Download as pdf or txt
You might also like
- R. J. Singh - Solid State Physics-Pearson Education (2011)Document609 pagesR. J. Singh - Solid State Physics-Pearson Education (2011)saisasikumar26No ratings yet
- Hydraulic ExcelDocument13 pagesHydraulic ExcelahkuehNo ratings yet
- EXP2 UV-Visible Deteermination of An Unknown Concentration of Kmno4 Solution PDFDocument5 pagesEXP2 UV-Visible Deteermination of An Unknown Concentration of Kmno4 Solution PDFRaidah AfiqahNo ratings yet
- 61 ReportDocument12 pages61 ReportAnika TabassumNo ratings yet
- An Efficient Hardware Implementation of Reinforcement Learning: The Q-Learning AlgorithmDocument12 pagesAn Efficient Hardware Implementation of Reinforcement Learning: The Q-Learning AlgorithmNguyễn Hồng NhungNo ratings yet
- An Efficient Hardware Implementation of Reinforcement Learning: The Q-Learning AlgorithmDocument12 pagesAn Efficient Hardware Implementation of Reinforcement Learning: The Q-Learning AlgorithmNguyễn Hồng NhungNo ratings yet
- Autonomous Reinforcement Learning-BioloidDocument7 pagesAutonomous Reinforcement Learning-Bioloiddarkot1234No ratings yet
- Building Reinforcement Learning EnvironmentDocument7 pagesBuilding Reinforcement Learning Environmentazad Tech20No ratings yet
- RL Project - Deep Q-Network Agent ReportDocument11 pagesRL Project - Deep Q-Network Agent ReportPhạm TịnhNo ratings yet
- Making The Car Faster On Highway in DeeptrafficDocument3 pagesMaking The Car Faster On Highway in Deeptrafficapi-339792990No ratings yet
- Reinforcement Learning, Crawling Robot: Faculty of Sciences and Techniques Béni-MellalDocument5 pagesReinforcement Learning, Crawling Robot: Faculty of Sciences and Techniques Béni-MellalMohamedLahouaouiNo ratings yet
- Neural NetworksDocument39 pagesNeural NetworksRajaNo ratings yet
- Proposal PDFDocument8 pagesProposal PDFmarcoNo ratings yet
- Simulation of The Navigation of A Mobile Robot by The Q-Learning Using Artificial Neuron NetworksDocument12 pagesSimulation of The Navigation of A Mobile Robot by The Q-Learning Using Artificial Neuron NetworkstechlabNo ratings yet
- Reinforcement Learning For IoT - FinalDocument45 pagesReinforcement Learning For IoT - Finalali hussainNo ratings yet
- Stock Price Prediction Using Reinforcement LearningDocument6 pagesStock Price Prediction Using Reinforcement Learningankurdey2002.adNo ratings yet
- Rahman2018 Article ImplementationOfQLearningAndDe PDFDocument6 pagesRahman2018 Article ImplementationOfQLearningAndDe PDFGustavo Pinares MamaniNo ratings yet
- 10.1109 Lars-Sbr.2015.41 ApbpDocument6 pages10.1109 Lars-Sbr.2015.41 Apbpnarvan.m31No ratings yet
- DeepMind WhitepaperDocument9 pagesDeepMind WhitepapercrazylifefreakNo ratings yet
- Genetic Reinforcement Learning Algorithms For On-Line Fuzzy Inference System Tuning "Application To Mobile Robotic"Document31 pagesGenetic Reinforcement Learning Algorithms For On-Line Fuzzy Inference System Tuning "Application To Mobile Robotic"Nelson AriasNo ratings yet
- Online Learning Applications: Advertising ProjectDocument82 pagesOnline Learning Applications: Advertising ProjectRoberto ReggianiNo ratings yet
