
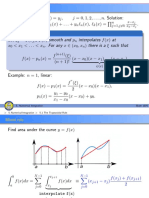
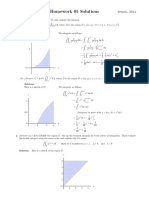
Sol 1
Sol 1
You might also like
- APPM 4360/5360 Homework Assignment #5 Solutions Spring 2019: Ǫ/m - Then, For All Z D and All N N (Ǫ) N (Ǫ ǪDocument7 pagesAPPM 4360/5360 Homework Assignment #5 Solutions Spring 2019: Ǫ/m - Then, For All Z D and All N N (Ǫ) N (Ǫ ǪJulio RacineNo ratings yet
- Quiz 7A SolutionsDocument3 pagesQuiz 7A Solutionsfatmaakbulut980No ratings yet
- Math PDFDocument61 pagesMath PDFMarvin Jay BayodNo ratings yet
- Unit - VDocument41 pagesUnit - VharikaranNo ratings yet
- Calculus Challenge, Spring 2005 Solutions: LN (LN N) LN (LN N) (LN (LN N) )Document2 pagesCalculus Challenge, Spring 2005 Solutions: LN (LN N) LN (LN N) (LN (LN N) )Taghi KhajeNo ratings yet
- Semana 13Document9 pagesSemana 13HAYBI MICAELA GUILLEN DELGADONo ratings yet
- Unit - VDocument41 pagesUnit - VSUJIN JOHNSONNo ratings yet
- Arfken-11.8.24: Keerthi Vasan G CDocument2 pagesArfken-11.8.24: Keerthi Vasan G CDiego AlejandroNo ratings yet
- Solutions To Problem Set 6Document4 pagesSolutions To Problem Set 6eetahaNo ratings yet
- In-Class Example (4) For Laurent Series: Math 128, Fall 2013 Instructor: Dr. Doreen de LeonDocument2 pagesIn-Class Example (4) For Laurent Series: Math 128, Fall 2013 Instructor: Dr. Doreen de LeonmauropenagosNo ratings yet
- 1 1 0.5z 1 1 0.3z 1 1 0.7z 1 (1 0.5z) (1 0.3z) 1 (1 0.5z) (1 0.7z) 1 1 0.5z 1 1 0.3z 1 1 0.7zDocument4 pages1 1 0.5z 1 1 0.3z 1 1 0.7z 1 (1 0.5z) (1 0.3z) 1 (1 0.5z) (1 0.7z) 1 1 0.5z 1 1 0.3z 1 1 0.7zDio Izqhaq Risky SasongkoNo ratings yet
- SI507-A22 Quiz1SyllabusDocument48 pagesSI507-A22 Quiz1SyllabusAtul VermaNo ratings yet
- Fourier Sine IngralDocument3 pagesFourier Sine Ingralarghadeepdas18No ratings yet
- L20Document3 pagesL20Ishak KETTAFNo ratings yet
- Unit 3 - Signals & Systems - WWW - Rgpvnotes.inDocument10 pagesUnit 3 - Signals & Systems - WWW - Rgpvnotes.inAdvait HirveNo ratings yet
- 2914 Solutions Chapter11Document6 pages2914 Solutions Chapter11Thomas LiuNo ratings yet
- #) Ffladw 1 Vixwieover: CostcostDocument2 pages#) Ffladw 1 Vixwieover: CostcostBarni “BarNeY” FógelNo ratings yet
- Math Formulas: Definite Integrals of Rational FunctionsDocument1 pageMath Formulas: Definite Integrals of Rational FunctionsArun AchalamNo ratings yet
- Solutions Chapter 4Document9 pagesSolutions Chapter 4Jesus MoralNo ratings yet
- 110calculus3 Hw6 SolDocument3 pages110calculus3 Hw6 Solnoorul hadiNo ratings yet
- Test 3 SolDocument7 pagesTest 3 Sol林鈺添No ratings yet
- .Laurent SeriesDocument5 pages.Laurent SeriesLakshmanan SakthivelNo ratings yet
- Mate AplicataDocument1 pageMate AplicataToderasc RazvanNo ratings yet
- Solutions Set 7Document6 pagesSolutions Set 7amircsgo4747No ratings yet
- Tugas Z TransformDocument14 pagesTugas Z TransformSrimuliani NihiNo ratings yet
- Integration BeeDocument3 pagesIntegration BeeMattNo ratings yet
