Download as pdf or txt
You might also like
- The Illusion of Thin-Tails Under Aggregation - SSRN-Id1987562Document4 pagesThe Illusion of Thin-Tails Under Aggregation - SSRN-Id1987562adeka1No ratings yet
- Market Timing Sin A LittleDocument16 pagesMarket Timing Sin A LittlehaginileNo ratings yet
- FlyletsDocument1 pageFlyletsKranthi KiranNo ratings yet
- The Boom of 2021Document4 pagesThe Boom of 2021Jeff McGinnNo ratings yet
- Ig Index Pairs Trading ReportDocument8 pagesIg Index Pairs Trading Reportweb2091No ratings yet
- RTD ToS Fields ExamplesDocument2 pagesRTD ToS Fields ExamplesdatsnoNo ratings yet
- Philippine Pineapple Industry PDFDocument10 pagesPhilippine Pineapple Industry PDFJojit Balod50% (2)
- Microscopic Simulation of Financial Markets: From Investor Behavior to Market PhenomenaFrom EverandMicroscopic Simulation of Financial Markets: From Investor Behavior to Market PhenomenaNo ratings yet
- The Missing Risk Premium: Why Low Volatility Investing WorksDocument118 pagesThe Missing Risk Premium: Why Low Volatility Investing WorksMinh NguyenNo ratings yet
- SSRN Id2607730Document84 pagesSSRN Id2607730superbuddyNo ratings yet
- ACM The Great Vega ShortDocument10 pagesACM The Great Vega ShortwarrenprosserNo ratings yet
- Value and Momentum EverywhereDocument58 pagesValue and Momentum EverywhereDessy ParamitaNo ratings yet
- Statistical Arbitrage 6Document7 pagesStatistical Arbitrage 6TraderCat SolarisNo ratings yet
- Statistical Arbitrage - Part IIDocument2 pagesStatistical Arbitrage - Part IIsamuelcwlsonNo ratings yet
- Aether Analytics Strategy DeckDocument21 pagesAether Analytics Strategy DeckAlex BernalNo ratings yet
- A Stochastic Model For Order Book DynamiDocument21 pagesA Stochastic Model For Order Book DynamiAnalyticNo ratings yet
- Option Pricing Under Power Laws A RobustDocument5 pagesOption Pricing Under Power Laws A RobustLucas D'AmelioNo ratings yet
- SHILLER, Robert J. (1984) Stock Prices and Social DynamicsDocument54 pagesSHILLER, Robert J. (1984) Stock Prices and Social DynamicsDouglas de Medeiros FrancoNo ratings yet
- Analysis of Stock Market Data by Using Dynamic Fourier and Wavelets TeknikDocument13 pagesAnalysis of Stock Market Data by Using Dynamic Fourier and Wavelets TeknikJauharin InsiyahNo ratings yet
- SSRN Id2759734Document24 pagesSSRN Id2759734teppeiNo ratings yet
- Predictingvolatility LazardresearchDocument9 pagesPredictingvolatility Lazardresearchhc87No ratings yet
- The Swiss Army Knife of Options Analytics: Vola DynamicsDocument4 pagesThe Swiss Army Knife of Options Analytics: Vola DynamicsdanNo ratings yet
- Situation Index Handbook 2014Document43 pagesSituation Index Handbook 2014kcousinsNo ratings yet
- Net Net USDocument70 pagesNet Net USFloris OliemansNo ratings yet
- SSRN Id593584Document28 pagesSSRN Id593584Loulou DePanamNo ratings yet
- Change Point DetectionDocument23 pagesChange Point DetectionSalbani ChakraborttyNo ratings yet
- Gary Antonacci - Momentum Success Factors (2012)Document33 pagesGary Antonacci - Momentum Success Factors (2012)johnetownsendNo ratings yet
- Trading Manual: Indicator OverviewDocument101 pagesTrading Manual: Indicator OverviewMrugenNo ratings yet
- The IBS Effect Mean Reversion in Equity ETFsDocument31 pagesThe IBS Effect Mean Reversion in Equity ETFstylerduNo ratings yet
- Moskowitz Time Series Momentum PaperDocument23 pagesMoskowitz Time Series Momentum PaperthyagosmesmeNo ratings yet
- Predatory Trading IIDocument47 pagesPredatory Trading IIAlexNo ratings yet
