Download as pdf or txt
You might also like
- Maths Project 2Document16 pagesMaths Project 2Shivam kumar Verma91% (11)
- DBA-5102 Statistics - For - Management AssignmentDocument12 pagesDBA-5102 Statistics - For - Management AssignmentPrasanth K SNo ratings yet
- Pred IntDocument17 pagesPred IntKristi RogersNo ratings yet
- NotesDocument44 pagesNotesAamna RazaNo ratings yet
- Quick and Dirty Regression TutorialDocument6 pagesQuick and Dirty Regression TutorialStefan Pius DsouzaNo ratings yet
- By Microsoft Website: DURATION: 6 Weeks Amount Paid: Yes: Introduction To Data ScienceDocument21 pagesBy Microsoft Website: DURATION: 6 Weeks Amount Paid: Yes: Introduction To Data ScienceVishal AgrawalNo ratings yet
- X Bar&RchartDocument9 pagesX Bar&RchartPramod AthiyarathuNo ratings yet
- SPSS Estimating Percentile RanksDocument6 pagesSPSS Estimating Percentile RanksDonald StephenNo ratings yet
- Plotting Experimental Data in Graphs and Error AnalysisDocument35 pagesPlotting Experimental Data in Graphs and Error AnalysisSURESH SURAGANINo ratings yet
- Evans Analytics2e PPT 04 RevisedDocument51 pagesEvans Analytics2e PPT 04 RevisedNur SabrinaNo ratings yet
- Correspondence Analysis: Ata Cience and NalyticsDocument6 pagesCorrespondence Analysis: Ata Cience and NalyticsSWAPNIL MISHRANo ratings yet
- Z Test FormulaDocument6 pagesZ Test FormulaE-m FunaNo ratings yet
- Published With Written Permission From SPSS Statistics 11111Document21 pagesPublished With Written Permission From SPSS Statistics 11111arbab buttNo ratings yet
- M 3: M D, M R D A T: Odule Easures of Ispersion Easures of Elationship AND ATA Nalysis OOLDocument6 pagesM 3: M D, M R D A T: Odule Easures of Ispersion Easures of Elationship AND ATA Nalysis OOLAadel SepahNo ratings yet
- Measures of Central TendencyDocument48 pagesMeasures of Central TendencySheila Mae Guad100% (1)
- Getting Started With IBM SPSS Statistics For Windows: A Training Manual For BeginnersDocument56 pagesGetting Started With IBM SPSS Statistics For Windows: A Training Manual For Beginnersbenben08No ratings yet
- What Is A Correlation Matrix?Document4 pagesWhat Is A Correlation Matrix?Irfan UllahNo ratings yet
- Module V 1Document7 pagesModule V 1Animesh MandalNo ratings yet
- Excel Stats Nicar2013Document6 pagesExcel Stats Nicar2013yaktamerNo ratings yet
- BSChem-Statistics in Chemical Analysis PDFDocument6 pagesBSChem-Statistics in Chemical Analysis PDFKENT BENEDICT PERALESNo ratings yet
- Deciles and PercentilesDocument52 pagesDeciles and PercentilesShaik Mujeeb RahamanNo ratings yet
- Chapter 6 Normal Distibutions: Graphs of Normal Distributions (Section 6.1 of UnderstandableDocument8 pagesChapter 6 Normal Distibutions: Graphs of Normal Distributions (Section 6.1 of UnderstandableAsiongMartinez12No ratings yet
- Safari - 23-Mar-2019 at 1:49 PMDocument1 pageSafari - 23-Mar-2019 at 1:49 PMRakesh ChoNo ratings yet
- Skewness KurtosisDocument52 pagesSkewness KurtosisJazzie SorianoNo ratings yet
- Lab 4 Excel BasicsDocument26 pagesLab 4 Excel BasicsUttam KolekarNo ratings yet
- Notes On Data Processing, Analysis, PresentationDocument63 pagesNotes On Data Processing, Analysis, Presentationjaneth pallangyoNo ratings yet
- Explanatory Data AnalysisDocument28 pagesExplanatory Data AnalysisdevashreereddyNo ratings yet
- Excel BasicsDocument26 pagesExcel BasicsDaniel FrancisNo ratings yet
- BDA 09 Shridhti TiwariDocument12 pagesBDA 09 Shridhti TiwariShrishti TiwariNo ratings yet
- What Is Linear RegressionDocument3 pagesWhat Is Linear Regressionthepirate 52No ratings yet
