Download as pdf or txt
You might also like
- MachineLearningNotes PDFDocument299 pagesMachineLearningNotes PDFKarthik selvamNo ratings yet
- Python Hands OnDocument11 pagesPython Hands Onprashant pal100% (1)
- Synectics Lesson Plan C BurtDocument2 pagesSynectics Lesson Plan C Burtapi-524542474No ratings yet
- Lesson Plan in English 8 Fact and OpinionDocument5 pagesLesson Plan in English 8 Fact and OpinionGrace Ganancial Monteliza75% (4)
- Taize June2014Document14 pagesTaize June2014Jakie Ubina100% (3)
- Python Strings1Document1 pagePython Strings1Harish ReddyNo ratings yet
- Other Structured Types Sets, Tuples, DictionariesDocument19 pagesOther Structured Types Sets, Tuples, DictionariesJatin SinghNo ratings yet
- Document 15Document36 pagesDocument 15Adithya nairNo ratings yet
- Index: SR - No Date Practicals Remarks 1. 2. 3. 4. 5Document16 pagesIndex: SR - No Date Practicals Remarks 1. 2. 3. 4. 5Play DudeNo ratings yet
- Python StringsDocument10 pagesPython StringsHarish ReddyNo ratings yet
- Dictionaries: PythonDocument16 pagesDictionaries: PythonKsNo ratings yet
- Python Final Assignment ImpDocument12 pagesPython Final Assignment Impanjali.pandey0501No ratings yet
- Playfair CipherDocument5 pagesPlayfair Cipher106AshiqNo ratings yet
- Ins Journal All PracsDocument19 pagesIns Journal All PracsShejal PalNo ratings yet
- Crypto DaDocument29 pagesCrypto Davaibhav.chaurasia2021No ratings yet
- Dictionary NotesDocument4 pagesDictionary NotesIlakkiyaa KPNo ratings yet
- NLP ExptsDocument41 pagesNLP ExptsAbhishek TiwariNo ratings yet
- 7) Classes and Instances Find The Three Elements That Sum To Zero From A Set of N Real NumbersDocument3 pages7) Classes and Instances Find The Three Elements That Sum To Zero From A Set of N Real Numbers18bcs097 M. SanthiyaNo ratings yet
- While Loop: Fibonacci SeriesDocument21 pagesWhile Loop: Fibonacci SeriesAnuj RuhelaNo ratings yet
- Write A Python Program Using List and Their Built in FunctionsDocument11 pagesWrite A Python Program Using List and Their Built in Functions18bcs097 M. SanthiyaNo ratings yet
- Python Code ExamplesDocument30 pagesPython Code ExamplesAsaf KatzNo ratings yet
- N, While, /N, ,, Break Else: Input Print Len Print LenDocument7 pagesN, While, /N, ,, Break Else: Input Print Len Print LenSıla KöseNo ratings yet
- Practice QsDocument6 pagesPractice QsRohain KoulNo ratings yet
- CyberDocument10 pagesCyberMohamed RiyazNo ratings yet
- Chapter 9 DictionariesDocument6 pagesChapter 9 Dictionariessanju kumarNo ratings yet
- Rec2 SlidesDocument98 pagesRec2 SlidesTamer SultanyNo ratings yet
- Week 11 AppDocument6 pagesWeek 11 Appishankalathil79No ratings yet
- Python UsecasesDocument46 pagesPython UsecasesAnubhav PaulNo ratings yet
- Python Basic Data TypesDocument27 pagesPython Basic Data TypesAkansha UniyalNo ratings yet
- Dictionary in PythonDocument9 pagesDictionary in PythonNargis AliNo ratings yet
- "Enter A Number:": Def If Return Else ReturnDocument5 pages"Enter A Number:": Def If Return Else ReturnAparna PaiNo ratings yet
- Code3 0Document28 pagesCode3 0Harsh SinghNo ratings yet
- Phytoncodesxx 2Document12 pagesPhytoncodesxx 2Jennifer VeronaNo ratings yet
- Rica PythonDocument7 pagesRica PythonSamielyn Ingles RamosNo ratings yet
- Tuples: 'Physics' 'Chemistry' "A" "B" "C" "D" "E"Document7 pagesTuples: 'Physics' 'Chemistry' "A" "B" "C" "D" "E"sanju kumarNo ratings yet
