
Experiment: An Exercise Designed To Determine The Effects of One or
Experiment: An Exercise Designed To Determine The Effects of One or
You might also like
- Solution Manual For Design and Analysis of Experiments 9th Edition - Douglas C. MontgomeryDocument25 pagesSolution Manual For Design and Analysis of Experiments 9th Edition - Douglas C. MontgomerySaleh22% (9)
- Field Experimental Designs in AgricultureDocument12 pagesField Experimental Designs in AgricultureBoryana100% (2)
- Hypothesis TestingDocument12 pagesHypothesis TestingJp Combis100% (1)
- Statistics WorkDocument2 pagesStatistics WorkBrittanyWilliams50% (2)
- EFREN S. TELLERMO-Course ProfessorDocument11 pagesEFREN S. TELLERMO-Course ProfessorRizalyn GepilanoNo ratings yet
- Programmed Statistics (Question-Answers)Document551 pagesProgrammed Statistics (Question-Answers)nitesh kewat93% (42)
- Quiz 3Document6 pagesQuiz 3BibliophilioManiac100% (1)
- Sampling TheoryDocument108 pagesSampling TheoryAbduli SalimuNo ratings yet
- BIBDDocument109 pagesBIBDShikha Kashyap100% (1)
- Chapter4 Anova Experimental Design AnalysisDocument31 pagesChapter4 Anova Experimental Design AnalysisAnup ŠářkarNo ratings yet
- 2 Hypothesis Testing (Part 1)Document8 pages2 Hypothesis Testing (Part 1)Von Adrian Inociaan HernandezNo ratings yet
- One Sample T-TestDocument25 pagesOne Sample T-Testgerwin dagumNo ratings yet
- Chapter4 Anova Experimental Design Analysis PDFDocument31 pagesChapter4 Anova Experimental Design Analysis PDFsricharitha6702No ratings yet
- Chi Square HandaoutsDocument6 pagesChi Square HandaoutsSharmaine CondinoNo ratings yet
- HypothesisDocument29 pagesHypothesisdionvenus100% (1)
- Handout 1 Experiment DesignDocument15 pagesHandout 1 Experiment DesignFleming MwijukyeNo ratings yet
- 11 BS201 Prob and Stat - Ch5Document17 pages11 BS201 Prob and Stat - Ch5knmounika2395No ratings yet
- Design Notes-1Document72 pagesDesign Notes-1Samuel GitongaNo ratings yet
- STAT 8200 - Design and Analysis of Experiments For Research Workers - Lecture NotesDocument100 pagesSTAT 8200 - Design and Analysis of Experiments For Research Workers - Lecture NotesGizawNo ratings yet
- Design and Analysis of ExperimentsDocument6 pagesDesign and Analysis of ExperimentsFatima SarwarNo ratings yet
- C22 P09 Chi Square TestDocument33 pagesC22 P09 Chi Square TestsandeepNo ratings yet
- Engineering Data and Analysis - Notes 14Document9 pagesEngineering Data and Analysis - Notes 14Chou Xi MinNo ratings yet
- Control of Experimental Error: Bull's Eye Represents The True Value of The Parameter You Wish To EstimateDocument27 pagesControl of Experimental Error: Bull's Eye Represents The True Value of The Parameter You Wish To EstimateIsmael NeuNo ratings yet
- Chapter 1Document22 pagesChapter 1Adilhunjra HunjraNo ratings yet
- Hypothesis TestingDocument16 pagesHypothesis Testingbdsumaiya314No ratings yet
- Chapter 9Document14 pagesChapter 9Khay OngNo ratings yet
- Science Research Iii: Second Quarter-Module 6 Hypothesis Testing For The Means - Two Sample (Independent Sample)Document9 pagesScience Research Iii: Second Quarter-Module 6 Hypothesis Testing For The Means - Two Sample (Independent Sample)marc marcNo ratings yet
- BS 1 4Document74 pagesBS 1 4archit sahayNo ratings yet
- The Central Limit Theorem and Hypothesis Testing FinalDocument29 pagesThe Central Limit Theorem and Hypothesis Testing FinalMichelleneChenTadle100% (1)
- Intro To Experimental DesignDocument21 pagesIntro To Experimental DesignmercyNo ratings yet
- Research Design Type of Study Exploratory of Formulative Descriptive/DiagnosticDocument3 pagesResearch Design Type of Study Exploratory of Formulative Descriptive/DiagnosticAhmad YassirNo ratings yet
