
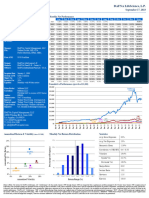
U.S. 2017 Census Data: Detroit, MI
U.S. 2017 Census Data: Detroit, MI
You might also like
- Rebirth of The Useless Bastard SonDocument32 pagesRebirth of The Useless Bastard Sonthe.untamed.annaNo ratings yet
- CP-563E, CS-563E, CP-573E, CS-573E, CS-583E, CP-663E, CS-663E and CS-683E Vibratory Compactor Electrical SystemDocument11 pagesCP-563E, CS-563E, CP-573E, CS-573E, CS-583E, CP-663E, CS-663E and CS-683E Vibratory Compactor Electrical SystemMohamed Mohamed100% (3)
- The Most Important Biblical Discovery of Our TimeDocument21 pagesThe Most Important Biblical Discovery of Our Timececampillo100% (1)
- NYC Population FactFinderDocument5 pagesNYC Population FactFinderDonnie BoscoNo ratings yet
- CDP-2) Demographic ProfileDocument17 pagesCDP-2) Demographic ProfileJohn Eric CatalanNo ratings yet
- Michigan Voting DemocraphicsDocument18 pagesMichigan Voting DemocraphicsAnonymous 5fWuzHNo ratings yet
- San Juan - 16 - 5YR - 2016Document21 pagesSan Juan - 16 - 5YR - 2016Jesus RosarioNo ratings yet
- Bank Mandiri Taspen BPD Sumatera Barat Bank Mestika: AssetDocument2 pagesBank Mandiri Taspen BPD Sumatera Barat Bank Mestika: AssetMartha Gracia ManurungNo ratings yet
- Regional DEED Data, Becker County, Nov. 15, 2021Document8 pagesRegional DEED Data, Becker County, Nov. 15, 2021Michael AchterlingNo ratings yet
- DP03 Selected Economic Characteristics 2012 American Community Survey 1-Year EstimatesDocument5 pagesDP03 Selected Economic Characteristics 2012 American Community Survey 1-Year Estimatesapi-28460727No ratings yet
- Chapter IiiDocument3 pagesChapter IiiJm SandiegoNo ratings yet
- ReportDocument8 pagesReportHuy DươngNo ratings yet
- Chapter 4 and 5 FinalisedDocument8 pagesChapter 4 and 5 FinalisedJaya DeviNo ratings yet
- Aspect 1 Age Percentage SheetDocument1 pageAspect 1 Age Percentage SheetmoobinamalNo ratings yet
- Age Distribution of Motor Vehicles As at 30 November 2023: Age (Years) Cars Motorcycles Buses Goods & Other VehiclesDocument11 pagesAge Distribution of Motor Vehicles As at 30 November 2023: Age (Years) Cars Motorcycles Buses Goods & Other VehiclesJunxian LiuNo ratings yet
- Puerto Rico 20 5YR 2020 0Document18 pagesPuerto Rico 20 5YR 2020 0Francisco MéndezNo ratings yet
- Acs 15 1yr DP04Document8 pagesAcs 15 1yr DP04Justin CarderNo ratings yet
- Union County Demographic Census Data, 2010Document4 pagesUnion County Demographic Census Data, 2010The State NewspaperNo ratings yet
- CINA Deluxe DQP For Breast ER PR and Her2 Prognostic Factors Manxia 2 9 ..Document12 pagesCINA Deluxe DQP For Breast ER PR and Her2 Prognostic Factors Manxia 2 9 ..MayNo ratings yet
- Cookeville, TN Demographics 2016Document7 pagesCookeville, TN Demographics 2016blake fahyNo ratings yet
- Final Na Nga BaDocument24 pagesFinal Na Nga BaJomarCalacagNo ratings yet
- Marriage and Divorce Statistics For South Korea 2023. (Korean)Document59 pagesMarriage and Divorce Statistics For South Korea 2023. (Korean)8hxynhdr97No ratings yet
- Bamberg County Demographic Census Data, 2010Document4 pagesBamberg County Demographic Census Data, 2010The State NewspaperNo ratings yet
