Download as pdf or txt
You might also like
- Step by Step 10g R2 RAC Instalation On HP-UXDocument23 pagesStep by Step 10g R2 RAC Instalation On HP-UXAnkush Kumar100% (4)
- Proposed Oracle RAC Installation PlanDocument3 pagesProposed Oracle RAC Installation PlanBiplab ParidaNo ratings yet
- SCCM Basic TroubleshootingDocument11 pagesSCCM Basic Troubleshootingsinghdeepak87100% (1)
- ASM Best Practices 2017Document34 pagesASM Best Practices 2017DesmondChewNo ratings yet
- Oracle RAC ArchitectureDocument26 pagesOracle RAC ArchitectureRiturajHarsh100% (1)
- Flex ASM and Flex ClusterDocument36 pagesFlex ASM and Flex ClustersandeepappsdbaNo ratings yet
- Rac Node DeleteDocument19 pagesRac Node Deletesreeharirao kadaliNo ratings yet
- Presentation Understanding Oracle RAC Internals - Part 1 - SlidesDocument48 pagesPresentation Understanding Oracle RAC Internals - Part 1 - Slidesjatin_meghaniNo ratings yet
- KP Data Guard For RLSDocument31 pagesKP Data Guard For RLSKande RajaNo ratings yet
- Oracle12c DataGuard-FarSync and Whats New - IOUGDocument43 pagesOracle12c DataGuard-FarSync and Whats New - IOUGa singhNo ratings yet
- 04-RAC DB Administration OverviewDocument18 pages04-RAC DB Administration OverviewYonogyNo ratings yet
- 12carch and New Features MMDocument58 pages12carch and New Features MMHOD CANo ratings yet
- Oracle 11g R2 RAC and Grid Infrastructure by Rene KundersmaDocument20 pagesOracle 11g R2 RAC and Grid Infrastructure by Rene Kundersmaittichai100% (1)
- 11g R2 RAC Administration-2Document17 pages11g R2 RAC Administration-2Ebin VargheseNo ratings yet
- 11g R2 RAC Administration 2Document17 pages11g R2 RAC Administration 2Mohammad ZaheerNo ratings yet
- Installing Highly Available SAP Applications On Oracle Solaris 11 For Oracle Solaris Cluster 4.xDocument40 pagesInstalling Highly Available SAP Applications On Oracle Solaris 11 For Oracle Solaris Cluster 4.xengko17No ratings yet
- NEW Oracle Real Application Clusters and Oracle Clusterware Release 11.2Document49 pagesNEW Oracle Real Application Clusters and Oracle Clusterware Release 11.2Khalid WazirNo ratings yet
- Slides RAC Tier0info Jan06Document11 pagesSlides RAC Tier0info Jan06infoNo ratings yet
- ZFS RAID Calculator v7.1 - Partner Version - MacOSX CompatibleDocument28 pagesZFS RAID Calculator v7.1 - Partner Version - MacOSX CompatibleemedinillaNo ratings yet
- Database Platform Applicatio N Code Applicatio N Name Host Name Seconda Ry Host Data Guard Host Instance NameDocument3 pagesDatabase Platform Applicatio N Code Applicatio N Name Host Name Seconda Ry Host Data Guard Host Instance Namepankaj aggarwalNo ratings yet
- Ougf 2012 11gr2 Rac Kai YuDocument44 pagesOugf 2012 11gr2 Rac Kai Yumohd1985ibrahimNo ratings yet
- Create RAC Physical Standby DatabaseDocument52 pagesCreate RAC Physical Standby DatabaseyimerNo ratings yet
- Sandesh RAC Troubleshooting Diagnosability OTNyathra2 PDFDocument129 pagesSandesh RAC Troubleshooting Diagnosability OTNyathra2 PDFUdaya Samudrala0% (1)
- Practica de Base de DatosDocument73 pagesPractica de Base de DatosMarco Antonio AraujoNo ratings yet
- 173 - Oracle RAC From Dream To Production - 1.0.0Document46 pages173 - Oracle RAC From Dream To Production - 1.0.0Mohamed WahiebNo ratings yet
- Install Rac On Solaris VmwareDocument33 pagesInstall Rac On Solaris Vmwareguelerekrem100% (3)
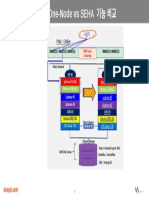
- RAC Architecture - 1Document1 pageRAC Architecture - 1신종근No ratings yet
- Oracle Database High Availability Strategy, Architecture and SolutionsDocument26 pagesOracle Database High Availability Strategy, Architecture and Solutionsk2sh07No ratings yet