- Principles of Experimental DesignDocument14 pagesPrinciples of Experimental Designsunil dhanjuNo ratings yet
- 1.6 Experimental Design Notes MAT 1260Document3 pages1.6 Experimental Design Notes MAT 1260esch9150No ratings yet
- Mod. 8 A T Test Between MeansDocument20 pagesMod. 8 A T Test Between MeansPhelsie Print ShopNo ratings yet
- Clay 2017Document13 pagesClay 2017everst gouveiaNo ratings yet
- ECOLAPP NotesDocument29 pagesECOLAPP NotesyarahbitangNo ratings yet
- Research 1 - Module 5Document3 pagesResearch 1 - Module 5Arnold CabanerosNo ratings yet
- Sample Size Determination: BY DR Zubair K.ODocument43 pagesSample Size Determination: BY DR Zubair K.OOK ViewNo ratings yet
- Sample Size Determination: BY DR Zubair K.ODocument43 pagesSample Size Determination: BY DR Zubair K.OMakmur SejatiNo ratings yet
- Design of Experiment (G2)Document26 pagesDesign of Experiment (G2)YANA UPADHYAYNo ratings yet
- Statistics & Probability Q4 - Week 5-6Document13 pagesStatistics & Probability Q4 - Week 5-6Rayezeus Jaiden Del RosarioNo ratings yet
- X. Understanding Hypothesis Testing PDFDocument38 pagesX. Understanding Hypothesis Testing PDFBrian GarciaNo ratings yet
- Hypothesis Testing TopicDocument18 pagesHypothesis Testing TopicjermyneducusinandresNo ratings yet
- Measurement 6th Sem (H) DSE4 Lec 4 05 05 2020Document19 pagesMeasurement 6th Sem (H) DSE4 Lec 4 05 05 2020JiisbbbduNo ratings yet
- Testing of HypothesisDocument18 pagesTesting of HypothesisPavan DeshpandeNo ratings yet
- Ag213 Unit 5 Online PDFDocument29 pagesAg213 Unit 5 Online PDFNaiker KaveetNo ratings yet
- Chapter 5: Sampling Distributions & Hypothesis TestingDocument19 pagesChapter 5: Sampling Distributions & Hypothesis TestingAbhishek KushwahaNo ratings yet
- Module 3b - One Sample Tests - Docx 1 PDFDocument12 pagesModule 3b - One Sample Tests - Docx 1 PDFSam Rae LimNo ratings yet
- Reviewer CHAPTER 12Document8 pagesReviewer CHAPTER 12Krisha AvorqueNo ratings yet
- AE 108 Handout No.2Document8 pagesAE 108 Handout No.2hambalos broadcastingincNo ratings yet
- Lecture 4Document32 pagesLecture 4junaidNo ratings yet
- STAT Q4 Week 3 Enhanced.v1Document10 pagesSTAT Q4 Week 3 Enhanced.v1queenkysultan14No ratings yet
- Hypothesis Testing RevisedDocument22 pagesHypothesis Testing RevisedBrafiel Claire Curambao LibayNo ratings yet
- MA113-CHAPTER 6Document3 pagesMA113-CHAPTER 6Mark SolivaNo ratings yet
- Quarter 4 - Week 3: Department of Education - Republic of The PhilippinesDocument12 pagesQuarter 4 - Week 3: Department of Education - Republic of The PhilippinesARNEL B. GONZALESNo ratings yet
- Research 3 Quarter 3 LESSON-2-HYPOTHESIS-TESTINGDocument29 pagesResearch 3 Quarter 3 LESSON-2-HYPOTHESIS-TESTINGRaven Third-partyAccNo ratings yet
- Hypothesis-TestingDocument47 pagesHypothesis-TestingJOSE EPHRAIM MAGLAQUENo ratings yet
- R Codes For Randomized Complete Block Design: International Journal of Information Science and SystemDocument8 pagesR Codes For Randomized Complete Block Design: International Journal of Information Science and SystemDr-Rabia AlmamalookNo ratings yet
- Statistics and Probability: Quarter 4 - Module 3: Test Statistic On Population Mean Week 3 To Week 4Document20 pagesStatistics and Probability: Quarter 4 - Module 3: Test Statistic On Population Mean Week 3 To Week 4JoshNo ratings yet
- 4 Research Design Useful Daily LIfeDocument10 pages4 Research Design Useful Daily LIfeTrisha Joy Dela CruzNo ratings yet
- Sample Sizes for Clinical, Laboratory and Epidemiology StudiesFrom EverandSample Sizes for Clinical, Laboratory and Epidemiology StudiesNo ratings yet