- Interplay Between Theory and Experimentin AFM Nanomechanical Studies of PolymersDocument29 pagesInterplay Between Theory and Experimentin AFM Nanomechanical Studies of PolymersLIAKMANNo ratings yet
- Inverse TrigoDocument31 pagesInverse TrigoaloksirofmathematicsNo ratings yet
- Ejercicios MMF2Document2 pagesEjercicios MMF2Jhonny RomeroNo ratings yet
- Math 361, Problem Set 10Document4 pagesMath 361, Problem Set 10Qori QurratulNo ratings yet
- Some Notes On The Poisson Distribution: Ernie Croot October 7, 2010Document4 pagesSome Notes On The Poisson Distribution: Ernie Croot October 7, 2010MonaNo ratings yet
- Lecture 38 PDFDocument3 pagesLecture 38 PDFDK White LionNo ratings yet
- MATH1070 4 Numerical Integration PDFDocument135 pagesMATH1070 4 Numerical Integration PDFOkoth Jimmy JamesNo ratings yet
- 38.1 Examples of Laurent SeriesDocument3 pages38.1 Examples of Laurent SeriesJason HaNo ratings yet
- Screenshot 2023-06-27 (12.04.39 AM)Document33 pagesScreenshot 2023-06-27 (12.04.39 AM)federica sgammatoNo ratings yet
- Elec303 HW7Document3 pagesElec303 HW7wendyNo ratings yet
- Regras de PrimitivacaoDocument3 pagesRegras de PrimitivacaoPedro CorreiaNo ratings yet
- CS1 NotesDocument27 pagesCS1 NoteswallhumedxxNo ratings yet
- Institute of Electrical and Electronic EngineeringDocument48 pagesInstitute of Electrical and Electronic EngineeringКдйікі КциNo ratings yet
- 数值最优化算法与理论(课后习题)Document66 pages数值最优化算法与理论(课后习题)YU CHUNo ratings yet
- 6 Laurent's TheoremDocument11 pages6 Laurent's TheoremShubhi VarshneyNo ratings yet
- EM Wave Equation PDFDocument32 pagesEM Wave Equation PDFYashwanth YashuNo ratings yet
- Solution One ProblemDocument2 pagesSolution One ProblemNAVEEN RAJ RNo ratings yet
- Homework05-Solutions S14 PDFDocument4 pagesHomework05-Solutions S14 PDFBianny RemolinaNo ratings yet
- NPTEL Week 4Document15 pagesNPTEL Week 4GAURAV RATHORENo ratings yet
- Qualifying Round 2017 TestDocument2 pagesQualifying Round 2017 TestDiego TorrezNo ratings yet
- Problem Set 4 SolutionsDocument6 pagesProblem Set 4 SolutionsandrewlimjfNo ratings yet
- MAT235: Discussion 4: 1 Order StatisticsDocument3 pagesMAT235: Discussion 4: 1 Order StatisticsharuzNo ratings yet
- Let X, Y, Z Have Joint PDF F (X, Y, Z) 2 (X + y + Z) 3, 0 QuizletDocument1 pageLet X, Y, Z Have Joint PDF F (X, Y, Z) 2 (X + y + Z) 3, 0 QuizletDarryl SinagaNo ratings yet
- NCUMC18 SolutionsDocument7 pagesNCUMC18 SolutionsGlory OlalereNo ratings yet
- Segédanyag ÖsszesDocument1 pageSegédanyag ÖsszesBalázs MegyeryNo ratings yet
- Homework 07 Solutions: Math 21a Spring, 2014Document6 pagesHomework 07 Solutions: Math 21a Spring, 2014TARANNAUM JAHAN SULTANNo ratings yet
- Lecture1 2Document8 pagesLecture1 2yicanwang921No ratings yet
- Unit 3 - Signal & Systems - WWW - Rgpvnotes.inDocument10 pagesUnit 3 - Signal & Systems - WWW - Rgpvnotes.inAbhishek PatelNo ratings yet