- Engineering A Synthetic Volatility Index - Sutherland ResearchDocument3 pagesEngineering A Synthetic Volatility Index - Sutherland Researchslash7782100% (1)
- Forecasting The Term Structure of Government Bond Yields: Article in PressDocument28 pagesForecasting The Term Structure of Government Bond Yields: Article in Pressstan32lem32No ratings yet
- CME Iceberg Detection PreprintDocument16 pagesCME Iceberg Detection PreprintIan DouglasNo ratings yet
- Why Distributions Matter (16 Jan 2012)Document43 pagesWhy Distributions Matter (16 Jan 2012)Peter UrbaniNo ratings yet
- Lecture3 Market Impact MicrostructureDocument18 pagesLecture3 Market Impact MicrostructureAl StringsNo ratings yet
- JOIM Demystifying Managed FuturesDocument17 pagesJOIM Demystifying Managed Futuresjrallen81No ratings yet
- Scott Locklin - A Bestiary of Algorithmic Trading Strategies Locklin On ScienceDocument13 pagesScott Locklin - A Bestiary of Algorithmic Trading Strategies Locklin On Sciencetedcruz4presidentNo ratings yet
- Commodities As An Asset ClassDocument7 pagesCommodities As An Asset ClassvaibhavNo ratings yet
- When Do Stop-Loss Rules Stop LossesDocument42 pagesWhen Do Stop-Loss Rules Stop LossesPieroNo ratings yet
- Better Hedge Ratios For Pairs TradingDocument11 pagesBetter Hedge Ratios For Pairs TradingAlex AleksicNo ratings yet
- 1989 The Box Spread Arbitrage Conditions Theory, Tests, and Investment StrategiesThe Box Spread Arbitrage Conditions Theory Tests and Investment StrategiesDocument19 pages1989 The Box Spread Arbitrage Conditions Theory, Tests, and Investment StrategiesThe Box Spread Arbitrage Conditions Theory Tests and Investment Strategiesthe4asempireNo ratings yet
- Profile ®: IIIIIIIIIIIIIIIIIDocument346 pagesProfile ®: IIIIIIIIIIIIIIIIIWilly Pérez-Barreto MaturanaNo ratings yet
- Tail Risk Management - PIMCO Paper 2008Document9 pagesTail Risk Management - PIMCO Paper 2008Geouz100% (1)
- 2016 Book HowTheFedMovesMarkets PDFDocument198 pages2016 Book HowTheFedMovesMarkets PDFbustinjeiberNo ratings yet
- Using Truncated Levy Flight To Estimate Downside RiskDocument12 pagesUsing Truncated Levy Flight To Estimate Downside RiskPedro De Sá MenezesNo ratings yet
- Financial Econometrics Rachev S.T PDFDocument146 pagesFinancial Econometrics Rachev S.T PDFRodrigo Chang100% (1)
- CH 22Document68 pagesCH 22Aireen TanioNo ratings yet
- Paper On Mcap To GDPDocument20 pagesPaper On Mcap To GDPgreyistariNo ratings yet
- From Implied To Spot Volatilities: Valdo DurrlemanDocument21 pagesFrom Implied To Spot Volatilities: Valdo DurrlemanginovainmonaNo ratings yet
- Dynamic Asset Allocation For Varied Financial Markets Under Regime Switching FrameworkDocument9 pagesDynamic Asset Allocation For Varied Financial Markets Under Regime Switching FrameworkFarhan SarwarNo ratings yet
- Volatility DerivativesDocument21 pagesVolatility DerivativesjohamarNo ratings yet
- Livevol Database StructureDocument15 pagesLivevol Database StructureJuan LamadridNo ratings yet
- Arbitrage PresentationDocument26 pagesArbitrage PresentationSanket PanditNo ratings yet
- Are Hedge Funds Becoming Regular Asset Managers or Are Regular Managers Pretending To Be Hedge Funds?Document45 pagesAre Hedge Funds Becoming Regular Asset Managers or Are Regular Managers Pretending To Be Hedge Funds?mayur8898357200No ratings yet
- Trading From Private Consumer Survey Data - Machine Learning Meets Survey Research (Talk at Columbia, Feb. 2020)Document24 pagesTrading From Private Consumer Survey Data - Machine Learning Meets Survey Research (Talk at Columbia, Feb. 2020)Graham GillerNo ratings yet
