
Professional Documents
Culture Documents
Huawei OceanStor Backup Software Technical White Paper For Simpana 1
Huawei OceanStor Backup Software Technical White Paper For Simpana 1
Uploaded by
yassineCopyright:
Available Formats
You might also like
- XNMS Operation GuideDocument76 pagesXNMS Operation GuideJose De PinaNo ratings yet
- PMDG 737NGX SDKDocument25 pagesPMDG 737NGX SDK廖宗原No ratings yet
- 阵阵 Dirty Cache 阵阵阵 Emcremote 阵阵阵阵Document6 pages阵阵 Dirty Cache 阵阵阵 Emcremote 阵阵阵阵taichiguanNo ratings yet
- Huawei OceanStor 5300 5500 5600 and 5800 V5 Mid-Range Hybrid Flash Storage Systems Technical White PaperDocument69 pagesHuawei OceanStor 5300 5500 5600 and 5800 V5 Mid-Range Hybrid Flash Storage Systems Technical White PaperPavel IlichevNo ratings yet
- Managing Volumes and File Systems For VNX ManuallyDocument100 pagesManaging Volumes and File Systems For VNX ManuallyPabloNo ratings yet
- Pg056-Cpri v87Document180 pagesPg056-Cpri v87Mümin GözütokNo ratings yet
- Oracle Generic Migration Version 1Document19 pagesOracle Generic Migration Version 1Karthik RamanNo ratings yet
- xilinx-1G/10G/25G Switching Ethernet SubsystemDocument139 pagesxilinx-1G/10G/25G Switching Ethernet SubsystemSaeed SaNo ratings yet
- Bandwidth Sharing of Multimode Base Station Co-Transmission (SRAN18.1 - Draft A)Document72 pagesBandwidth Sharing of Multimode Base Station Co-Transmission (SRAN18.1 - Draft A)VVLNo ratings yet
- Docu93960 - NetWorker 19.1 Cluster Integration Guide PDFDocument80 pagesDocu93960 - NetWorker 19.1 Cluster Integration Guide PDFmerz asmaNo ratings yet
- PenTest6 18 Preview PDFDocument25 pagesPenTest6 18 Preview PDFcbar15No ratings yet
- MX 204Document187 pagesMX 204Soemitro KolopakingNo ratings yet
- HP FF 5930-32QSFP+Document34 pagesHP FF 5930-32QSFP+lonnieNo ratings yet
- Aruba 5406R DatasheetDocument22 pagesAruba 5406R DatasheetWK OngNo ratings yet
- Cpri Mux (Lampsite) (Sran18.1 - Draft A)Document80 pagesCpri Mux (Lampsite) (Sran18.1 - Draft A)VVLNo ratings yet
- I) H3C S5560S-EI Series Enhanced Gigabit Switches Datasheet PDFDocument13 pagesI) H3C S5560S-EI Series Enhanced Gigabit Switches Datasheet PDFSON DANG LAMNo ratings yet
- Huawei CloudEngine S5732-H Series Hybrid Optical-Electrical Switches BrochureDocument14 pagesHuawei CloudEngine S5732-H Series Hybrid Optical-Electrical Switches BrochuregaspopperNo ratings yet
- Bandwidth On Demand (BOD) Charging Scheme: Pradya Sriroth TC/IPSTAR Representative Office - PhilippinesDocument5 pagesBandwidth On Demand (BOD) Charging Scheme: Pradya Sriroth TC/IPSTAR Representative Office - PhilippinesPradya SrirothNo ratings yet
- HPE 24 Port Gigabit L2 Switch - HP2530 - 24GDocument11 pagesHPE 24 Port Gigabit L2 Switch - HP2530 - 24GdhirarboyNo ratings yet
- Equipment Security (SRAN16.1 01)Document83 pagesEquipment Security (SRAN16.1 01)VVLNo ratings yet
- VNX5100 Hardware Information GuideDocument54 pagesVNX5100 Hardware Information Guidesandeepsohi88100% (2)
- 5G Architecture and SpecificationsDocument1 page5G Architecture and Specificationshrga hrgaNo ratings yet
- Backup Exec 15 Administrator's Guide PDFDocument1,457 pagesBackup Exec 15 Administrator's Guide PDFAhmed Abdelfattah67% (3)
- SK Telecom DASDocument2 pagesSK Telecom DASJ.R. ArmeaNo ratings yet
- Cisco SyncEDocument34 pagesCisco SyncEDhananjay ShrivastavNo ratings yet
- Ten Considerations For Chosing A Satellite Technology Platform IDirect 020711Document11 pagesTen Considerations For Chosing A Satellite Technology Platform IDirect 020711RomeliaGamarraNo ratings yet
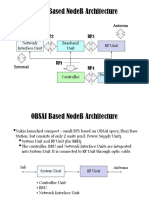
- Obsai Based Nodeb Architecture: AntennaDocument3 pagesObsai Based Nodeb Architecture: AntennaLucky RahmanNo ratings yet
- Sunsight Instruments - Engineering The World's Finest Alignment ToolsDocument2 pagesSunsight Instruments - Engineering The World's Finest Alignment ToolshoainamcomitNo ratings yet
- IFC Centralized Manager 7.1 UG 913-2091-01 ZADocument244 pagesIFC Centralized Manager 7.1 UG 913-2091-01 ZApham hai vanNo ratings yet
- LAN WAN MAnDocument6 pagesLAN WAN MAnAster AbrahaNo ratings yet
- Antenna Alignment SPAA05 NEX Brochure 2Document4 pagesAntenna Alignment SPAA05 NEX Brochure 2furqansNo ratings yet
- PenTest - Hi I Hacked Your ComputerDocument8 pagesPenTest - Hi I Hacked Your ComputerYaman JainNo ratings yet
- 3 Sync Quality MeasurementDocument59 pages3 Sync Quality MeasurementRyankirimiNo ratings yet
- Cisco 5G Monetization Strategies: Redefining The Network Reimaging OpportunityDocument35 pagesCisco 5G Monetization Strategies: Redefining The Network Reimaging OpportunitySuchitra Tonk AnandNo ratings yet
- CloudEngine 6850 Series Data Center Switches Data SheetDocument13 pagesCloudEngine 6850 Series Data Center Switches Data Sheetmehrdad.mortazavi2405No ratings yet
- Synch in Packet NetworkDocument34 pagesSynch in Packet NetworkUwais AbiNo ratings yet
- Trango Antenna User Manual ADXX XX SX 1 and 2 FT DiamDocument14 pagesTrango Antenna User Manual ADXX XX SX 1 and 2 FT DiamhussainNo ratings yet
- ROF For Wireless CommDocument40 pagesROF For Wireless CommVamsi Krishna BNo ratings yet
- Huawei FusionSphere Compatibility ListDocument46 pagesHuawei FusionSphere Compatibility ListAndrés EspejoNo ratings yet
- Remote Data Replicator (RDR) V6.1 User GuideDocument81 pagesRemote Data Replicator (RDR) V6.1 User GuideskyNo ratings yet
- Access Control Based On 802.1x (SRAN16.1 - 01)Document29 pagesAccess Control Based On 802.1x (SRAN16.1 - 01)VVLNo ratings yet
- Ecs UsermanualDocument441 pagesEcs UsermanualMuhammad ImranNo ratings yet
- Audit ReportDocument6 pagesAudit ReporthassaanpashaNo ratings yet
- Timing and Sync Over PSNDocument48 pagesTiming and Sync Over PSNmeo_omhtNo ratings yet
- OceanStor Dorado 6.1 Basic Storage Service Configuration Guide For BlockDocument266 pagesOceanStor Dorado 6.1 Basic Storage Service Configuration Guide For BlockPaweł KuraśNo ratings yet
- Sync Deployment Phase Agg-Access v1Document11 pagesSync Deployment Phase Agg-Access v1vargasriffoNo ratings yet
- Huawei - Enterprise - Hi Care Support ServicesDocument19 pagesHuawei - Enterprise - Hi Care Support Servicesfrankcardoza1No ratings yet
- ANUE SCENARIOS Heynen Mobile BackhaulDocument29 pagesANUE SCENARIOS Heynen Mobile BackhaulJoao HortaNo ratings yet
- Qfx5120 Ethernet Switch DatasheetDocument15 pagesQfx5120 Ethernet Switch Datasheettayyab676No ratings yet
- PacketFence Network Devices Configuration Guide-4.0.6Document82 pagesPacketFence Network Devices Configuration Guide-4.0.6maariussNo ratings yet
- HP IP Console SwitchDocument127 pagesHP IP Console SwitchKishor SriramNo ratings yet
- Neutral Host Distributed Antenna Systems: An Introduction ToDocument14 pagesNeutral Host Distributed Antenna Systems: An Introduction TomkempemaNo ratings yet
- HCIA-AI V1.0 Lab GuideDocument124 pagesHCIA-AI V1.0 Lab Guidemulte123No ratings yet
- Automatic OMCH Establishment (SRAN9.0 - 01) PDFDocument131 pagesAutomatic OMCH Establishment (SRAN9.0 - 01) PDFriamaNo ratings yet
- Dopra Linux OS Security (SingleRAN - 04) PDFDocument35 pagesDopra Linux OS Security (SingleRAN - 04) PDFSam FicherNo ratings yet
- Pki (Sran10.1 02)Document183 pagesPki (Sran10.1 02)riamaNo ratings yet
- Triple Play: Building the converged network for IP, VoIP and IPTVFrom EverandTriple Play: Building the converged network for IP, VoIP and IPTVNo ratings yet
- Huawei OceanStor 5000 V5 Series Hybrid Flash Storage Systems Technical White PaperDocument82 pagesHuawei OceanStor 5000 V5 Series Hybrid Flash Storage Systems Technical White PaperIvan CruzNo ratings yet
- #00400221-IGateway Bill User Manual (V300R001 - 02)Document309 pages#00400221-IGateway Bill User Manual (V300R001 - 02)Shahab RezakhaniNo ratings yet
- Huawei OceanStor Dorado All-Flash Storage 6.1.0 Technical White PaperDocument186 pagesHuawei OceanStor Dorado All-Flash Storage 6.1.0 Technical White PaperFernandoNo ratings yet
- New WinRAR ZIP ArchiveDocument4 pagesNew WinRAR ZIP ArchivePutraOrionNo ratings yet
- Tutorial Letter 101/3/2020: Taxation of IndividualsDocument53 pagesTutorial Letter 101/3/2020: Taxation of Individuals44v8ct8cdyNo ratings yet
- RD Service Device Driver 3.0Document2 pagesRD Service Device Driver 3.0Manish DabralNo ratings yet
- B CSR1000v Configuration Guide Chapter 010110Document6 pagesB CSR1000v Configuration Guide Chapter 010110RcuisNo ratings yet
- Mediatek Antenna TestingDocument64 pagesMediatek Antenna TestingEduardo Solana LopezNo ratings yet
- Mir200 User Guide - Robot Interface 20 v10Document45 pagesMir200 User Guide - Robot Interface 20 v10việt dũng bùiNo ratings yet
- 1791 Certificate Testreport NICE Trading Recording V6.2.4 OpenScape Xpert V4R5Document15 pages1791 Certificate Testreport NICE Trading Recording V6.2.4 OpenScape Xpert V4R5Davaadagva AltansarnaiNo ratings yet
- SWOT Analysis of AMD by Prajwal.P.rahangdaleDocument8 pagesSWOT Analysis of AMD by Prajwal.P.rahangdalePrajwal RahangdaleNo ratings yet
- DevOps PPT by MQSDocument17 pagesDevOps PPT by MQSQasim SultaniNo ratings yet
- Coding Interview in JavaDocument568 pagesCoding Interview in JavaYasin KIZILKAYANo ratings yet
- Answer History of ComputersDocument55 pagesAnswer History of ComputersUttam RimalNo ratings yet
- Block Chain ContentDocument1 pageBlock Chain ContentPRIYAM XEROXNo ratings yet
- Bca Sp2020 Groupno-07 Movie Ticket Booking SystemDocument33 pagesBca Sp2020 Groupno-07 Movie Ticket Booking SystemManisha DasNo ratings yet
- Student Projects in Computer Networking: Simulation Versus CodingDocument6 pagesStudent Projects in Computer Networking: Simulation Versus CodingAjeethNo ratings yet
- CVDF - Google SearchDocument1 pageCVDF - Google SearchJames Jackel JamesonNo ratings yet
- MOBILE APPLICATION DEVELOPMENT ContentDocument2 pagesMOBILE APPLICATION DEVELOPMENT ContentSUBHRANSU MOHAN BHUTIANo ratings yet
- 009.1 Data Structure - IIDocument14 pages009.1 Data Structure - IINamanNo ratings yet
- Encapsulated Postscript File Format Specification: Adobe Developer SupportDocument34 pagesEncapsulated Postscript File Format Specification: Adobe Developer SupportSándor NagyNo ratings yet
- DEU-1661 VRV CAD Launch FinalDocument2 pagesDEU-1661 VRV CAD Launch Finalabdullah sahibNo ratings yet
- SIP5 7SK82-85 V07.80 Manual C024-7 enDocument1,686 pagesSIP5 7SK82-85 V07.80 Manual C024-7 enMauro Lúcio SilvaNo ratings yet
- NX CAM Setup TemplatesDocument10 pagesNX CAM Setup TemplatesCadcamnx BrasilNo ratings yet
- CSharp-Advanced-LINQ-ExercisesDocument7 pagesCSharp-Advanced-LINQ-ExercisesbulavinmailforlegezaNo ratings yet
- 13 Ilnas BlockchainDocument69 pages13 Ilnas Blockchainfateh abbasNo ratings yet
- Android App Tools Android Android Tools: RelativelayoutDocument7 pagesAndroid App Tools Android Android Tools: RelativelayoutDivya RajputNo ratings yet
- Application Notes For Configuring Avaya IP Office ServiceDocument34 pagesApplication Notes For Configuring Avaya IP Office Serviceitmilton19No ratings yet
- 7 The InternetDocument27 pages7 The Internet2087Mohammad HusainNo ratings yet
- Bca Unified SyllabusDocument16 pagesBca Unified SyllabusAshishNo ratings yet
- Lto Transfer of Ownership Data Sheet: Lot No.: Buyer No.Document5 pagesLto Transfer of Ownership Data Sheet: Lot No.: Buyer No.Jester MabutiNo ratings yet
- MT830 / MT831: Energy Measurement and ManagementDocument2 pagesMT830 / MT831: Energy Measurement and ManagementneutronbnNo ratings yet























































































Huawei OceanStor Backup Software Technical White Paper For Simpana 1
Huawei OceanStor Backup Software Technical White Paper For Simpana 1
Uploaded by
yassineOriginal Title
Copyright
Available Formats
Share this document
Did you find this document useful?
