Download as docx, pdf, or txt
You might also like
- Statistics-and-Probability - G11 - Quarter - 4 - Module - 1 - Test-of-HypothesisDocument35 pagesStatistics-and-Probability - G11 - Quarter - 4 - Module - 1 - Test-of-HypothesisVincent Villasante85% (86)
- 3D Animal Granny Squares: Over 30 creature crochet patterns for pop-up granny squaresFrom Everand3D Animal Granny Squares: Over 30 creature crochet patterns for pop-up granny squaresRating: 4 out of 5 stars4/5 (4)
- CRD Prob With Sol PDFDocument9 pagesCRD Prob With Sol PDFmamtha_v1No ratings yet
- Spring 12 ECON-E370 IU Exam 1 ReviewDocument27 pagesSpring 12 ECON-E370 IU Exam 1 ReviewTutoringZoneNo ratings yet
- Random VariablesDocument62 pagesRandom VariablesVEANo ratings yet
- Chapter3 Lesson1Document27 pagesChapter3 Lesson1ASHLEY NICOLE DELA VEGANo ratings yet
- Random VariablesDocument35 pagesRandom VariablesMaicel Cate Delos SantosNo ratings yet
- Lab9 Split Plot Design and Its RelativesDocument12 pagesLab9 Split Plot Design and Its Relativesjorbeloco100% (1)
- Weekend Workshop I: Proc MixedDocument23 pagesWeekend Workshop I: Proc MixedptscribNo ratings yet
- Topic 6. Two-Way Designs: Randomized Complete Block DesignDocument21 pagesTopic 6. Two-Way Designs: Randomized Complete Block DesignTeflon SlimNo ratings yet
- 1.1 Experimental Designs I Stat 162 1Document66 pages1.1 Experimental Designs I Stat 162 1hmoody tNo ratings yet
- Bio 3 ApointquarterlabDocument6 pagesBio 3 ApointquarterlabArief Rahman ariefNo ratings yet
- Stats Midterm2022 2023Document2 pagesStats Midterm2022 2023Kurt Rencel VillarbaNo ratings yet
- Lesson 1.1 Random VariableDocument13 pagesLesson 1.1 Random VariableAldous FranciscoNo ratings yet
- Random VariablesDocument99 pagesRandom VariablesRHEA ROSE ABANADORNo ratings yet
- Statistics & Probability Week 1-2Document16 pagesStatistics & Probability Week 1-2AyenNo ratings yet
- A Basket Contains 10 Ripe Bananas and 4 Unripe BanDocument4 pagesA Basket Contains 10 Ripe Bananas and 4 Unripe BanAlexis Nicole Madahan100% (1)
- LAS - Statistics and Probability - Q3 - L1 LC 1 3Document9 pagesLAS - Statistics and Probability - Q3 - L1 LC 1 3Aprile Jane BaiñoNo ratings yet
- Statistics & Probability: September 23, 2021 Deo-Ann S. Surigao Subject TeacherDocument54 pagesStatistics & Probability: September 23, 2021 Deo-Ann S. Surigao Subject TeacherRenlo SanaaNo ratings yet
- Lect8 PDFDocument20 pagesLect8 PDFEsamul HaqNo ratings yet
- Analysis of Variance Analysis of Variance: Steps For One Way ClassificationDocument2 pagesAnalysis of Variance Analysis of Variance: Steps For One Way ClassificationNathaniel EsguerraNo ratings yet
- Statistics & Probability: Quarter 3: Week 1 Learning Activity SheetsDocument9 pagesStatistics & Probability: Quarter 3: Week 1 Learning Activity SheetsVictoria SalvacionNo ratings yet
- 2 Mean Hypothesis Tests With Sigma Unknown (2009)Document4 pages2 Mean Hypothesis Tests With Sigma Unknown (2009)Tin NguyenNo ratings yet
- Ouantitative Techniques For Business Decision Nov 2018Document2 pagesOuantitative Techniques For Business Decision Nov 2018ziyanouziNo ratings yet
