Download as pdf or txt
You might also like
- Full Download Ebook Ebook PDF Nonequilibrium Molecular Dynamics Theory Algorithms and Applications PDFDocument41 pagesFull Download Ebook Ebook PDF Nonequilibrium Molecular Dynamics Theory Algorithms and Applications PDFrebecca.glennon522100% (48)
- Practice On Sinusoidal and Inverse FunctionsDocument3 pagesPractice On Sinusoidal and Inverse FunctionsKinjal Koli0% (1)
- OpenSCAD User Manual - Print Version PDFDocument108 pagesOpenSCAD User Manual - Print Version PDFqqwerty1982100% (2)
- Thermodynamics As A Consequence of Information ConservationDocument24 pagesThermodynamics As A Consequence of Information ConservationLocutus BorgNo ratings yet
- Analytical Approximation of Optimal Thermoeconomic Efficiencie - 2023 - ResultsDocument13 pagesAnalytical Approximation of Optimal Thermoeconomic Efficiencie - 2023 - Resultsronaldquezada038No ratings yet
- Scripta MaterialiaDocument6 pagesScripta MaterialiaadityamduttaNo ratings yet
- Comparison of The Serial and Parallel Algorithms of Generalized Ensemble Simulations: An Analytical ApproachDocument7 pagesComparison of The Serial and Parallel Algorithms of Generalized Ensemble Simulations: An Analytical ApproachBibek GuptaNo ratings yet
- 1 s2.0 S0010465522003137 MainDocument7 pages1 s2.0 S0010465522003137 MainMUHAMMAD BILAL KHURSHEEDNo ratings yet
- Measuring The Characteristic Function of Work DistributionDocument6 pagesMeasuring The Characteristic Function of Work DistributionDiogo Lima BarretoNo ratings yet
- PhysRevX 9 041032 PDFDocument21 pagesPhysRevX 9 041032 PDFJige ChenNo ratings yet
- Adjustment of Automatic Capacitors Using Parametric Optimal FlowDocument8 pagesAdjustment of Automatic Capacitors Using Parametric Optimal Flowdiogo_dahlkeNo ratings yet
- Building-Up Virtual Optimized Mechanism For Flame ModelingDocument8 pagesBuilding-Up Virtual Optimized Mechanism For Flame ModelingEduardoNo ratings yet
- Rational Approximation of The Absolute Value Function From Measurements: A Numerical Study of Recent MethodsDocument28 pagesRational Approximation of The Absolute Value Function From Measurements: A Numerical Study of Recent MethodsFlorinNo ratings yet
- Physica E: Low-Dimensional Systems and Nanostructures: Yanchao Zhang, Jincan Chen TDocument4 pagesPhysica E: Low-Dimensional Systems and Nanostructures: Yanchao Zhang, Jincan Chen TAstrid Camila Riveros MesaNo ratings yet
- Ergotropy From Quantum and Classical CorrelationsDocument16 pagesErgotropy From Quantum and Classical CorrelationsAslı ÖzdemirNo ratings yet
- Quantum ThermodynamicsDocument19 pagesQuantum Thermodynamics20 2162 Parth SonawaneNo ratings yet
- Maximal Fluctuation Exploitation in Gaussian Information EnginesDocument16 pagesMaximal Fluctuation Exploitation in Gaussian Information Enginesrechin bohterNo ratings yet
- Maxwel-Cattaneeo Regularization Heat EquationDocument4 pagesMaxwel-Cattaneeo Regularization Heat EquationEnder MecanicPOPNo ratings yet
- Pap101e AAMDocument17 pagesPap101e AAMadi63No ratings yet
- Nicol 2001Document19 pagesNicol 2001Clarence AG YueNo ratings yet
- High Accuracy Numerical Methods For Thermally Perfect Gas Flows With ChemistryDocument16 pagesHigh Accuracy Numerical Methods For Thermally Perfect Gas Flows With ChemistryGunvir SinghNo ratings yet
- 2 20849 Jtskvol86no3may2024Document8 pages2 20849 Jtskvol86no3may2024Michael ChenNo ratings yet
- Bulk EuHfO3 From First PrinciplesDocument6 pagesBulk EuHfO3 From First PrinciplesMaycol AvalosNo ratings yet
- Sa 2Document9 pagesSa 2Gabriel VelascoNo ratings yet
- Physical Quantum AlgorithmsDocument7 pagesPhysical Quantum AlgorithmsSankha DeepNo ratings yet
- 3823123.235756.45 WTDocument8 pages3823123.235756.45 WTnafobif278No ratings yet
- An Adaptive Variational Algorithm For Exact Molecular Simulations On A Quantum ComputerDocument9 pagesAn Adaptive Variational Algorithm For Exact Molecular Simulations On A Quantum ComputerRaiyan RahmanNo ratings yet