- 16895-Article Text-20389-1-2-20210518Document8 pages16895-Article Text-20389-1-2-20210518Francis SimpsonNo ratings yet
- Playing Geometry Dash With Convolutional Neural NetworksDocument7 pagesPlaying Geometry Dash With Convolutional Neural NetworksfriedmanNo ratings yet
- Qpol 2104.07715Document31 pagesQpol 2104.07715roi.ho2706No ratings yet
- Lecture 2: Intelligent AgentsDocument29 pagesLecture 2: Intelligent AgentsB AnaNo ratings yet
- cs171 hw1 Solutions PDFDocument5 pagescs171 hw1 Solutions PDFsingu ruthwikNo ratings yet
- Probabilistic Robotics Final ReportDocument9 pagesProbabilistic Robotics Final ReportAndrew SackNo ratings yet
- Deep Quality-Value (DQV) Learning: Preprint. Work in ProgressDocument10 pagesDeep Quality-Value (DQV) Learning: Preprint. Work in ProgressfradmardNo ratings yet
- Reinforcement Learning: Russell and Norvig: CH 21Document16 pagesReinforcement Learning: Russell and Norvig: CH 21ZuzarNo ratings yet
- Reinforcement Learning Based Quadcopter ControllerDocument7 pagesReinforcement Learning Based Quadcopter ControllerJoma JemmyNo ratings yet
- ReportDocument4 pagesReportAshfaq JanNo ratings yet
- Assignment3 Yash PatelDocument10 pagesAssignment3 Yash PateladyanrfutureNo ratings yet
- Reinforcement LearningDocument5 pagesReinforcement LearningStabak NandiNo ratings yet
- Learning Simple Games With Neural Networks: Kumar Ashutosh Mohd Safwan Manas VashisthaDocument6 pagesLearning Simple Games With Neural Networks: Kumar Ashutosh Mohd Safwan Manas VashisthaMohd SafwanNo ratings yet
- RL Course ReportDocument10 pagesRL Course ReportshaneNo ratings yet
- Reinforcement Learning Control of Robot Manipulators in Uncertain EnvironmentsDocument6 pagesReinforcement Learning Control of Robot Manipulators in Uncertain EnvironmentsVehid TavakolNo ratings yet
- Generating Intelligent Agent Behaviors in Multi-Agent Game AI Using Deep Reinforcement Learning AlgorithmDocument9 pagesGenerating Intelligent Agent Behaviors in Multi-Agent Game AI Using Deep Reinforcement Learning AlgorithmInternational Journal of Advances in Applied Sciences (IJAAS)No ratings yet
- Insect Based Navigation in Multi-Agent Environment.: Supervisor: Prof. Dr. Zulfiquar Ali MemonDocument12 pagesInsect Based Navigation in Multi-Agent Environment.: Supervisor: Prof. Dr. Zulfiquar Ali MemonMehreenNo ratings yet
- 4 Active Teaching in Robot Programming by DemonstrationDocument6 pages4 Active Teaching in Robot Programming by DemonstrationoldenNo ratings yet
- Maai 6Document143 pagesMaai 6Tùng ĐàoNo ratings yet
- Ruan 2019Document5 pagesRuan 2019Nirban DasNo ratings yet
- Scirobotics - Add6864 SMDocument11 pagesScirobotics - Add6864 SM王根萌No ratings yet
- 2011-Leon Teaching A RobotbDocument8 pages2011-Leon Teaching A RobotbfarhadNo ratings yet
- Lec 21Document28 pagesLec 21dr.compilationyt2No ratings yet
- 111 ReportDocument6 pages111 ReportNguyễn Tự SangNo ratings yet
- Hanna2021 Article GroundedActionTransformationFoDocument31 pagesHanna2021 Article GroundedActionTransformationFoAyman TaniraNo ratings yet
- Unit 1 Question With Answer2Document9 pagesUnit 1 Question With Answer2Abhishek GoyalNo ratings yet
