Download as pdf or txt
You might also like
- JaBuka TopologyDocument131 pagesJaBuka TopologyGabriel Dalla VecchiaNo ratings yet
- M2 Difference EqnsDocument36 pagesM2 Difference EqnsJeremy Oh100% (1)
- OBE Mathematics in The Modern WorldDocument14 pagesOBE Mathematics in The Modern WorldShela Ramos100% (1)
- Ext Angle THM Practice Triangle Sum PracticeDocument4 pagesExt Angle THM Practice Triangle Sum PracticeJavzanlkham VanchinbazarNo ratings yet
- Unit - I Artificial Neural NetworksDocument23 pagesUnit - I Artificial Neural NetworksMary MorseNo ratings yet
- Unit - I Artificial Neural NetworksDocument23 pagesUnit - I Artificial Neural NetworksMary MorseNo ratings yet
- Hebbian Learning and Gradient Descent Learning: Neural Computation: Lecture 5Document20 pagesHebbian Learning and Gradient Descent Learning: Neural Computation: Lecture 5richaNo ratings yet
- Lecture 2.1.3 - HopfieldDocument10 pagesLecture 2.1.3 - HopfieldMohd YusufNo ratings yet
- Lecture 4 - 2007 - Backpropagation - (HINTON)Document60 pagesLecture 4 - 2007 - Backpropagation - (HINTON)alan1966No ratings yet
- Busiess Analytics Data Mining Lecture 7Document37 pagesBusiess Analytics Data Mining Lecture 7utkarsh bhargavaNo ratings yet
- Chapter 4Document10 pagesChapter 4Emanuel DiegoNo ratings yet
- 3 DeltaRule PDFDocument10 pages3 DeltaRule PDFEs ENo ratings yet
- Artificial Neural Network Supervised LearningDocument14 pagesArtificial Neural Network Supervised LearningsegnumutraNo ratings yet
- Pre University 2023-24Document51 pagesPre University 2023-24Sam XiiNo ratings yet
- DL Concepts 1 OverviewDocument80 pagesDL Concepts 1 OverviewB PrasadNo ratings yet
- Chapter 07 Artificial Neural NetworkDocument62 pagesChapter 07 Artificial Neural NetworkRijesh ShresthaNo ratings yet
- 001 IntroDocument66 pages001 IntromanikNo ratings yet
- شبكات عصبية ٢Document6 pagesشبكات عصبية ٢Afkir Al-HusaineNo ratings yet
- Pseudo Label FinalDocument6 pagesPseudo Label FinaljustinthecoachNo ratings yet
- Chapter 10: Artificial Neural NetworksDocument17 pagesChapter 10: Artificial Neural NetworksTran Kim ToaiNo ratings yet
- Neural Networks For Machine LearningDocument47 pagesNeural Networks For Machine LearningMohammad AlzyoudNo ratings yet
- Lect 15 MLP Introduction BackpropDocument24 pagesLect 15 MLP Introduction Backpropharshitad1272No ratings yet
- Multilayer Perceptrons and Backpropagation Learning: 1 Some HistoryDocument6 pagesMultilayer Perceptrons and Backpropagation Learning: 1 Some HistoryIgnacio IriarteNo ratings yet
- Lecture Slides 2 - Neural Networks - 2021Document42 pagesLecture Slides 2 - Neural Networks - 2021alvinNo ratings yet
- Artificial Neural NetworksDocument54 pagesArtificial Neural NetworksSabin ThapaNo ratings yet
- Ar$ficial Neural Network - : Adaline and MadalineDocument22 pagesAr$ficial Neural Network - : Adaline and MadalineFaslil FawaidiNo ratings yet
- Indo German Winter Academy 2010: Multigrid MethodsDocument40 pagesIndo German Winter Academy 2010: Multigrid MethodsVesa RäisänenNo ratings yet
- CNN and Gan: Introduction ToDocument58 pagesCNN and Gan: Introduction ToGopiNath VelivelaNo ratings yet
- Lecture 1, Part 3: Training A Classifier: Roger GrosseDocument11 pagesLecture 1, Part 3: Training A Classifier: Roger GrosseShamil shihab pkNo ratings yet
- Inductive Bias: How To Generalize On Novel DataDocument33 pagesInductive Bias: How To Generalize On Novel Datasaniaaisha11No ratings yet
- Artificial Neural Network (ANN) : Duration: 8 Hrs OutlineDocument61 pagesArtificial Neural Network (ANN) : Duration: 8 Hrs Outlineanhtu9_910280373No ratings yet
- Automatic Generation Control Using Artificial Neural Networks - HarkiratDocument47 pagesAutomatic Generation Control Using Artificial Neural Networks - Harkiratmalini72No ratings yet
- Model of Neuron in An ANNDocument12 pagesModel of Neuron in An ANNpolinati.vinesh2023No ratings yet