- Effectiveness-NTU Correlation For Low Temperature PCM Encapsulated in SpheresDocument7 pagesEffectiveness-NTU Correlation For Low Temperature PCM Encapsulated in SpheresJoão JúniorNo ratings yet
- PRXQuantum 3 040334Document10 pagesPRXQuantum 3 040334Oppe heimerNo ratings yet
- PhysRevX 13 041041Document34 pagesPhysRevX 13 041041ctk74378No ratings yet
- Yamamoto 2016Document11 pagesYamamoto 2016Matheus AgostinNo ratings yet
- Maximal Fluctuation Exploitation in Gaussian Information EnginesDocument17 pagesMaximal Fluctuation Exploitation in Gaussian Information EnginesAlessio GagliardiNo ratings yet
- 3.9 Knudsen Heat CapacityDocument13 pages3.9 Knudsen Heat CapacityКирилл МаксимовNo ratings yet
- Mol. Simul. 49, 1117-1124 (2023) +supplementalDocument12 pagesMol. Simul. 49, 1117-1124 (2023) +supplementalSweta AkhoriNo ratings yet
- Thermodynamic Linear AlgebraDocument36 pagesThermodynamic Linear Algebrac42qvh59ghNo ratings yet
- 2023 Unification of The First Law of Quantum ThermodynamicsDocument43 pages2023 Unification of The First Law of Quantum ThermodynamicsWI TONo ratings yet
- Hydrodynamic Transport Functions From Quantum Kinetic Field TheoryDocument20 pagesHydrodynamic Transport Functions From Quantum Kinetic Field TheoryKaustubhNo ratings yet
- 4 - IEEE Proceedings 2016 - Dynamic Model Validation of The Radiant Floor Heating System Based On The Object Oriented ApproachDocument6 pages4 - IEEE Proceedings 2016 - Dynamic Model Validation of The Radiant Floor Heating System Based On The Object Oriented ApproachslmokraouiNo ratings yet
- Convex Integration Constructions in HydrodynamicsDocument44 pagesConvex Integration Constructions in HydrodynamicsGustavo SoaresNo ratings yet
- Optimization Criteria, Bounds, and Efficiencies of Heat EnginesDocument5 pagesOptimization Criteria, Bounds, and Efficiencies of Heat EnginesAma PredaNo ratings yet
- Water Thermal Cond and Other CorrDocument6 pagesWater Thermal Cond and Other Corrtanmay kakadeNo ratings yet
- ChuangDocument8 pagesChuangKamal ChoudharyNo ratings yet
- Extractable Work From CorrelationsDocument14 pagesExtractable Work From Correlationsdani_cirigNo ratings yet
- Efficiency of Inefficient Endoreversible Thermal MachinesDocument7 pagesEfficiency of Inefficient Endoreversible Thermal Machinescarolina coaquiraNo ratings yet
- SciPostPhys 14 3 055Document17 pagesSciPostPhys 14 3 055マルワNo ratings yet
- JCC 20696Document12 pagesJCC 20696Lbmm Física MolecularNo ratings yet
- Content ServerDocument16 pagesContent ServerSophie OrtegaNo ratings yet
- Stabilizing Open Quantum Batteries by Sequential MeasurementsDocument9 pagesStabilizing Open Quantum Batteries by Sequential MeasurementsOscar BohórquezNo ratings yet
- Rodrguez Her N Ndez 2014Document6 pagesRodrguez Her N Ndez 2014Tengku Arief Buana PerkasaNo ratings yet
- M L Aiello-Nicosia 1985 Eur. J. Phys. 6 148Document7 pagesM L Aiello-Nicosia 1985 Eur. J. Phys. 6 148Andrés Oswaldo Rivera HérnandezNo ratings yet
- Thermo-Economic Analysis and Optimization of The Steam Absorption Chiller Network PlantDocument12 pagesThermo-Economic Analysis and Optimization of The Steam Absorption Chiller Network PlantAlvaro Antonio Ochoa VillaNo ratings yet
- Diffusion2 PDFDocument26 pagesDiffusion2 PDFlolaNo ratings yet
- GH 99Document10 pagesGH 99Gonzalo BustosNo ratings yet
- 2305 03197Document14 pages2305 03197A.R.Bathri NarayananNo ratings yet
- Hamiltonian ApproachDocument9 pagesHamiltonian ApproachPaulaGF88No ratings yet
- PhysRevE 91 012104Document8 pagesPhysRevE 91 012104Aditi MisraNo ratings yet
- Atomic Structure Optimization With Machine-Learning Enabled Interpolation Between Chemical ElementsDocument9 pagesAtomic Structure Optimization With Machine-Learning Enabled Interpolation Between Chemical Elementsrajdeep.jzsNo ratings yet
- ME 315 H M T: EAT AND ASS RansferDocument32 pagesME 315 H M T: EAT AND ASS RansferMuhammad Hasan100% (1)
- Alhadad 2018Document9 pagesAlhadad 2018cemilNo ratings yet
