4. Equivalence. Fractions Decimals Percentages (A)Steve HatolNo ratings yet
- IEQ Oct 2017 PresentationDocument32 pagesIEQ Oct 2017 PresentationnotagoodpasswordoliverNo ratings yet
- The Under and Overestimation of RiskDocument18 pagesThe Under and Overestimation of RiskHhp YmNo ratings yet
- LNG Spot Prices and Long-Term Contracts: Peter R HartleyDocument41 pagesLNG Spot Prices and Long-Term Contracts: Peter R HartleyAhmad NawwarNo ratings yet
- Business Inventories Fell 0.7 Percent in NovemberDocument1 pageBusiness Inventories Fell 0.7 Percent in NovemberInternational Business TimesNo ratings yet
- SDE KultamDocument33 pagesSDE Kultamindira maharaniNo ratings yet
- Case Study: Masa: Hasil AnalisisDocument35 pagesCase Study: Masa: Hasil AnalisisAtikah DarayaniNo ratings yet
- ZOES WB Presentation June17 (1) 2017Document29 pagesZOES WB Presentation June17 (1) 2017Ala BasterNo ratings yet
- The Largest Automobile Scandal in The History !Document21 pagesThe Largest Automobile Scandal in The History !rohitNo ratings yet
- 2020 - 05 Barbon and Buraschi 2020 - Gamma FragilityDocument60 pages2020 - 05 Barbon and Buraschi 2020 - Gamma Fragilitynexxus hcNo ratings yet
- HW3 Managerial FinanceDocument13 pagesHW3 Managerial FinanceAndrew HawkinsNo ratings yet
- Assignements in Corporate FinanceDocument1 pageAssignements in Corporate FinanceshehurinaNo ratings yet
- Expro RBI Expert Group HandbookDocument26 pagesExpro RBI Expert Group HandbookJavier RivasNo ratings yet
- AQR Alternative Thinking Q1 2021 Capital Market Assumptions For Major Asset ClassessDocument16 pagesAQR Alternative Thinking Q1 2021 Capital Market Assumptions For Major Asset ClassessindiaNo ratings yet
- Lbo ModelDocument4 pagesLbo Modelharshalp1212No ratings yet
- An Economist's Guide To Visualizing Data: Jonathan A. SchwabishDocument28 pagesAn Economist's Guide To Visualizing Data: Jonathan A. SchwabishResuf AhmedNo ratings yet
- Lecture 15 - 2024Document40 pagesLecture 15 - 2024Marwan MikdadiNo ratings yet
- Risk and Return Chapter 5Document55 pagesRisk and Return Chapter 5sundas younasNo ratings yet
- A11 IndustryInputs Module4Document5 pagesA11 IndustryInputs Module4Ranga SenthilNo ratings yet
- Continuation To StocksDocument53 pagesContinuation To StocksTahaNo ratings yet
- Assessment of Assumptions in SLR:: There Is A Real Linear Relationship Between The Mean Response andDocument6 pagesAssessment of Assumptions in SLR:: There Is A Real Linear Relationship Between The Mean Response andKhushbakht BalochNo ratings yet
- Beverage Trends AnalysisDocument49 pagesBeverage Trends AnalysisCarlosNo ratings yet
- 2018 Roche RD ReportDocument27 pages2018 Roche RD ReportsyedNo ratings yet
- Dividend Practices of Islamic Banks in Bangladesh (Shariah Compliances) by Hasan Asif SouravDocument21 pagesDividend Practices of Islamic Banks in Bangladesh (Shariah Compliances) by Hasan Asif SouravHasan Asif SouravNo ratings yet
- Chapter 5Document82 pagesChapter 5MUHAMMAD IMRAN HAKIM BIN SULAIMAN STUDENTNo ratings yet
- Chuchu's AssignmentDocument26 pagesChuchu's AssignmentamirNo ratings yet
- Chapter 24. Tool Kit For Portfolio Theory, Asset Pricing Models, and Behavioral FinanceDocument22 pagesChapter 24. Tool Kit For Portfolio Theory, Asset Pricing Models, and Behavioral Financetreeken2No ratings yet
- Frenchay Dysarthria Assessment: What's New?Document28 pagesFrenchay Dysarthria Assessment: What's New?srigiriaslp12No ratings yet
- What Is Popdev? - Nimfa OgenaDocument41 pagesWhat Is Popdev? - Nimfa OgenaMulat Pinoy-Kabataan News NetworkNo ratings yet
- Rational Investing with Ratios: Implementing Ratios with Enterprise Value and Behavioral FinanceFrom EverandRational Investing with Ratios: Implementing Ratios with Enterprise Value and Behavioral FinanceNo ratings yet
- D Ata Science In: PracticeDocument7 pagesD Ata Science In: PracticeShadowfax_u0% (1)