- Randomized Block DesignDocument8 pagesRandomized Block DesignDhona أزلف AquilaniNo ratings yet
- Chapter 3: Discrete Distributions: Probability and Statistics For Science and Engineering With Examples in R Hongshik AhnDocument44 pagesChapter 3: Discrete Distributions: Probability and Statistics For Science and Engineering With Examples in R Hongshik AhnSudat KhanNo ratings yet
- Week 6Document20 pagesWeek 6Crius DiomedesNo ratings yet
- 1.6.2 RCBD (Hale) - Supp ReadingDocument13 pages1.6.2 RCBD (Hale) - Supp ReadingTeflon SlimNo ratings yet
- 6 Probability DistributionDocument20 pages6 Probability Distributionjeanescabelle14No ratings yet
- Completely Randomized Design: Ma. Rowena M. Bayrante, PHDDocument22 pagesCompletely Randomized Design: Ma. Rowena M. Bayrante, PHDBob UrbandubNo ratings yet
- B.Tech DEC 2022 COM MAIR-21 SEM 3Document2 pagesB.Tech DEC 2022 COM MAIR-21 SEM 3ankit12012064No ratings yet
- Statistics and ProbabilityDocument26 pagesStatistics and ProbabilityMarianne ParejaNo ratings yet
- LSM 1102 Continual Assessment 2 Sem 2 2005-6 Answer SchemebDocument6 pagesLSM 1102 Continual Assessment 2 Sem 2 2005-6 Answer Schemebgivena2ndchanceNo ratings yet
- 7402-3 Specimen Question Paper (Set 2) - Paper 3 v1.0-1Document24 pages7402-3 Specimen Question Paper (Set 2) - Paper 3 v1.0-1Jasmine ShahNo ratings yet
- MIT Exam 2Document12 pagesMIT Exam 2Daniela Sanclemente100% (1)
- Statistics and ProbabilityDocument27 pagesStatistics and ProbabilityYdzel Jay Dela TorreNo ratings yet
- T9 Factorial 2nd PartDocument8 pagesT9 Factorial 2nd PartmaleticjNo ratings yet
- Wbjee Pyqs Previous 11 Years 2014 To 2024Document595 pagesWbjee Pyqs Previous 11 Years 2014 To 2024seseti8190No ratings yet
- Sampling Sampling Distribution 2Document22 pagesSampling Sampling Distribution 2chaoticcatlady44No ratings yet
- Probability, Ratio of Genotype & Phenotype, Chi SquareDocument34 pagesProbability, Ratio of Genotype & Phenotype, Chi SquarekfaizahNo ratings yet
- Act 8 - Corn Chi Square AnalysisDocument5 pagesAct 8 - Corn Chi Square AnalysisChristine PazNo ratings yet
- Wbjee 2014 ChemistryDocument28 pagesWbjee 2014 Chemistrycan iNo ratings yet
- Classification of Experimental DesignsDocument26 pagesClassification of Experimental DesignsSHEETAL SINGHNo ratings yet
- Topic6 ReadingDocument13 pagesTopic6 ReadingJeannetteNo ratings yet
- Aqa Chem4 QP Jan13Document24 pagesAqa Chem4 QP Jan13LoomberryNo ratings yet
- Chem 2017Document8 pagesChem 2017vivek kumarNo ratings yet
- Topic 6. Randomized Complete Block Design (RCBD)Document20 pagesTopic 6. Randomized Complete Block Design (RCBD)Teflon SlimNo ratings yet
- St. Mary'S School of Novaliches, Inc. Third Quarterly Exam Statistic and Probability 11 S.Y. 2022-2023Document3 pagesSt. Mary'S School of Novaliches, Inc. Third Quarterly Exam Statistic and Probability 11 S.Y. 2022-2023Jessie James AlbaniaNo ratings yet
- Sampling Methods: - Reasons To SampleDocument15 pagesSampling Methods: - Reasons To SampleArnalistan EkaNo ratings yet