Is this content inappropriate?
Report this DocumentCopyright:
Available Formats
Huawei OceanStor Backup Software Technical White Paper For Simpana 1
Huawei OceanStor Backup Software Technical White Paper For Simpana 1
Uploaded by
yassineCopyright:
Available Formats
Huawei OceanStor Backup Software Technical White Paper for Simpana :
Huawei OceanStor Backup Software Technical White
Paper for Simpana
Huawei Technologies Co., Ltd
2014-11-18 Copyright © Huawei Page 1 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana
Copyright © Huawei Technologies Co., Ltd. 2014. All rights reserved.
No part of this document may be reproduced or transmitted in any form or by
any means without prior written consent of Huawei Technologies Co., Ltd.
Trademark Notice
, HUAWEI, and are trademarks or registered trademarks of
Huawei Technologies Co., Ltd.
Other trademarks, product, service and company names mentioned are the
property of their respective owners.
General Disclaimer
The information in this document may contain predictive statements including,
without limitation, statements regarding the future financial and operating
results, future product portfolio, new technology, etc. There are a number of
factors that could cause actual results and developments to differ materially
from those expressed or implied in the predictive statements. Therefore, such
information is provided for reference purpose only and constitutes neither an
offer nor an acceptance. Huawei may change the information at any time
without notice.
2014-11-18 Copyright © Huawei Page 2 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana :
Contents
Copyright © Huawei Technologies Co., Ltd. 2014. All rights reserved. ................. 2
Trademark Notice ........................................................................................................ 2
General Disclaimer ...................................................................................................... 2
Contents ....................................................................................................................... 3
Figures .......................................................................................................................... 6
Tables ........................................................................................................................... 8
1 Software Architecture ............................................................................................ 9
1.1 CommServe Server ................................................................................................................ 9
1.2 MediaAgent Server ................................................................................................................ 9
1.3 iDA....................................................................................................................................... 10
1.4 CTE ...................................................................................................................................... 10
1.5 Distributed Indexing Mechanism — Soul of Data Management Software .......................... 10
2 iDA ........................................................................................................................... 12
2.1 File System iDA ................................................................................................................... 12
2.1.1 Backup and Recovery Module of the File System ...................................................... 12
2.1.2 Data archiver of the File System ................................................................................. 12
2.2 Oracle iDA ........................................................................................................................... 13
2.2.1 Backing up an Oracle Database .................................................................................. 13
2.2.2 Recovering the Oracle Database ................................................................................. 17
2.3 Microsoft SQL Server iDA .................................................................................................. 21
2.3.1 SQL Server Transaction Log and Automatic Recovery .............................................. 21
2.3.2 Backup of the SQL Server Database ........................................................................... 22
2.3.3 Recovery of the SQL Server Database ........................................................................ 22
2.3.4 Characteristics of the SQL Server iDA ....................................................................... 22
High performance .................................................................................................... 23
High reliability ......................................................................................................... 23
Ease of use ................................................................................................................. 23
2.4 Microsoft Exchange iDA ..................................................................................................... 24
2.4.1 Backup and Recovery of the Exchange ...................................................................... 24
2.4.2 Exchange Data Archiver ............................................................................................. 26
2014-11-18 Copyright © Huawei Page 3 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana
2.4.3 Legal Hold of the Exchange ....................................................................................... 29
2.5 IBM Lotus Domino iDA ...................................................................................................... 30
2.5.1 Domino Backup .......................................................................................................... 30
2.5.2 Domino Archiver and Legal Hold ............................................................................... 31
2.6 Microsoft SharePoint iDA ................................................................................................... 31
2.7 SAP iDA .............................................................................................................................. 32
2.7.1 SAP Backup and Recovery ......................................................................................... 32
2.7.2 SAP Archive Management .......................................................................................... 33
2.8 NAS iDA.............................................................................................................................. 34
2.8.1 NAS Backup ............................................................................................................... 34
2.8.2 NAS Data Archiver ..................................................................................................... 34
Setting NAS archiving ............................................................................................ 34
2.9 DB2 iDA .............................................................................................................................. 36
3 Virtual Server Agent............................................................................................. 37
3.1 VMware Data Protection...................................................................................................... 37
3.2 MS Hyper-V Data Protection ............................................................................................... 38
3.3 SnapProtect for Virtual Server Agent ................................................................................... 40
4 SnapProtect............................................................................................................. 41
5 Continuous Data Replicator ............................................................................... 43
5.1 Recovery Management Layer .............................................................................................. 43
5.2 Role of the CDR on the Recovery Layer ............................................................................. 44
5.3 CDR Process ........................................................................................................................ 44
5.4 Copy Modes ......................................................................................................................... 44
One-to-one copy ....................................................................................................... 45
Multiple-to-one copy ............................................................................................... 45
One-to-multiple copy .............................................................................................. 45
5.5 Data Protection for Multiple Remote Offices and Data Centers .......................................... 46
5.6 Cost-Effective Disaster Recovery ........................................................................................ 47
5.7 Troubleshooting Method for Network Interruptions ............................................................ 47
5.8 Maximized Use of the Available Network Bandwidth ......................................................... 48
5.9 Integrated Management with the Copy Function ................................................................. 49
5.10 Conclusions ........................................................................................................................ 49
6 Other Technical Features ..................................................................................... 51
6.1 Smart Clients ........................................................................................................................ 52
6.2 Synthetic Full Backup .......................................................................................................... 52
6.3 Auxiliary Copy ..................................................................................................................... 53
6.4 Storage Policies .................................................................................................................... 54
6.5 Granular Restores ................................................................................................................. 55
6.6 Restart/Checkpoint ............................................................................................................... 55
6.7 GridStor ............................................................................................................................... 55
2014-11-18 Copyright © Huawei Page 4 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana
6.8 Data Verification .................................................................................................................. 56
6.9 Content Index ....................................................................................................................... 56
6.10 Media Remote Storage ....................................................................................................... 57
6.10.1 Auxiliary Copy.......................................................................................................... 57
6.10.2 Magnetic Tape Outbound Storage ............................................................................. 58
6.11 Image-Level Backup .......................................................................................................... 59
6.12 Deduplication ..................................................................................................................... 59
6.13 Global Deduplication ......................................................................................................... 61
6.14 DASH Copy ....................................................................................................................... 61
6.15 DASH Full ......................................................................................................................... 62
2014-11-18 Copyright © Huawei Page 5 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana :
Figures
Figure 2-1 .................................................................................................................................. 13
Figure 2-2 .................................................................................................................................. 14
Figure 2-3 .................................................................................................................................. 14
Figure 2-4 .................................................................................................................................. 15
Figure 2-5 .................................................................................................................................. 15
Figure 2-6 .................................................................................................................................. 15
Figure 2-7 .................................................................................................................................. 16
Figure 2-8 .................................................................................................................................. 16
Figure 2-9 .................................................................................................................................. 16
Figure 2-10 ................................................................................................................................ 17
Figure 2-11 ................................................................................................................................ 17
Figure 2-12 ................................................................................................................................ 17
Figure 2-13 ................................................................................................................................ 18
Figure 2-14 ................................................................................................................................ 18
Figure 2-15 ................................................................................................................................ 18
Figure 2-16 ................................................................................................................................ 18
Figure 2-17 ................................................................................................................................ 19
Figure 2-18 ................................................................................................................................ 19
Figure 2-19 ................................................................................................................................ 20
Figure 2-20 ................................................................................................................................ 20
Figure 2-21 ................................................................................................................................ 20
Figure 2-22 ................................................................................................................................ 21
Figure 2-23 ................................................................................................................................ 23
Figure 2-24 ................................................................................................................................ 25
Figure 2-25 ................................................................................................................................ 26
2014-11-18 Copyright © Huawei Page 6 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana
Figure 2-26 ................................................................................................................................ 26
Figure 2-27 ................................................................................................................................ 27
Figure 2-28 ................................................................................................................................ 28
Figure 2-29 ................................................................................................................................ 28
Figure 2-30 ................................................................................................................................ 29
Figure 2-31 ................................................................................................................................ 29
Figure 2-32 ................................................................................................................................ 30
Figure 2-33 ................................................................................................................................ 35
Figure 2-34 ................................................................................................................................ 35
Figure 2-35 ................................................................................................................................ 36
Figure 5-1 .................................................................................................................................. 45
Figure 5-2 .................................................................................................................................. 45
Figure 5-3 .................................................................................................................................. 45
Figure 5-4 .................................................................................................................................. 46
Figure 6-1 .................................................................................................................................. 51
Figure 6-2 .................................................................................................................................. 52
Figure 6-3 .................................................................................................................................. 53
Figure 6-4 .................................................................................................................................. 54
Figure 6-5 .................................................................................................................................. 55
Figure 6-6 GridStor — sharing storage devices and data directory .......................................... 56
2014-11-18 Copyright © Huawei Page 7 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana :
Tables
Table 2-1 .................................................................................................................................... 25
2014-11-18 Copyright © Huawei Page 8 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana :
1 Software Architecture
1.1 CommServe Server
The CommServe server is a backup management server. It is connected to a
local area network (LAN). As the core of the backup domain, it performs all
configurations and settings.
CommVault Simpana uses this server to control the entire data management
system, maintain all configuration data (of clients, media and agents, and
backup devices), control the recording of all activities and historical tasks, and
provide graphical user interfaces (GUIs) and web interfaces.
1.2 MediaAgent Server
MediaAgent is a software module. It transmits data between a physical
storage device and the corresponding client agent. MediaAgent manages
backup devices and saves data and data indexes to a storage medium. It
supports various storage system structures. Therefore, it can quickly adapt to
the changing in storage technologies. Simpana MediaAgent supports the
following types of storage media:
Disks: The Bunch Of Disks (JBOD) and Redundant Arrays of
Inexpensive Disks (RAID) technologies can be adopted.
Intelligent disk arrays: High-end disk arrays (such as EMC Symmetrix,
HP StorageWorks, HDS Lightning, or XIOtech Magnitude) provide the
snapshot or remote copy functions. CommVault has passed the Volume
Shadow Service (VSS) certification of Microsoft Windows Storage
Server 2003.
Automatic tape library: MediaAgent supports typical tape libraries with
mechanical hands, multiple tape slots, and multiple tape drives. It can
manage tape slots, drives, and mechanical hands.
Independent tape drive: MediaAgent can manage independent tape drives.
Tapes are manually inserted or removed.
MO library with barcodes: Jukeboxes.
Media without barcodes
Each MediaAgent can transmit various types of data. It can perform multiple
backup and recovery, data migration, legal archiving, and quick recovery
2014-11-18 Copyright © Huawei Page 9 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana
operations. This allows various data transmission tasks to share expensive
high-performance storage devices smoothly.
The production servers that are connected to the storage area network (SAN)
are also connected to the LAN. LAN-free backup of these servers and LAN
backup of the servers on other LANs can be performed. After grid storage is
configured, MediaAgent provides the switchover function. If a network or
MediaAgent server becomes faulty during backup, the backup operations can
be switched automatically to another MediaAgent server.
1.3 iDA
iDA is used for backing up and restoring file systems. It provides the
resumable transmission function. When a network or MediaAgent server
becomes faulty, another MediaAgent server will take over the services at the
breakpoint and send the data to the backup media.
If iDA and MediaAgent are installed on one server, LAN-free backup is
supported.
1.4 CTE
CommVault supports integrated data management. Its core is the underlying
software Common Technology Engine (CTE). As the backbone in the
Simpana architecture, the CTE enables independent products to interact and
communicate with each other. This allows various independent applications to
automatically interact and communicate with each other. These applications
include the following modules: backup and recovery, data migration, legal
archiving, quick recovery, storage resource management, and SAN
management.
Unlike traditional software, each CommVault module is an independent
solution. Each CommVault module must use the CTE. These modules share
the CTE. An integrated console is provided, on which centralized policies can
be created for accomplishing data management operations through each
module. The integrated automatic process is very efficient. The administrator
can quickly detect problems and discover solutions to the problems. For
example, the data migration module is requested to transfer data to a
secondary storage medium as soon as the data volume in the primary storage
medium is detected to have reached the alarming level. The data migration
continues until the data volume in the primary storage medium falls below the
alarming level.
1.5 Distributed Indexing Mechanism — Soul of
Data Management Software
All data management software modules (including backup and recovery and
data migration) generate internal indexes and searches data by index. An
index is a piece of data that records the following information: data name, size,
owner, save path, and storage duration. It is used to search for the backup data
during recovery. Indexes are the key to data recovery. If indexes are lost, the
2014-11-18 Copyright © Huawei Page 10 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana
software will break down. Generally, an index consists of dozens of bytes.
When the host quantity and data volume are limited, the importance of
indexes is not manifested. When a large number of hosts are involved, a great
deal of data needs to be managed, longer storage duration is required, and the
index quantity is huge, the organization and management of indexes
determine the running and extensibility performance of the software. In the
coming sections, CommVault and traditional software are compared in terms
of the indexing mechanism, which shows that the indexing mechanism of
CommVault is more applicable to enterprises.
Traditional software adopts a single centralized indexing system.
The index information is stored on the management server. To save or
obtain the index information, users need to access the management server.
As the data volume increases, the management server has become the
bottleneck of the entire system (CPU/memory/disk/network), which
restricts the flexibility and expansibility of the system.
The indexes and folders are backed up each time the data is backed up.
As the amount of indexes grows, this backup takes longer time than a
normal backup task. As a result, the running of the production system is
affected.
The indexes and folders are composed of binary files, which are difficult
to be searched, backed up, or recovered.
When the centralized indexing system is adopted, the amount of indexes
grows rapidly to hundreds of megabytes. If the indexes are lost, it usually
takes several days or even a week to recover them.
Each module (such as backup, data migration, or snapshot) adopts an
independent indexing mechanism. It is very complex to manage and
maintain these indexing systems, and large quantities of manual O&M
operations are required. In this case, the software cannot provide even
basic services, let alone extended functions.
CommVault adopts a unified distributed indexing system.
Indexes are hierarchically managed by CommServe and MediaAgent.
− MediaAgent manages tier-1 indexes, and CommServe manages tier-2
indexes.
− Tier-1 indexes and backup data are stored in the same backup
medium.
There is no need to back up tier-1 indexes, and the indexes can be
quickly recovered when an exception occurs.