- Gen PTL (MM) NPT % Pollen Stainability of Pollen (IKI) (Mean Sem) (Mean Sem) Germ %viable %non-ViableDocument5 pagesGen PTL (MM) NPT % Pollen Stainability of Pollen (IKI) (Mean Sem) (Mean Sem) Germ %viable %non-ViableTeflon SlimNo ratings yet
- Regional Hybrid TrialDocument8 pagesRegional Hybrid TrialTeflon SlimNo ratings yet
- R Codes For My Germination DataDocument1 pageR Codes For My Germination DataTeflon SlimNo ratings yet
- Obs Source Ss DF Ms Fvalue Probf 1 2 3 4: YieldDocument292 pagesObs Source Ss DF Ms Fvalue Probf 1 2 3 4: YieldTeflon SlimNo ratings yet
- File Name: M0928 Location: Abuja PLO: Rep Entry Pedigree Yieldin Yieldu Plstin Plstun Dyskin DyskunDocument48 pagesFile Name: M0928 Location: Abuja PLO: Rep Entry Pedigree Yieldin Yieldu Plstin Plstun Dyskin DyskunTeflon SlimNo ratings yet
- Interploidy Hybridization in Sympatric Zones The FormationDocument14 pagesInterploidy Hybridization in Sympatric Zones The FormationTeflon SlimNo ratings yet
- Table 3. GCA Effects of Extra-Early Yellow Inbred Parents For Grain Yield and Other Agronomic Traits Evaluated Across Test Environments in 2011Document1 pageTable 3. GCA Effects of Extra-Early Yellow Inbred Parents For Grain Yield and Other Agronomic Traits Evaluated Across Test Environments in 2011Teflon SlimNo ratings yet
- Table 2Document1 pageTable 2Teflon SlimNo ratings yet
- Hybrid Yield Pollen Dysk ASI PHT EPP PaspDocument46 pagesHybrid Yield Pollen Dysk ASI PHT EPP PaspTeflon SlimNo ratings yet
- CS 563 Instructor: A. TettehDocument22 pagesCS 563 Instructor: A. TettehTeflon SlimNo ratings yet
- Table 4Document1 pageTable 4Teflon SlimNo ratings yet
- Table 1. Description of The 20 Yellow-Endosperm Entry Pedigree Reaction To Low-N Reaction To Striga-InfestationDocument1 pageTable 1. Description of The 20 Yellow-Endosperm Entry Pedigree Reaction To Low-N Reaction To Striga-InfestationTeflon SlimNo ratings yet
- Results FileDocument159 pagesResults FileTeflon SlimNo ratings yet
- Responses To Reviewers' Comments CommentDocument4 pagesResponses To Reviewers' Comments CommentTeflon SlimNo ratings yet
- Anhu 12083Document8 pagesAnhu 12083Teflon SlimNo ratings yet
- Diallel ProgenyDocument12 pagesDiallel ProgenyTeflon SlimNo ratings yet
- Inbred Lines Evaluated in Nigeria, 2011.: MaizeDocument1 pageInbred Lines Evaluated in Nigeria, 2011.: MaizeTeflon SlimNo ratings yet
- Fig 1Document1 pageFig 1Teflon SlimNo ratings yet
- Figure 1Document1 pageFigure 1Teflon SlimNo ratings yet
- Lecture 5Document14 pagesLecture 5Teflon SlimNo ratings yet
- CS 563 October 15, 2018 Components of Variance: P G + E P A + D + I + EDocument13 pagesCS 563 October 15, 2018 Components of Variance: P G + E P A + D + I + ETeflon SlimNo ratings yet
- Correlation and Regression Analyses: Measurement of More Than One Variable On Each Experimental or Observational UnitDocument23 pagesCorrelation and Regression Analyses: Measurement of More Than One Variable On Each Experimental or Observational UnitTeflon SlimNo ratings yet
- RE-sequencing and MarkersDocument24 pagesRE-sequencing and MarkersTeflon SlimNo ratings yet
- Trapping and Identifying Mealybugs in Oregon VineyardsDocument5 pagesTrapping and Identifying Mealybugs in Oregon VineyardsTeflon SlimNo ratings yet
- Methods of Insect CollectionDocument2 pagesMethods of Insect CollectionTeflon SlimNo ratings yet
- Geographical Distribution of The Cacao Swollen Shoot Virus Molecular Variability in GhanaDocument8 pagesGeographical Distribution of The Cacao Swollen Shoot Virus Molecular Variability in GhanaTeflon SlimNo ratings yet
- Mealybugs (Hemiptera: Pseudococcidae) Species On Economically Important Fruit Crops in Sri LankaDocument15 pagesMealybugs (Hemiptera: Pseudococcidae) Species On Economically Important Fruit Crops in Sri LankaTeflon SlimNo ratings yet