- Stat136 - Chapter 4.1Document28 pagesStat136 - Chapter 4.1Sharmaine MagcantaNo ratings yet
- ZOO/VI/09 (2) : ART DescriptiveDocument52 pagesZOO/VI/09 (2) : ART DescriptiveAhmad razaNo ratings yet
- Randomized Block DesignDocument17 pagesRandomized Block DesignZaryaab AhmedNo ratings yet
- Sampling: The Act of Studying Only A Segment or Subset of The Population Representing The WholeDocument42 pagesSampling: The Act of Studying Only A Segment or Subset of The Population Representing The WholeKate BarilNo ratings yet
- 2014 Lab 5 (Topic 8)Document11 pages2014 Lab 5 (Topic 8)Anonymous gUySMcpSqNo ratings yet
- Completely Randomized DesignDocument7 pagesCompletely Randomized DesignElizabeth Ann FelixNo ratings yet
- 2015 Hw1011 KeyDocument5 pages2015 Hw1011 KeyPiNo ratings yet
- Random VariableDocument11 pagesRandom VariablealfonsosucabNo ratings yet
- 2020 November Exam Paper GR7 MathsDocument11 pages2020 November Exam Paper GR7 MathspeterNo ratings yet
- Dr. V. Valliammal: Department of Applied Mathematics Sri Venkateswara College of EngineeringDocument46 pagesDr. V. Valliammal: Department of Applied Mathematics Sri Venkateswara College of EngineeringMahendran KNo ratings yet
- Lesson 2 Chapter 3Document12 pagesLesson 2 Chapter 3Stephanie BiyoNo ratings yet
- 2014 Lab 8 (Topic 12) PDFDocument11 pages2014 Lab 8 (Topic 12) PDFPiNo ratings yet
- An Introduction to Probability and StatisticsFrom EverandAn Introduction to Probability and StatisticsRating: 4 out of 5 stars4/5 (1)
- Gen PTL (MM) NPT % Pollen Stainability of Pollen (IKI) (Mean Sem) (Mean Sem) Germ %viable %non-ViableDocument5 pagesGen PTL (MM) NPT % Pollen Stainability of Pollen (IKI) (Mean Sem) (Mean Sem) Germ %viable %non-ViableTeflon SlimNo ratings yet
- File Name: M0928 Location: Abuja PLO: Rep Entry Pedigree Yieldin Yieldu Plstin Plstun Dyskin DyskunDocument48 pagesFile Name: M0928 Location: Abuja PLO: Rep Entry Pedigree Yieldin Yieldu Plstin Plstun Dyskin DyskunTeflon SlimNo ratings yet
- Regional Hybrid TrialDocument8 pagesRegional Hybrid TrialTeflon SlimNo ratings yet
- Hybrid Yield Pollen Dysk ASI PHT EPP PaspDocument46 pagesHybrid Yield Pollen Dysk ASI PHT EPP PaspTeflon SlimNo ratings yet
- Interploidy Hybridization in Sympatric Zones The FormationDocument14 pagesInterploidy Hybridization in Sympatric Zones The FormationTeflon SlimNo ratings yet
- R Codes For My Germination DataDocument1 pageR Codes For My Germination DataTeflon SlimNo ratings yet
- Correlation and Regression Analyses: Measurement of More Than One Variable On Each Experimental or Observational UnitDocument23 pagesCorrelation and Regression Analyses: Measurement of More Than One Variable On Each Experimental or Observational UnitTeflon SlimNo ratings yet
- Obs Source Ss DF Ms Fvalue Probf 1 2 3 4: YieldDocument292 pagesObs Source Ss DF Ms Fvalue Probf 1 2 3 4: YieldTeflon SlimNo ratings yet
- Results FileDocument159 pagesResults FileTeflon SlimNo ratings yet