- Administering Ocr and Voting DiskDocument60 pagesAdministering Ocr and Voting Diskshaikali1980No ratings yet
- Sun SolarisDocument1 pageSun SolarisBenny PrasetiohadiNo ratings yet
- RAC 11gR2 CLUSTER SETUPDocument82 pagesRAC 11gR2 CLUSTER SETUPvenkatreddyNo ratings yet
- Designing A PowerHA SystemMirror For AIX High Availability Solution - HA17 - HerreraDocument59 pagesDesigning A PowerHA SystemMirror For AIX High Availability Solution - HA17 - HerreraFabrice PLATELNo ratings yet
- Lapukhov Move Fast UnbreakDocument46 pagesLapukhov Move Fast UnbreakJavier AlejandroNo ratings yet
- ORAC 12cDocument212 pagesORAC 12cJoão Paulo SilvanoNo ratings yet
- Oracle Sparc T4Document4 pagesOracle Sparc T4Den SantosNo ratings yet
- Fastsocket: Speed Up Your SocketDocument51 pagesFastsocket: Speed Up Your SocketAkikoYuukiNo ratings yet
- Build Your Own Oracle RAC 10g Cluster On Linux and FireWireDocument68 pagesBuild Your Own Oracle RAC 10g Cluster On Linux and FireWireahmedgalal007No ratings yet
- 1432 RAC in OracleCloud Michalewicz SinghDocument57 pages1432 RAC in OracleCloud Michalewicz SinghdmdunlapNo ratings yet
- Howtocopy db12c Fs Lun Copies 2952056Document24 pagesHowtocopy db12c Fs Lun Copies 2952056nizamNo ratings yet
- DBA2 PremmDocument36 pagesDBA2 Premmafour98No ratings yet
- Installing Oracle RAC Software StackDocument14 pagesInstalling Oracle RAC Software StackkpratnakerNo ratings yet
- Oracle 11g RAC Installation - ChecklistDocument7 pagesOracle 11g RAC Installation - ChecklistSudipta GangulyNo ratings yet
- CON8171 Michalewicz-Michalewicz CON8171 RAC Operational BPDocument74 pagesCON8171 Michalewicz-Michalewicz CON8171 RAC Operational BPNguyenNo ratings yet
- Lora Tech Intro PDFDocument39 pagesLora Tech Intro PDFRoberto AmbrozioNo ratings yet
- Rmoug Flexasm Dflexclusters 01Document62 pagesRmoug Flexasm Dflexclusters 01Ali AnwarNo ratings yet
- Lec15 WirelessDocument52 pagesLec15 WirelessDr.W.Regis Anne - PSGCTNo ratings yet
- Tut7320 PDFDocument58 pagesTut7320 PDFHemantNo ratings yet
- A Practical Guide To Oracle 10g RAC Its REAL Easy!: Gavin Soorma, Emirates Airline, Dubai Session# 106Document113 pagesA Practical Guide To Oracle 10g RAC Its REAL Easy!: Gavin Soorma, Emirates Airline, Dubai Session# 106manjubashini_suriaNo ratings yet
- Mysql Cluster Deployment Best PracticesDocument39 pagesMysql Cluster Deployment Best Practicessushil punNo ratings yet
- D59999GC30 Les02Document18 pagesD59999GC30 Les02Oli ZVNo ratings yet
- 1.IOS XR - Intro-UseDocument68 pages1.IOS XR - Intro-Useagus kurniawanNo ratings yet
- B Release Notes Sonic 202012Document8 pagesB Release Notes Sonic 202012rkrao77No ratings yet
- Recover Corrupt/Missing OCR With No Backup - (Oracle 10g) : Oracle DBA Tips CornerDocument12 pagesRecover Corrupt/Missing OCR With No Backup - (Oracle 10g) : Oracle DBA Tips Cornershaikali1980No ratings yet
- Oracle 11g R1/R2 Real Application Clusters EssentialsFrom EverandOracle 11g R1/R2 Real Application Clusters EssentialsRating: 5 out of 5 stars5/5 (1)
- DRBD-Cookbook: How to create your own cluster solution, without SAN or NAS!From EverandDRBD-Cookbook: How to create your own cluster solution, without SAN or NAS!No ratings yet
- PLC: Programmable Logic Controller – Arktika.: EXPERIMENTAL PRODUCT BASED ON CPLD.From EverandPLC: Programmable Logic Controller – Arktika.: EXPERIMENTAL PRODUCT BASED ON CPLD.No ratings yet
- IP Routing Protocols All-in-one: OSPF EIGRP IS-IS BGP Hands-on LabsFrom EverandIP Routing Protocols All-in-one: OSPF EIGRP IS-IS BGP Hands-on LabsNo ratings yet
- Fundamentals of Distributed Object Systems: The CORBA PerspectiveFrom EverandFundamentals of Distributed Object Systems: The CORBA PerspectiveNo ratings yet