− MediaAgent keeps a cache to manage tier-1 indexes.
− A tier-1 index contains the location of the backup data in the backup
medium.
Random tape reading and writing
Small backup and recovery granularity
− Tier-2 indexes are managed by the database of CommServe, which
facilitates data search, backup, and recovery.
− It greatly enhances the flexibility and extensibility of the system.
Backup and data migration adopt a unified indexing mechanism, which
is simple to manage and maintain and provides high technical reusability
and flexible extended functions.
2014-11-18 Copyright © Huawei Page 11 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana :
2 iDA
2.1 File System iDA
2.1.1 Backup and Recovery Module of the File System
The file system iDA of CommVault provides centralized data protection and
recovery for unstructured files, such as Windows, Unix, Linux, NetWare, and
Mac files. It provides options for deleting redundant data, managing
operations, and generating advanced reports, which allows simpler backup,
recovery, and search of data in a file system.
The file system iDA has the following technical characteristics:
Simple data management: The file system iDA provides the simple data
backup and recovery function. Automatic backup policies can be
customized on a centralized graphic console.
Point-in-time recovery: When a system-level fault occurs, the file system
iDA supports quick point-in-time data recovery.
Redundant data block deletion: In cooperation with the redundant data
deletion module, CommVault can delete redundant data blocks during
file transfer to reduce the backup window and save storage space.
2.1.2 Data archiver of the File System
Storage space management focuses on unstructured files that occupy a large
part of the storage space but are seldom accessed.
As more service data is generated, large quantities of local primary hard disks
are required if the traditional online storage mode is adopted. It leads to more
investment and complex management. Most data (such as videos and old data
on the file server) in the disks is seldom accessed but still occupies disk space
and wastes investment. In this case, storage tiering can be adopted to ensure
the balance between performance and price.
CommVault provides the storage tiering function. It can store most of the data
that is seldom accessed in an offline medium (such as a SATA disk array, tape
library, or CD-ROM library) and only a small amount of data that is relatively
frequently accessed in the primary storage medium. When the data stored in
an offline medium is accessed, the system automatically sends the data to the
primary storage medium. Similarly, the system can automatically move the
data that is not accessed for a long period of time from the primary storage
2014-11-18 Copyright © Huawei Page 12 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana
medium to an offline medium. This can reduce the investment and
management cost.
2.2 Oracle iDA
The Oracle iDA of CommVault Simpana provides a simple end-to-end backup
and recovery solution for Oracle data. It allows users to perform full backup
and recovery of the entire Oracle database, backup and recovery of single data
files or table spaces, or backup of archived logs and point-in-time recovery.
CommVault Simpana adopts the SnapProtect technology for backing up
Oracle databases. Based on the snapshot and clone technologies of
mainstream storage disk arrays, a point-in-time snapshot and recovery
mechanism is provided on the management GUI of CommVault Simpana.
2.2.1 Backing up an Oracle Database
The prerequisite for Oracle Recovery Manager (RMAN) backup is as follows:
The database is running in ARCHIVELOG mode.
The Oracle backup is a graphic operation process. The operations are simple
and do not involve large quantities of scripts. The basic procedure is as
follows:
Create an Oracle backup instance.
Figure 2-1
Select the data to be backed up (entire database or a table space) and
storage policy.
2014-11-18 Copyright © Huawei Page 13 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana
Figure 2-2
Figure 2-3
After the database NoCatalog is backed up, run the control file backup script. Then,
the database can be recovered even if the control file is damaged. If the control file is
backed up in script mode on the local computer, it is necessary to back up it in file
mode to a storage device. Therefore, a file backup set needs to be added.
After the backup instance is created, start the backup manually or
perform the backup as planned.
2014-11-18 Copyright © Huawei Page 14 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana
Figure 2-4
Figure 2-5
The backup progress is displayed in the console window. Users can
double-click an activity to view details and the RMAN logs.
Figure 2-6
2014-11-18 Copyright © Huawei Page 15 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana
Figure 2-7
After the Oracle database is backed up, CommVault can automatically
initiate backup of the control file to ensure time consistency between the
backups.
Figure 2-8
Figure 2-9
2014-11-18 Copyright © Huawei Page 16 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana
Figure 2-10
2.2.2 Recovering the Oracle Database
On the CommVault GUI, users can invoke the RMAN to recover an Oracle
database and perform inter-computer recovery. The specific procedure is as
follows:
Recover the control file to the destination computer.
Figure 2-11
Select the control file to be recovered.
Figure 2-12
Specify the destination computer.
2014-11-18 Copyright © Huawei Page 17 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana
Figure 2-13
Recover the control file.
Figure 2-14
Figure 2-15
Rename the recovered control file according to the standard in the
SPFILESID.ORA file on the destination server, and make three copies of the
file.
Figure 2-16
2014-11-18 Copyright © Huawei Page 18 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana
Recover the database file. Before the recovery, switch the database to
MOUNT state.
Figure 2-17
Initiate recovery on the CommVault console.
Figure 2-18
Select the destination computer and contents to be recovered.
2014-11-18 Copyright © Huawei Page 19 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana
Figure 2-19
The recovery progress is displayed in the console window. Users can
double-click an activity to view details and the RMAN logs.
Figure 2-20
Figure 2-21
2014-11-18 Copyright © Huawei Page 20 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana
Figure 2-22
Run the following command on the SQL*Plus of the destination computer.
recover database using backup controlfile until cancel;",
Type CANCEL after Specify log.
Run the alter database open resetlogs; command to rebuild the redolog and
open the database.
After the preceding operations are performed, the inter-computer Oracle
recovery is complete. The database has been started on the destination
computer.
2.3 Microsoft SQL Server iDA
Before using CommVault to back up or recover the SQL Server, users must
have an understanding of the common backup and recovery concepts of the
SQL Server.
2.3.1 SQL Server Transaction Log and Automatic
Recovery
The SQL Server transaction log refers to the recording of database changing.
All operations on a database can be recorded and saved as independent files.
Each transaction is recorded in detail in the transaction log. Users can restore
a data file to a previous state based on the log. The transaction logging begins
when a transaction starts. Any operation on a database during the transaction
process is recorded. The logging does not stop until users click Commit or
Rollback. Each database has at least a transaction log and a data file.
Microsoft SQL Server checks each database in the system at each start to
perform automatic recovery. It checks the master database first, and then starts
a thread to cover all databases in the system. The automatic recovery
mechanism checks the transaction log of ach SQL Server database. If a
transaction log contains any incomplete transaction, the transaction will be
rolled back. Then, the automatic recovery mechanism checks the transaction
log to locate the incomplete transactions that are not written into the database.
If any incomplete transaction is found, the transaction will be completed and
rolled forward.
The SQL Server transaction log combines the Oracle rollback segment and
online Oracle redo log functions. Every database has its own transaction log,
which records all changes of the database. The log is shared by all users of the
database. After a transaction begins and a data change is made, a BEGIN
2014-11-18 Copyright © Huawei Page 21 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana
TRANSACTION event (similar to the modification event) is recorded in the
log. This event is used for determining the start of the transaction during
automatic recovery. When a data modification event is received, the change is
recorded in the transaction log and written preferentially into the database.
2.3.2 Backup of the SQL Server Database
Microsoft SQL Server provides the following data backup modes:
Full backup
Differential backup: After a full backup of the database is performed, the
system periodically uses BACKUP DATABASE WITH
DIFFERENTIAL to back up changed data and indexes.
Transaction log backup: The part of the transaction log that is not needed
will be removed during the backup. An independent file group is
provided for the transaction log of Microsoft SQL Server. This file group
can be repeatedly added during backup or after being deleted. By default,
the SQL Server transaction log increases automatically until it uses up all
available space or reaches a preset limit. When the transaction log uses
up all available space or reaches the preset limit, an error occurs, and no
data modification is allowed until the log is backed up or deleted.
File or file group backup: The SQL Server can back up data files or data
file groups.
Backup can be performed when a database is being used. In this way, the
systems whose running cannot be interrupted can be backed up. The
transaction log backup data or differential backup data can be saved to a full
backup in point-in-time mode. The backup data can be used to recover the
data of the database.
Users can stop the Oracle archiver to skip backup. Similarly, members of the
user group db_owner can forcibly remove folders from the transaction log in
point-in-time mode. This process can be accomplished by using the SQL
Server Enterprise Manager (deleting the transaction log in point-in-time
mode), Transact-SQL (sp_dboption storage process), or SQL-DMO.
2.3.3 Recovery of the SQL Server Database
A database can be restored to a previous state by using the transaction log
backup. The transaction log backup, however, cannot recover the database by
itself. It needs the cooperation of the database file that has been backed up.
Before the database recovery, the data file must be recovered. Before the
entire data file is completely recovered, users must not set it to be finished.
Otherwise, the transaction log cannot be recovered. When the data file is
completely recovered, the system restores the database to the expected state
based on the transaction log backup. If multiple transaction log backups exist
after the last backup of the database, the system will recover the transaction
logs one by one according to their creation time.
2.3.4 Characteristics of the SQL Server iDA
CommVault invokes the virtual device interface (VDI) of the SQL to back up
and recover the SQL server. In the GUI, users can select a server, type the user,
account, and password, and select the backup policy and medium server. The
SQL Server iDA has the following characteristics:
2014-11-18 Copyright © Huawei Page 22 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana
High performance
The MSDN API is used for performing online backup and recovery. This
allows databases to be protected at any time.
The VDI provides faster data transmission during backup and recovery.
It is seamlessly integrated with the slice function of the SQL. It can write
multiple data flows into multiple tape drives, speeding up the backup.
Multiple database backup and recovery processes can be performed
simultaneously. This reduces the requirements for system resources and
backup windows.
LAN-free backup by using the built-in sharing storage is supported.
Users can select databases and perform inter-computer recovery and
point-in-time recovery.
High reliability
The automatic hot disaster recovery policy can reduce the breakdown
time due to data damage and hardware fault.
The resumable backup function can reduce the backup time and ensure
the completion of data protection operations.
Various recovery modes (such as point-in-time recovery and gradual
database recovery) are supported to quickly locate the scope of data loss.
New SQL databases can be automatically discovered during backup. This
ensures that new data can be protected.
Ease of use
An integrated GUI and wizard ensure quick deployment and convenient
management.
Access control and security policies can be configured. Node table (NT),
Exchange, and SQL user groups can be created. Operation rights can be
authorized. Operation rights of unauthorized user groups can be
automatically restricted.
Unified event monitoring and observing is provided. Events can be
filtered.
Figure 2-23
2014-11-18 Copyright © Huawei Page 23 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana
Import scripts can be invoked in a recovery plan to perform automatic
recovery.
If an import script is embedded in the recovery task, the system automatically
runs the import script to recover the database after the backup file is recovered.
The entire process is automatic and does not need any manual intervention.
2.4 Microsoft Exchange iDA
2.4.1 Backup and Recovery of the Exchange
The Exchange backup and recovery agent of CommVault can be integrated
with the Exchange through the Messaging Application Programming Interface
(MAPI) to protect storage groups, information stores, mailboxes, public
folders, and web folders. It can also recover single contact items, calendar
items, tasks, and emails by small granularity. It provides the single instance
storage (SIS) backup function to capture the actual target storage of the
Exchange, which is rapider and reduces storage space usage than traditional
full backup. In cooperation with the backup agent of the Windows file system,
it can provide unified protection for the entire Exchange environment.
In terms of Exchange protection, CommVault has the following advantages:
A simple unified GUI is provided.
The data availability is maximized. Emails, attachments, public folders,
web folders, and their contents can be recovered by small granularity.
The Exchange database and system can be quickly recovered.
The VSS and Exchange 2003, Exchange 2007, or Exchange 2010 can be
transparently integrated.
The data protection, archiving, copy, and snapshot functions can
conveniently invoked, and a unified administration console is provided.
The major functions of CommVault are as follows:
Ease of use: CommVault is easy to install, configure, manage, and learn.
Web-based browsing management: It can manage the Exchange data at
any position across the networks that are accessible by web.
Reliable recovery: The Microsoft IT team in Redmond has been using
CommVault to manage the Exchange data during Exchange and Office
R&D processes since 1999. Many internal departments of Microsoft also
use it to protect the Exchange data, such as DogFoodLab, the largest
Microsoft Exchange R&D laboratory.
Integration with Microsoft Cutting-Edge: CommVault can speed up the
upgrade of the Windows system where the Exchange system belongs and
restore the data of the source version to the target version.
Hybrid environment: CommVault supports the hybrid Windows
environment that consists of new and old software versions, which
facilitates deployment and upgrade and extends the life-cycle of old
systems.
Automatic discovery: By protecting active directories, the automatic
mailbox discovery function of CommVault is extended. After users are
added to the user group AD, CommVault can automatically discover and
protect their Exchange mailboxes.
2014-11-18 Copyright © Huawei Page 24 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana
The Exchange backup modes are as follows:
Table 2-1
Data Type Description Backup Type
Database Information storage Full backup
Organizational structure of Differential backup
the Exchange
Shared documentation of
the Exchange
Log files and patches
Public folders All public folders Full backup
Emails or other files in the Incremental backup
folders Synthetic full backup
Attachments
Web folders All web folders Full backup
Emails or other files in the Incremental backup
folders Synthetic full backup
Attachments
Emails Mailboxes of all users Full backup
Folders in the mailboxes Incremental backup
Files in the folders Synthetic full backup
Attachments
CommVault provides the following Exchange recovery functions:
CommVault provides a GUI for recovering the Exchange data in various
modes.
It can recover an entire Exchange server and its information storage, including
private storage, public storage, storage groups, and transaction log. This
ensures quick recovery of the Exchange system when a disaster occurs.
The following figures shows the recovery of the entire Exchange system:
Figure 2-24
CommVault provides online data recovery by small granularity. It can recover
single emails, contact items, calendar items, and notes. Users can browse all
2014-11-18 Copyright © Huawei Page 25 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana
mails and folders protected by CommVault conveniently without knowing
their corresponding mailbox or storage group. This avoids endless scanning of
tape sets. Inter-mailbox recovery is supported. By using the ranking and
search functions, users can rank and search information by sender, recipient,
date, and topic.
Figure 2-25
In the CommVault environment, each individual Outlook user can
independently recover the mailbox data that has been backed up. CommVault
provides the ADD-IN module for Outlook users. This easy-to-use module
reduces the workload of Exchange system administrators.