- Table 3. GCA Effects of Extra-Early Yellow Inbred Parents For Grain Yield and Other Agronomic Traits Evaluated Across Test Environments in 2011Document1 pageTable 3. GCA Effects of Extra-Early Yellow Inbred Parents For Grain Yield and Other Agronomic Traits Evaluated Across Test Environments in 2011Teflon SlimNo ratings yet
- Figure 1Document1 pageFigure 1Teflon SlimNo ratings yet
- Table 4Document1 pageTable 4Teflon SlimNo ratings yet
- Table 1. Description of The 20 Yellow-Endosperm Entry Pedigree Reaction To Low-N Reaction To Striga-InfestationDocument1 pageTable 1. Description of The 20 Yellow-Endosperm Entry Pedigree Reaction To Low-N Reaction To Striga-InfestationTeflon SlimNo ratings yet
- Lecture 5Document14 pagesLecture 5Teflon SlimNo ratings yet
- Inbred Lines Evaluated in Nigeria, 2011.: MaizeDocument1 pageInbred Lines Evaluated in Nigeria, 2011.: MaizeTeflon SlimNo ratings yet
- Table 2Document1 pageTable 2Teflon SlimNo ratings yet
- Responses To Reviewers' Comments CommentDocument4 pagesResponses To Reviewers' Comments CommentTeflon SlimNo ratings yet
- Diallel ProgenyDocument12 pagesDiallel ProgenyTeflon SlimNo ratings yet
- CS 563 October 15, 2018 Components of Variance: P G + E P A + D + I + EDocument13 pagesCS 563 October 15, 2018 Components of Variance: P G + E P A + D + I + ETeflon SlimNo ratings yet
- Fig 1Document1 pageFig 1Teflon SlimNo ratings yet
- Anhu 12083Document8 pagesAnhu 12083Teflon SlimNo ratings yet
- RE-sequencing and MarkersDocument24 pagesRE-sequencing and MarkersTeflon SlimNo ratings yet
- Trapping and Identifying Mealybugs in Oregon VineyardsDocument5 pagesTrapping and Identifying Mealybugs in Oregon VineyardsTeflon SlimNo ratings yet
- CS 563 Instructor: A. TettehDocument22 pagesCS 563 Instructor: A. TettehTeflon SlimNo ratings yet
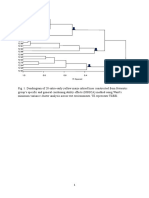
- Geographical Distribution of The Cacao Swollen Shoot Virus Molecular Variability in GhanaDocument8 pagesGeographical Distribution of The Cacao Swollen Shoot Virus Molecular Variability in GhanaTeflon SlimNo ratings yet
- Mealybugs (Hemiptera: Pseudococcidae) Species On Economically Important Fruit Crops in Sri LankaDocument15 pagesMealybugs (Hemiptera: Pseudococcidae) Species On Economically Important Fruit Crops in Sri LankaTeflon SlimNo ratings yet
- Methods of Insect CollectionDocument2 pagesMethods of Insect CollectionTeflon SlimNo ratings yet
- EMS05 CH 1Document32 pagesEMS05 CH 1aleong1No ratings yet
- Assignment - 3Document2 pagesAssignment - 3Priyanka AlmiaNo ratings yet
- 3.1 Determine Study Area and Duration of Study 3.2Document9 pages3.1 Determine Study Area and Duration of Study 3.2Markos DanielNo ratings yet
- Activity 1 Measures of DispersionDocument4 pagesActivity 1 Measures of Dispersionyt premNo ratings yet
- Empirical Software Engineering (Swe504) : Practical FileDocument27 pagesEmpirical Software Engineering (Swe504) : Practical Fileyankit kumarNo ratings yet
- Coaching Actuaries Exam P Suggested Study Schedule: Phase 1: LearnDocument7 pagesCoaching Actuaries Exam P Suggested Study Schedule: Phase 1: LearnRobert Watisthis100% (1)
- Random Sample and Central: Limit Theorem X-Bar and R Control ChartsDocument40 pagesRandom Sample and Central: Limit Theorem X-Bar and R Control ChartsEskandar Sukri100% (1)