- Strategic and Tactical Asset Allocation: An Integrated ApproachFrom EverandStrategic and Tactical Asset Allocation: An Integrated ApproachNo ratings yet
- Sectors and Styles: A New Approach to Outperforming the MarketFrom EverandSectors and Styles: A New Approach to Outperforming the MarketRating: 1 out of 5 stars1/5 (1)
- Corps@sos - Wa.gov: UBI Number: 602 946 134 Business NameDocument1 pageCorps@sos - Wa.gov: UBI Number: 602 946 134 Business NamedatsnoNo ratings yet
- Stock IndicatorDocument2 pagesStock IndicatordatsnoNo ratings yet
- Corps@sos - Wa.gov: UBI Number: 601 257 413 Business NameDocument1 pageCorps@sos - Wa.gov: UBI Number: 601 257 413 Business NamedatsnoNo ratings yet
- Corps@sos - Wa.gov: UBI Number: 601 257 413 Business NameDocument1 pageCorps@sos - Wa.gov: UBI Number: 601 257 413 Business NamedatsnoNo ratings yet
- Corps@sos - Wa.gov: UBI Number: 601 257 413 Business NameDocument1 pageCorps@sos - Wa.gov: UBI Number: 601 257 413 Business NamedatsnoNo ratings yet
- Commercial Statement of Change: Existing Registered AgentDocument2 pagesCommercial Statement of Change: Existing Registered AgentdatsnoNo ratings yet
- CongratulationLetterDocument1 pageCongratulationLetterdatsnoNo ratings yet
- Page: 1 of 2: Work Order #: 2020012800054474 - 1 Received Date: 01/28/2020 Amount Received: $0.00Document2 pagesPage: 1 of 2: Work Order #: 2020012800054474 - 1 Received Date: 01/28/2020 Amount Received: $0.00datsnoNo ratings yet
- Commercial Statement of Change: Existing Registered AgentDocument2 pagesCommercial Statement of Change: Existing Registered AgentdatsnoNo ratings yet
- Corps@sos - Wa.gov: UBI Number: 601 257 413 Business NameDocument1 pageCorps@sos - Wa.gov: UBI Number: 601 257 413 Business NamedatsnoNo ratings yet
- Guidance For Daily COVID-19 Screening of Staff and VisitorsDocument2 pagesGuidance For Daily COVID-19 Screening of Staff and VisitorsdatsnoNo ratings yet
- Foreign Registration Statement: Ubi NumberDocument3 pagesForeign Registration Statement: Ubi NumberdatsnoNo ratings yet
- CertificateDocument1 pageCertificatedatsnoNo ratings yet
- Unified Bonds 20141008Document57 pagesUnified Bonds 20141008datsnoNo ratings yet
- Basic Employee Training On Covid-19 Infection Prevention: June, 2020Document16 pagesBasic Employee Training On Covid-19 Infection Prevention: June, 2020datsnoNo ratings yet
- Aussie Dollar PDFDocument1 pageAussie Dollar PDFdatsnoNo ratings yet
- FilingCorrespondence CongratulationLetterDocument1 pageFilingCorrespondence CongratulationLetterdatsnoNo ratings yet
- Guidance On Developing A COVID-19 Safety Plan For Critical InfrastructureDocument3 pagesGuidance On Developing A COVID-19 Safety Plan For Critical InfrastructuredatsnoNo ratings yet
- Bias For The DayDocument28 pagesBias For The DaydatsnoNo ratings yet
- As of 12/31/14 10 Yrs. 25 Yrs. 50 Yrs. 75 Yrs. Since 1927 The Balanced Portfolio 60/40 Cash 1.6% 3.3% 5.4% 4.1% 3.7%Document3 pagesAs of 12/31/14 10 Yrs. 25 Yrs. 50 Yrs. 75 Yrs. Since 1927 The Balanced Portfolio 60/40 Cash 1.6% 3.3% 5.4% 4.1% 3.7%datsnoNo ratings yet
- Aussie Dollar PDFDocument1 pageAussie Dollar PDFdatsnoNo ratings yet
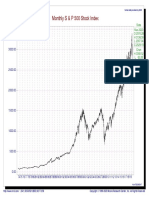
- Monthly S & P 500 Stock IndexDocument1 pageMonthly S & P 500 Stock IndexdatsnoNo ratings yet
- Chicago Boothf Garch ScriptDocument6 pagesChicago Boothf Garch ScriptdatsnoNo ratings yet
- Best Practice For Refinery FlowsheetsDocument6 pagesBest Practice For Refinery Flowsheetskhaled_behery9934No ratings yet