- Allen StatsDocument2 pagesAllen Statsapi-332368008No ratings yet
- Civilian Labor Force ProfileDocument2 pagesCivilian Labor Force Profilefariasr23No ratings yet
- Appendix A National ProfileDocument17 pagesAppendix A National ProfileTimelendersNo ratings yet
- Age Why - Do - You - Like - The - Shop CrosstabulationDocument11 pagesAge Why - Do - You - Like - The - Shop CrosstabulationLatif AbdulNo ratings yet
- Detroit Census ACS - 11 - 5YR - DP03Document5 pagesDetroit Census ACS - 11 - 5YR - DP03Stephen BoyleNo ratings yet
- Determinants of Performance A Case of Life Insurance Sector of PakistanDocument28 pagesDeterminants of Performance A Case of Life Insurance Sector of PakistanM SadiqNo ratings yet
- DAFNA FactSheetDocument2 pagesDAFNA FactSheetfxarb098No ratings yet
- Expanded National Nutrition Survey: 2019 Results: Health and Nutritional Status of Filipino Adults, 20-59 Years OldDocument61 pagesExpanded National Nutrition Survey: 2019 Results: Health and Nutritional Status of Filipino Adults, 20-59 Years Oldzvfvr95hrkNo ratings yet
- Students - Purdue Agribusiness Simulation Spreadsheets Group 2 (Period 3)Document65 pagesStudents - Purdue Agribusiness Simulation Spreadsheets Group 2 (Period 3)Ifechukwu AnunobiNo ratings yet
- MediCall - Nursing Informatics App Proposal PDFDocument20 pagesMediCall - Nursing Informatics App Proposal PDFPaul MarloweNo ratings yet
- FM Exam PracticeDocument12 pagesFM Exam Practicejyotiguptapr7991No ratings yet
- Public Transport Services 31.01.23Document15 pagesPublic Transport Services 31.01.23adi.sNo ratings yet
- RepresentativenessDocument4 pagesRepresentativenessHarshvardhini MunwarNo ratings yet
- Childrens FBC Reference Ranges PDFDocument1 pageChildrens FBC Reference Ranges PDFnisha justinNo ratings yet
- Childrens FBC Reference RangesDocument1 pageChildrens FBC Reference RangesPat MobileNo ratings yet
- Residents Aged 65 and Older: The Share of Population Age 65+ Continues To GrowDocument6 pagesResidents Aged 65 and Older: The Share of Population Age 65+ Continues To GrowM-NCPPCNo ratings yet
- AGE COHORTS & MEDIAN, 1990-2010: Montgomery County, MarylandDocument1 pageAGE COHORTS & MEDIAN, 1990-2010: Montgomery County, MarylandM-NCPPCNo ratings yet
- COVID-19 Mass Vaccination Analysis 3-22-2021-UPDATEDocument11 pagesCOVID-19 Mass Vaccination Analysis 3-22-2021-UPDATEDavid IbanezNo ratings yet
- DP04 Selected Housing Characteristics 2006-2010 American Community Survey 5-Year EstimatesDocument4 pagesDP04 Selected Housing Characteristics 2006-2010 American Community Survey 5-Year Estimatesbranthom88No ratings yet
- Gantt - Brisas de Pencahue II 284 Viv (DS 49) - REPROGRAMACION 13-10Document424 pagesGantt - Brisas de Pencahue II 284 Viv (DS 49) - REPROGRAMACION 13-10jneiracNo ratings yet
- BLS Characteristics of Minimum Wage Workers 2015Document33 pagesBLS Characteristics of Minimum Wage Workers 2015Stephen LoiaconiNo ratings yet
- Calculo CAPMDocument142 pagesCalculo CAPMcrackesteban6536No ratings yet