- AS-Statistics-Facts-and-Definitions-Quiz Answers PT 1Document2 pagesAS-Statistics-Facts-and-Definitions-Quiz Answers PT 1cokonkwoNo ratings yet
- Stat - Prob 11 - Q3 - SLM - WK2Document11 pagesStat - Prob 11 - Q3 - SLM - WK2Lynelle Quinal80% (5)
- Everything You Ever Wanted To Know About Statistics: Prof. Andy FieldDocument37 pagesEverything You Ever Wanted To Know About Statistics: Prof. Andy FieldMohan PudasainiNo ratings yet
- Experiment 1 Formal Report: Application of Statistical Concepts in The Determination of Weight Variation in SamplesDocument6 pagesExperiment 1 Formal Report: Application of Statistical Concepts in The Determination of Weight Variation in SamplesNathalie Dagmang67% (3)
- Department of Statistics: Distribution Theory IDocument102 pagesDepartment of Statistics: Distribution Theory Isal27adamNo ratings yet
- 2 Testing Hypothesis Levin Rubin Chpt8Document11 pages2 Testing Hypothesis Levin Rubin Chpt8ashokgroy121100% (1)
- MGT 524 Quantitative Analysis Sohana Factors Group Assignment DraftsDocument14 pagesMGT 524 Quantitative Analysis Sohana Factors Group Assignment DraftssaidaNo ratings yet
- Lec28 StratifiedSamplingDocument15 pagesLec28 StratifiedSamplinghu jackNo ratings yet
- Mtes 3123 StatisticDocument7 pagesMtes 3123 Statistickamil007No ratings yet
- UNZA: Department of Mathematics and Statistics MAT1110: Foundation Mathematics and Statistics For Social Sciences Tutorial Sheet 6 (2020/2021)Document3 pagesUNZA: Department of Mathematics and Statistics MAT1110: Foundation Mathematics and Statistics For Social Sciences Tutorial Sheet 6 (2020/2021)Hendrix NailNo ratings yet
- Chapter 5 QuizDocument5 pagesChapter 5 QuizMaria Pia100% (1)
- STAT 2507 Course OutlineDocument2 pagesSTAT 2507 Course OutlinedeanNo ratings yet
- Formula Sheet For Final - ExamDocument1 pageFormula Sheet For Final - ExamIsabel EirasNo ratings yet
- An Example of A HypothesisDocument2 pagesAn Example of A HypothesisAjibade TaofikNo ratings yet
- Westmont College Student Solutions Manual: Probability and Statistics, Fourth Edition, by Hogg and CraigDocument61 pagesWestmont College Student Solutions Manual: Probability and Statistics, Fourth Edition, by Hogg and CraigLandon MoirNo ratings yet
- Assignment #3 Hypothesis TestingDocument10 pagesAssignment #3 Hypothesis TestingJihen SmariNo ratings yet
- Quantitative Analysis AssignmentDocument6 pagesQuantitative Analysis AssignmentsarangpetheNo ratings yet
- Problem 2 - Survey: Importing Nessceary LibrariesDocument10 pagesProblem 2 - Survey: Importing Nessceary LibrariesBhagyaSree JNo ratings yet
- S3 Independent T Test & One-Way ANOVADocument20 pagesS3 Independent T Test & One-Way ANOVAatiqah_asbiNo ratings yet
- Statistical Techniques in Business & Economics 16 Edition: Marchal / WathenDocument3 pagesStatistical Techniques in Business & Economics 16 Edition: Marchal / WathenSougata Tikader FranchNo ratings yet
- Work TheoryDocument57 pagesWork TheoryIftekhar AliNo ratings yet
- Inferential Statistics and The Use of Administrative Data in US Educational ResearchDocument8 pagesInferential Statistics and The Use of Administrative Data in US Educational ResearchMujianiNo ratings yet
- Class 4Document9 pagesClass 4Smruti RanjanNo ratings yet
- Confidence IntervalDocument34 pagesConfidence IntervalAngelyn Taberna NatividadNo ratings yet
- Part 3 Simulation With RDocument42 pagesPart 3 Simulation With RNguyễn OanhNo ratings yet
- QTTDocument1 pageQTTHusen AliNo ratings yet
- AssignmentDocument2 pagesAssignmentJaylord ReyesNo ratings yet
- Chapter 8 Exercises - Lyman Ott Michael Longnecker An IntroducDocument13 pagesChapter 8 Exercises - Lyman Ott Michael Longnecker An Introduchnoor60% (1)















































