- Dictionary: Dict ('Name': 'Geeks', 1: (1, 2, 3, 4) )Document14 pagesDictionary: Dict ('Name': 'Geeks', 1: (1, 2, 3, 4) )ahmedNo ratings yet
- Computer Science 1 - Csci 1100 Test 3 - Version 2 November 21, 2013Document8 pagesComputer Science 1 - Csci 1100 Test 3 - Version 2 November 21, 2013PatSramekNo ratings yet
- Pyhton Practicals PDFDocument17 pagesPyhton Practicals PDFMegha SundriyalNo ratings yet
- Working With Lists and Dictionaries: Back Exercise Question / AnswerDocument11 pagesWorking With Lists and Dictionaries: Back Exercise Question / Answerujjubro1201No ratings yet
- FALLSEM2017-18 CSE1701 LO SJT120 VL2017181004844 Reference Material V Strings Lists Dicts RegexDocument11 pagesFALLSEM2017-18 CSE1701 LO SJT120 VL2017181004844 Reference Material V Strings Lists Dicts RegexSahars DasNo ratings yet
- PFC - Workshop 05: Question 1 (2.5 Marks) : Write A Program To Perform These TasksDocument7 pagesPFC - Workshop 05: Question 1 (2.5 Marks) : Write A Program To Perform These TasksDuong Thanh Duy (K17 QN)No ratings yet
- Basics of PythonDocument8 pagesBasics of PythonsumitNo ratings yet
- Open Source Assignment 2Document9 pagesOpen Source Assignment 2Shivi MehrotraNo ratings yet
- Dictionaries Manipulation PracticeDocument8 pagesDictionaries Manipulation PracticeAnand GaneshNo ratings yet
- My First Script.rDocument32 pagesMy First Script.rAlexandra Blasetti KuhnNo ratings yet
- DictionaryDocument60 pagesDictionaryManan kansaraNo ratings yet
- Python IntroductionDocument20 pagesPython IntroductionKalaivani VNo ratings yet
- Litcoder Final Modules OnlyDocument9 pagesLitcoder Final Modules Onlynaveen kumarNo ratings yet
- Python Tuple Sets DictionaryDocument17 pagesPython Tuple Sets DictionaryAvantika SaxenaNo ratings yet
- CNS (Full PGM)Document124 pagesCNS (Full PGM)KaleeswariNo ratings yet
- Python Lab Programs 1. To Write A Python Program To Find GCD of Two NumbersDocument12 pagesPython Lab Programs 1. To Write A Python Program To Find GCD of Two NumbersAYUSHI DEOTARENo ratings yet
- Caesar Cipher:: Applied Cryptography and Network Security SLOT: L21+L22 Lab Assignment - 1Document13 pagesCaesar Cipher:: Applied Cryptography and Network Security SLOT: L21+L22 Lab Assignment - 1R B SHARANNo ratings yet
- Loops: Genome 559: Introduction To Statistical and Computational Genomics Prof. James H. ThomasDocument27 pagesLoops: Genome 559: Introduction To Statistical and Computational Genomics Prof. James H. ThomasRahul JagdaleNo ratings yet
- Python Final Lab 2019Document35 pagesPython Final Lab 2019vanithaNo ratings yet
- Module 1 Python Basics - ProgramsDocument13 pagesModule 1 Python Basics - ProgramsMegha TrivediNo ratings yet
- Experiment 1: Write A Python Program To Find Sum of Series (1+ (1+2) + (1+2+3) +-+ (1+2+3+ - +N) )Document20 pagesExperiment 1: Write A Python Program To Find Sum of Series (1+ (1+2) + (1+2+3) +-+ (1+2+3+ - +N) )jai geraNo ratings yet
- Python Programming Jagesh SoniDocument15 pagesPython Programming Jagesh SoniJagesh SoniNo ratings yet
- cbc86808-82ba-48d0-b8d1-34b4e3ce7c98Document17 pagescbc86808-82ba-48d0-b8d1-34b4e3ce7c98pravingmail84No ratings yet
- Unit 3 Indexing Slicing and Data StructureDocument12 pagesUnit 3 Indexing Slicing and Data Structureupendra mauryaNo ratings yet
- Ngo Van Thang 19 It 196Document5 pagesNgo Van Thang 19 It 196lequochuy.10112000No ratings yet