- Stastical Data Analysis: A Lokeshwari 22N31E0014Document30 pagesStastical Data Analysis: A Lokeshwari 22N31E0014turpu poojithareddyNo ratings yet
- Regression Analysis in ExcelDocument20 pagesRegression Analysis in Excelsherryl caoNo ratings yet
- Forecasting With ExcelDocument20 pagesForecasting With ExcelRod FormNo ratings yet
- Research Methodology: Result and Analysis (Part 1)Document65 pagesResearch Methodology: Result and Analysis (Part 1)ramesh babuNo ratings yet
- Calculating and Displaying Regression Statistics in ExcelDocument4 pagesCalculating and Displaying Regression Statistics in Exceldickson phiriNo ratings yet
- Spss Coursework HelpDocument8 pagesSpss Coursework Helpfzdpofajd100% (2)
- Statistical Analysis NotesDocument21 pagesStatistical Analysis Notesblee47No ratings yet
- Bda 09 Nidhi YadavDocument12 pagesBda 09 Nidhi YadavShrishti TiwariNo ratings yet
- Regression TutorialDocument5 pagesRegression TutorialBálint L'Obasso TóthNo ratings yet
- DSBDAL - Assignment No 10Document5 pagesDSBDAL - Assignment No 10spNo ratings yet
- Linear Regression Analysis in ExcelDocument15 pagesLinear Regression Analysis in ExcelBertrand SomlareNo ratings yet
- Using Spss For Descriptive Analysis: Description & Correlation - 1Document16 pagesUsing Spss For Descriptive Analysis: Description & Correlation - 1armailgmNo ratings yet
- BA 1 - Describing and Summarizing Data PDFDocument4 pagesBA 1 - Describing and Summarizing Data PDFpurwadaNo ratings yet
- Lab 5 InstructionsDocument4 pagesLab 5 InstructionsRachaelNo ratings yet
- The Idiomatic Programmer - Statistics PrimerDocument44 pagesThe Idiomatic Programmer - Statistics PrimerssignnNo ratings yet
- Stats Mid TermDocument22 pagesStats Mid TermvalkriezNo ratings yet
- MachineryDocument9 pagesMachineryAditya KumarNo ratings yet
- Summary of The Introduction To StatsDocument7 pagesSummary of The Introduction To StatsRavi Indra VarmaNo ratings yet
- Evaluating Analytical ChemistryDocument4 pagesEvaluating Analytical ChemistryArjune PantallanoNo ratings yet
- Basic Commands SPSSDocument25 pagesBasic Commands SPSSAyesha AhmedNo ratings yet
- Statistics For Linear Equation 2009Document2 pagesStatistics For Linear Equation 2009ytnateNo ratings yet
- Regression AnalysisDocument17 pagesRegression AnalysisNk KumarNo ratings yet
- DWDM Unit 1 Chap2 PDFDocument21 pagesDWDM Unit 1 Chap2 PDFindiraNo ratings yet
- Data Visualizations: HistogramsDocument27 pagesData Visualizations: HistogramsHuu Van TranNo ratings yet
- Descriptive StatisticsDocument4 pagesDescriptive StatisticsRaghad Al QweeflNo ratings yet
- Evaluating Model Performance Unit 6Document46 pagesEvaluating Model Performance Unit 6jahnabi122No ratings yet
- Preliminary Analysis: - Descriptive Statistics. - Checking The Reliability of A ScaleDocument92 pagesPreliminary Analysis: - Descriptive Statistics. - Checking The Reliability of A ScaleslezhummerNo ratings yet
- IA Physics This Template Is For Guidance OnlyDocument5 pagesIA Physics This Template Is For Guidance OnlynaimaNo ratings yet
- StatisticsDocument33 pagesStatisticsAnonymous J5sNuoIy100% (2)
- Chapter 2 - StatDocument100 pagesChapter 2 - Statjouie tabilinNo ratings yet
- The Practically Cheating Statistics Handbook TI-83 Companion GuideFrom EverandThe Practically Cheating Statistics Handbook TI-83 Companion GuideRating: 3.5 out of 5 stars3.5/5 (3)
- The Mathematics of (Hacking) PasswordsDocument11 pagesThe Mathematics of (Hacking) PasswordsFederico CarusoNo ratings yet
- DAT101x Lab 3 - Statistical AnalysisDocument19 pagesDAT101x Lab 3 - Statistical AnalysisFederico CarusoNo ratings yet