- Google, FB in ChinaDocument4 pagesGoogle, FB in ChinaShadowfax_uNo ratings yet
- 1 Mongolia A Cultural Portrait UsingDocument9 pages1 Mongolia A Cultural Portrait UsingShadowfax_uNo ratings yet
- Business Ethics 10 2016-10-27 Competition Ethics E2Document14 pagesBusiness Ethics 10 2016-10-27 Competition Ethics E2Shadowfax_uNo ratings yet
- Consent Form For Thesis Instruction: Applicant SignatureDocument1 pageConsent Form For Thesis Instruction: Applicant SignatureShadowfax_uNo ratings yet
- Impact of Total Quality Management and Service Quality in The Banking SectorDocument5 pagesImpact of Total Quality Management and Service Quality in The Banking SectorShadowfax_uNo ratings yet
- A Model of Tourism Destination Brand Equity The Case of Wine Tourism Destinations in SpainDocument13 pagesA Model of Tourism Destination Brand Equity The Case of Wine Tourism Destinations in SpainShadowfax_uNo ratings yet
- Sta4853 12printDocument3 pagesSta4853 12printShadowfax_uNo ratings yet
- 2012 KPMG Nigeria Banking Industry Customer Satisfaction Survey Final PDFDocument32 pages2012 KPMG Nigeria Banking Industry Customer Satisfaction Survey Final PDFShadowfax_uNo ratings yet
- Example Arm A EstimationDocument6 pagesExample Arm A EstimationShadowfax_uNo ratings yet
- Reynolds03 JSSC Vol38no9 Pp1555-1560 ADirectConvReceiverICforWCDMAMobileSystemsDocument6 pagesReynolds03 JSSC Vol38no9 Pp1555-1560 ADirectConvReceiverICforWCDMAMobileSystemsTom BlattnerNo ratings yet
- Megawatt-Frequency: ProblemDocument15 pagesMegawatt-Frequency: ProblemSudhir KumarNo ratings yet
- CardozoDocument12 pagesCardozoAman Dheer KapoorNo ratings yet
- Adhikari Grad - Msu 0128N 15526Document66 pagesAdhikari Grad - Msu 0128N 15526Tce Shikin100% (1)
- 11MA Meek PDFDocument7 pages11MA Meek PDFHenry BarriosNo ratings yet
- Research On Kano Model Based On Online Comment Data Mining: Huaming Song Chao ChenDocument7 pagesResearch On Kano Model Based On Online Comment Data Mining: Huaming Song Chao ChenshitalNo ratings yet
- Analysis of VarianceDocument5 pagesAnalysis of VarianceAshis LambaNo ratings yet
- Tip #2 - How To Turn A Note Into A ParagraphDocument1 pageTip #2 - How To Turn A Note Into A ParagraphJoel TrogeNo ratings yet
- ConceptattainmentDocument2 pagesConceptattainmentapi-239512266100% (2)
- Resume Rajkiran Updated - GenDocument4 pagesResume Rajkiran Updated - GenRaj KiranNo ratings yet
- Format No 7 RSOP Final ReportDocument2 pagesFormat No 7 RSOP Final ReportMelissa MillerNo ratings yet
- An Assesment On The Impact of Converting Used Paper Into Flower Vase For Grade 12 Abm Students at Bestlink College of The Philippines S.Y. 2019-2020Document59 pagesAn Assesment On The Impact of Converting Used Paper Into Flower Vase For Grade 12 Abm Students at Bestlink College of The Philippines S.Y. 2019-2020Jay Ar DadiroNo ratings yet
- Adaptive Performance Teacher 3Document13 pagesAdaptive Performance Teacher 3Indah CahyaaNo ratings yet
- Constantinides 2006Document33 pagesConstantinides 2006Cristian ReyesNo ratings yet
- Spatial Analysis of Human Population Distribution and Growth in Marinduque Island, PhilippinesDocument3 pagesSpatial Analysis of Human Population Distribution and Growth in Marinduque Island, PhilippinesMarinela DaumarNo ratings yet
- Venn DiagramDocument2 pagesVenn DiagramVelley Jay Casawitan100% (9)
- chw3m Outline 2015Document3 pageschw3m Outline 2015api-267090186No ratings yet
- A Transportation Management SystemDocument2 pagesA Transportation Management SystemQuinie MoralesNo ratings yet
- Principals' Con Ict Resolution Strategies and Teachers' Job Effectiveness in Public Secondary Schools in Akwa Ibom State, NigeriaDocument7 pagesPrincipals' Con Ict Resolution Strategies and Teachers' Job Effectiveness in Public Secondary Schools in Akwa Ibom State, NigeriaCristiana AmarieiNo ratings yet
- Volatility RegimeDocument202 pagesVolatility RegimeDaniele Rubinetti100% (1)