- SPCC PracticalssDocument6 pagesSPCC Practicalssajay bangarNo ratings yet
- Create A Simple Calculator Application Using Servlet.: T.Y.I.T Enterprise Java Student's ManualDocument33 pagesCreate A Simple Calculator Application Using Servlet.: T.Y.I.T Enterprise Java Student's ManualJack RocketsNo ratings yet
- Mantra To Remove House LizardsDocument1 pageMantra To Remove House LizardsChakradhar DNo ratings yet
- PDF An Invitation To Applied Category Theory Seven Sketches in Compositionality 1St Edition Brendan Fong Ebook Full ChapterDocument54 pagesPDF An Invitation To Applied Category Theory Seven Sketches in Compositionality 1St Edition Brendan Fong Ebook Full Chapterjames.fahey314100% (6)
- Parts Book - DTDC-2020Document9 pagesParts Book - DTDC-2020omar solimanNo ratings yet
- DLL - All Subjects 2 - Q4 - W8 - D3Document15 pagesDLL - All Subjects 2 - Q4 - W8 - D3zyrianNo ratings yet
- Barnes-The Law of ContradictionDocument9 pagesBarnes-The Law of ContradictionOscar Leandro González RuizNo ratings yet
- English As A Foreign Language BrochureDocument15 pagesEnglish As A Foreign Language BrochureKaro López RendónNo ratings yet
- t3 e 616 Descriptive Writing Cover Lesson Pack PresentationDocument23 pagest3 e 616 Descriptive Writing Cover Lesson Pack Presentationsaleh tahaNo ratings yet
- Storage PDFDocument937 pagesStorage PDFeduflormir100% (1)
- Osborne, Grant R. - Romans. The IVP New Testament Commentary Series (Romanos)Document448 pagesOsborne, Grant R. - Romans. The IVP New Testament Commentary Series (Romanos)Libros100% (4)
- MODULE 7 SYNTAX Plus WorksheetsDocument13 pagesMODULE 7 SYNTAX Plus WorksheetsShean Jerica Salem100% (1)
- Well Data MGMTDocument218 pagesWell Data MGMTahmed_497959294No ratings yet
- July 16,2023 Worship ChordsDocument2 pagesJuly 16,2023 Worship ChordsAnna Liza GomezNo ratings yet
- First Hibernate Example Without IDE: 1) Create The Persistent ClassDocument23 pagesFirst Hibernate Example Without IDE: 1) Create The Persistent ClassMambo SasaNo ratings yet
- DBMS Objective TypeDocument8 pagesDBMS Objective TypeSaritha PuttaNo ratings yet
- Tested On Windows7 ProDocument2 pagesTested On Windows7 ProManjunath ShashiNo ratings yet
- EIE4105 IntroductionDocument38 pagesEIE4105 IntroductiontchxiNo ratings yet
- PPT 9Document25 pagesPPT 9Gunawan WibisonoNo ratings yet
- Building A Digital Light Meter With A Calibrated LDRDocument9 pagesBuilding A Digital Light Meter With A Calibrated LDRIsaac CohenNo ratings yet
- Present Simple TenseDocument3 pagesPresent Simple TenseAbílio AraújoNo ratings yet
- Catholic Apologetics Guide 101Document97 pagesCatholic Apologetics Guide 101Godwin Delali Adadzie100% (35)
- The Seat of MosesDocument4 pagesThe Seat of MosesMalachi3_6No ratings yet
- Present Simple To Be ExercisesDocument4 pagesPresent Simple To Be ExercisesAMANNo ratings yet
- English Final Test (Level 1)Document4 pagesEnglish Final Test (Level 1)pablo.drumer.95No ratings yet
- International Codes of Signal FlagsDocument4 pagesInternational Codes of Signal FlagsPriscilla ChantalNo ratings yet
- Ee Nagaraniki EmaindhiDocument3 pagesEe Nagaraniki Emaindhiverification sectionNo ratings yet
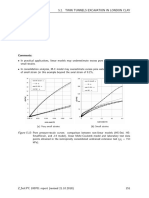
- The Hardening Soil Model A Pratical Guidebook (151-205)Document55 pagesThe Hardening Soil Model A Pratical Guidebook (151-205)rullyirwandiNo ratings yet