- ICRA2024 IRL Reward Shaping WuDocument8 pagesICRA2024 IRL Reward Shaping Wukkanishk2023No ratings yet
- Ann Lab Manual 2Document7 pagesAnn Lab Manual 2Manak JainNo ratings yet
- Reinforcement Learning OptimizationDocument6 pagesReinforcement Learning OptimizationrhvzjprvNo ratings yet
- QQL NS 2019012315280690Document9 pagesQQL NS 2019012315280690roi.ho2706No ratings yet
- Multi-Agent Deep Reinforcement Learning: Maxim Egorov Stanford UniversityDocument8 pagesMulti-Agent Deep Reinforcement Learning: Maxim Egorov Stanford UniversityCreativ PinoyNo ratings yet
- Playing Atari With Deep Reinforcement Learning HighlightedDocument9 pagesPlaying Atari With Deep Reinforcement Learning HighlightedFelipe DuarteNo ratings yet
- Symbolic AI MDP DPDocument6 pagesSymbolic AI MDP DPSeyidaliNo ratings yet
- Learning Weighted Linguistic Rules To Control An Autonomous RobotDocument26 pagesLearning Weighted Linguistic Rules To Control An Autonomous RobotGraça MariettoNo ratings yet
- Stochastic Policy Gradient Reinforcement Learning On A Simple 3D BipedDocument34 pagesStochastic Policy Gradient Reinforcement Learning On A Simple 3D BipedMuhammad AbyanNo ratings yet
- RL Course ReportDocument11 pagesRL Course Reportsyed zain abbasNo ratings yet
- Case Study 1: Consider The Simple Anthropomorphic Arm in Fig.1. Several Practical Uses ofDocument3 pagesCase Study 1: Consider The Simple Anthropomorphic Arm in Fig.1. Several Practical Uses ofmahdiye nouriNo ratings yet
- Predictive Information and Explorative Behavior of Autonomous RobotsDocument11 pagesPredictive Information and Explorative Behavior of Autonomous RobotsjoykakinnNo ratings yet
- CSD311: Artificial IntelligenceDocument11 pagesCSD311: Artificial IntelligenceAyaan KhanNo ratings yet
- Scaling Monosemanticity - Extracting Interpretable Features From Claude 3 SonnetDocument75 pagesScaling Monosemanticity - Extracting Interpretable Features From Claude 3 SonnetGustavo B.No ratings yet
- Backpropagation: Fundamentals and Applications for Preparing Data for Training in Deep LearningFrom EverandBackpropagation: Fundamentals and Applications for Preparing Data for Training in Deep LearningNo ratings yet
- Image Classification: Step-by-step Classifying Images with Python and Techniques of Computer Vision and Machine LearningFrom EverandImage Classification: Step-by-step Classifying Images with Python and Techniques of Computer Vision and Machine LearningNo ratings yet
- Trajectory Tracking Control and Robustness Analysis of A Robotic Manipulator Using Advanced Control TechniquesDocument13 pagesTrajectory Tracking Control and Robustness Analysis of A Robotic Manipulator Using Advanced Control Techniques李默然No ratings yet
- mmr03 CdsDocument79 pagesmmr03 Cds李默然No ratings yet
- Sang Wan 2009Document11 pagesSang Wan 2009李默然No ratings yet
- Bipedal Walking Robot Using Deep Deterministic Policy GradientDocument5 pagesBipedal Walking Robot Using Deep Deterministic Policy Gradient李默然No ratings yet
- Mrppsim: A Multi-Robot Path Planning Simulation: Ebtehal Turki Saho Alotaibi, Hisham Al-RawiDocument11 pagesMrppsim: A Multi-Robot Path Planning Simulation: Ebtehal Turki Saho Alotaibi, Hisham Al-Rawi李默然No ratings yet