- Calculus2014 Lecturenote 10 9Document8 pagesCalculus2014 Lecturenote 10 9盧思宇No ratings yet
- Gamma DistributionDocument3 pagesGamma Distributionqwertypushkar123No ratings yet
- Laplace: F: (A, + ) R (A, B) B A Lim R F (X) DX (A, + ) (X) DX Lim Z F (X) DXDocument33 pagesLaplace: F: (A, + ) R (A, B) B A Lim R F (X) DX (A, + ) (X) DX Lim Z F (X) DXscal1No ratings yet
- Seminar 12 Derivate Part Iale: Probleme RezolvateDocument4 pagesSeminar 12 Derivate Part Iale: Probleme RezolvateBostan AlexandruNo ratings yet
- RST 7Document13 pagesRST 7ShanNo ratings yet
- Real-Time Surveillance Through Face Recognition UsDocument9 pagesReal-Time Surveillance Through Face Recognition UsfluidjNo ratings yet
- Formula For NavigationDocument9 pagesFormula For NavigationbalaNo ratings yet
- Mathematics For Ntse Questions - MMDocument127 pagesMathematics For Ntse Questions - MMKavyansh NagNo ratings yet
- Lecture 3 - Analysis and Design For Axial TensionDocument10 pagesLecture 3 - Analysis and Design For Axial TensionDubu DubuNo ratings yet
- 3012 NotesDocument55 pages3012 NotesEnlaiNo ratings yet
- ID Pengaruh Pengetahuan Auditor Pengalaman Auditor Kompleksitas Tugas Locus of ContDocument15 pagesID Pengaruh Pengetahuan Auditor Pengalaman Auditor Kompleksitas Tugas Locus of ContSteven adiNo ratings yet
- Electron Plasma Oscillation SDocument6 pagesElectron Plasma Oscillation SCésar AveleyraNo ratings yet
- Files-3-Handouts Solved Problems Chapter 3 Mechanical Systems PDFDocument7 pagesFiles-3-Handouts Solved Problems Chapter 3 Mechanical Systems PDFHemanta DikshitNo ratings yet
- Digital Image Processing - Pages-122-126Document5 pagesDigital Image Processing - Pages-122-126Faheem KhanNo ratings yet
- Control Strategies For Microgrids With Distributed Energy Storage Systems - An OverviewDocument15 pagesControl Strategies For Microgrids With Distributed Energy Storage Systems - An OverviewJoão Adolpho VictorioNo ratings yet
- Modeling in Chemical EngineeringDocument6 pagesModeling in Chemical EngineeringGraceOktavianaNo ratings yet
- AOA Course ContentsDocument5 pagesAOA Course ContentsMarryam ZulfiqarNo ratings yet
- Disappearing Number InfoDocument8 pagesDisappearing Number InfosarthorksNo ratings yet
- ILLIAC IV-Diameter-Average Internode Distance-And Bisection Width of The Twisted Torus NetworkDocument10 pagesILLIAC IV-Diameter-Average Internode Distance-And Bisection Width of The Twisted Torus NetworkAbhishek DuttaNo ratings yet
- Vidyalankar: Digital ElectronicsDocument22 pagesVidyalankar: Digital Electronicsramanaidu1No ratings yet
- Econ110 Spring2019 PS7Document7 pagesEcon110 Spring2019 PS7Alaina NicoleNo ratings yet
- Gas Flowmeter Calibration1957045249Document49 pagesGas Flowmeter Calibration1957045249Mohamed NaserNo ratings yet