- Research Paper Descriptive StatisticsDocument6 pagesResearch Paper Descriptive Statisticsp0lolilowyb3100% (1)
- Data Science Interview PreparationDocument113 pagesData Science Interview PreparationReva V100% (1)
- W10 Anova Dua HalaDocument50 pagesW10 Anova Dua HalaAnonymous hHT0iOyQAzNo ratings yet
- Comparison of Perceptual Responses Between Different Upper-Body Sprint Interval Exercise ProtocolsDocument9 pagesComparison of Perceptual Responses Between Different Upper-Body Sprint Interval Exercise ProtocolsDouglas MarinNo ratings yet
- Multidimensional Scale For Measuring Rural LeadershipDocument7 pagesMultidimensional Scale For Measuring Rural LeadershipDr. Amulya Kumar MohantyNo ratings yet
- Explore Kelompok: 1. Uji Normalitas Data Luas Luka BakarDocument5 pagesExplore Kelompok: 1. Uji Normalitas Data Luas Luka BakarAch JubaidiNo ratings yet
- Experimental Psychology Chapter 15 Flashcards - QuizletDocument4 pagesExperimental Psychology Chapter 15 Flashcards - QuizletPie MacailingNo ratings yet
- Nama Lengkap: Reza Fahlevi NPM: 213110071 Kelas: 1D Program Studi: Teknik Sipil Dosen Pembimbing: Muchammad Zaenal Muttaqin, ST., MSCDocument6 pagesNama Lengkap: Reza Fahlevi NPM: 213110071 Kelas: 1D Program Studi: Teknik Sipil Dosen Pembimbing: Muchammad Zaenal Muttaqin, ST., MSCReza fahleviNo ratings yet
- Presented By: Amrita Sahoo (21202220) Rasleen Kaur (21202260) Anisha Mohanty (21202223) Tathagat Das (21202283) Teena Rose Tom (21202284)Document20 pagesPresented By: Amrita Sahoo (21202220) Rasleen Kaur (21202260) Anisha Mohanty (21202223) Tathagat Das (21202283) Teena Rose Tom (21202284)RashiNo ratings yet
- Lesson 5 Finding Answers Through Data CollectionDocument51 pagesLesson 5 Finding Answers Through Data CollectionEugene TorreNo ratings yet
- Stepha 1Document13 pagesStepha 1yaiyalahNo ratings yet
- ES 209 Engineering Data Analysis - Long QuizDocument3 pagesES 209 Engineering Data Analysis - Long QuizSonny Mae TuboNo ratings yet
- FINALTERM Mth302 Solved by Chanda Rehman Paper No19Document9 pagesFINALTERM Mth302 Solved by Chanda Rehman Paper No19Noor Khan KNo ratings yet
- Estimation of Population MeanDocument14 pagesEstimation of Population MeanAmartyaNo ratings yet
- Lecture 1-2-118Document117 pagesLecture 1-2-118nahid mushtaqNo ratings yet
- 6 Mean Median and Mode From Grouped FrequenciesDocument12 pages6 Mean Median and Mode From Grouped Frequenciesapi-299265916100% (2)
- Sampling Size Determination 3Document3 pagesSampling Size Determination 3MackNo ratings yet
- Measures of DispersionDocument6 pagesMeasures of DispersionQims QuestNo ratings yet
- Exercise (Individual) : Student Name: Matric NoDocument5 pagesExercise (Individual) : Student Name: Matric NoAafini ZakariaNo ratings yet
- Logistic Regression Using SPSS Level1 MASHDocument7 pagesLogistic Regression Using SPSS Level1 MASHmuralidharanNo ratings yet
- Class Material - Multiple Linear RegressionDocument57 pagesClass Material - Multiple Linear RegressionVishvajit KumbharNo ratings yet