- Population by Age in 2010: Percent Change 2010 2000Document8 pagesPopulation by Age in 2010: Percent Change 2010 2000Matthew TaylorNo ratings yet
- Chapter-4 1Document17 pagesChapter-4 1Cindy Jane OmillioNo ratings yet
- Heg Ltd. (Amisha Agrawal)Document5 pagesHeg Ltd. (Amisha Agrawal)Amit ChhabriaNo ratings yet
- Aaaa Data AnalysisDocument104 pagesAaaa Data AnalysisAnugya BaliyanNo ratings yet
- Analyse Bus 31-12-2018Document198 pagesAnalyse Bus 31-12-2018n.02thierryNo ratings yet
- Unit+3+Changing+Populations+Assignment+ +2c+Cgc1d1+ +Canada+Population+PyramidDocument4 pagesUnit+3+Changing+Populations+Assignment+ +2c+Cgc1d1+ +Canada+Population+PyramidAfnansstuffNo ratings yet
- 2011 Reader DemographicsDocument2 pages2011 Reader DemographicsThe Florida Times-UnionNo ratings yet
- Statistik Deskriptif: Lampiran 3Document19 pagesStatistik Deskriptif: Lampiran 3'eni Freaks'No ratings yet
- INITIALDocument19 pagesINITIALEloisa EspadillaNo ratings yet
- July 2010 Labor Demographics 09.02Document2 pagesJuly 2010 Labor Demographics 09.02JonHealeyNo ratings yet
- Total Population, Age 18+, and Children Under 18, 2010: Montgomery County, MarylandDocument6 pagesTotal Population, Age 18+, and Children Under 18, 2010: Montgomery County, MarylandM-NCPPCNo ratings yet
- Gaydemographics USA 2000 Census Gay State-NDocument2 pagesGaydemographics USA 2000 Census Gay State-N24x7emarketingNo ratings yet
- Decennialdp2020.dp1 2024 05 22T163745Document192 pagesDecennialdp2020.dp1 2024 05 22T163745benhaddouche.imraneNo ratings yet
- Table 210-06101Document28 pagesTable 210-06101Benito Santana RiosNo ratings yet
- Practica Sem 7 - Finanzas CoorpDocument9 pagesPractica Sem 7 - Finanzas Coorpabimm2502No ratings yet
- Central Region Political Opinion Poll - October 2021Document23 pagesCentral Region Political Opinion Poll - October 2021The Star Kenya100% (1)
- 4th NAOS MeetingDocument19 pages4th NAOS MeetingjudymelicioNo ratings yet
- Math Practice Simplified: Decimals & Percents (Book H): Practicing the Concepts of Decimals and PercentagesFrom EverandMath Practice Simplified: Decimals & Percents (Book H): Practicing the Concepts of Decimals and PercentagesRating: 5 out of 5 stars5/5 (3)
- VAW Content AnalysisDocument25 pagesVAW Content AnalysisIrene NwoyeNo ratings yet
- Manhole Profiling Tool To Help Determine Serious EventsDocument6 pagesManhole Profiling Tool To Help Determine Serious EventsIrene NwoyeNo ratings yet
- NYPD Annual Firearms Discharge Report 2013Document74 pagesNYPD Annual Firearms Discharge Report 2013jcm23No ratings yet
- Criminal Court Summonses in NYC CUNY Law School ReportDocument10 pagesCriminal Court Summonses in NYC CUNY Law School ReportIrene NwoyeNo ratings yet
- Project of WCM 19c0h008 Madhu MaamDocument41 pagesProject of WCM 19c0h008 Madhu MaamSourav TiwariNo ratings yet
- EPM-1183 Ethics, Code of Conduct & Professional PracticeDocument41 pagesEPM-1183 Ethics, Code of Conduct & Professional PracticeDev ThackerNo ratings yet
- Tender Bids From March 2012 To April 2017Document62 pagesTender Bids From March 2012 To April 2017scribd_109097762No ratings yet