- Metu NCC Fall Semester (2017-1) PHY 105 General Physics I (3580105) Course SyllabusDocument3 pagesMetu NCC Fall Semester (2017-1) PHY 105 General Physics I (3580105) Course SyllabusErgin ÖzdikicioğluNo ratings yet
- Assignment 1Document6 pagesAssignment 1John Does0% (1)
- Two-Dimensional Sample Entropy: Assessing Image Texture Through IrregularityDocument12 pagesTwo-Dimensional Sample Entropy: Assessing Image Texture Through IrregularityRodrigo VasconcelosNo ratings yet
- Homework12 SolutionsDocument5 pagesHomework12 SolutionsOscar Alarcon CelyNo ratings yet
- SSC GD 2023 Reasoning RwaDocument248 pagesSSC GD 2023 Reasoning Rwakarishmasatyam999No ratings yet
- Vakev Exetat 2020-2021 Advanced Level MathsDocument25 pagesVakev Exetat 2020-2021 Advanced Level Mathsvigiraneza0No ratings yet
- Science ReviewerDocument12 pagesScience ReviewerMai100% (1)
- Chem 17 Chemical KineticsDocument15 pagesChem 17 Chemical KineticsAnneNo ratings yet
- Rubisov Anton 201511 MAS ThesisDocument94 pagesRubisov Anton 201511 MAS ThesisJose Antonio Dos RamosNo ratings yet
- Claret School of Zamboanga City: Teacher'S Learning Plan in Grade 9 MathematicsDocument3 pagesClaret School of Zamboanga City: Teacher'S Learning Plan in Grade 9 Mathematicsmarie ruth de los reyesNo ratings yet
- PDP Transferable Skills AuditDocument12 pagesPDP Transferable Skills AuditUsman KhalidNo ratings yet
- Java Codes For Stamp Duty CalculatorDocument9 pagesJava Codes For Stamp Duty Calculatorapi-27070090No ratings yet























































































Download as pdf or txt
You might also like
- APPM 4360/5360 Homework Assignment #5 Solutions Spring 2019: Ǫ/m - Then, For All Z D and All N N (Ǫ) N (Ǫ ǪDocument7 pagesAPPM 4360/5360 Homework Assignment #5 Solutions Spring 2019: Ǫ/m - Then, For All Z D and All N N (Ǫ) N (Ǫ ǪJulio RacineNo ratings yet
- Quiz 7A SolutionsDocument3 pagesQuiz 7A Solutionsfatmaakbulut980No ratings yet
- Math PDFDocument61 pagesMath PDFMarvin Jay BayodNo ratings yet
- Unit - VDocument41 pagesUnit - VharikaranNo ratings yet
- Calculus Challenge, Spring 2005 Solutions: LN (LN N) LN (LN N) (LN (LN N) )Document2 pagesCalculus Challenge, Spring 2005 Solutions: LN (LN N) LN (LN N) (LN (LN N) )Taghi KhajeNo ratings yet
- Semana 13Document9 pagesSemana 13HAYBI MICAELA GUILLEN DELGADONo ratings yet
- Unit - VDocument41 pagesUnit - VSUJIN JOHNSONNo ratings yet
- Arfken-11.8.24: Keerthi Vasan G CDocument2 pagesArfken-11.8.24: Keerthi Vasan G CDiego AlejandroNo ratings yet
- Solutions To Problem Set 6Document4 pagesSolutions To Problem Set 6eetahaNo ratings yet
- In-Class Example (4) For Laurent Series: Math 128, Fall 2013 Instructor: Dr. Doreen de LeonDocument2 pagesIn-Class Example (4) For Laurent Series: Math 128, Fall 2013 Instructor: Dr. Doreen de LeonmauropenagosNo ratings yet