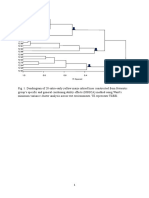




































Download as doc, pdf, or txt
You might also like
- Solution Manual For Design and Analysis of Experiments 9th Edition - Douglas C. MontgomeryDocument25 pagesSolution Manual For Design and Analysis of Experiments 9th Edition - Douglas C. MontgomerySaleh22% (9)
- Field Experimental Designs in AgricultureDocument12 pagesField Experimental Designs in AgricultureBoryana100% (2)
- Hypothesis TestingDocument12 pagesHypothesis TestingJp Combis100% (1)
- Statistics WorkDocument2 pagesStatistics WorkBrittanyWilliams50% (2)
- EFREN S. TELLERMO-Course ProfessorDocument11 pagesEFREN S. TELLERMO-Course ProfessorRizalyn GepilanoNo ratings yet
- Programmed Statistics (Question-Answers)Document551 pagesProgrammed Statistics (Question-Answers)nitesh kewat93% (42)
- Quiz 3Document6 pagesQuiz 3BibliophilioManiac100% (1)
- Sampling TheoryDocument108 pagesSampling TheoryAbduli SalimuNo ratings yet
- BIBDDocument109 pagesBIBDShikha Kashyap100% (1)
- Chapter4 Anova Experimental Design AnalysisDocument31 pagesChapter4 Anova Experimental Design AnalysisAnup ŠářkarNo ratings yet
- 2 Hypothesis Testing (Part 1)Document8 pages2 Hypothesis Testing (Part 1)Von Adrian Inociaan HernandezNo ratings yet
- One Sample T-TestDocument25 pagesOne Sample T-Testgerwin dagumNo ratings yet
- Chapter4 Anova Experimental Design Analysis PDFDocument31 pagesChapter4 Anova Experimental Design Analysis PDFsricharitha6702No ratings yet
- Chi Square HandaoutsDocument6 pagesChi Square HandaoutsSharmaine CondinoNo ratings yet
- HypothesisDocument29 pagesHypothesisdionvenus100% (1)
- Handout 1 Experiment DesignDocument15 pagesHandout 1 Experiment DesignFleming MwijukyeNo ratings yet
- 11 BS201 Prob and Stat - Ch5Document17 pages11 BS201 Prob and Stat - Ch5knmounika2395No ratings yet
- Design Notes-1Document72 pagesDesign Notes-1Samuel GitongaNo ratings yet
- STAT 8200 - Design and Analysis of Experiments For Research Workers - Lecture NotesDocument100 pagesSTAT 8200 - Design and Analysis of Experiments For Research Workers - Lecture NotesGizawNo ratings yet
- Design and Analysis of ExperimentsDocument6 pagesDesign and Analysis of ExperimentsFatima SarwarNo ratings yet
- C22 P09 Chi Square TestDocument33 pagesC22 P09 Chi Square TestsandeepNo ratings yet
- Engineering Data and Analysis - Notes 14Document9 pagesEngineering Data and Analysis - Notes 14Chou Xi MinNo ratings yet
- Control of Experimental Error: Bull's Eye Represents The True Value of The Parameter You Wish To EstimateDocument27 pagesControl of Experimental Error: Bull's Eye Represents The True Value of The Parameter You Wish To EstimateIsmael NeuNo ratings yet
- Chapter 1Document22 pagesChapter 1Adilhunjra HunjraNo ratings yet
- Hypothesis TestingDocument16 pagesHypothesis Testingbdsumaiya314No ratings yet
- Chapter 9Document14 pagesChapter 9Khay OngNo ratings yet
- Science Research Iii: Second Quarter-Module 6 Hypothesis Testing For The Means - Two Sample (Independent Sample)Document9 pagesScience Research Iii: Second Quarter-Module 6 Hypothesis Testing For The Means - Two Sample (Independent Sample)marc marcNo ratings yet
- BS 1 4Document74 pagesBS 1 4archit sahayNo ratings yet
- The Central Limit Theorem and Hypothesis Testing FinalDocument29 pagesThe Central Limit Theorem and Hypothesis Testing FinalMichelleneChenTadle100% (1)
- Intro To Experimental DesignDocument21 pagesIntro To Experimental DesignmercyNo ratings yet
- Research Design Type of Study Exploratory of Formulative Descriptive/DiagnosticDocument3 pagesResearch Design Type of Study Exploratory of Formulative Descriptive/DiagnosticAhmad YassirNo ratings yet