- Prospectus19 20 Part2 PDFDocument76 pagesProspectus19 20 Part2 PDFSanand M KNo ratings yet
- The Literary Comparison Contrast EssayDocument7 pagesThe Literary Comparison Contrast EssayThapelo SebolaiNo ratings yet
- (GUARANTEED RATE AFFINITY) & (8905 BEAVER FALLS) - UCC1 Financial Statement LIENDocument9 pages(GUARANTEED RATE AFFINITY) & (8905 BEAVER FALLS) - UCC1 Financial Statement LIENHakim-Aarifah BeyNo ratings yet
- Ep08 Measuring The Concentration of Sugar Solutions With Optical ActivityDocument2 pagesEp08 Measuring The Concentration of Sugar Solutions With Optical ActivityKw ChanNo ratings yet
- Comparative and Superlative Adjectives PresentationDocument15 pagesComparative and Superlative Adjectives Presentationapi-248688582No ratings yet
- Direct Object: Subjec T Verb ObjectDocument6 pagesDirect Object: Subjec T Verb ObjectHaerani Ester SiahaanNo ratings yet
- HBO Types of CommunicationsDocument14 pagesHBO Types of CommunicationsJENEVIE B. ODONNo ratings yet
- Blockchain-Enabled Drug Supply Chain: Sheetal Nayak, Prachitee Shirvale, Nihar Naik, Snehpriya Khul, Amol SawantDocument4 pagesBlockchain-Enabled Drug Supply Chain: Sheetal Nayak, Prachitee Shirvale, Nihar Naik, Snehpriya Khul, Amol SawantWaspNo ratings yet
- Module 2 UrineDocument17 pagesModule 2 UrineGiulia Nădășan-CozmaNo ratings yet
- # Pembagian Kelas Alkes Per KategoriDocument41 pages# Pembagian Kelas Alkes Per KategoriR.A.R TVNo ratings yet
- Womens EssentialsDocument50 pagesWomens EssentialsNoor-uz-Zamaan AcademyNo ratings yet
- Karakteristik Material Baja St.37 Dengan Temperatur Dan Waktu Pada Uji Heat Treatment Menggunakan FurnaceDocument14 pagesKarakteristik Material Baja St.37 Dengan Temperatur Dan Waktu Pada Uji Heat Treatment Menggunakan FurnaceYudii NggiNo ratings yet
- Landmark Cases Oposa vs. Factoran, JRDocument7 pagesLandmark Cases Oposa vs. Factoran, JRChristine JungoyNo ratings yet
- SWM Notes IIDocument8 pagesSWM Notes IIBeast gaming liveNo ratings yet
- Testi I Pare YlberiDocument6 pagesTesti I Pare YlberiAhmetNo ratings yet
- Note On F3 SC C2 TransportationDocument4 pagesNote On F3 SC C2 Transportationgan tong hock a.k.a ganosNo ratings yet
- (Promotion Policy of APDCL) by Debasish Choudhury: RecommendationDocument1 page(Promotion Policy of APDCL) by Debasish Choudhury: RecommendationDebasish ChoudhuryNo ratings yet
- Lion of The North - Rules & ScenariosDocument56 pagesLion of The North - Rules & ScenariosBrant McClureNo ratings yet
- Module 1Document17 pagesModule 1Richilien Teneso43% (14)
- Chords Like Jeff BuckleyDocument5 pagesChords Like Jeff BuckleyTDROCKNo ratings yet
- Negotiation ProcessDocument6 pagesNegotiation ProcessAkshay NashineNo ratings yet
- Assignment 11 STM DavisDocument8 pagesAssignment 11 STM Davisrajesh laddhaNo ratings yet
- UMRAH Supplications DUADocument10 pagesUMRAH Supplications DUAsamNo ratings yet
- A Shoe Story: Look at Manny's Shoes. Where Do You Think They Have Been?Document8 pagesA Shoe Story: Look at Manny's Shoes. Where Do You Think They Have Been?Renier John BambaNo ratings yet




























































