- Graphics Course 0125Document73 pagesGraphics Course 0125Federico CarusoNo ratings yet
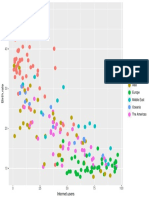
- Region: Africa Asia Europe Middle East Oceania The AmericasDocument1 pageRegion: Africa Asia Europe Middle East Oceania The AmericasFederico CarusoNo ratings yet
- 2007 War Detal HasDocument37 pages2007 War Detal HasFederico CarusoNo ratings yet
- Good Morning Heartache PDFDocument1 pageGood Morning Heartache PDFFederico CarusoNo ratings yet
- Brown, Ray-Bass Method-Bass Clarinet CutDocument90 pagesBrown, Ray-Bass Method-Bass Clarinet CutFederico Caruso67% (3)
- Ib Maths - GRAPHDocument18 pagesIb Maths - GRAPHTanvi SoniNo ratings yet
- Digital Control SystemsDocument1 pageDigital Control SystemsAnonymous HyOfbJ6100% (1)
- MCV4U Chapter 1 Assignment - A9d0c550a10552355394502 - 240213 - 153054Document2 pagesMCV4U Chapter 1 Assignment - A9d0c550a10552355394502 - 240213 - 153054Jaideep GillNo ratings yet
- Data Results Lab 8Document5 pagesData Results Lab 8Jane RihanNo ratings yet
- Sensitivity Analysis With The Simplex Tableau Duality: 1 © 2003 Thomson /South-Western SlideDocument12 pagesSensitivity Analysis With The Simplex Tableau Duality: 1 © 2003 Thomson /South-Western SlideSarvesh ShindeNo ratings yet
- LC Chromatography Lab ReportDocument7 pagesLC Chromatography Lab Reportapi-456196423No ratings yet
- Lampiran SPSSDocument18 pagesLampiran SPSSnovitaNo ratings yet
- MCQ Module 1 RGPV Mathematics IIIDocument7 pagesMCQ Module 1 RGPV Mathematics IIIPawari Ho rhi hNo ratings yet
- Trabajo 1Document8 pagesTrabajo 1jhonNo ratings yet
- Andre Du ToitDocument22 pagesAndre Du Toittroy_13No ratings yet
- Material Summary AssignmentDocument7 pagesMaterial Summary AssignmentAwindya CandrasmurtiNo ratings yet
- Review Jurnal 1 - TrehaloseDocument3 pagesReview Jurnal 1 - TrehaloseMuhammad Saepul AnwarNo ratings yet
- Continuity and Differentiability (Phase 1) - TatvaDocument50 pagesContinuity and Differentiability (Phase 1) - TatvaShiwanshi RaiNo ratings yet
- Unit Iii Data Analysis and ReportingDocument14 pagesUnit Iii Data Analysis and ReportingjanNo ratings yet
- Statistics Operations and NotationsDocument3 pagesStatistics Operations and NotationsSamantha IslamNo ratings yet
- Lec 5Document80 pagesLec 5Brijesh Kumar MauryaNo ratings yet
- Pert and S CurveDocument41 pagesPert and S CurveEdgar Bryan NicartNo ratings yet
- Stat Module 6Document3 pagesStat Module 6Princess TolentinoNo ratings yet
- Ronald Aylmer FisherDocument3 pagesRonald Aylmer FisherLee Ting100% (1)
- MA6251 Mathematics II Notes Regulation 2013 2nd Semester Notes Maths 2 Notes M2 Notes Lecture Notes Subject Notes - 10th 12th Time Table 2018 - Regulation 2017 Syllabus Notes Collections - 3Document5 pagesMA6251 Mathematics II Notes Regulation 2013 2nd Semester Notes Maths 2 Notes M2 Notes Lecture Notes Subject Notes - 10th 12th Time Table 2018 - Regulation 2017 Syllabus Notes Collections - 3XaviFernando0% (1)
- Additional Mathematics Summary NotesDocument3 pagesAdditional Mathematics Summary NotesDavid Ardiansyah100% (1)
- Engineering Maths 3 (Week3)Document21 pagesEngineering Maths 3 (Week3)Charles BongNo ratings yet
- Basic Calculus Activity Sheets Week 5Document10 pagesBasic Calculus Activity Sheets Week 5Ely BNo ratings yet
- Dissertation Document AnalysisDocument6 pagesDissertation Document AnalysisCollegePapersWritingServiceCanada100% (1)
- Critical Analysis Literature ReviewDocument7 pagesCritical Analysis Literature Reviewaflsvwoeu100% (1)
- Laplace Tab PDFDocument2 pagesLaplace Tab PDFsonNo ratings yet