- Neural NetworksDocument42 pagesNeural NetworksTharun RaajNo ratings yet
- Machine Learning 10-701 Final Exam May 5, 2015: Obvious Exceptions For Pacemakers and Hearing AidsDocument17 pagesMachine Learning 10-701 Final Exam May 5, 2015: Obvious Exceptions For Pacemakers and Hearing AidsNithinNo ratings yet
- CS4740/5740 Introduction To NLP Fall 2017 Neural Language Models and ClassifiersDocument7 pagesCS4740/5740 Introduction To NLP Fall 2017 Neural Language Models and ClassifiersEdward LeeNo ratings yet
- Lecture BDS 4 23 24 PrintDocument14 pagesLecture BDS 4 23 24 PrintVictor Van der WelNo ratings yet
- Different Classes of Abstract Models: - Supervised Learning (EX: Perceptron) Reinforcement Learning - Unsupervised Learning (EX: Hebb Rule)Document31 pagesDifferent Classes of Abstract Models: - Supervised Learning (EX: Perceptron) Reinforcement Learning - Unsupervised Learning (EX: Hebb Rule)hari pukhaNo ratings yet
- Adaline and MedalineDocument14 pagesAdaline and MedalineBHAVNA AGARWAL50% (2)
- Lecture 10 Neural NetworkDocument34 pagesLecture 10 Neural NetworkMohsin IqbalNo ratings yet
- As Lecture9 NN2Document2 pagesAs Lecture9 NN2mrtfkhangNo ratings yet
- 1 - Single Layer Perceptron ANN SDocument40 pages1 - Single Layer Perceptron ANN SDumidu GhanasekaraNo ratings yet
- Neural Network PresentationDocument33 pagesNeural Network PresentationMohd Yaseen100% (4)
- Matrix Pseudoinversion For Image Neural ProcessingDocument17 pagesMatrix Pseudoinversion For Image Neural ProcessingAtınç YılmazNo ratings yet
- 02 LearningProcessDocument38 pages02 LearningProcessHipiijxsdjNo ratings yet
- Artificial Neural Networks: System That Can Acquire, Store, and Utilize Experiential KnowledgeDocument43 pagesArtificial Neural Networks: System That Can Acquire, Store, and Utilize Experiential KnowledgeUtkarsh AgarwalNo ratings yet
- Large Scale Deep LearningDocument170 pagesLarge Scale Deep Learningpavancreative81No ratings yet
- Lecun 20181015 Ihes Gomax PDFDocument109 pagesLecun 20181015 Ihes Gomax PDFlauraNo ratings yet
- L3 BackpropagationDocument61 pagesL3 BackpropagationAlimohd AslamNo ratings yet
- Logistic Regression: ClassificationDocument32 pagesLogistic Regression: Classificationesteban1815No ratings yet
- Neural Network and Fuzzy LogicDocument54 pagesNeural Network and Fuzzy Logicshreyas sr100% (1)
- Presentation On: Neural NetworkDocument30 pagesPresentation On: Neural NetworkMuhanad Al-khalisyNo ratings yet
- Simple PerceptronsDocument28 pagesSimple PerceptronsRishabhNo ratings yet
- Back Prop in Cortex 2007Document16 pagesBack Prop in Cortex 2007danielNo ratings yet
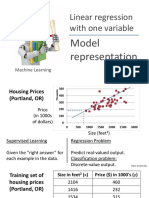
- Linear Regression With One Variable: Model RepresentationDocument48 pagesLinear Regression With One Variable: Model RepresentationKo Có tênNo ratings yet
- Linear Regression With One Variable: Model RepresentationDocument48 pagesLinear Regression With One Variable: Model RepresentationKo Có tênNo ratings yet
- Section 12 PDFDocument7 pagesSection 12 PDFMASHIAT MUTMAINNAHNo ratings yet
- Math Essentials1234adadvklop32165adada PDFDocument55 pagesMath Essentials1234adadvklop32165adada PDFAbu SalehNo ratings yet
- Math Essentials PDFDocument55 pagesMath Essentials PDFAbu SalehNo ratings yet
- 1234adadvklop32165adada PDFDocument55 pages1234adadvklop32165adada PDFAbu SalehNo ratings yet
- Math Essentials1234adadada PDFDocument55 pagesMath Essentials1234adadada PDFAbu SalehNo ratings yet
- Deep Learning Nonlinear ControlDocument68 pagesDeep Learning Nonlinear ControlDaotao DaihocNo ratings yet
- Week 06 Lecture MaterialDocument46 pagesWeek 06 Lecture MaterialMeer HassanNo ratings yet
- Green's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)From EverandGreen's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)No ratings yet
- CRC Understanding Digital Image Processing 1138566845 PDFDocument375 pagesCRC Understanding Digital Image Processing 1138566845 PDFWang Chen Yu100% (2)