Figure 2-26
2.4.2 Exchange Data Archiver
Email data has a life-cycle. Its meaning varies at different periods. When the
data is just generated, it is most frequently accessed and brings most benefits
to enterprises. As time goes by, the frequency of access and benefits fall. The
data volume that is seldom accessed is much more than the data that is
frequently accessed. The mailbox of each user has a limited capacity, which
cannot store all emails. An enterprise cannot afford the cost to expand storage
devices to store all email data, which is irrational in terms of IT development.
The frequency of access of email data falls gradually from generation to
storage, use, archiving, and deletion. To improve the usage of storage devices
and reduce the storage cost, the storage position of email data also changes
2014-11-18 Copyright © Huawei Page 26 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana
along with the frequency of access. CommVault adopts the storage tiering
mechanism. To ensure data availability, key email data is stored by using
expensive storage technologies and modes, such as RAID disk array, copy,
scheduled copy, and hierarchical backup. When the email data cannot bring
benefits for the enterprise any more, the data will be moved to a less
expensive storage medium. When the email data is not accessed any more, it
will be deleted or moved. If the email data is required by law or governmental
regulations to be stored for many years, it will be moved to a nearline or
offline storage medium to be archived, which is safe and cost-effective.
The tiering storage mechanism can meet the requirement of customers for
minimized storage cost. The specific advantages are as follows:
Minimized total storage cost: The data that is seldom accessed is stored
in a less expensive storage medium. In this way, the performance
advantage of disks and the cost advantage of tapes are combined.
Optimal performance: Tiering storage of email data maximizes the
advantages of different types of storage devices.
Improved data availability: In tiering storage mode, the historical data
that is seldom used is moved to an auxiliary storage device or archived to
an offline storage pool. In this way, the data does not need to be saved
repeatedly, and the save time is reduced. This improves the availability of
the online data. The available space in disks can be maintained above the
level required by the system.
Transparent data migration to applications: After the tiering storage
mechanism is adopted, the header of an email is stored on the source
storage device when the email is moved to another storage device. This
allows users to access the email without changing the access mode and
data migration to be transparent to applications.
Emails can be archived by preset rules, for example, by the quota of each
mailbox.
Figure 2-27
Emails can also be archived by their attributes.
2014-11-18 Copyright © Huawei Page 27 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana
Figure 2-28
After emails are moved, users can view the following information in the
personal Outlook window.
Figure 2-29
The icon of each email has been changed into the CommVault icon and
marked with ARCHIVED, indicating that the body and attachments of the
email have been moved to a secondary storage medium. To access this data,
users can double-click the email. CommVault will automatically recover the
email.
In the Outlook window, an individual user can delete the header information
of the archived emails that are seldom used. When the user finds that such an
email is still useful, the email cannot be recovered since the header
information of the email has been deleted. In this case, the user can use the
ADD-IN module provided by CommVault for Outlook to search and recover
the data. The GUI for this function is the same as that for searching backup
data of mailboxes.
2014-11-18 Copyright © Huawei Page 28 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana
Figure 2-30
User authorities are involved when this recovery mode is adopted.
CommVault can perfectly combine the recovery and search rights and active
directory rights of users to prevent data loss.
Figure 2-31
2.4.3 Legal Hold of the Exchange
CommVault adopts the log mechanism of the Exchange database to meet legal
hold requirements. After the log mechanism is adopted, any email that comes
to or leaves the Exchange server will be copied to a specified mailbox. This
allows all emails to be managed and monitored but has no impact on
individuals. Individual users can continue to receive, delete, and archive
emails without changing habits.
In this mode, the mailbox that stores all emails increases unlimitedly, which
uses large a large deal of storage resources and affects the performance of the
Exchange server. CommVault can move emails from the mailbox to keep the
size of the mailbox below an acceptable level and reduce the load of the
Exchange server.
2014-11-18 Copyright © Huawei Page 29 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana
Figure 2-32
CommVault can automatically scan Exchange mailboxes to locate the mailbox
that adopts the log mechanism, which can reduce the configuration difficulties
for email server administrators. After the emails in the log mailbox are
successfully archived, the emails can be deleted to save mailbox space.
2.5 IBM Lotus Domino iDA
CommVault Simpana provides various modular solutions for IBM Lotus
Domino data management.
The Domino database backup protects mailbox data.
The data archiver for the Domino mailbox system controls the growth
and cost of the primary storage medium.
The data archiver for Domino legal hold can be associated with the email
log function of the Domino system to archive all emails and attachments
that comes to or leaves a mailbox.
Singly or in cooperation with other functions, the Lotus Domino data agent
provided by CommVault Simpana can protect the Domino data, control the
growth of Domino data, reduce cost, and detect and manage the risks that
result from non-compliance with laws or regulations. The data archiver
provides services for the terminal users, administrators, and regulation
compliance check team. It helps the email system maintain high performance
with increasing data volume.
2.5.1 Domino Backup
The iDA provides two backup and recovery modes for Lotus Domino:
Lotus Domino database backup and recovery
Lotus Domino document backup and recovery
The Lotus Domino Server iDA can protect Domino databases, including:
Lotus Domino database of the FAT file system
Lotus Domino database of the NT file system
2014-11-18 Copyright © Huawei Page 30 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana
Domino transaction log (if the transaction log function is enabled)
All Notes databases and templates
The Lotus Domino Server iDA can protect Domino databases, including:
Back up single or all Domino mailboxes and emails.
Recover single or all Domino mailboxes and emails.
Back up and recover database logs or non-log templates.
2.5.2 Domino Archiver and Legal Hold
CommVault provides the Domino archiver to help users comply with laws and
regulations, prepare e-Discovery, improve the Domino server performance,
reduce NSF problems, and cancel restrictions on mailbox quotas and
information capacity.
Large quantities of important emails need to be stored in the Domino server
for a long period of time. These emails are seldom accessed. They occupy
much of the space of the primary storage medium, affects the system
performance, and leads to increasing backup data and insufficiency in backup
windows. The data archiver provided by CommVault provides tiering
management of Notes emails.
As a hierarchical storage management (HSM) solution, the email archiver can
archive emails to a secondary storage medium to release the space in the
primary storage medium. When a user wants to access these emails, the
system automatically recovers the data from the secondary storage medium to
the primary storage medium. By configuring policies for selecting,
transferring, and retaining constant data, enterprises can obtain huge benefits
in terms of economy and productivity. Old emails are stored in a hierarchical
architecture (consisting of primary and secondary disk arrays and tapes). This
architecture can efficiently cope with the rapid increase in emails. The archive
mechanism is transparent. The archived data can be recovered directly to the
original storage position. Users can access the data at any time. System
administrators do not need to undergo expensive trainings to understand the
mechanism. Segmented physical transmission or folder maintenance within
the life-cycle of the data is not involved. Administrators can maintain the
efficiency of the primary storage medium. The tiering storage mechanism
reduces the cost of data storage and access.
The legal hold module of CommVault can archive Notes emails in compliance
with the related laws or regulations. In legal hold mode, all sent or received
emails will be archived to a safe storage library.
2.6 Microsoft SharePoint iDA
The integrated information management® solution of CommVault provides
high-performance data management, activity archiving, backup and recovery,
redundant data deletion, and search for enterprises in compliance with related
laws and regulations. CommVault has enhanced the Microsoft SharePoint
management. It uses Microsoft® FAST to invoke data based on contents. It
also makes use of the advantages of the 64-bit Windows ServerTM
environment where SharePoint belongs.
It can search the online, nearline, and offline data within the enterprise
by using Microsoft FAST.
2014-11-18 Copyright © Huawei Page 31 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana
It is integrated with the SharePoint Search Index.
It provides archiving, data migration, recovery, and copy functions that
are independent of versions.
It provides OnePass backup and archiving.
Data can be archived by document size, time, and version. This allows
SharePoint database operations to be performed more quickly and neatly
and users to invoke any or all versions of a document.
Interrupted backup and recovery, archiving, and reclaiming can be
resumed from the breakpoint.
It is seamlessly integrated with the onsite or hosted SharePoint versions.
Integrated disaster recovery and application recovery can be performed
by small granularity.
It is integrated with CommVault SnapProtect and VSS.
It is seamlessly integrated with the Azure and other cloud storage
platforms.
Redundant data deletion and SIS are supported..
Redundant client data can be deleted. Delete the redundant data before
data migration.
It can perform search in Microsoft® Exchange, SharePoint, Microsoft®
LyncTM, Windows, and heterogeneous data simultaneously.
Data can be automatically imported to the SharePoint Records Center.
It provides data management for SharePoint and the Windows server
where the SharePoint belongs.
CommVault Simpana provides a browser-based GUI for Hyper-V data
management. Users and administrators can perform micro data management
to control data growth and storage cost.
As each CommVault version is independent, users can quickly install or
upgrade them to Office Server 2010 or various SharePoint 2010 versions
(enterprise, standard, and basic). CommVault provides small-granularity
management (backup, archiving, and recovery) for various SharePoint items
(such as sites, documents, lists, ASPX pages, templates, and contacts). This
allows users to manage all versions of various SharePoint items.
2.7 SAP iDA
The integrated platform provided by CommVault for SAP has passed the
NetWeaver certification. This platform provides extensible end-to-end data
protection and management functions.
2.7.1 SAP Backup and Recovery
SIMAPNA provides backup and recovery functions for SAP R3 and
NetWeaver, which can help the customer face various challenges (such as
powerful extensibility and quick data protection) to reduce risks and cost. This
solution integrates the SAP seamlessly and safely into a cloud platform for
cost-effective and reliable SAP operations.
2014-11-18 Copyright © Huawei Page 32 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana
It uses the SnapProtect technology to provide quick data management
and protection for large-scale SAP environments. Backup and recovery
in this case takes only a few minutes.
It supports various sophisticated databases (MaxDB, Oracle, DB2, and
MS SQL Server) that can be used in cooperation with the SAP to protect
the data in underlying databases.
It can use the SAP GUI to provide all features and functions through the
integrated SAP BACKINT, BAPI, and certified support services.
It provides the function of recovering data in point-in-time mode. In
cooperation with the simplified automatic log reclaiming function for
SAP databases, it can protect service processes and transactions and
prevent system breakdowns.
The audit-ready report provides complete data for enterprises to comply
with related laws and regulations.
The built-in redundant source and destination data deletion function can
delete all manageable data related to the SAP from disks, tapes, and
cloud systems to reduce storage time, storage size, and cost.
Real-time copy of systems and sites allows centralized disaster recovery
and management of SAP data and systems.
The seamless integration with cloud platforms provides new approaches
to SAP data management and an efficient method for reliable protection
of the SAP environment.
2.7.2 SAP Archive Management
The rapid growth of the SAP environment leads to the deterioration of the
overall performance and response time, which has impacts on service
processing and enterprise revenues. The SAP data archiving solution provided
by CommVault can help customers move the SAP data reliably, efficiently,
and economically to any storage device or cloud system to maintain the high
performance of the SAP deployment.
The automatic indexing and cataloging of SAP documents and
transaction data allows users to quickly search information during
lawsuits or legal hold.
The legal hold and e-discovery functions help customers integrate the
SAP and non-SAP data into an reviewable platform.
CommVault is completely integrated with the SAP ArchiveLink interface,
which has passed the related certification.
The SAP data archiving solution is an organic component of CommVault
integrated data management and protection platform. It provides
all-round protection (such as backup, recovery, and archiving) for SAP
and non-SAP environments.
The virtual storage pool management function allows data and
information to be archived to any disk or tape, which reduces the
complexity and cost of storage.
The data protection and management of SAP and non-SAP systems is
unified. This reduces the total ownership cost, resource cost, and various
risks caused by independent solutions.
2014-11-18 Copyright © Huawei Page 33 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana
2.8 NAS iDA
2.8.1 NAS Backup
The network-attached storage (NAS) iDA of Simpana provides an end-to-end
data backup and recovery solution for NAS servers. It supports the following
mainstream NAS storage brands: NetAPP, HDS, and EMC.
The NAS iDA has the following characteristics:
Comprehensive backup and recovery capability: The NAS iDA provides
flexible data backup and recovery capability for NAS servers. Simpana
can invoke the Network Data Management Protocol (NDMP) provided
by the NAS server to perform full backup, incremental backup, and
differential backup. The data that is backed up can be restored to various
NAS servers or Windows file servers.
Point-in-time recovery: In the case of data loss, the NAS iDA provides
quick point-in-time data recovery.
Redundant data deletion: The NAS iDA provides the function of deleting
block-level redundant data and backing up the only NAS data block.
2.8.2 NAS Data Archiver
The NAS data archiver provides the data archiving, recovery, and online
reclaiming functions for mainstream NAS products (NetAPP, EMC, and HDS).
Period of storage, transparent reclaiming, and e-discovery can be set for the
archived data.
The NAS data archiver can move the NAS data from the primary storage
medium to a secondary storage medium or tape according to predefined rules.
This helps customers reduce the cost of the primary storage medium. The
tiering storage management mechanism can make use of the storage resources
of enterprises to the maximum degree.
Users can create headers for the archived files. By accessing headers, terminal
users can transparently reclaim the archived files without browsing or
recovering data from the GUI of a third-party application, no matter whether
the files are stored in a secondary storage medium or copied to tapes.
The NAS data archiver has the following Characteristics:
Reclaiming control: Users can configure the parameters of head files. For
example, users can set the maximum number of headers in a reclaiming
task. Once the number of headers in a reclaiming task reaches the upper
limit, the task needs to queue for the processing.
Point-in-time recovery: Users can recover multiple archived files
uniformly on the recovery GUI.
Clearance of headers: Users can set the period of storage for headers. The
system will automatically clear the overdue headers to release the storage
space.
Setting NAS archiving
2014-11-18 Copyright © Huawei Page 34 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana
Figure 2-33
Archive contents
Figure 2-34
NAS archiving rules
2014-11-18 Copyright © Huawei Page 35 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana
Figure 2-35
2.9 DB2 iDA
The DB2 iDA of CommVault Simpana provides online backup and recovery
for DB2 databases.
The DB2 iDA is one of the various iDAs provided by CommVault. It provides
a GUI for the online protection of DB2 systems, user libraries, historical files,
and log files.
2014-11-18 Copyright © Huawei Page 36 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana :
3 Virtual Server Agent
3.1 VMware Data Protection
The virtual server agent (VSA) of CommVault Simpana is located on a server
that is not the virtual server to be backed up. It can be a virtual server. In this
case, no local agent on virtual machines is required. The common VSA uses
built-in tools (VMware VADP and Microsoft VSS) of the virtual platform to
perform block-level incremental image backup, volume-level backup, and
file-level backup. Various recovery solutions are provided for each backup
type, including entire virtual machine backup and small-granularity backup
(such as single file backup). Inter-platform (between VMware and Microsoft)
recovery is also provided for data migration or test.