- 1 1 0.5z 1 1 0.3z 1 1 0.7z 1 (1 0.5z) (1 0.3z) 1 (1 0.5z) (1 0.7z) 1 1 0.5z 1 1 0.3z 1 1 0.7zDocument4 pages1 1 0.5z 1 1 0.3z 1 1 0.7z 1 (1 0.5z) (1 0.3z) 1 (1 0.5z) (1 0.7z) 1 1 0.5z 1 1 0.3z 1 1 0.7zDio Izqhaq Risky SasongkoNo ratings yet
- SI507-A22 Quiz1SyllabusDocument48 pagesSI507-A22 Quiz1SyllabusAtul VermaNo ratings yet
- Fourier Sine IngralDocument3 pagesFourier Sine Ingralarghadeepdas18No ratings yet
- L20Document3 pagesL20Ishak KETTAFNo ratings yet
- Unit 3 - Signals & Systems - WWW - Rgpvnotes.inDocument10 pagesUnit 3 - Signals & Systems - WWW - Rgpvnotes.inAdvait HirveNo ratings yet
- 2914 Solutions Chapter11Document6 pages2914 Solutions Chapter11Thomas LiuNo ratings yet
- #) Ffladw 1 Vixwieover: CostcostDocument2 pages#) Ffladw 1 Vixwieover: CostcostBarni “BarNeY” FógelNo ratings yet
- Math Formulas: Definite Integrals of Rational FunctionsDocument1 pageMath Formulas: Definite Integrals of Rational FunctionsArun AchalamNo ratings yet
- Solutions Chapter 4Document9 pagesSolutions Chapter 4Jesus MoralNo ratings yet
- 110calculus3 Hw6 SolDocument3 pages110calculus3 Hw6 Solnoorul hadiNo ratings yet
- Test 3 SolDocument7 pagesTest 3 Sol林鈺添No ratings yet
- .Laurent SeriesDocument5 pages.Laurent SeriesLakshmanan SakthivelNo ratings yet
- Mate AplicataDocument1 pageMate AplicataToderasc RazvanNo ratings yet
- Solutions Set 7Document6 pagesSolutions Set 7amircsgo4747No ratings yet
- Tugas Z TransformDocument14 pagesTugas Z TransformSrimuliani NihiNo ratings yet
- Integration BeeDocument3 pagesIntegration BeeMattNo ratings yet
- Interplay Between Theory and Experimentin AFM Nanomechanical Studies of PolymersDocument29 pagesInterplay Between Theory and Experimentin AFM Nanomechanical Studies of PolymersLIAKMANNo ratings yet
- Inverse TrigoDocument31 pagesInverse TrigoaloksirofmathematicsNo ratings yet
- Ejercicios MMF2Document2 pagesEjercicios MMF2Jhonny RomeroNo ratings yet
- Math 361, Problem Set 10Document4 pagesMath 361, Problem Set 10Qori QurratulNo ratings yet
- Some Notes On The Poisson Distribution: Ernie Croot October 7, 2010Document4 pagesSome Notes On The Poisson Distribution: Ernie Croot October 7, 2010MonaNo ratings yet
- Lecture 38 PDFDocument3 pagesLecture 38 PDFDK White LionNo ratings yet
- MATH1070 4 Numerical Integration PDFDocument135 pagesMATH1070 4 Numerical Integration PDFOkoth Jimmy JamesNo ratings yet
- 38.1 Examples of Laurent SeriesDocument3 pages38.1 Examples of Laurent SeriesJason HaNo ratings yet
- Screenshot 2023-06-27 (12.04.39 AM)Document33 pagesScreenshot 2023-06-27 (12.04.39 AM)federica sgammatoNo ratings yet
- Elec303 HW7Document3 pagesElec303 HW7wendyNo ratings yet
- Regras de PrimitivacaoDocument3 pagesRegras de PrimitivacaoPedro CorreiaNo ratings yet
- CS1 NotesDocument27 pagesCS1 NoteswallhumedxxNo ratings yet
- Institute of Electrical and Electronic EngineeringDocument48 pagesInstitute of Electrical and Electronic EngineeringКдйікі КциNo ratings yet