- 15 Support Vector MachinesDocument30 pages15 Support Vector MachinesWang Chen YuNo ratings yet
- 06b Discriminant AnalysisDocument18 pages06b Discriminant AnalysisWang Chen YuNo ratings yet
- 16 Dimensionality ReductionDocument37 pages16 Dimensionality ReductionWang Chen YuNo ratings yet
- Machine Learning Machine Learning DataDocument43 pagesMachine Learning Machine Learning DataWang Chen YuNo ratings yet
- 06c Nearest NeighborDocument17 pages06c Nearest NeighborWang Chen YuNo ratings yet
- 3rd Quarter Assessment Math 10Document5 pages3rd Quarter Assessment Math 10Erick DiosoNo ratings yet
- Analysis of Pressure Transient Tests in Naturally Fractured Reservoirs 2472 0518 1000121Document10 pagesAnalysis of Pressure Transient Tests in Naturally Fractured Reservoirs 2472 0518 1000121Franco HernandezNo ratings yet
- 1987 - Generalized Predictive Control - Part I - Clarke PDFDocument12 pages1987 - Generalized Predictive Control - Part I - Clarke PDFademargcjuniorNo ratings yet
- BSCPH 101 PDFDocument328 pagesBSCPH 101 PDFPankaj RajNo ratings yet
- Knowledge Graph EmbeddingDocument8 pagesKnowledge Graph Embeddingnigel989No ratings yet
- Chapter 8 Circular Measure PDFDocument11 pagesChapter 8 Circular Measure PDFTakib AhmedNo ratings yet
- 5.1 Elementary Theory of Initial-Value ProblemsDocument11 pages5.1 Elementary Theory of Initial-Value ProblemswandileNo ratings yet
- Fourier Series and IntegralsDocument10 pagesFourier Series and IntegralsFahrudin MNo ratings yet
- Applied Functional Analysis Main Principles and Their Applications Zeidler CompressDocument417 pagesApplied Functional Analysis Main Principles and Their Applications Zeidler CompresshhhybpmdqzNo ratings yet
- Mathematics in Modern WorldDocument2 pagesMathematics in Modern WorldAnne Jezreel OgoyNo ratings yet
- MAT1514 Assignment 1, 2024Document2 pagesMAT1514 Assignment 1, 2024bafanacheraneNo ratings yet
- 1 Chinese Remainder TheoremDocument4 pages1 Chinese Remainder TheoremDoddy FeryantoNo ratings yet
- Unit1 BinaryNumSystemDocument27 pagesUnit1 BinaryNumSystemShripad AshtekarNo ratings yet
- Complete Syllabus of Maths - The PunditsDocument9 pagesComplete Syllabus of Maths - The PunditsSanu SanuNo ratings yet
- Channel Capacity, Shannon Hartley Law and Shannon's LimitDocument29 pagesChannel Capacity, Shannon Hartley Law and Shannon's LimitstanleyNo ratings yet
- Model Paper 19 With Pass CodeDocument8 pagesModel Paper 19 With Pass CodeDevin GamageNo ratings yet
- Shift and Rotate Instructions: Sahar Mosleh California State University San Marcos 1Document19 pagesShift and Rotate Instructions: Sahar Mosleh California State University San Marcos 1Gokul SaiNo ratings yet
- Roark's Formula 0 30Document1 pageRoark's Formula 0 30Jay CeeNo ratings yet
- HMWK 4Document5 pagesHMWK 4Jasmine NguyenNo ratings yet
- LT Lecture 10 Problem Solving Using SetsDocument35 pagesLT Lecture 10 Problem Solving Using SetsTechnical InformationNo ratings yet
- Junior Kangaroo Mathematical Challenge Tuesday 13th June 2017 Organised by The United Kingdom Mathematics TrustDocument4 pagesJunior Kangaroo Mathematical Challenge Tuesday 13th June 2017 Organised by The United Kingdom Mathematics TrustAdd UpNo ratings yet
- Q1. The Equivalent Circuit in The Laplace DomainDocument23 pagesQ1. The Equivalent Circuit in The Laplace DomainumarsaboNo ratings yet
- Pertemuan 1 - Memodelkan PerubahanDocument8 pagesPertemuan 1 - Memodelkan PerubahanRara Sandhy WinandaNo ratings yet
- The Meanings of Physics Equations and Physics EducDocument8 pagesThe Meanings of Physics Equations and Physics EducLola TomasNo ratings yet
- 2d and 3d ShapesDocument15 pages2d and 3d ShapesLakshaya JainNo ratings yet
- Presentation Output: Learning Task 7: Photo Conic SectionsDocument28 pagesPresentation Output: Learning Task 7: Photo Conic Sectionsjaypee sarmientoNo ratings yet