- Principles of Experimental DesignDocument14 pagesPrinciples of Experimental Designsunil dhanjuNo ratings yet
- 1.6 Experimental Design Notes MAT 1260Document3 pages1.6 Experimental Design Notes MAT 1260esch9150No ratings yet
- Mod. 8 A T Test Between MeansDocument20 pagesMod. 8 A T Test Between MeansPhelsie Print ShopNo ratings yet
- Clay 2017Document13 pagesClay 2017everst gouveiaNo ratings yet
- ECOLAPP NotesDocument29 pagesECOLAPP NotesyarahbitangNo ratings yet
- Research 1 - Module 5Document3 pagesResearch 1 - Module 5Arnold CabanerosNo ratings yet
- Sample Size Determination: BY DR Zubair K.ODocument43 pagesSample Size Determination: BY DR Zubair K.OOK ViewNo ratings yet
- Sample Size Determination: BY DR Zubair K.ODocument43 pagesSample Size Determination: BY DR Zubair K.OMakmur SejatiNo ratings yet
- Design of Experiment (G2)Document26 pagesDesign of Experiment (G2)YANA UPADHYAYNo ratings yet
- Statistics & Probability Q4 - Week 5-6Document13 pagesStatistics & Probability Q4 - Week 5-6Rayezeus Jaiden Del RosarioNo ratings yet
- X. Understanding Hypothesis Testing PDFDocument38 pagesX. Understanding Hypothesis Testing PDFBrian GarciaNo ratings yet
- Hypothesis Testing TopicDocument18 pagesHypothesis Testing TopicjermyneducusinandresNo ratings yet
- Measurement 6th Sem (H) DSE4 Lec 4 05 05 2020Document19 pagesMeasurement 6th Sem (H) DSE4 Lec 4 05 05 2020JiisbbbduNo ratings yet
- Testing of HypothesisDocument18 pagesTesting of HypothesisPavan DeshpandeNo ratings yet
- Ag213 Unit 5 Online PDFDocument29 pagesAg213 Unit 5 Online PDFNaiker KaveetNo ratings yet
- Chapter 5: Sampling Distributions & Hypothesis TestingDocument19 pagesChapter 5: Sampling Distributions & Hypothesis TestingAbhishek KushwahaNo ratings yet
- Module 3b - One Sample Tests - Docx 1 PDFDocument12 pagesModule 3b - One Sample Tests - Docx 1 PDFSam Rae LimNo ratings yet
- Reviewer CHAPTER 12Document8 pagesReviewer CHAPTER 12Krisha AvorqueNo ratings yet
- AE 108 Handout No.2Document8 pagesAE 108 Handout No.2hambalos broadcastingincNo ratings yet
- Lecture 4Document32 pagesLecture 4junaidNo ratings yet
- STAT Q4 Week 3 Enhanced.v1Document10 pagesSTAT Q4 Week 3 Enhanced.v1queenkysultan14No ratings yet
- Hypothesis Testing RevisedDocument22 pagesHypothesis Testing RevisedBrafiel Claire Curambao LibayNo ratings yet
- MA113-CHAPTER 6Document3 pagesMA113-CHAPTER 6Mark SolivaNo ratings yet
- Quarter 4 - Week 3: Department of Education - Republic of The PhilippinesDocument12 pagesQuarter 4 - Week 3: Department of Education - Republic of The PhilippinesARNEL B. GONZALESNo ratings yet
- Research 3 Quarter 3 LESSON-2-HYPOTHESIS-TESTINGDocument29 pagesResearch 3 Quarter 3 LESSON-2-HYPOTHESIS-TESTINGRaven Third-partyAccNo ratings yet
- Hypothesis-TestingDocument47 pagesHypothesis-TestingJOSE EPHRAIM MAGLAQUENo ratings yet
- R Codes For Randomized Complete Block Design: International Journal of Information Science and SystemDocument8 pagesR Codes For Randomized Complete Block Design: International Journal of Information Science and SystemDr-Rabia AlmamalookNo ratings yet
- Statistics and Probability: Quarter 4 - Module 3: Test Statistic On Population Mean Week 3 To Week 4Document20 pagesStatistics and Probability: Quarter 4 - Module 3: Test Statistic On Population Mean Week 3 To Week 4JoshNo ratings yet
- 4 Research Design Useful Daily LIfeDocument10 pages4 Research Design Useful Daily LIfeTrisha Joy Dela CruzNo ratings yet
- Sample Sizes for Clinical, Laboratory and Epidemiology StudiesFrom EverandSample Sizes for Clinical, Laboratory and Epidemiology StudiesNo ratings yet