You might also like
- Rebirth of The Useless Bastard SonDocument32 pagesRebirth of The Useless Bastard Sonthe.untamed.annaNo ratings yet
- CP-563E, CS-563E, CP-573E, CS-573E, CS-583E, CP-663E, CS-663E and CS-683E Vibratory Compactor Electrical SystemDocument11 pagesCP-563E, CS-563E, CP-573E, CS-573E, CS-583E, CP-663E, CS-663E and CS-683E Vibratory Compactor Electrical SystemMohamed Mohamed100% (3)
- The Most Important Biblical Discovery of Our TimeDocument21 pagesThe Most Important Biblical Discovery of Our Timececampillo100% (1)
- NYC Population FactFinderDocument5 pagesNYC Population FactFinderDonnie BoscoNo ratings yet
- CDP-2) Demographic ProfileDocument17 pagesCDP-2) Demographic ProfileJohn Eric CatalanNo ratings yet
- Michigan Voting DemocraphicsDocument18 pagesMichigan Voting DemocraphicsAnonymous 5fWuzHNo ratings yet
- San Juan - 16 - 5YR - 2016Document21 pagesSan Juan - 16 - 5YR - 2016Jesus RosarioNo ratings yet
- Bank Mandiri Taspen BPD Sumatera Barat Bank Mestika: AssetDocument2 pagesBank Mandiri Taspen BPD Sumatera Barat Bank Mestika: AssetMartha Gracia ManurungNo ratings yet
- Regional DEED Data, Becker County, Nov. 15, 2021Document8 pagesRegional DEED Data, Becker County, Nov. 15, 2021Michael AchterlingNo ratings yet
- DP03 Selected Economic Characteristics 2012 American Community Survey 1-Year EstimatesDocument5 pagesDP03 Selected Economic Characteristics 2012 American Community Survey 1-Year Estimatesapi-28460727No ratings yet
- Chapter IiiDocument3 pagesChapter IiiJm SandiegoNo ratings yet
- ReportDocument8 pagesReportHuy DươngNo ratings yet
- Chapter 4 and 5 FinalisedDocument8 pagesChapter 4 and 5 FinalisedJaya DeviNo ratings yet
- Aspect 1 Age Percentage SheetDocument1 pageAspect 1 Age Percentage SheetmoobinamalNo ratings yet
- Age Distribution of Motor Vehicles As at 30 November 2023: Age (Years) Cars Motorcycles Buses Goods & Other VehiclesDocument11 pagesAge Distribution of Motor Vehicles As at 30 November 2023: Age (Years) Cars Motorcycles Buses Goods & Other VehiclesJunxian LiuNo ratings yet
- Puerto Rico 20 5YR 2020 0Document18 pagesPuerto Rico 20 5YR 2020 0Francisco MéndezNo ratings yet
- Acs 15 1yr DP04Document8 pagesAcs 15 1yr DP04Justin CarderNo ratings yet
- Union County Demographic Census Data, 2010Document4 pagesUnion County Demographic Census Data, 2010The State NewspaperNo ratings yet
- CINA Deluxe DQP For Breast ER PR and Her2 Prognostic Factors Manxia 2 9 ..Document12 pagesCINA Deluxe DQP For Breast ER PR and Her2 Prognostic Factors Manxia 2 9 ..MayNo ratings yet
- Cookeville, TN Demographics 2016Document7 pagesCookeville, TN Demographics 2016blake fahyNo ratings yet
- Final Na Nga BaDocument24 pagesFinal Na Nga BaJomarCalacagNo ratings yet
- Marriage and Divorce Statistics For South Korea 2023. (Korean)Document59 pagesMarriage and Divorce Statistics For South Korea 2023. (Korean)8hxynhdr97No ratings yet
- Bamberg County Demographic Census Data, 2010Document4 pagesBamberg County Demographic Census Data, 2010The State NewspaperNo ratings yet