- Bangladesh University of Professionals: Mirpur Cantonment, DhakaDocument3 pagesBangladesh University of Professionals: Mirpur Cantonment, DhakaSinhaj NoorNo ratings yet
- 2019 h2 Econs Promo ExamDocument9 pages2019 h2 Econs Promo Exam2022 BALAKRISHNAN ADHITHINo ratings yet
- Ethics Marks Improvement Booklet 2023Document63 pagesEthics Marks Improvement Booklet 2023Jas SinNo ratings yet
- Shinepukur Ceramics Limited: Balance Sheet StatementDocument9 pagesShinepukur Ceramics Limited: Balance Sheet StatementTahmid Shovon100% (1)
- AF301 Unit 8 System Oriented TheoriesDocument28 pagesAF301 Unit 8 System Oriented TheoriesNarayan DiviyaNo ratings yet
- Tax Invoice: Bharat Auto Agency Hero Insurance Broking India Private LimitedDocument1 pageTax Invoice: Bharat Auto Agency Hero Insurance Broking India Private Limitedbharauthero barautNo ratings yet
- Lhoopa Survey Form Sheet1Document1 pageLhoopa Survey Form Sheet1franciscojr.tranceNo ratings yet
- Ferns N Petals - Company Profile 2021Document4 pagesFerns N Petals - Company Profile 2021Marc GrossNo ratings yet
- 2010 - Rosly - Shariah Parameter ReconsideredDocument19 pages2010 - Rosly - Shariah Parameter ReconsideredyuwonliloNo ratings yet
- PR2 Module 2 CheckedDocument4 pagesPR2 Module 2 CheckedJohn Clyde RanchezNo ratings yet
- Black BookDocument55 pagesBlack Bookprabhas MakwanaNo ratings yet
- Test Bank For Intermediate Microeconomics 8th Edition VarianDocument12 pagesTest Bank For Intermediate Microeconomics 8th Edition Varianjaperstogyxp94cNo ratings yet
- No842 Licences For MiningDocument2 pagesNo842 Licences For MiningimmanuelvinothNo ratings yet
- LatikDocument6 pagesLatikkpk8xnwmfgNo ratings yet
- V4s46A Cement Quality AssuranceDocument22 pagesV4s46A Cement Quality AssuranceDilnesa EjiguNo ratings yet
- Financial Management: Financial Management Refers To That Part of TheDocument19 pagesFinancial Management: Financial Management Refers To That Part of TheMayuraa ShekatkarNo ratings yet
- Money and Banking SystemDocument65 pagesMoney and Banking SystemfabyunaaaNo ratings yet
- Rsa Securid Appliance: A Convenient and Cost-Effective Two-Factor Authentication SolutionDocument2 pagesRsa Securid Appliance: A Convenient and Cost-Effective Two-Factor Authentication SolutionAfif Al FattahNo ratings yet
- Weekly Report 929 18-06-2021Document51 pagesWeekly Report 929 18-06-2021cpasl123No ratings yet
- Internship at Carlsquare: DealsDocument1 pageInternship at Carlsquare: DealsReyansh SharmaNo ratings yet
- MM 4 4th Edition Dawn Iacobucci Test Bank 1Document22 pagesMM 4 4th Edition Dawn Iacobucci Test Bank 1jessica100% (49)
- Jawaban Exercise 1.1 Dan Jawaban Exercise 1.2Document2 pagesJawaban Exercise 1.1 Dan Jawaban Exercise 1.2gunadi.nursalimNo ratings yet
- ⻜飞凡英语Pte写作Essay机经+参考答案: © Feifan English Training 2016-2017 All Rights ReservedDocument54 pages⻜飞凡英语Pte写作Essay机经+参考答案: © Feifan English Training 2016-2017 All Rights ReservednealNo ratings yet
- Application For Certification - NewDocument3 pagesApplication For Certification - NewALOKE GANGULYNo ratings yet
- Kirana KingDocument5 pagesKirana KingWITN NEWSNo ratings yet
- FINAL DHSUD Branding Playbook Oct2023 1Document60 pagesFINAL DHSUD Branding Playbook Oct2023 1Yam LicNo ratings yet
- Implications of Ethical Tradition For Business 021923Document13 pagesImplications of Ethical Tradition For Business 021923Raven DometitaNo ratings yet
- Procurement PlanDocument3 pagesProcurement Planmmalnar1No ratings yet