- QEEE Assignment - 53902 - 1524155396Document4 pagesQEEE Assignment - 53902 - 1524155396Sajjad SalariaNo ratings yet
- You Cannot Turn On Network Discovery in Network and Sharing Center in Windows Server 2008, Windows Server 2008 R2, or Windows Server 2012Document3 pagesYou Cannot Turn On Network Discovery in Network and Sharing Center in Windows Server 2008, Windows Server 2008 R2, or Windows Server 2012VÕ QUỐC HIỆUNo ratings yet
- CCNP 300 410 Enarsi NetworkTUT New Questions 13 Sep 2020Document55 pagesCCNP 300 410 Enarsi NetworkTUT New Questions 13 Sep 2020Sang Nguyen NgocNo ratings yet
- Consuming Messages With Kafka Consumers and Consumer Groups: Ryan PlantDocument38 pagesConsuming Messages With Kafka Consumers and Consumer Groups: Ryan PlantancgateNo ratings yet
- Demantra Software ComponentsDocument17 pagesDemantra Software ComponentsSandeep ChatterjeeNo ratings yet
- Push Button InterruptDocument6 pagesPush Button Interruptying25082No ratings yet
- 21Mbps Wifi Data Card: Model No: 21.6Mw-63Document2 pages21Mbps Wifi Data Card: Model No: 21.6Mw-63NandgulabDeshmukhNo ratings yet
- Mysql Master SlaveDocument8 pagesMysql Master SlaveEdgar Anibal BaezNo ratings yet
- Quanta Kl5a R1a Schematics PDFDocument46 pagesQuanta Kl5a R1a Schematics PDFCesar VillegasNo ratings yet
- Post-Grad Labview Course Exercise 11: G BoormanDocument3 pagesPost-Grad Labview Course Exercise 11: G BoormanDaud JanNo ratings yet
- Current LogDocument69 pagesCurrent LogLiongsu 86No ratings yet
- Nvidia Nvs 315 Data Sheet Pny VersionDocument1 pageNvidia Nvs 315 Data Sheet Pny Versionmudassirphd502No ratings yet
- System On Chip Design and Modelling: University of Cambridge Computer Laboratory Lecture NotesDocument144 pagesSystem On Chip Design and Modelling: University of Cambridge Computer Laboratory Lecture Notesgkk001No ratings yet
- Project SampleDocument84 pagesProject Samplese.vellingiri1979No ratings yet
- Comptia: Exam Questions 220-1001Document13 pagesComptia: Exam Questions 220-1001Tauseef AzizNo ratings yet
- Printer Configuration For ZebraDocument8 pagesPrinter Configuration For ZebraNimisha NigamNo ratings yet
- Serial PC Link CP1EDocument10 pagesSerial PC Link CP1ETahir SamadNo ratings yet
- Ms Word Module 3Document13 pagesMs Word Module 3R TECHNo ratings yet
- Optitex Installation Guide (For Administrators)Document62 pagesOptitex Installation Guide (For Administrators)Lembarek BOUHAFSNo ratings yet
- Cosy 131 User GuideDocument30 pagesCosy 131 User GuideSaid SaidouNo ratings yet
- A Trust Based Context-Aware Access Control For Web ServicesDocument19 pagesA Trust Based Context-Aware Access Control For Web ServicesvasanthisbNo ratings yet
- Websphere MQ CommandsDocument11 pagesWebsphere MQ CommandsPurnaG9No ratings yet
- Arduino Comparison Tables 05082015 v1Document1 pageArduino Comparison Tables 05082015 v1Paul Alin NăsuleaNo ratings yet
- SQL Express 2019 (Update) Log - Registry ItemsDocument644 pagesSQL Express 2019 (Update) Log - Registry ItemsitNo ratings yet
- 02-PAS-Fundamentals-The VaultDocument33 pages02-PAS-Fundamentals-The VaultOliver QuiambaoNo ratings yet
- Fortinet Testking NSE4 v2016-16-20 by Andy 167qDocument79 pagesFortinet Testking NSE4 v2016-16-20 by Andy 167qAndrew WebbNo ratings yet
- MDA Win68K WolDocument3 pagesMDA Win68K WolAnonymous KhhapQJVYtNo ratings yet
- TSW900ETH TSW900ETH: Ethernet TesterDocument12 pagesTSW900ETH TSW900ETH: Ethernet TesterJulia AssisNo ratings yet
- HP Beats Special Edition 15-p030nr NotebookDocument2 pagesHP Beats Special Edition 15-p030nr NotebookMaskered SantanderNo ratings yet