- 数值最优化算法与理论(课后习题)Document66 pages数值最优化算法与理论(课后习题)YU CHUNo ratings yet
- 6 Laurent's TheoremDocument11 pages6 Laurent's TheoremShubhi VarshneyNo ratings yet
- EM Wave Equation PDFDocument32 pagesEM Wave Equation PDFYashwanth YashuNo ratings yet
- Solution One ProblemDocument2 pagesSolution One ProblemNAVEEN RAJ RNo ratings yet
- Homework05-Solutions S14 PDFDocument4 pagesHomework05-Solutions S14 PDFBianny RemolinaNo ratings yet
- NPTEL Week 4Document15 pagesNPTEL Week 4GAURAV RATHORENo ratings yet
- Qualifying Round 2017 TestDocument2 pagesQualifying Round 2017 TestDiego TorrezNo ratings yet
- Problem Set 4 SolutionsDocument6 pagesProblem Set 4 SolutionsandrewlimjfNo ratings yet
- MAT235: Discussion 4: 1 Order StatisticsDocument3 pagesMAT235: Discussion 4: 1 Order StatisticsharuzNo ratings yet
- Let X, Y, Z Have Joint PDF F (X, Y, Z) 2 (X + y + Z) 3, 0 QuizletDocument1 pageLet X, Y, Z Have Joint PDF F (X, Y, Z) 2 (X + y + Z) 3, 0 QuizletDarryl SinagaNo ratings yet
- NCUMC18 SolutionsDocument7 pagesNCUMC18 SolutionsGlory OlalereNo ratings yet
- Segédanyag ÖsszesDocument1 pageSegédanyag ÖsszesBalázs MegyeryNo ratings yet
- Homework 07 Solutions: Math 21a Spring, 2014Document6 pagesHomework 07 Solutions: Math 21a Spring, 2014TARANNAUM JAHAN SULTANNo ratings yet
- Lecture1 2Document8 pagesLecture1 2yicanwang921No ratings yet
- Unit 3 - Signal & Systems - WWW - Rgpvnotes.inDocument10 pagesUnit 3 - Signal & Systems - WWW - Rgpvnotes.inAbhishek PatelNo ratings yet
- Calculus2014 Lecturenote 10 9Document8 pagesCalculus2014 Lecturenote 10 9盧思宇No ratings yet
- Gamma DistributionDocument3 pagesGamma Distributionqwertypushkar123No ratings yet
- Laplace: F: (A, + ) R (A, B) B A Lim R F (X) DX (A, + ) (X) DX Lim Z F (X) DXDocument33 pagesLaplace: F: (A, + ) R (A, B) B A Lim R F (X) DX (A, + ) (X) DX Lim Z F (X) DXscal1No ratings yet
- Seminar 12 Derivate Part Iale: Probleme RezolvateDocument4 pagesSeminar 12 Derivate Part Iale: Probleme RezolvateBostan AlexandruNo ratings yet
- RST 7Document13 pagesRST 7ShanNo ratings yet
- Real-Time Surveillance Through Face Recognition UsDocument9 pagesReal-Time Surveillance Through Face Recognition UsfluidjNo ratings yet
- Formula For NavigationDocument9 pagesFormula For NavigationbalaNo ratings yet
- Mathematics For Ntse Questions - MMDocument127 pagesMathematics For Ntse Questions - MMKavyansh NagNo ratings yet
- Lecture 3 - Analysis and Design For Axial TensionDocument10 pagesLecture 3 - Analysis and Design For Axial TensionDubu DubuNo ratings yet
- 3012 NotesDocument55 pages3012 NotesEnlaiNo ratings yet
- ID Pengaruh Pengetahuan Auditor Pengalaman Auditor Kompleksitas Tugas Locus of ContDocument15 pagesID Pengaruh Pengetahuan Auditor Pengalaman Auditor Kompleksitas Tugas Locus of ContSteven adiNo ratings yet
- Electron Plasma Oscillation SDocument6 pagesElectron Plasma Oscillation SCésar AveleyraNo ratings yet