- Allen StatsDocument2 pagesAllen Statsapi-332368008No ratings yet
- Civilian Labor Force ProfileDocument2 pagesCivilian Labor Force Profilefariasr23No ratings yet
- Appendix A National ProfileDocument17 pagesAppendix A National ProfileTimelendersNo ratings yet
- Age Why - Do - You - Like - The - Shop CrosstabulationDocument11 pagesAge Why - Do - You - Like - The - Shop CrosstabulationLatif AbdulNo ratings yet
- Detroit Census ACS - 11 - 5YR - DP03Document5 pagesDetroit Census ACS - 11 - 5YR - DP03Stephen BoyleNo ratings yet
- Determinants of Performance A Case of Life Insurance Sector of PakistanDocument28 pagesDeterminants of Performance A Case of Life Insurance Sector of PakistanM SadiqNo ratings yet
- DAFNA FactSheetDocument2 pagesDAFNA FactSheetfxarb098No ratings yet
- Expanded National Nutrition Survey: 2019 Results: Health and Nutritional Status of Filipino Adults, 20-59 Years OldDocument61 pagesExpanded National Nutrition Survey: 2019 Results: Health and Nutritional Status of Filipino Adults, 20-59 Years Oldzvfvr95hrkNo ratings yet
- Students - Purdue Agribusiness Simulation Spreadsheets Group 2 (Period 3)Document65 pagesStudents - Purdue Agribusiness Simulation Spreadsheets Group 2 (Period 3)Ifechukwu AnunobiNo ratings yet
- MediCall - Nursing Informatics App Proposal PDFDocument20 pagesMediCall - Nursing Informatics App Proposal PDFPaul MarloweNo ratings yet
- FM Exam PracticeDocument12 pagesFM Exam Practicejyotiguptapr7991No ratings yet
- Public Transport Services 31.01.23Document15 pagesPublic Transport Services 31.01.23adi.sNo ratings yet
- RepresentativenessDocument4 pagesRepresentativenessHarshvardhini MunwarNo ratings yet
- Childrens FBC Reference Ranges PDFDocument1 pageChildrens FBC Reference Ranges PDFnisha justinNo ratings yet
- Childrens FBC Reference RangesDocument1 pageChildrens FBC Reference RangesPat MobileNo ratings yet
- Residents Aged 65 and Older: The Share of Population Age 65+ Continues To GrowDocument6 pagesResidents Aged 65 and Older: The Share of Population Age 65+ Continues To GrowM-NCPPCNo ratings yet
- AGE COHORTS & MEDIAN, 1990-2010: Montgomery County, MarylandDocument1 pageAGE COHORTS & MEDIAN, 1990-2010: Montgomery County, MarylandM-NCPPCNo ratings yet
- COVID-19 Mass Vaccination Analysis 3-22-2021-UPDATEDocument11 pagesCOVID-19 Mass Vaccination Analysis 3-22-2021-UPDATEDavid IbanezNo ratings yet
- DP04 Selected Housing Characteristics 2006-2010 American Community Survey 5-Year EstimatesDocument4 pagesDP04 Selected Housing Characteristics 2006-2010 American Community Survey 5-Year Estimatesbranthom88No ratings yet
- Gantt - Brisas de Pencahue II 284 Viv (DS 49) - REPROGRAMACION 13-10Document424 pagesGantt - Brisas de Pencahue II 284 Viv (DS 49) - REPROGRAMACION 13-10jneiracNo ratings yet
- BLS Characteristics of Minimum Wage Workers 2015Document33 pagesBLS Characteristics of Minimum Wage Workers 2015Stephen LoiaconiNo ratings yet
- Calculo CAPMDocument142 pagesCalculo CAPMcrackesteban6536No ratings yet