The vStorage API Data Protection (VADP) interface is a new backup interface
of VMware ESX 4 and later versions. Compared with the VMware
Consolidated Backup (VCB) method, it provides enhanced functions and
performance.
Besides locating problems in the current data environment, the revolutionary
data management solution of CommVault Simpana can also help users quickly
transit to the virtual and cloud environment of the future data center with
various technologies to enjoy the various benefits brought by the modern data
center.
CommVault Simpana provides the following advantages in terms of virtual
machine protection:
Hundreds of virtual machines can be protected within minutes without
affecting the physical production servers.
The built-in source/destination redundant data deletion function reduces
the backup data volume.
The consistency between the internal applications of virtual machines is
100% ensured.
Data recovery, search, and e-discovery can be performed by small
granularity.
All-round storage resource management is provided. The environment
and virtual architecture can be conveniently managed by detailed reports.
In a word, Simpana provides reliable data management. It can help users
switch quickly to the virtual machine environment.
2014-11-18 Copyright © Huawei Page 37 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana
3.2 MS Hyper-V Data Protection
The integrated data management® solution of CommVault considers the
Windows-based software as a whole and provides high-performance data
management, archiving, backup and recovery, redundant data deletion, and
search functions for Hyper-V and applications in the Hyper-V environment.
The VSA-Virtual Server Agent of CommVault enhances the Hyper-V and
increases the data volume managed by the virtual Windows server and virtual
machines. It can also invoke virtual data by using Microsoft® FAST. All
VMware data backed up or archived by CommVault can be recovered by the
entire server, volume, or file. CommVault can also help customers move
virtual machines from VMware to Hyper-V.
Single backup can be performed by server, volume, or file.
The data of all applications (Microsoft® Exchange, Microsoft®
SharePoint®, Microsoft® SQL ServerTM, and Active Directory®) in the
Hyper-V framework can be managed.
It is integrated with the VSS.
Automatic VMs discovery ensures that new servers are also protected.
The redundant data deletion function can release the storage space.
Data can be archived by document size, time, and version. This allows
SharePoint and Exchange database operations to be performed more
quickly and neatly and users to reclaim any or all versions of a
document.
It is seamlessly integrated with the Azure platform and adopts the tiering
storage mechanism.
Synthetic full backup can reduce the number of full backups and the total
requirement for storage resources.
Interrupted backup and recovery can be resumed from the breakpoint.
It is integrated with CommVault SnapProtect and VSS.
Synchronous data search can be performed in the Hyper-V, Exchange,
SharePoint, Microsoft® LyncTM, and Windows.
It can automatically send data to the SharePoint recording center.
It is seamlessly integrated with the Cluster Shared Volume (CSV).
It is integrated with the copy function of CommVault to meet the
requirement for high availability.
VMs can be easily cloned.
CommVault Simpana provides a browser-based GUI for enhanced Hyper-V
data management. Users and administrators can perform micro data
management to control data growth and storage cost.
CommVault provides the following enhanced functions for Hyper-V data
management:
It can back up, recover, move, archive, mine, search, and quick recover
emails, information, folders, contacts, calendar items, or the entire
SharePoint environment with Windows Server SystemTM by various
granularities.
The redundant data deletion and SIS functions greatly reduce the total
storage resources required for backing up and archiving data, including
storing the deleted data to the Azure and tapes.
2014-11-18 Copyright © Huawei Page 38 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana
FAST can used to search contents within an enterprise. Heterogeneous
search and SharePoint search are supported.
Active Directory and ADAM provides object and property management.
Users can use the Security Identifying Information (SID) to create
objects in the Windows server environment.
The VSA of CommVault supports the Hyper-VTM. Each VSA can serve
multiple VMs.
Simpana provides continuous data copying.
The HTTP server provides the random scheduling function, which
increases the transmitted data volume.
The SnapProtect technology provides the immediate snapshot function,
which can quickly recover servers and applications.
A web desktop console is provided for remote offline browsing.
A browser-based GUI is provided for global management.
Multiple languages are supported. Multiple languages are also supported
by Microsoft® Outlook for active archiving. This allows users to use
their native languages.
The operations for generating reports, including customizing reports, are
simple. The reports can be sent to mobile devices and the Microsoft®
system center.
Inter-server recovery is provided for moving small- or large-scale data
from one SharePoint environment to another.
SharePoint 2010 upgrade is sped up. Data can be safely obtained from
previous SharePoint versions.
The 64-bit optimization of CommVault ensures high system performance
and maximizes the advantages of the 64-bit server technology and 64-bit
Windows server software.
CommVault provides quota-based mailbox management. This function
allows users to manage old and useless emails by storing a certain
amount emails to a less expensive secondary storage medium (such as
the Windows storage server) to maintain a limited data volume in the
mailbox.
The offline data management is simple. Various storage medium types
(disks, SAN, NAS, tapes, magneto-optical disks, and DVDs) can be used
in hybrid mode.
It is integrated with the VSS for Exchange, SharePoint, and SQL data
management. The common requester function is provided for uniformly
processing snapshots by hardware or supplier without considering the
vendor.
Synthetic full backup can significantly reduce the number of full backups
and the number of required storage media.
It can be partially integrated with the web for obtaining files seamlessly
from a secondary or tertiary medium.
CommVault provides extensive professional services and support for
global customers. It supports quick installation and can be customized
according to the actual environment.
2014-11-18 Copyright © Huawei Page 39 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana
3.3 SnapProtect for Virtual Server Agent
In cooperation with the built-in snapshot engine of the storage medium, the
SnapProtect for Virtual Server Agent can quickly create recoverable data
copies for the datastore of virtual machines. These snapshots can also be used
for quick virtual recovery.
The SnapProtect for VSA and MediaAgent are deployed on a Windows
platform. If the VSA is deployed on a virtual machine, it is recommended that
the virtual machine run on an ESX server that is dedicated for backup to avoid
resource competition with other tasks. The ESX server dedicated for backup
can run on the ESXi version.
Each SnapProtect process is the same as that of standard backup. The
improvement is as follows: This process initiates a snapshot instead of
copying all data blocks immediately.
The specific process is as follows:
Automatically search and discover new virtual machines according to
predefined rules.
Quiesce the virtual machines to ensure the consistency between image
files.
Locate the datastore where the virtual machines to be backed up belongs.
Create the hardware snapshot of the storage system. This step takes a few
seconds, depending on the technology of the hardware vendor.
Unquiesce the virtual machines for them to run normally.
Generate indexes for the snapshots according to predefined rules.
As snapshot protection is created by using the SnapProtect technology, it takes
only a few minutes to protect the data. Quiescing virtual machines also takes
only a few seconds. This allows multiple data copies of virtual machines to be
generated with the minimized impact on the system. Better recovery can be
provided, and the recovery level is improved.
In the typical environment, a snapshot-based data copy is created every four to
eight hours, and one of them is selected at a certain time and saved to a
backup medium (a disk or tape).
The advantages are as follows:
Quick and reliable virtual data protection is provided, whose impact on
the system is minimized. More important systems can be virtualized,
resulting in high return on investment (ROI).
Usually, the VMware is the strategic choice, and the storage platform is
the technological choice. The SnapProtect for VSA is independent of the
storage system. It provides data management functions and methods for
various storage brands. More flexible technological choices are provided
for strategic decisions.
Multiple data copies are created every day. Data can be recovered from
the latest copy. Compared with data recovery from the backup at night, it
can effectively reduce the data loss volume.
The unified data management provided by Simpana can be easily
extended to cloud platforms. This allows other future data management
technologies to be used.
2014-11-18 Copyright © Huawei Page 40 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana :
4 SnapProtect
The SnapProtect technology provided by Simpana can recover billions of
bytes of key data within minutes.
Simpana SnapProtect™ is integrated with the quick and continuous
hardware-based snapshot function. It can protect the largest virtual and
physical server environment and meet the strictest data protection
requirements. It can recover the server environment within minutes. A quick
recovery copy can be created by creating an internal hardware snapshot copy
of the storage disk array. This has little impact on the production server.
Hundreds of systems and related applications can be protected within minutes.
When other solutions protect systems and applications through network,
CommVault is trying to capture the entire environment without affecting
production applications. To this end, the hardware-based snapshot technology
is adopted.
It can create recovery copies without moving any data. This can
minimize the load of the production server.
It can create multiple recovery points every day. This minimizes service
risks and improves the service level.
The protection and recovery function is independent of the underlying
hardware. Simpana can be used on any disk array hardware.
Applications and data can be easily recovered, no matter where they are
stored.
With the integrated CommVault, administrators do not need to create and
maintain scripts or manage various independent storage disk arrays,
technologies, or products. It simplifies the management, protection, and
recovery of the application data on each storage medium or tape layer without
affecting the production system.
Most advanced recovery functions
The recovery of single objects, single files, entire volumes, or entire
applications is performed on the Simpana administration console. In any of
the following scenarios, users do not need to install or run recovery scripts or
perform any manual operations: Microsoft Exchange, SQL Server, SAP,
Oracle, DB2, and SAP. Simpana SnapProtect will perform all the operations
automatically. Enabling object recovery in a database is as simple as selecting
a check box on the administration console. Users can enable the functions of
accessing the SharePoint documents and mailboxes and archiving emails by
using the SnapProtect.
2014-11-18 Copyright © Huawei Page 41 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana
Simpana is a practical tool. Users can browse their backup tasks, including the
tasks of virtual machines, physical servers, volumes, files, objects, and entire
applications, directly on the Simpana administration console.
Maximized ROI of storage systems and networks
The SnapProtect technology provides 7 x 24 protection for the tier-1, tier-2,
and tier-3 key tasks and service data with the investment in the high-speed
Ethernet and optical network and the high performance of storage disk arrays.
Free of constraints due to solutions
Many enterprises use the disk array-based snapshot technology to create
point-in-time data copies to protect online data access. The snapshot
technology has certain advantages. To make use of these advantages, however,
users are facing new challenges. In this case, users must ensure that data
copies can be managed on different storage and tape layers to meet storage,
cost, and recovery requirements.
Solution-related constraints usually involve the creation and maintenance of
complicated scripts. Multiple products and technologies are independently
managed. These technologies and products include various application-based
snap-type products, data migration technologies, and archiving and backup
products. They can ensure that the data can be moved between different
storage layers and positions and leave tapes at last. If the storage systems and
tapes are not uniformly cataloged or managed, it is a heavy and
time-consuming task to manually recover the data. Usually, a system
administrator with various professional skills has to restore the data from
various storage layers to the product system and manually ensure the
consistency and timeliness of the application data.
Bottom line: business operation advantages and low cost
By reducing the storage and management time, the SnapProtect technology
can reduce the business operation cost and investment related to the
management and protection of key application data. This can save input and
manpower, which can be used in other projects. The data is reliably protected
and can be recovered easily when it is required.
2014-11-18 Copyright © Huawei Page 42 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana :
5 Continuous Data Replicator
Enterprises and governments may have offices and data centers in different
regions. They are very concerned about how to use Simpana to protect
large-scale distributed data. Traditionally, local backup devices are used.
Local backup is very expensive, and disaster recovery backup is not supported.
Due to the deficiency of operators in skills, remote data protection and
recovery becomes a knotty problem. CommVault offers a solution to this issue.
Simpana has many options that ensure cost-effective high-quality remote data
protection and availability and provides a unified enterprise-level data
management environment for decentralized enterprises.
As a CommVault module, the Continuous Data Replicator (CDR) can protect
data in cooperation with other modules. Both CDR and SnapProtect are on the
recovery management layer of the data center. The CDR adopts a special
method to meet the recovery time objective (RTO) and recovery point
objective (RPO). Changes are continuously copied. In most cases, the
destination recovery time is only seconds later than the time of the original
data. In combination with the recovery point during copying, the recovery
time can be minimized. Data can be recovered from a volume backup or from
a valid snapshot at an appropriate time.
The CDR and the entire data management module of CommVault use the
same GUI and policies to protect copy data during the entire life-cycle of the
data.
5.1 Recovery Management Layer
The difference between the recovery management layer and data protection
layer is how to quickly recover data and meet the RTO and RPO set by the
customer. For typical data protection modes such as backup, these values are
counted by day. On the recovery management layer, data is protected by copy
and snapshot technologies. The original format of the data is used. Data is
recovered by loading volumes or copying back the data, while traditionally
data is recovered based on the backup data in a disk or tape. The CDR
combines the file-based copy and snapshot functions to meet the RTO and
RPO set by the customer. Changes are continuously copied. In most cases, the
destination recovery time is only seconds later than the time of the original
data. In combination with the recovery point during copying, the recovery
time can be minimized. Data can be recovered from a volume backup or from
a valid snapshot at an appropriate time.
2014-11-18 Copyright © Huawei Page 43 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana
5.2 Role of the CDR on the Recovery Layer
The CDR provides the following special function: It can copy the data with
byte-level changes. Combined with the SnapShot technology, it provides an
ideal solution for WAN-based environment.
Many customers with multiple remote offices or data centers are looking
for a stable centralized data protection solution. The byte-level data copy
function provided by the CDR can optimize the valid bandwidth of the
WAN. In transparent combination with the Galaxy backup function, it
protects an all-round data protection solution for remote offices and data
centers.
Customers are looking for a cost-effective disaster recovery (DR)
solution for their application data. For example, they want a solution to
protect the data in the email system and databases. By combining the
copy technology and the application-sensitive snapshot technology, the
CDR can automatically maintain the updates of remote copies. If the data
is damaged or a disaster occurs, the remote copies can be quickly loaded
and put in use.
5.3 CDR Process
The CDR copies data from the source computer to the destination computer in
almost real time to protect applications and file systems. Remote key data is
defined as a member of the copy set. It corresponds to the destination file in
the data center through the WAN. The CDR can also provide the data
availability service with low-cost copies. When data is written on the source
computer, the copied data will be obtained, and the byte-level changes will be
transmitted to and written on the destination computer. Data transmission
during the copy process is divided into two stages: Create a basic copy (or
image), and update the data in the data set continuously and incrementally. To
ensure that the incremental change data can be sent reliably to the destination
computer, a recording mechanism is adopted. During copying, the network
bandwidth is also controlled to restrict the traffic of data transmission from the
source computer. The copy function provides a cost-effective solution for
protecting remote data resources by data type, data set size, or data change
rate.
Compared independent copy products, Simpana CDR provides richer entire
data protection. For example, the product of a vendor needs to create a
snapshot on the source computer and then send the snapshot to the destination
computer, which means that a large deal of image data needs to be transmitted
over the network. The CDR can invoke copied data to provide snapshots to
ensure the consistency between applications. The recovery points are stored
on the destination computer. They can be used as the data source for DR
backup. The copy configuration and central backup policies are transparently
integrated. The following figure shows the procedure for copying data and
creating recovery points.