- An Algorithm For Gradient-Regularized Plasticity Coupled To Damage Based On A Dual Mixed FE-FormulationDocument17 pagesAn Algorithm For Gradient-Regularized Plasticity Coupled To Damage Based On A Dual Mixed FE-Formulationking sunNo ratings yet
- N HeptaneDocument7 pagesN HeptaneFranciscoBarrancoLopezNo ratings yet
- TAS GoldParaFactSheet FinalDocument2 pagesTAS GoldParaFactSheet FinalNavneet KaliaNo ratings yet
- News Paper AdDocument1 pageNews Paper AdNavneet KaliaNo ratings yet
- PCT Fee Tables: (Amounts On 10 December 2010, Unless Otherwise Indicated)Document6 pagesPCT Fee Tables: (Amounts On 10 December 2010, Unless Otherwise Indicated)Navneet KaliaNo ratings yet
- AgendaDocument3 pagesAgendaNavneet KaliaNo ratings yet
- Geometric SequencesDocument4 pagesGeometric SequencesAftermath There's CyenceNo ratings yet
- NBKHHDocument41 pagesNBKHHSneha SruthiNo ratings yet
- Spatial Autocorrelation Using GIS: Jennie Murack Murack@mit - EduDocument37 pagesSpatial Autocorrelation Using GIS: Jennie Murack Murack@mit - EduLuzianeRibeiroNo ratings yet
- Abaqus Compression of A Rubber Seal WorkshopDocument8 pagesAbaqus Compression of A Rubber Seal WorkshopSandeep PahadeNo ratings yet
- Dynamics - Chapter - 2 - Kinematics - of - Particles Rectilinear Motion To Normal Tangential Coordinates PDFDocument56 pagesDynamics - Chapter - 2 - Kinematics - of - Particles Rectilinear Motion To Normal Tangential Coordinates PDFJP NielesNo ratings yet
- Ece - Ilyr - Ivsem - QBDocument116 pagesEce - Ilyr - Ivsem - QBBala KumarNo ratings yet
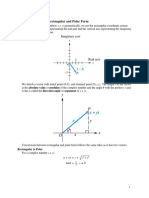
- Notes Polar Complex Numbers PDFDocument3 pagesNotes Polar Complex Numbers PDFMr. Mark B.No ratings yet
- Fanuc Series 16 / 18 / 160 / 180 - Model PB Parameter ManualDocument66 pagesFanuc Series 16 / 18 / 160 / 180 - Model PB Parameter ManualClubmasterNo ratings yet
- Computational ComplexityDocument20 pagesComputational ComplexityigbboyNo ratings yet
- Question Bank CS604BDocument14 pagesQuestion Bank CS604BMaz Har Ul0% (1)
- PRM500 Module 1Document19 pagesPRM500 Module 1Chan NovNo ratings yet
- Bohr & Wheeler Fission Theory Calculation 4 March 2009: Z A 2 A ADocument22 pagesBohr & Wheeler Fission Theory Calculation 4 March 2009: Z A 2 A AAlexandre PereiraNo ratings yet
- 13.1 Difference Equations: DefinitionsDocument26 pages13.1 Difference Equations: DefinitionsMuhammad ShoaibNo ratings yet
- Guide To ADePTDocument50 pagesGuide To ADePTslipi14100% (1)
- jU7fSi-f1500 Chapter 15Document23 pagesjU7fSi-f1500 Chapter 15san.ras0715No ratings yet
- EFEAv6p03 User ManualDocument190 pagesEFEAv6p03 User ManualJoão FerreiraNo ratings yet
- The Paradox of Fourier Heat EquationDocument7 pagesThe Paradox of Fourier Heat EquationAngélica RuizNo ratings yet
- Production FunctionDocument16 pagesProduction FunctionvedhajuvalNo ratings yet
- Chapter 3 - DJDocument3 pagesChapter 3 - DJEunice GabrielNo ratings yet
- Class XI (NEW) Syllabus 3rd AugustDocument46 pagesClass XI (NEW) Syllabus 3rd AugustSandipan ChakrabortyNo ratings yet
- How To Calculate Number of Steps Amp Reactive Power of The Capacitor BanksDocument8 pagesHow To Calculate Number of Steps Amp Reactive Power of The Capacitor BanksRobert GalarzaNo ratings yet
- Symbolic MEV ExtractionDocument20 pagesSymbolic MEV ExtractionisnullNo ratings yet
- Linguistics ExerciseDocument2 pagesLinguistics ExerciseSharon Zheng100% (1)
- 7 - Monte-Carlo-Simulation With XL STAT - English GuidelineDocument8 pages7 - Monte-Carlo-Simulation With XL STAT - English GuidelineGauravShelkeNo ratings yet
- V4A Group2Document21 pagesV4A Group2Bane BarrionNo ratings yet
- Bessel Functions (Guide)Document22 pagesBessel Functions (Guide)Hoang Phan Thanh100% (1)
- Letter Recognition Using HOlland-Style Adaptive Classifiers PDFDocument22 pagesLetter Recognition Using HOlland-Style Adaptive Classifiers PDFAntonio Rodrigues Carvalho NetoNo ratings yet
- Model Questions and Answers MA (101) Mathematics TMJA CoorayDocument9 pagesModel Questions and Answers MA (101) Mathematics TMJA CoorayRashan PeirisNo ratings yet