- Population by Age in 2010: Percent Change 2010 2000Document8 pagesPopulation by Age in 2010: Percent Change 2010 2000Matthew TaylorNo ratings yet
- Chapter-4 1Document17 pagesChapter-4 1Cindy Jane OmillioNo ratings yet
- Heg Ltd. (Amisha Agrawal)Document5 pagesHeg Ltd. (Amisha Agrawal)Amit ChhabriaNo ratings yet
- Aaaa Data AnalysisDocument104 pagesAaaa Data AnalysisAnugya BaliyanNo ratings yet
- Analyse Bus 31-12-2018Document198 pagesAnalyse Bus 31-12-2018n.02thierryNo ratings yet
- Unit+3+Changing+Populations+Assignment+ +2c+Cgc1d1+ +Canada+Population+PyramidDocument4 pagesUnit+3+Changing+Populations+Assignment+ +2c+Cgc1d1+ +Canada+Population+PyramidAfnansstuffNo ratings yet
- 2011 Reader DemographicsDocument2 pages2011 Reader DemographicsThe Florida Times-UnionNo ratings yet
- Statistik Deskriptif: Lampiran 3Document19 pagesStatistik Deskriptif: Lampiran 3'eni Freaks'No ratings yet
- INITIALDocument19 pagesINITIALEloisa EspadillaNo ratings yet
- July 2010 Labor Demographics 09.02Document2 pagesJuly 2010 Labor Demographics 09.02JonHealeyNo ratings yet
- Total Population, Age 18+, and Children Under 18, 2010: Montgomery County, MarylandDocument6 pagesTotal Population, Age 18+, and Children Under 18, 2010: Montgomery County, MarylandM-NCPPCNo ratings yet
- Gaydemographics USA 2000 Census Gay State-NDocument2 pagesGaydemographics USA 2000 Census Gay State-N24x7emarketingNo ratings yet
- Decennialdp2020.dp1 2024 05 22T163745Document192 pagesDecennialdp2020.dp1 2024 05 22T163745benhaddouche.imraneNo ratings yet
- Table 210-06101Document28 pagesTable 210-06101Benito Santana RiosNo ratings yet
- Practica Sem 7 - Finanzas CoorpDocument9 pagesPractica Sem 7 - Finanzas Coorpabimm2502No ratings yet
- Central Region Political Opinion Poll - October 2021Document23 pagesCentral Region Political Opinion Poll - October 2021The Star Kenya100% (1)
- 4th NAOS MeetingDocument19 pages4th NAOS MeetingjudymelicioNo ratings yet
- Math Practice Simplified: Decimals & Percents (Book H): Practicing the Concepts of Decimals and PercentagesFrom EverandMath Practice Simplified: Decimals & Percents (Book H): Practicing the Concepts of Decimals and PercentagesRating: 5 out of 5 stars5/5 (3)
- VAW Content AnalysisDocument25 pagesVAW Content AnalysisIrene NwoyeNo ratings yet
- Manhole Profiling Tool To Help Determine Serious EventsDocument6 pagesManhole Profiling Tool To Help Determine Serious EventsIrene NwoyeNo ratings yet
- NYPD Annual Firearms Discharge Report 2013Document74 pagesNYPD Annual Firearms Discharge Report 2013jcm23No ratings yet
- Criminal Court Summonses in NYC CUNY Law School ReportDocument10 pagesCriminal Court Summonses in NYC CUNY Law School ReportIrene NwoyeNo ratings yet
- Project of WCM 19c0h008 Madhu MaamDocument41 pagesProject of WCM 19c0h008 Madhu MaamSourav TiwariNo ratings yet
- EPM-1183 Ethics, Code of Conduct & Professional PracticeDocument41 pagesEPM-1183 Ethics, Code of Conduct & Professional PracticeDev ThackerNo ratings yet
- Tender Bids From March 2012 To April 2017Document62 pagesTender Bids From March 2012 To April 2017scribd_109097762No ratings yet