- Gen PTL (MM) NPT % Pollen Stainability of Pollen (IKI) (Mean Sem) (Mean Sem) Germ %viable %non-ViableDocument5 pagesGen PTL (MM) NPT % Pollen Stainability of Pollen (IKI) (Mean Sem) (Mean Sem) Germ %viable %non-ViableTeflon SlimNo ratings yet
- Regional Hybrid TrialDocument8 pagesRegional Hybrid TrialTeflon SlimNo ratings yet
- R Codes For My Germination DataDocument1 pageR Codes For My Germination DataTeflon SlimNo ratings yet
- Obs Source Ss DF Ms Fvalue Probf 1 2 3 4: YieldDocument292 pagesObs Source Ss DF Ms Fvalue Probf 1 2 3 4: YieldTeflon SlimNo ratings yet
- File Name: M0928 Location: Abuja PLO: Rep Entry Pedigree Yieldin Yieldu Plstin Plstun Dyskin DyskunDocument48 pagesFile Name: M0928 Location: Abuja PLO: Rep Entry Pedigree Yieldin Yieldu Plstin Plstun Dyskin DyskunTeflon SlimNo ratings yet
- Interploidy Hybridization in Sympatric Zones The FormationDocument14 pagesInterploidy Hybridization in Sympatric Zones The FormationTeflon SlimNo ratings yet
- Table 3. GCA Effects of Extra-Early Yellow Inbred Parents For Grain Yield and Other Agronomic Traits Evaluated Across Test Environments in 2011Document1 pageTable 3. GCA Effects of Extra-Early Yellow Inbred Parents For Grain Yield and Other Agronomic Traits Evaluated Across Test Environments in 2011Teflon SlimNo ratings yet
- Table 2Document1 pageTable 2Teflon SlimNo ratings yet
- Hybrid Yield Pollen Dysk ASI PHT EPP PaspDocument46 pagesHybrid Yield Pollen Dysk ASI PHT EPP PaspTeflon SlimNo ratings yet
- CS 563 Instructor: A. TettehDocument22 pagesCS 563 Instructor: A. TettehTeflon SlimNo ratings yet
- Table 4Document1 pageTable 4Teflon SlimNo ratings yet
- Table 1. Description of The 20 Yellow-Endosperm Entry Pedigree Reaction To Low-N Reaction To Striga-InfestationDocument1 pageTable 1. Description of The 20 Yellow-Endosperm Entry Pedigree Reaction To Low-N Reaction To Striga-InfestationTeflon SlimNo ratings yet
- Results FileDocument159 pagesResults FileTeflon SlimNo ratings yet
- Responses To Reviewers' Comments CommentDocument4 pagesResponses To Reviewers' Comments CommentTeflon SlimNo ratings yet
- Anhu 12083Document8 pagesAnhu 12083Teflon SlimNo ratings yet
- Diallel ProgenyDocument12 pagesDiallel ProgenyTeflon SlimNo ratings yet
- Inbred Lines Evaluated in Nigeria, 2011.: MaizeDocument1 pageInbred Lines Evaluated in Nigeria, 2011.: MaizeTeflon SlimNo ratings yet
- Fig 1Document1 pageFig 1Teflon SlimNo ratings yet
- Figure 1Document1 pageFigure 1Teflon SlimNo ratings yet
- Lecture 5Document14 pagesLecture 5Teflon SlimNo ratings yet
- CS 563 October 15, 2018 Components of Variance: P G + E P A + D + I + EDocument13 pagesCS 563 October 15, 2018 Components of Variance: P G + E P A + D + I + ETeflon SlimNo ratings yet
- Correlation and Regression Analyses: Measurement of More Than One Variable On Each Experimental or Observational UnitDocument23 pagesCorrelation and Regression Analyses: Measurement of More Than One Variable On Each Experimental or Observational UnitTeflon SlimNo ratings yet
- RE-sequencing and MarkersDocument24 pagesRE-sequencing and MarkersTeflon SlimNo ratings yet
- Trapping and Identifying Mealybugs in Oregon VineyardsDocument5 pagesTrapping and Identifying Mealybugs in Oregon VineyardsTeflon SlimNo ratings yet
- Methods of Insect CollectionDocument2 pagesMethods of Insect CollectionTeflon SlimNo ratings yet
- Geographical Distribution of The Cacao Swollen Shoot Virus Molecular Variability in GhanaDocument8 pagesGeographical Distribution of The Cacao Swollen Shoot Virus Molecular Variability in GhanaTeflon SlimNo ratings yet
- Mealybugs (Hemiptera: Pseudococcidae) Species On Economically Important Fruit Crops in Sri LankaDocument15 pagesMealybugs (Hemiptera: Pseudococcidae) Species On Economically Important Fruit Crops in Sri LankaTeflon SlimNo ratings yet