- Report GeneticAlgorithm LeandroDocument7 pagesReport GeneticAlgorithm Leandro李默然No ratings yet
- High Rise Part B To DDocument32 pagesHigh Rise Part B To DAnnie JiangNo ratings yet
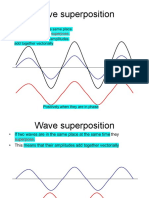
- Wave SuperpositionDocument29 pagesWave SuperpositionAndrei Allen GonzalesNo ratings yet
- System On Chip Scaling - LectureDocument46 pagesSystem On Chip Scaling - LectureAhmad UsmanNo ratings yet
- Pneumatic TMT Rod Bending MachineDocument45 pagesPneumatic TMT Rod Bending MachineXaviour XaviNo ratings yet
- Fremap Osram Sylvania CatalogDocument22 pagesFremap Osram Sylvania CatalogFremap Industries S A100% (1)
- Sealants Just Spaghetti and MeatballsDocument13 pagesSealants Just Spaghetti and MeatballsJosé R. MedinaNo ratings yet
- Problem 2 For The Frame Shown, Using Matrix Structural Analysis ,..Document6 pagesProblem 2 For The Frame Shown, Using Matrix Structural Analysis ,..gerlyn montillaNo ratings yet
- 2015 FSAE Chassis Rules Quick RefDocument7 pages2015 FSAE Chassis Rules Quick RefAnonymous Ms8nYcbxY2No ratings yet
- MK4 DMK Stay Cable System Brochure PDFDocument24 pagesMK4 DMK Stay Cable System Brochure PDFIndra MishraNo ratings yet
- Module 1Document47 pagesModule 1greatrijuvanNo ratings yet
- Abaqus 6 - 8 UsersubDocument465 pagesAbaqus 6 - 8 UsersubMario PolancoNo ratings yet
- Modeling of A SEPIC Converter Operating in Discontinuous Conduction ModeDocument4 pagesModeling of A SEPIC Converter Operating in Discontinuous Conduction ModetybonescribdNo ratings yet
- Structural Analysis RamamruthamDocument3 pagesStructural Analysis RamamruthamManjari Arasada50% (6)
- A Presentation ON: Nano TechnologyDocument23 pagesA Presentation ON: Nano TechnologyBrandon JohnsonNo ratings yet
- EEE201 SyllabusDocument2 pagesEEE201 SyllabuskannanchammyNo ratings yet
- SMR PYQs 7-9Document6 pagesSMR PYQs 7-9TRY UP GamingNo ratings yet
- List For Written Exam of Ph.D. 2013Document14 pagesList For Written Exam of Ph.D. 2013Anup ShuklaNo ratings yet
- E-Books - Direction Test - (Sampurna 2.0 Dec 2023)Document23 pagesE-Books - Direction Test - (Sampurna 2.0 Dec 2023)devanshNo ratings yet
- Syllabus Semester 1Document8 pagesSyllabus Semester 1Eng Abdulkadir MahamedNo ratings yet
- Comb Filter Effect: Compal AT-Audio/ Viction - WuDocument24 pagesComb Filter Effect: Compal AT-Audio/ Viction - WuMeng-Chien WuNo ratings yet
- SpiraxSarco-B13-Condensate RemovalDocument72 pagesSpiraxSarco-B13-Condensate Removaldanenic100% (2)
- Theory of Heat in 1822Document27 pagesTheory of Heat in 1822B.R.NagabhushanNo ratings yet
- Chapter 4 EOS FDocument32 pagesChapter 4 EOS FjeffierNo ratings yet
- Pile Foundation#1Document86 pagesPile Foundation#1reza pahleviNo ratings yet
- Geotechnical Instrumentation and MonitoringDocument2 pagesGeotechnical Instrumentation and MonitoringLuiz SilvaNo ratings yet
- Comparative Study of A Voided Post Tensioning Flat Slab With Different Slab SystemsDocument26 pagesComparative Study of A Voided Post Tensioning Flat Slab With Different Slab SystemsRahulKikaniNo ratings yet
- Transport of Substances in PlantsDocument18 pagesTransport of Substances in PlantsArash HalimNo ratings yet