- Files-3-Handouts Solved Problems Chapter 3 Mechanical Systems PDFDocument7 pagesFiles-3-Handouts Solved Problems Chapter 3 Mechanical Systems PDFHemanta DikshitNo ratings yet
- Digital Image Processing - Pages-122-126Document5 pagesDigital Image Processing - Pages-122-126Faheem KhanNo ratings yet
- Control Strategies For Microgrids With Distributed Energy Storage Systems - An OverviewDocument15 pagesControl Strategies For Microgrids With Distributed Energy Storage Systems - An OverviewJoão Adolpho VictorioNo ratings yet
- Modeling in Chemical EngineeringDocument6 pagesModeling in Chemical EngineeringGraceOktavianaNo ratings yet
- AOA Course ContentsDocument5 pagesAOA Course ContentsMarryam ZulfiqarNo ratings yet
- Disappearing Number InfoDocument8 pagesDisappearing Number InfosarthorksNo ratings yet
- ILLIAC IV-Diameter-Average Internode Distance-And Bisection Width of The Twisted Torus NetworkDocument10 pagesILLIAC IV-Diameter-Average Internode Distance-And Bisection Width of The Twisted Torus NetworkAbhishek DuttaNo ratings yet
- Vidyalankar: Digital ElectronicsDocument22 pagesVidyalankar: Digital Electronicsramanaidu1No ratings yet
- Econ110 Spring2019 PS7Document7 pagesEcon110 Spring2019 PS7Alaina NicoleNo ratings yet
- Gas Flowmeter Calibration1957045249Document49 pagesGas Flowmeter Calibration1957045249Mohamed NaserNo ratings yet
- Metu NCC Fall Semester (2017-1) PHY 105 General Physics I (3580105) Course SyllabusDocument3 pagesMetu NCC Fall Semester (2017-1) PHY 105 General Physics I (3580105) Course SyllabusErgin ÖzdikicioğluNo ratings yet
- Assignment 1Document6 pagesAssignment 1John Does0% (1)
- Two-Dimensional Sample Entropy: Assessing Image Texture Through IrregularityDocument12 pagesTwo-Dimensional Sample Entropy: Assessing Image Texture Through IrregularityRodrigo VasconcelosNo ratings yet
- Homework12 SolutionsDocument5 pagesHomework12 SolutionsOscar Alarcon CelyNo ratings yet
- SSC GD 2023 Reasoning RwaDocument248 pagesSSC GD 2023 Reasoning Rwakarishmasatyam999No ratings yet
- Vakev Exetat 2020-2021 Advanced Level MathsDocument25 pagesVakev Exetat 2020-2021 Advanced Level Mathsvigiraneza0No ratings yet
- Science ReviewerDocument12 pagesScience ReviewerMai100% (1)
- Chem 17 Chemical KineticsDocument15 pagesChem 17 Chemical KineticsAnneNo ratings yet
- Rubisov Anton 201511 MAS ThesisDocument94 pagesRubisov Anton 201511 MAS ThesisJose Antonio Dos RamosNo ratings yet
- Claret School of Zamboanga City: Teacher'S Learning Plan in Grade 9 MathematicsDocument3 pagesClaret School of Zamboanga City: Teacher'S Learning Plan in Grade 9 Mathematicsmarie ruth de los reyesNo ratings yet
- PDP Transferable Skills AuditDocument12 pagesPDP Transferable Skills AuditUsman KhalidNo ratings yet
- Java Codes For Stamp Duty CalculatorDocument9 pagesJava Codes For Stamp Duty Calculatorapi-27070090No ratings yet