- AS-Statistics-Facts-and-Definitions-Quiz Answers PT 1Document2 pagesAS-Statistics-Facts-and-Definitions-Quiz Answers PT 1cokonkwoNo ratings yet
- Stat - Prob 11 - Q3 - SLM - WK2Document11 pagesStat - Prob 11 - Q3 - SLM - WK2Lynelle Quinal80% (5)
- Everything You Ever Wanted To Know About Statistics: Prof. Andy FieldDocument37 pagesEverything You Ever Wanted To Know About Statistics: Prof. Andy FieldMohan PudasainiNo ratings yet
- Experiment 1 Formal Report: Application of Statistical Concepts in The Determination of Weight Variation in SamplesDocument6 pagesExperiment 1 Formal Report: Application of Statistical Concepts in The Determination of Weight Variation in SamplesNathalie Dagmang67% (3)
- Department of Statistics: Distribution Theory IDocument102 pagesDepartment of Statistics: Distribution Theory Isal27adamNo ratings yet
- 2 Testing Hypothesis Levin Rubin Chpt8Document11 pages2 Testing Hypothesis Levin Rubin Chpt8ashokgroy121100% (1)
- MGT 524 Quantitative Analysis Sohana Factors Group Assignment DraftsDocument14 pagesMGT 524 Quantitative Analysis Sohana Factors Group Assignment DraftssaidaNo ratings yet
- Lec28 StratifiedSamplingDocument15 pagesLec28 StratifiedSamplinghu jackNo ratings yet
- Mtes 3123 StatisticDocument7 pagesMtes 3123 Statistickamil007No ratings yet
- UNZA: Department of Mathematics and Statistics MAT1110: Foundation Mathematics and Statistics For Social Sciences Tutorial Sheet 6 (2020/2021)Document3 pagesUNZA: Department of Mathematics and Statistics MAT1110: Foundation Mathematics and Statistics For Social Sciences Tutorial Sheet 6 (2020/2021)Hendrix NailNo ratings yet
- Chapter 5 QuizDocument5 pagesChapter 5 QuizMaria Pia100% (1)
- STAT 2507 Course OutlineDocument2 pagesSTAT 2507 Course OutlinedeanNo ratings yet
- Formula Sheet For Final - ExamDocument1 pageFormula Sheet For Final - ExamIsabel EirasNo ratings yet
- An Example of A HypothesisDocument2 pagesAn Example of A HypothesisAjibade TaofikNo ratings yet
- Westmont College Student Solutions Manual: Probability and Statistics, Fourth Edition, by Hogg and CraigDocument61 pagesWestmont College Student Solutions Manual: Probability and Statistics, Fourth Edition, by Hogg and CraigLandon MoirNo ratings yet
- Assignment #3 Hypothesis TestingDocument10 pagesAssignment #3 Hypothesis TestingJihen SmariNo ratings yet
- Quantitative Analysis AssignmentDocument6 pagesQuantitative Analysis AssignmentsarangpetheNo ratings yet
- Problem 2 - Survey: Importing Nessceary LibrariesDocument10 pagesProblem 2 - Survey: Importing Nessceary LibrariesBhagyaSree JNo ratings yet
- S3 Independent T Test & One-Way ANOVADocument20 pagesS3 Independent T Test & One-Way ANOVAatiqah_asbiNo ratings yet
- Statistical Techniques in Business & Economics 16 Edition: Marchal / WathenDocument3 pagesStatistical Techniques in Business & Economics 16 Edition: Marchal / WathenSougata Tikader FranchNo ratings yet
- Work TheoryDocument57 pagesWork TheoryIftekhar AliNo ratings yet
- Inferential Statistics and The Use of Administrative Data in US Educational ResearchDocument8 pagesInferential Statistics and The Use of Administrative Data in US Educational ResearchMujianiNo ratings yet
- Class 4Document9 pagesClass 4Smruti RanjanNo ratings yet
- Confidence IntervalDocument34 pagesConfidence IntervalAngelyn Taberna NatividadNo ratings yet
- Part 3 Simulation With RDocument42 pagesPart 3 Simulation With RNguyễn OanhNo ratings yet
- QTTDocument1 pageQTTHusen AliNo ratings yet
- AssignmentDocument2 pagesAssignmentJaylord ReyesNo ratings yet
- Chapter 8 Exercises - Lyman Ott Michael Longnecker An IntroducDocument13 pagesChapter 8 Exercises - Lyman Ott Michael Longnecker An Introduchnoor60% (1)