- Prospectus19 20 Part2 PDFDocument76 pagesProspectus19 20 Part2 PDFSanand M KNo ratings yet
- The Literary Comparison Contrast EssayDocument7 pagesThe Literary Comparison Contrast EssayThapelo SebolaiNo ratings yet
- (GUARANTEED RATE AFFINITY) & (8905 BEAVER FALLS) - UCC1 Financial Statement LIENDocument9 pages(GUARANTEED RATE AFFINITY) & (8905 BEAVER FALLS) - UCC1 Financial Statement LIENHakim-Aarifah BeyNo ratings yet
- Ep08 Measuring The Concentration of Sugar Solutions With Optical ActivityDocument2 pagesEp08 Measuring The Concentration of Sugar Solutions With Optical ActivityKw ChanNo ratings yet
- Comparative and Superlative Adjectives PresentationDocument15 pagesComparative and Superlative Adjectives Presentationapi-248688582No ratings yet
- Direct Object: Subjec T Verb ObjectDocument6 pagesDirect Object: Subjec T Verb ObjectHaerani Ester SiahaanNo ratings yet
- HBO Types of CommunicationsDocument14 pagesHBO Types of CommunicationsJENEVIE B. ODONNo ratings yet
- Blockchain-Enabled Drug Supply Chain: Sheetal Nayak, Prachitee Shirvale, Nihar Naik, Snehpriya Khul, Amol SawantDocument4 pagesBlockchain-Enabled Drug Supply Chain: Sheetal Nayak, Prachitee Shirvale, Nihar Naik, Snehpriya Khul, Amol SawantWaspNo ratings yet
- Module 2 UrineDocument17 pagesModule 2 UrineGiulia Nădășan-CozmaNo ratings yet
- # Pembagian Kelas Alkes Per KategoriDocument41 pages# Pembagian Kelas Alkes Per KategoriR.A.R TVNo ratings yet
- Womens EssentialsDocument50 pagesWomens EssentialsNoor-uz-Zamaan AcademyNo ratings yet
- Karakteristik Material Baja St.37 Dengan Temperatur Dan Waktu Pada Uji Heat Treatment Menggunakan FurnaceDocument14 pagesKarakteristik Material Baja St.37 Dengan Temperatur Dan Waktu Pada Uji Heat Treatment Menggunakan FurnaceYudii NggiNo ratings yet
- Landmark Cases Oposa vs. Factoran, JRDocument7 pagesLandmark Cases Oposa vs. Factoran, JRChristine JungoyNo ratings yet
- SWM Notes IIDocument8 pagesSWM Notes IIBeast gaming liveNo ratings yet
- Testi I Pare YlberiDocument6 pagesTesti I Pare YlberiAhmetNo ratings yet
- Note On F3 SC C2 TransportationDocument4 pagesNote On F3 SC C2 Transportationgan tong hock a.k.a ganosNo ratings yet
- (Promotion Policy of APDCL) by Debasish Choudhury: RecommendationDocument1 page(Promotion Policy of APDCL) by Debasish Choudhury: RecommendationDebasish ChoudhuryNo ratings yet
- Lion of The North - Rules & ScenariosDocument56 pagesLion of The North - Rules & ScenariosBrant McClureNo ratings yet
- Module 1Document17 pagesModule 1Richilien Teneso43% (14)
- Chords Like Jeff BuckleyDocument5 pagesChords Like Jeff BuckleyTDROCKNo ratings yet
- Negotiation ProcessDocument6 pagesNegotiation ProcessAkshay NashineNo ratings yet
- Assignment 11 STM DavisDocument8 pagesAssignment 11 STM Davisrajesh laddhaNo ratings yet
- UMRAH Supplications DUADocument10 pagesUMRAH Supplications DUAsamNo ratings yet
- A Shoe Story: Look at Manny's Shoes. Where Do You Think They Have Been?Document8 pagesA Shoe Story: Look at Manny's Shoes. Where Do You Think They Have Been?Renier John BambaNo ratings yet