5.4 Copy Modes
CommVault CDR supports the following copy modes:
2014-11-18 Copyright © Huawei Page 44 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana
One-to-one copy
Figure 5-1
Multiple-to-one copy
Figure 5-2
One-to-multiple copy
Figure 5-3
2014-11-18 Copyright © Huawei Page 45 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana
5.5 Data Protection for Multiple Remote Offices
and Data Centers
The CDR is seamlessly integrated with the data life-cycle management
function of Simpana. A powerful unified GUI is provided, which allows users
to control the copy process and the data protection and archiving of remote
offices. In this way, administrators can extend the data life-cycle management
to remote offices with a policy and a console.
The following figure shows how to protect the data of multiple remote file
systems, email systems, database systems, and local servers in centralized
mode. The application data is copied to a central server. A backup policy is
created on the server to provide offline data backup. This backup set can be
directly browsed. If a backup agent is installed on the client, the data can also
be restored directly to the client. This greatly reduces the workload of
administrators in tracing backup sets, especially those of remote servers.
Figure 5-4
After the data of a remote office is copied and the corresponding recovery
point is created, the data of the remote office becomes a part of the data
protection policy. Recovery points are created by COW. A COW is a
space-saving snapshot volume that contains the copied data. This type of
snapshot can recover data in various modes.
Snapshots can be loaded as read-only volumes for users to browse, read,
and copy the file data.
Administrators can process any recovery point on the COW and change
it into a complete volume. This volume has a specified time for any
server in the network environment.
2014-11-18 Copyright © Huawei Page 46 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana
Each recovery point is associated with a storage policy after it is created,
and a backup set is automatically created. This backup set can be
browsed and recovered like a common part of the recovery process.
This special function combines copy and backup. It allows users to browse
and recover their backup sets in their remote offices. After a user creates a
backup set on a local computer, the CDR can automatically maps the copy
data to the primary backup server.
5.6 Cost-Effective Disaster Recovery
Currently, the CDR supports the following products: Windows, Unix, and
Linux file systems, and Exchange, SQL, and Oracle applications. The CDR
can copy and manage the time points of application data consistency. When
the data center requires a DR policy, the CDR can provide a cost-effective
choice, which is a remote image solution same as the Symmetrix Remote Data
Facility (SRDF).
The CDR can automatically discover the applications that are installed and the
folders (logs and databases) that need to be copied. When the applications are
running, it can create an initial copy for these key data. It can handle locked
files.
Various CDR configuration options are provided. One-to-multiple mode can
be set to copy a key database from the central server to multiple DR scenarios.
Recovery points can be created in a special mode or as planned. This allows
key applications to be quickly and reliably started in DR scenarios. The
following figure shows a possible configuration solution. The central email
server and database server are copied to two different places over the WAN to
prevent the occurrence of disasters. The application data is copied to a remote
center. Recovery points are created at specified intervals to ensure that a valid
snapshot is available when any disaster occurs.
5.7 Troubleshooting Method for Network
Interruptions
The reliability of the remote copy solution depends on the network. If the
network is to be interrupted or is interrupted, whether the disaster recovery
solution is capable of rectifying the network interruption becomes a key issue.
The CDR provides reliable network interruption recovery capability to ensure
the synchronization of data sets.
Considering the impact of network interruption on copying, two factors must
be taken into account:
Small network interruption: A small network interruption can be rectified
within minutes or hours. The copying system can obtain file changes from the
source computer according to the interruption duration and the copied data
volume and save them into the log. After the network connection is recovered,
the system can send the copied log to the destination computer. Like most
copy solutions, the CDR records content changes on the source computer into
2014-11-18 Copyright © Huawei Page 47 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana
the log and makes changes on the destination computer according to the log.
After the network connection is recovered, the copied data is sent back to the
system. Both normal copying and running of applications are not interrupted.
Large-scale network interruption: A large-scale network interruption refers to
an interruption during which the copy data obtained from the source computer
exceeds the available log space. In this case, the copied change data during
network interruption will be lost, and the copied data on the destination
computer is incomplete. Users can re-create a copy on the destination
computer and send all data on the source computer to the destination computer.
This method, however, is inapplicable to large-scale databases. Some
solutions initialize copy by comparing files one by one between the source
and destination computers. With this method, users do not need to copy all
files. In the case of a large complex copy set, it consumes too many resources
and too long time.
The CDR provides an intelligent synchronization mechanism for
automatically recreating the complete copy data after the network connection
is recovered. In this way, users do not need to copy all files or endure the
process of comparing each file. The CDR adopts a new mechanism. It invokes
the change log file of the Windows file system and quickly locates the files
that are changed during network interruption instead of comparing them one
by one. It is very important for an enterprise-level database.
5.8 Maximized Use of the Available Network
Bandwidth
The CDR provides various enterprise-level functions to improve the
efficiency of network resource use. On both enterprise's private networks that
connect remote offices and Internet, the CDR allows administrators to control
and protect data during data transmission.
Data compression: If the available network bandwidth is limited,
administrators can compress and copy data flows. After data compression is
set on the source computer, all data in the copy log is compressed before it is
sent to the destination computer. The data will be decompressed and written
into the destination volume on the destination computer. The space that is
saved by data compression depends on the type of data to be copied.
Data encryption: Private networks are not suitable for copying key service
data between remote offices. When copying data on open networks,
administrators can encrypt data to protect privacy. The CDR can encrypt data
flows by using the Blowfish algorithm on the source data. Data flows will be
decrypted and written into the copy volume after they reach the destination
computer.
Bandwidth restriction: Network resources are expensive. A private network is
seldom used only for copying. In most cases, private networks also need to
handle other services during copying. In this case, the copying process
competes with other service processes for network bandwidth. The CDR
provides the bandwidth restriction function. It allows administrators to
allocate the certain available bandwidth to the copying process. The
bandwidth allocation can be automatically adjusted according to the plan
made by administrators. For example, 90% bandwidth is allocated to copying
at night and weekends and 40% bandwidth is allocated to copying at work
hours in a typical office environment.
2014-11-18 Copyright © Huawei Page 48 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana
Boundless synchronization: Compared with daily changes, a data set is too big.
The network bandwidth may meet the requirement for daily change copying,
but it takes several days to create the initial copy. In this case, users can use
the boundless synchronization mode to quickly copy the initial data to the
destination computer.
The CDR provides a tool for processing large-scale data sets. This tool is
integrated with the copy process. After the initial copy data is obtained,
administrators can upload the initial data to the destination computer. A
backup set or disk cloning can be adopted. During data transmission, the CDR
obtains and records data changes on the source computer. After the
initialization is complete, the CDR transmits the changed data. The normal
copy process starts.
When a remote disaster occurs, this is also an effective method for recovering
the remote system. When the primary system becomes faulty, the secondary
system becomes the production system. The administrator can use the
boundless synchronization mode to restore the data quickly to the primary
system from the secondary system and copy the changed data to the primary
system. In this way, the primary system can be quickly recovered.
5.9 Integrated Management with the Copy
Function
The CDR is integrated with the uniform data management platform of
Simpana. Its powerful function has exceeded the backup function. It can
manage data archiving and data copying efficiently in combination.
Data archiving is a capacity management solution on the Simpana platform. It
can move large quantities of files that are seldom accessed to a secondary
storage medium according to predefined rules, leaving only small stubs at the
original place. When the data is accessed, the system can automatically and
transparently recover the data from the secondary storage medium to the
primary storage medium.
The CDR and data archiving functions work in transparent cooperation. The
CDR copies stubs but does not obtain the data from the secondary storage
medium. After stubs are copied, the data can still be normally accessed.
The data archiver is very important for the CDR, no matter it is installed on
the source or destination computer. On the source computer, the data archiver
can reduce the data sets to be copied and the time taken for initial copying. On
the destination computer, the data archiver serves as a capacity management
tool. It is an effective tool for managing the data of multiple remote offices in
a central system.
5.10 Conclusions
The CDR extends the functions of Simpana modules on the recovery layer. It
is integrated with the data protection and capacity management functions
through a single unified GUI. The settings, operations, and recovery points of
data copying can be managed and monitored. The CDR provides various
enterprise-level functions, such as data compression, data encryption,
advanced connection recovery, and boundless synchronization. It is the first
2014-11-18 Copyright © Huawei Page 49 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana
choice solution for remote office data management and disaster recovery. The
advantages of the CDR solution are as follows:
Impact on the performance of the source system: Owing to its special
technical advantages, it uses only a few resources of the source system.
In the production system, the impact of the CDR on the source system
depends on the data volume of the source system to be copied. In a
system whose copy data volume is normal, the CPU usage of the CDR is
less 8%, and the memory usage of the CDR is only dozens of MBs.
Low network bandwidth: The CDR copies data by byte. It can ensure
timely copy in the case of limited bandwidth. It provides the data
compression function to further reduce the requirement for bandwidth.
Powerful error tolerance: It provides powerful error tolerance during
network failures. When the copying process is interrupted due to a
disaster or transmission exception, the services of the primary system are
not affected. After the network connection is recovered, the cached data
can be automatically copied to the disaster recovery center.
Convenient management: It provides a perfect GUI. All operations can
be performed and managed in one window. It provides rich reports,
which can be used to manage all storage resources and clients. It is
completely localized, which facilitate the maintenance and management
by users.
2014-11-18 Copyright © Huawei Page 50 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana :
6 Other Technical Features
CommVault Simpana data protection software is an important part of Simpana
integrated information management. It provides strong and complete functions
and supports data backups by using all series of magnetic tapes, disks, and
compact disks. Simpana disk-based data protection solution allows the
administrator to use disks as high-performance backup devices. In addition, it
supports all storage structures, such as the DAS, NAS, SAN, or IP-SAN, and
all data transfer methods, such as IP-based or data block-based data transfer.
CommVault disk-based data protection technology has a faster backup speed
and smaller backup window. In addition, it provides faster concurrent
restoration performance and randomly accessed data backups, and moves data
to tier-2 storage media with policy-based means for long-term reservation.
Simpana supports various operating systems, major applications, and
databases.
Figure 6-1
2014-11-18 Copyright © Huawei Page 51 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana
Simpana provides a series of data protection solutions from centralized LAN
backup to SAN server-less backup. Users can select required data protection
solutions to protect their UNIX or Windows environments. In addition, they
can select stores with different performance to match their service
requirements, greatly reducing the total cost in the data life cycle.
CommVault disk-based data protection solution can be used in other media,
such as magnetic tapes or compact disks. Even if data is saved in different
media, the user can view protected data in a unified browser interface.
Simpana can directly restore data from any media. In any stage of the data life
cycle, the user only need to describe data types according to related policies.
Then, data is moved and storage devices are controlled automatically and
stably. The user can store data at the proper time and in a proper place to cope
with restrictions on availability and expenses.
The following sections describe backup and recovery advantages of Simpana:
6.1 Smart Clients
On the Windows platform, the smart client can improve operating
performance, eliminate lengthy and repeated file scans, save time for backups,
archiving, and resource management, and provide online data for content
index. The smart client optimizes the following:
System efficiency during backups or archiving
Incremental file backup policy
File archiving policy
Storage management report
Online content index policy
Figure 6-2
6.2 Synthetic Full Backup
Synthetic full backup is a process of synthesizing the last full backup and
associated incremental backups to a new full backup. Synthetic full backup
has the following advantages:
A new full backup is generated without reading the original data, avoiding
impacts on the CPU of the application server.
The generated new full backup can be used for data protection, new site
setting, or system test setting.
2014-11-18 Copyright © Huawei Page 52 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana
Figure 6-3
To improve ILM (Information Life-cycle Management) efficiency, the user
can complete synthetic full backups in different media. For example,
last-week full backups are performed on magnetic tapes and daily incremental
backups are performed on disks for fast backup and recovery. The synthetic
full backup function can synthesize full backups on magnetic tapes and
incremental backups on disks to a new full backup for remote storage or
disaster recovery. This flexible function allows IT technical personnel to tailor
a restoration plan and maximize performance and efficiency by using all tiers
of storage.
6.3 Auxiliary Copy
Using the auxiliary copy function, Simpana can create or migrate backup data
copies between different media or locations. The policy-based tiered storage is
performed in the background and does not require manual intervention. Data
copy creation is based on schedule policies while data reservation and deletion
are based on reservation policies. Therefore, if a storage method is out of date
and needs to be changed, data copying is terminated or data copies are
re-created in the entire storage set.
The auxiliary copy function plays a key role in reducing storage expenses.
Using this function, the user can copy out-of-date data to inexpensive media
and quickly store key data to expensive media, which is also the intention of
ILM. Making full use of this function can efficiently improve Return on
Investment (ROI) and reduce the total cost of ownership (TCO) for an
enterprise.
The priority of auxiliary copy is lower than that of scheduled backup.
Auxiliary copy is activated in the background when the system load is not
heavy. The built-in automatic restart function allows it to be resumed after
being suspended. When an activity with a higher priority needs to be
performed, the user can suspend auxiliary copy to accelerate the activity and
resume it from the interruption point after the activity is complete. The
built-in automatic restart function can effectively use storage resources,
reduce dependence on human intervention, and ensure that key data is backed
up on time.
2014-11-18 Copyright © Huawei Page 53 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana
6.4 Storage Policies
As a major factor of ILM, storage policies define all key decisions. Storage
policies provide a logical method to respond to physical resources and target
locations. Storage resources contain the following configurable items:
Data copy location
Target store type
Compact disks
Disks
Magnetic tapes
Tape library
Drive pool
Media type
Capacity
Data directory
Number of data copies to be created
Retention period of each copy
Maximum reuse times
Figure 6-4
Once a storage policy is defined, data can be assigned with a storage policy in
one-click mode. This changes data management methods and the change is
complete without reconfiguring hardware, connection, and networks.
Back-end operations for assigning and defining storage policies are complete
separately within Simpana. This reduces maintenance expenses and
complexity for IT personnel. For example, using Simpana storage policies can
simplify complicated activities, such as configuration, maintenance,
management, and reporting, and greatly reduce expenses for managing data
storage environments.
2014-11-18 Copyright © Huawei Page 54 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana
6.5 Granular Restores
As described above, Simpana can restore a single object instead of the entire
system by backing up and indexing some applications, such as Exchange,
Lotus Notes, and Active Directory with one instance. This means that an email
can be restored and directly written back to the user's mailbox or that users
can be restored by using AD attributes to avoid data losses. Key user
information is recorded and can be directly restored from backup media. The
administrator does not need to restore the entire system and search the system
for required information. That's why many competitors claim that they can
provide granular restores. Built into Simpana, granular restores for
applications reduce system breakdown time and potential expenses for
restoring unnecessary data. In addition, granular restores are an easy data
restoration method that reduces the time and expenses spent on multi-step data
restoration, searching data, and discovering data.
6.6 Restart/Checkpoint
All data transfer operations of Simpana, such as data backups, recovery,
auxiliary copy, and synthetic full backups, have checkpoints to ensure that
operations can be resumed after interruption. This function is important for
backup and recovery on the WAN and improves the backup and recovery
success rate. Compared with Simpana, competing products provide this
feature only for some functions and therefore have lower success rate.
Figure 6-5
6.7 GridStor
When the SAN is used, dynamic drives can be shared by multiple
MediaAgents, which improves resource usage and reduces redundant
resources. However, the SAN structure cannot eliminate errors caused by
hardware (both network and storage devices), resulting in data losses.
The QiNetix GridStor technology enables Simpana to provide error failover,
load balancing, storage pool, and prevention capability, which simplifies
management and improves data accesses. In addition, both near-line storage
and off-line storage can be used, reducing system TCO. Different from other
solutions in the market, GridStor can be used across different operating
systems and store types. For example, a backup activity in a Windows
operating system can be switched from Windows MediaAgent to MediaAgent
in a Solaris operating system. If data recovery is required, the user does not
need to know where the data is saved and the system can automatically find it.
2014-11-18 Copyright © Huawei Page 55 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana
Figure 6-6 GridStor — sharing storage devices and data directory
This means that the changed directory is always effective and allows
accessing the specified store even when the data written by the MediaAgent is
ineffective. Both original online storage resources and near-line or offline
storage resources may be used for backups. Priorities of storage resources are
set by users. Once priorities are set, storage resources are used automatically
and transparently, which optimizes resource utilization. Importantly, the user
can perform resource management in advance to balance load, perform
redirect activities to access unused storage resources, and correct errors in
backup and recovery to improve data access. In a word, GridStor is an
advantage and feature of Simpana.
6.8 Data Verification
After data is stored in media, no methods for determining what data can be
restored and restoring data instantly are provided. This results in doubled
expenses, time, and resources spent on data protection and low efficiency.
Therefore, ensuring data restorability is necessary. The cyclic redundancy
check (CRC) protects writing data to magnetic tape drives but cannot ensure
that the written data is restorable. The data verification tool of CommVault
checks whether backups are restorable.
The data verification tool can be set to verify data after all backups or full
backups, when the required data starts to be backed up, or after the required
data is backed up. The data verification tool helps the user to restore required
data reliably.
6.9 Content Index
CommVault can index online data, backup data, and archived data. Searched
data by using the search function includes indexed CommVault backups and
archived copies. The searched data can be auxiliary or offline copies of the
following data:
2014-11-18 Copyright © Huawei Page 56 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana
Any file system data
Microsoft Exchange information and accessories
IBM Lotus Domino information and accessories
Microsoft SharePoint documents and objects
Data stored in disks and magnetic tapes
The user can select and restore file or email information items for local
browse or separate uses. Restored items can be stored in work result
directories on the local network server. In addition, restored items can be
directly opened and browsed in the search window and exported to PST and
CAB files quickly and easily. The user can read, modify, and copy locally
stored files and information by using a file system or information application
program. Standard CommVault search (from archived data) or restoration
(from backups) is performed to search files or email information from the
management pool. The related work is usually tracked and reported and their
statuses can be browsed in the search window.
6.10 Media Remote Storage
To improve data reliability, magnetic tapes are considered to be remotely
restored for disaster recovery. CommVault can provide the following
technologies to store data remotely:
6.10.1 Auxiliary Copy
Using the auxiliary copy function, the user can copy important data backups
to a different magnetic tape or transfer them to a remote storage device over
the network when the system is idle. In this way, the loss or corruption of
major copies will not affect data recovery and therefore data is protected.
Auxiliary copy can be performed regularly or automatically triggered after a
backup is complete.
Using the auxiliary copy function, Simpana can create or migrate backup data
copies between different media or locations. The policy-based tiered storage is
performed in the background and does not require manual intervention. Data
copy creation is based on schedule policies while data reservation and deletion
are based on reservation policies. Therefore, if a storage method is out of date
and needs to be changed, data copying is terminated or data copies are
re-created in the entire storage set.
The priority of auxiliary copy is lower than that of scheduled backup.
Auxiliary copy is activated in the background when the system load is not
heavy. The built-in automatic restart function allows it to be resumed after
being suspended. When such a high-level activity needs to be performed, you
can suspend auxiliary copy to accelerate the high-level activity and resume it
from the interruption point after the high-level activity is complete. The
built-in automatic restart function can effectively use storage resources,
reduce dependence on human intervention, and ensure that key data is backed
up on time.
In addition, the user can use the auxiliary copy function to regularly copy data
from old magnetic tapes to new magnetic tapes, avoiding data losses due to
magnetic tape corruption. During a device upgrade (for example, using tape
2014-11-18 Copyright © Huawei Page 57 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana
libraries or magnetic tapes in new format), the user can migrate data by using
the auxiliary copy function.
You are advised to copy backup data to a remote disaster recovery center by
using DASH Copy.
6.10.2 Magnetic Tape Outbound Storage
A critical part of the disaster recovery plan is to store key data to a separate
location. Usually, data is stored in magnetic media such as magnetic tapes and
its copy is created and stored in a different offsite location. If data in the data
center is destroyed by disaster events, the user can perform data restoration by
using data stored in the offsite location. Generally, this process is named Vault
that is composed of outgoing from the magnetic tape library and manual
transport.
Vault Tracker provides a solution that manages and tracks remotely stored
portable storage media. In addition, it defines a series of tracking policies.
These tracking policies help the user to define what media must be moved,
where it must be moved to, and when it needs to be moved. Compared with
competing products, Simpana performs only logical management instead of
moving media. The management data is created to determine data to be
vaulted, vaulting location, and vaulting time. Media are only physical objects
containing data. The Vault Tracker solution supports some advanced concepts
and is important for managing remote media, such as virtual mail slots.
After tracking policies are defined, Vault Tracker activities can be performed
in a scheduled manner or triggered by events. Tracking policies contain
multiple types of mobile tracking as follows:
Library to location
Location to location
Location to library
Library to library
After the Vault Tracker activity is initialized, media are immediately removed
after being moved to library mail slots or media are assigned to be moved to
the reserved area of virtual mail slots. Virtual mail slots are a series of
neighboring slots in the tape library. They can be set to reserved areas for
vaulting media, which help to easily differentiate and move media.
During a remote movement, the status of media in transit must be monitored
and the related identifier generated in the Vault Tracker solution must ensure
that moved media can be correctly picked up. After a medium is moved to a
certain place and the related identifier is generated by Vault Tracker activities,
the medium can be viewed in the tracking history report of Vault Tracker with
CommCell browser and reporting mechanism.
In library-to-library tracking, expected backup reports and activities are added
to the pick-up list that is used for collecting related media in offsite locations.
These media will be returned to the source location for reuses. On the contrary,
identifiers are used to track media until they are returned to the source library
for reuses.
Vault Tracker is easy to use. Integrated to the QiNetix platform, it expands the
QiNetix platform and combines local and remote management on key data. It
maintains media local statuses and statuses in the offsite location and easily
accesses media by using Simpana and QiNetix data management tools. In
2014-11-18 Copyright © Huawei Page 58 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana
addition, it greatly reduces invalid data and data losses and provides an
intelligent method for remote media storage.
6.11 Image-Level Backup
The following problems may be encountered when the user backs up an
application system with millions of files and pictures:
Backup speed is slow and backup time is expressed in units of days.
The backup index is large. An index is generated for a single file in each
backup. Due to the large number of files, the size of the traditional
software index may reach TB as time elapses, affecting backup system
maintenance. For example, the index fails to be backed up.
The recovery speed is slow. Generally, the time for recovering data is
double of that for backing up data for traditional software. Recovery time
equals breakdown time. The data recovery speed is slow mainly due to
the large index (slow query speed) and tape use method of traditional
software.
CommVault adopts a two-level index structure, scientific magnetic tape use
method, and the image-level backup technology to quickly back up and
recover the preceding file system.
Image-level iDA can perform quick block-level backups for volume-level data.
Block-level backups greatly reduce the backup window. Compared with a
common file system, image-level iDA performs faster full backups and
incremental backups.
The value of an image-level backup lies in that a point-in-time data image is
created using the snapshot technology that imposes a small impact on
applications and still provides file-level granular restores. A typical
volume-level backup or snapshot restores only the entire volume while the
advanced indexing technology of Simpana allows the user to index and
recover a single file or folder from volume-level image backups.
Therefore, CommVault obtains data block changes from data block images by
using the block-level increment technology and updates backup copies based
on the obtained data block changes. Image-level technology is applicable to
the following environments:
A large file system with more than millions of files
An environment requiring a minimized backup interval and full backup
speed faster than recovery speed
An environment in which restoring the entire volume is more suitable
than granular restores.
CommVault Software Snapshot (CSS) captures snapshot images on the
production server with server breakdown time set to 0. These images are data
backup copies created by image-level iDA. Image-level backup supports
common file systems.
6.12 Deduplication
Exponential data increases bring multiple challenges for IT departments.
The challenges include quickly backing up and recovering increasingly
2014-11-18 Copyright © Huawei Page 59 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana
growing data, meeting stricter regulatory requirements, and realizing a
demanding recovery time object (RTO) with a tight budget. To tackle
these challenges, more and more users tend to use disks to back up data
and remotely replicate data over the network. This improves backup
system performance but brings the following challenges: Disk storage is
more expensive than traditional magnetic tape storage.
Unlike magnetic tapes, disks have no separated storage media and
read/write devices and cannot be expanded indefinitely.
Replicating massive data over the network imposes stricter requirements
on bandwidths.
How do I tackle these challenges? The deduplication technology is exact for
you to resolve the preceding problems. Deduplication eliminates duplicate
data in a storage system, geometrically reduces data actually stored or
transferred over the network, and greatly reduces storage and transmission
costs.
Deduplication is different from the common compression technology.
Compression reduces file sizes by eliminating redundant file data with the
compression algorithm but deduplication eliminates duplicate files or data
blocks scattered in a storage system with an algorithm.
Deduplication is different from the common incremental backup. An
incremental backup intends to back up only newly generated data but
deduplication reserves only unique data instances. Therefore, deduplication
gets an upper hand in reducing the data storage amount. The basic principle of
the deduplication technology is that data is filtered by blocks and same data
blocks are replaced by pointers pointing to the unique instance.
The deduplication solution built into Simpana is efficient, distributed, scalable,
and hardware-free. It helps to meet requirements on fast data increases and
long data storage and has no impact on fast recovery. The intelligent
integrated deduplication solution is applicable to the entire infrastructure from
a single client to back-end storage while other software adopts an isolated
deduplication solution. iDA, MediaAgent, and CommCell management
software components are used together, making full use of Common
Technology Engine, the core function of Simpana.
Global deduplication is applicable to all backup and archived data
regardless of data types, data sources, or platforms.
Adding the number of recovery points stored on the current disks
facilitates fast and direct data recovery.
Hardware-free deduplication allows the user to adopt any type of disks
for backing up or archiving data.
After deduplication, duplicate data is deleted from disk-based to
magnetic tape-based archiving storage layers, reducing the numbers of
required magnetic tapes and magnetic tape drives.
When stores are added, policy-based global deduplication does not need
to move or restore current data.
Data blocks do not need to be reorganized, having a small impact on
recovery speeds.
Deduplicated data can be quickly and easily recovered to the backup
system and other locations for tests, trial run, and disaster recovery.
Deduplication on a client site sends only unique data to disks, reducing
bandwidth and handling requirements on the target disk.
Deduplication can be performed on compressed or encrypted data.
2014-11-18 Copyright © Huawei Page 60 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana
Policy-based built-in global deduplication deletes all duplicate data that
complies with the global deduplication policy regardless of the number
of data directories in the policy, data types, or data flows, avoiding
isolated deduplication.
Hardware-free deduplication is applicable to all disk types and therefore
no special hardware or VTL interface is required.
Strong index and randomly accessed disks avoid reorganizing data
blocks during read operations. Read operations do not need hash because
MediaAgent directly reads required data blocks in a correct order and
sends them to the client, minimizing impacts on data restoration speeds.
Automatic forward reference ensures that the required data does not
reference very early data blocks, avoiding data block corruption. This
also avoids single point of failure and improves the scalability of the
deduplication storage area. Specifically, deduplicated data can be
seamlessly moved (not restored) from disks to magnetic tapes, reducing
the number of magnetic tapes and tape drives used for long-term copy
archiving.
Transparent restoration from magnetic tapes allows the user to
seamlessly and selectively restore the required data on magnetic tapes
instead of copying data on the entire magnetic tape to a disk, greatly
increasing data restoration speeds.
The hash generated on the client site can allocate deduplication workload,
improving throughput performance.
Integrated with the encryption function, deduplication on the client site
can deduplicate encrypted data. This minimizes network flows, protects
data security, and avoids unexpected losses or theft.
Deduplication can better calibrate data between multiple backups by
identifying contents to optimize deduplication effects.
Deduplication in the memory allows only unique data to be written to
disks, reducing input and output costs and improving backup throughput
performance.
Duplicate data is not transferred, avoiding transferring duplicate data to
disks and reducing valuable network bandwidths and resource
consumption on target storage devices.
Deduplication can be quickly deployed on the current infrastructure.
Specifically, Simpana is easy to install, configure, and manage. In
addition, it supports multiple platforms and application programs and
therefore it is easy to be integrated with the current system environments.
6.13 Global Deduplication
Global deduplication can be used across hundreds of clients and various data
storage policies. Each storage policy has its own data retention period but
shares the deduplication database. Global deduplication does not destroy data
protection or retention period, meeting service requirements.
6.14 DASH Copy
Using the Deduplication Accelerated Streaming Hash (DASH) copy function,
IT managers can replicate deduplication backup copies and therefore they can
2014-11-18 Copyright © Huawei Page 61 of 62
Technologies Co., Ltd
Huawei OceanStor Backup Software Technical White Paper for Simpana
have multiple copies. Each copy has its own retention period that determines
how long a copy needs to be reserved. For example, a source data set is copied
to site A and reserved for 30 days. Then, its backup can be copied to site B
and reserved for 90 days or copied to site C and reserved for two years. IT
managers can copy backup data to different locations where the data has
different retention periods and manage the data in a centralized manager.
6.15 DASH Full
The DASH Full function transfers only data identifiers instead of actual data
to the target store. In this way, the synthetic full backup takes only several
minutes decreasing from several hours. The DASH Full function minimizes
disk read operations, saves duplicate data decoding and repeated
deduplication operations, and reduces time and resource occupation.
2014-11-18 Copyright © Huawei Page 62 of 62
Technologies Co., Ltd
You might also like
- XNMS Operation GuideDocument76 pagesXNMS Operation GuideJose De PinaNo ratings yet
- PMDG 737NGX SDKDocument25 pagesPMDG 737NGX SDK廖宗原No ratings yet
- 阵阵 Dirty Cache 阵阵阵 Emcremote 阵阵阵阵Document6 pages阵阵 Dirty Cache 阵阵阵 Emcremote 阵阵阵阵taichiguanNo ratings yet
- Huawei OceanStor 5300 5500 5600 and 5800 V5 Mid-Range Hybrid Flash Storage Systems Technical White PaperDocument69 pagesHuawei OceanStor 5300 5500 5600 and 5800 V5 Mid-Range Hybrid Flash Storage Systems Technical White PaperPavel IlichevNo ratings yet
- Managing Volumes and File Systems For VNX ManuallyDocument100 pagesManaging Volumes and File Systems For VNX ManuallyPabloNo ratings yet
- Pg056-Cpri v87Document180 pagesPg056-Cpri v87Mümin GözütokNo ratings yet
- Oracle Generic Migration Version 1Document19 pagesOracle Generic Migration Version 1Karthik RamanNo ratings yet
- xilinx-1G/10G/25G Switching Ethernet SubsystemDocument139 pagesxilinx-1G/10G/25G Switching Ethernet SubsystemSaeed SaNo ratings yet
- Bandwidth Sharing of Multimode Base Station Co-Transmission (SRAN18.1 - Draft A)Document72 pagesBandwidth Sharing of Multimode Base Station Co-Transmission (SRAN18.1 - Draft A)VVLNo ratings yet
- Docu93960 - NetWorker 19.1 Cluster Integration Guide PDFDocument80 pagesDocu93960 - NetWorker 19.1 Cluster Integration Guide PDFmerz asmaNo ratings yet
- PenTest6 18 Preview PDFDocument25 pagesPenTest6 18 Preview PDFcbar15No ratings yet
- MX 204Document187 pagesMX 204Soemitro KolopakingNo ratings yet
- HP FF 5930-32QSFP+Document34 pagesHP FF 5930-32QSFP+lonnieNo ratings yet
- Aruba 5406R DatasheetDocument22 pagesAruba 5406R DatasheetWK OngNo ratings yet
- Cpri Mux (Lampsite) (Sran18.1 - Draft A)Document80 pagesCpri Mux (Lampsite) (Sran18.1 - Draft A)VVLNo ratings yet
- I) H3C S5560S-EI Series Enhanced Gigabit Switches Datasheet PDFDocument13 pagesI) H3C S5560S-EI Series Enhanced Gigabit Switches Datasheet PDFSON DANG LAMNo ratings yet
- Huawei CloudEngine S5732-H Series Hybrid Optical-Electrical Switches BrochureDocument14 pagesHuawei CloudEngine S5732-H Series Hybrid Optical-Electrical Switches BrochuregaspopperNo ratings yet
- Bandwidth On Demand (BOD) Charging Scheme: Pradya Sriroth TC/IPSTAR Representative Office - PhilippinesDocument5 pagesBandwidth On Demand (BOD) Charging Scheme: Pradya Sriroth TC/IPSTAR Representative Office - PhilippinesPradya SrirothNo ratings yet
- HPE 24 Port Gigabit L2 Switch - HP2530 - 24GDocument11 pagesHPE 24 Port Gigabit L2 Switch - HP2530 - 24GdhirarboyNo ratings yet
- Equipment Security (SRAN16.1 01)Document83 pagesEquipment Security (SRAN16.1 01)VVLNo ratings yet
- VNX5100 Hardware Information GuideDocument54 pagesVNX5100 Hardware Information Guidesandeepsohi88100% (2)
- 5G Architecture and SpecificationsDocument1 page5G Architecture and Specificationshrga hrgaNo ratings yet
- Backup Exec 15 Administrator's Guide PDFDocument1,457 pagesBackup Exec 15 Administrator's Guide PDFAhmed Abdelfattah67% (3)
- SK Telecom DASDocument2 pagesSK Telecom DASJ.R. ArmeaNo ratings yet
- Cisco SyncEDocument34 pagesCisco SyncEDhananjay ShrivastavNo ratings yet
- Ten Considerations For Chosing A Satellite Technology Platform IDirect 020711Document11 pagesTen Considerations For Chosing A Satellite Technology Platform IDirect 020711RomeliaGamarraNo ratings yet
- Obsai Based Nodeb Architecture: AntennaDocument3 pagesObsai Based Nodeb Architecture: AntennaLucky RahmanNo ratings yet
- Sunsight Instruments - Engineering The World's Finest Alignment ToolsDocument2 pagesSunsight Instruments - Engineering The World's Finest Alignment ToolshoainamcomitNo ratings yet
- IFC Centralized Manager 7.1 UG 913-2091-01 ZADocument244 pagesIFC Centralized Manager 7.1 UG 913-2091-01 ZApham hai vanNo ratings yet
- LAN WAN MAnDocument6 pagesLAN WAN MAnAster AbrahaNo ratings yet
- Antenna Alignment SPAA05 NEX Brochure 2Document4 pagesAntenna Alignment SPAA05 NEX Brochure 2furqansNo ratings yet
- PenTest - Hi I Hacked Your ComputerDocument8 pagesPenTest - Hi I Hacked Your ComputerYaman JainNo ratings yet
- 3 Sync Quality MeasurementDocument59 pages3 Sync Quality MeasurementRyankirimiNo ratings yet
- Cisco 5G Monetization Strategies: Redefining The Network Reimaging OpportunityDocument35 pagesCisco 5G Monetization Strategies: Redefining The Network Reimaging OpportunitySuchitra Tonk AnandNo ratings yet
- CloudEngine 6850 Series Data Center Switches Data SheetDocument13 pagesCloudEngine 6850 Series Data Center Switches Data Sheetmehrdad.mortazavi2405No ratings yet
- Synch in Packet NetworkDocument34 pagesSynch in Packet NetworkUwais AbiNo ratings yet
- Trango Antenna User Manual ADXX XX SX 1 and 2 FT DiamDocument14 pagesTrango Antenna User Manual ADXX XX SX 1 and 2 FT DiamhussainNo ratings yet
- ROF For Wireless CommDocument40 pagesROF For Wireless CommVamsi Krishna BNo ratings yet
- Huawei FusionSphere Compatibility ListDocument46 pagesHuawei FusionSphere Compatibility ListAndrés EspejoNo ratings yet
- Remote Data Replicator (RDR) V6.1 User GuideDocument81 pagesRemote Data Replicator (RDR) V6.1 User GuideskyNo ratings yet
- Access Control Based On 802.1x (SRAN16.1 - 01)Document29 pagesAccess Control Based On 802.1x (SRAN16.1 - 01)VVLNo ratings yet
- Ecs UsermanualDocument441 pagesEcs UsermanualMuhammad ImranNo ratings yet
- Audit ReportDocument6 pagesAudit ReporthassaanpashaNo ratings yet
- Timing and Sync Over PSNDocument48 pagesTiming and Sync Over PSNmeo_omhtNo ratings yet
- OceanStor Dorado 6.1 Basic Storage Service Configuration Guide For BlockDocument266 pagesOceanStor Dorado 6.1 Basic Storage Service Configuration Guide For BlockPaweł KuraśNo ratings yet
- Sync Deployment Phase Agg-Access v1Document11 pagesSync Deployment Phase Agg-Access v1vargasriffoNo ratings yet
- Huawei - Enterprise - Hi Care Support ServicesDocument19 pagesHuawei - Enterprise - Hi Care Support Servicesfrankcardoza1No ratings yet
- ANUE SCENARIOS Heynen Mobile BackhaulDocument29 pagesANUE SCENARIOS Heynen Mobile BackhaulJoao HortaNo ratings yet
- Qfx5120 Ethernet Switch DatasheetDocument15 pagesQfx5120 Ethernet Switch Datasheettayyab676No ratings yet
- PacketFence Network Devices Configuration Guide-4.0.6Document82 pagesPacketFence Network Devices Configuration Guide-4.0.6maariussNo ratings yet
- HP IP Console SwitchDocument127 pagesHP IP Console SwitchKishor SriramNo ratings yet
- Neutral Host Distributed Antenna Systems: An Introduction ToDocument14 pagesNeutral Host Distributed Antenna Systems: An Introduction TomkempemaNo ratings yet
- HCIA-AI V1.0 Lab GuideDocument124 pagesHCIA-AI V1.0 Lab Guidemulte123No ratings yet
- Automatic OMCH Establishment (SRAN9.0 - 01) PDFDocument131 pagesAutomatic OMCH Establishment (SRAN9.0 - 01) PDFriamaNo ratings yet
- Dopra Linux OS Security (SingleRAN - 04) PDFDocument35 pagesDopra Linux OS Security (SingleRAN - 04) PDFSam FicherNo ratings yet
- Pki (Sran10.1 02)Document183 pagesPki (Sran10.1 02)riamaNo ratings yet
- Triple Play: Building the converged network for IP, VoIP and IPTVFrom EverandTriple Play: Building the converged network for IP, VoIP and IPTVNo ratings yet
- Huawei OceanStor 5000 V5 Series Hybrid Flash Storage Systems Technical White PaperDocument82 pagesHuawei OceanStor 5000 V5 Series Hybrid Flash Storage Systems Technical White PaperIvan CruzNo ratings yet
- #00400221-IGateway Bill User Manual (V300R001 - 02)Document309 pages#00400221-IGateway Bill User Manual (V300R001 - 02)Shahab RezakhaniNo ratings yet
- Huawei OceanStor Dorado All-Flash Storage 6.1.0 Technical White PaperDocument186 pagesHuawei OceanStor Dorado All-Flash Storage 6.1.0 Technical White PaperFernandoNo ratings yet
- New WinRAR ZIP ArchiveDocument4 pagesNew WinRAR ZIP ArchivePutraOrionNo ratings yet
- Tutorial Letter 101/3/2020: Taxation of IndividualsDocument53 pagesTutorial Letter 101/3/2020: Taxation of Individuals44v8ct8cdyNo ratings yet
- RD Service Device Driver 3.0Document2 pagesRD Service Device Driver 3.0Manish DabralNo ratings yet
- B CSR1000v Configuration Guide Chapter 010110Document6 pagesB CSR1000v Configuration Guide Chapter 010110RcuisNo ratings yet
- Mediatek Antenna TestingDocument64 pagesMediatek Antenna TestingEduardo Solana LopezNo ratings yet
- Mir200 User Guide - Robot Interface 20 v10Document45 pagesMir200 User Guide - Robot Interface 20 v10việt dũng bùiNo ratings yet
- 1791 Certificate Testreport NICE Trading Recording V6.2.4 OpenScape Xpert V4R5Document15 pages1791 Certificate Testreport NICE Trading Recording V6.2.4 OpenScape Xpert V4R5Davaadagva AltansarnaiNo ratings yet
- SWOT Analysis of AMD by Prajwal.P.rahangdaleDocument8 pagesSWOT Analysis of AMD by Prajwal.P.rahangdalePrajwal RahangdaleNo ratings yet
- DevOps PPT by MQSDocument17 pagesDevOps PPT by MQSQasim SultaniNo ratings yet
- Coding Interview in JavaDocument568 pagesCoding Interview in JavaYasin KIZILKAYANo ratings yet
- Answer History of ComputersDocument55 pagesAnswer History of ComputersUttam RimalNo ratings yet
- Block Chain ContentDocument1 pageBlock Chain ContentPRIYAM XEROXNo ratings yet
- Bca Sp2020 Groupno-07 Movie Ticket Booking SystemDocument33 pagesBca Sp2020 Groupno-07 Movie Ticket Booking SystemManisha DasNo ratings yet
- Student Projects in Computer Networking: Simulation Versus CodingDocument6 pagesStudent Projects in Computer Networking: Simulation Versus CodingAjeethNo ratings yet
- CVDF - Google SearchDocument1 pageCVDF - Google SearchJames Jackel JamesonNo ratings yet
- MOBILE APPLICATION DEVELOPMENT ContentDocument2 pagesMOBILE APPLICATION DEVELOPMENT ContentSUBHRANSU MOHAN BHUTIANo ratings yet
- 009.1 Data Structure - IIDocument14 pages009.1 Data Structure - IINamanNo ratings yet
- Encapsulated Postscript File Format Specification: Adobe Developer SupportDocument34 pagesEncapsulated Postscript File Format Specification: Adobe Developer SupportSándor NagyNo ratings yet
- DEU-1661 VRV CAD Launch FinalDocument2 pagesDEU-1661 VRV CAD Launch Finalabdullah sahibNo ratings yet
- SIP5 7SK82-85 V07.80 Manual C024-7 enDocument1,686 pagesSIP5 7SK82-85 V07.80 Manual C024-7 enMauro Lúcio SilvaNo ratings yet
- NX CAM Setup TemplatesDocument10 pagesNX CAM Setup TemplatesCadcamnx BrasilNo ratings yet
- CSharp-Advanced-LINQ-ExercisesDocument7 pagesCSharp-Advanced-LINQ-ExercisesbulavinmailforlegezaNo ratings yet
- 13 Ilnas BlockchainDocument69 pages13 Ilnas Blockchainfateh abbasNo ratings yet
- Android App Tools Android Android Tools: RelativelayoutDocument7 pagesAndroid App Tools Android Android Tools: RelativelayoutDivya RajputNo ratings yet
- Application Notes For Configuring Avaya IP Office ServiceDocument34 pagesApplication Notes For Configuring Avaya IP Office Serviceitmilton19No ratings yet
- 7 The InternetDocument27 pages7 The Internet2087Mohammad HusainNo ratings yet
- Bca Unified SyllabusDocument16 pagesBca Unified SyllabusAshishNo ratings yet
- Lto Transfer of Ownership Data Sheet: Lot No.: Buyer No.Document5 pagesLto Transfer of Ownership Data Sheet: Lot No.: Buyer No.Jester MabutiNo ratings yet
- MT830 / MT831: Energy Measurement and ManagementDocument2 pagesMT830 / MT831: Energy Measurement and ManagementneutronbnNo ratings yet