Download as docx, pdf, or txt
You might also like
- Employees Mod DB PDFDocument1 pageEmployees Mod DB PDFJoe1No ratings yet
- Knn1 MinMaxScalarDocument13 pagesKnn1 MinMaxScalarJoe1No ratings yet
- Unit2 - Naive Bayes Classifier - HGDocument19 pagesUnit2 - Naive Bayes Classifier - HGsachin rajputNo ratings yet
- P-Value: The Probability of Unobserved Data That Are More "Extreme" Than The ObservedDocument7 pagesP-Value: The Probability of Unobserved Data That Are More "Extreme" Than The ObservedSaad JavedNo ratings yet
- Bayee's Theorem PDFDocument2 pagesBayee's Theorem PDFujwala_512No ratings yet
- Gaussian Mixture ModelDocument48 pagesGaussian Mixture ModelShubhanka ANo ratings yet
- Naive Bayes Classifier: Coin Toss and Fair Dice ExampleDocument16 pagesNaive Bayes Classifier: Coin Toss and Fair Dice ExampleRupali PatilNo ratings yet
- Ai PrinciplesDocument29 pagesAi PrinciplesKalpana MrcetNo ratings yet
- Getting To Know and Interpreting Your Data: Irina BaetuDocument46 pagesGetting To Know and Interpreting Your Data: Irina BaeturenodagenoNo ratings yet
- Are Female Mallards Attracted To The Color Green?Document5 pagesAre Female Mallards Attracted To The Color Green?Daniel BrownNo ratings yet
- Explanation-Of-Naive-Bayes-Classification First, Conditional Probability & Bayes' RuleDocument4 pagesExplanation-Of-Naive-Bayes-Classification First, Conditional Probability & Bayes' RuleKshitjNo ratings yet
- Lab4 ConditionalProbAndBayesDocument1 pageLab4 ConditionalProbAndBayesSamratNo ratings yet
- Bayesrule StatsDocument4 pagesBayesrule StatsPoonam NaiduNo ratings yet
- Bayesian Updating 2012Document5 pagesBayesian Updating 2012JulieNo ratings yet
- Acting Under Uncertainty Basic ConceptsDocument19 pagesActing Under Uncertainty Basic ConceptsSawaira KazmiNo ratings yet
- Asst3drfhg PsDocument7 pagesAsst3drfhg PsRafflesia KhanNo ratings yet
- Lect9 NBDocument46 pagesLect9 NBNaif AlajlaniNo ratings yet
- Homework 2Document25 pagesHomework 2Arpit Gulati100% (1)
- Ai Principles UncertaintyDocument21 pagesAi Principles UncertaintySouvik SarkarNo ratings yet
- Bayes 2Document48 pagesBayes 2N MaheshNo ratings yet
- Artificial Intelligence: Assignment On MLDocument6 pagesArtificial Intelligence: Assignment On MLdeAnkitNo ratings yet
- Bayes' Theorem Explained: The Basic IdeaDocument8 pagesBayes' Theorem Explained: The Basic IdeafajlsefisjfesNo ratings yet
- Bayes TheoremDocument7 pagesBayes TheoremDuy PhanNo ratings yet
- Reasoning Under Uncertainty (A Statistical Approach) : Jeremy WyattDocument21 pagesReasoning Under Uncertainty (A Statistical Approach) : Jeremy WyatthariniNo ratings yet
- Unit 2 .Statistical Decision Making-1Document213 pagesUnit 2 .Statistical Decision Making-1rahuljssstuNo ratings yet
- Chapter 3&4 ReviewDocument24 pagesChapter 3&4 Reviewjoeltan111No ratings yet
- Bayes and Naive Bayes PredictorsDocument5 pagesBayes and Naive Bayes PredictorsNguyễn Hoàng Phương TrầnNo ratings yet
- Counting Probablity 3 ConditionalDocument5 pagesCounting Probablity 3 ConditionalZoePhilipNo ratings yet
- Module 1 Computing Exercises - Intro To AiDocument5 pagesModule 1 Computing Exercises - Intro To AiJas LimNo ratings yet
- Probability Definitions of StatisticsDocument19 pagesProbability Definitions of StatisticsShihab KhanNo ratings yet
- Uncertainty in KBSDocument5 pagesUncertainty in KBSSuada Bőw WéěžýNo ratings yet
- Program Name: B.Tech CSE Semester: 5th Course Code:PEC-CS-D-501 (I) Facilitator Name: AasthaDocument17 pagesProgram Name: B.Tech CSE Semester: 5th Course Code:PEC-CS-D-501 (I) Facilitator Name: AasthaAastha KohliNo ratings yet
- BayesDocument3 pagesBayesCamille Rose MosteiroNo ratings yet
- 104654Document14 pages104654jegannancyNo ratings yet
- Course On Bayesian Methods in Environmental Valuation: Basics (Continued) : Models For Proportions and MeansDocument34 pagesCourse On Bayesian Methods in Environmental Valuation: Basics (Continued) : Models For Proportions and MeansAurora Rosa Neciosup ObandoNo ratings yet
- Notes - Module 4Document17 pagesNotes - Module 4Anand PandurangaNo ratings yet
- 6.2009 Hypothesis Testing-Binomial SDocument6 pages6.2009 Hypothesis Testing-Binomial Sfabremil7472100% (2)
- Bayes Theorem 2022Document36 pagesBayes Theorem 2022Navpreet KaurNo ratings yet
- Conditional Probability: Bayes' Theorem Is A Formula That Describes How To Update The Probabilities of Hypotheses WhenDocument5 pagesConditional Probability: Bayes' Theorem Is A Formula That Describes How To Update The Probabilities of Hypotheses WhenJoanne Bernadette IcaroNo ratings yet
- Bayes' Theorem Explained: 4 Ways: Ready To Dig in and Visually Explore The Basics? Let's Go!Document7 pagesBayes' Theorem Explained: 4 Ways: Ready To Dig in and Visually Explore The Basics? Let's Go!Max MbiseNo ratings yet
- 3 Bayes PDFDocument79 pages3 Bayes PDFkoleti vikasNo ratings yet
- BIA Data Exploration PDocument37 pagesBIA Data Exploration PAZGHNo ratings yet
- Bio StatisticsDocument24 pagesBio Statisticsvmc6gyvh9gNo ratings yet
- Bayesian Updating: Odds Class 12, 18.05 Jeremy Orloff and Jonathan BloomDocument8 pagesBayesian Updating: Odds Class 12, 18.05 Jeremy Orloff and Jonathan BloomMd CassimNo ratings yet
- ProbabilityDocument24 pagesProbabilityMahatma NarendranitiNo ratings yet
- Test of Hypothesis For 2020Document62 pagesTest of Hypothesis For 2020Jewel Drew Galita100% (1)
- Q4 Module 33 Measures of Position of Ungrouped DataDocument44 pagesQ4 Module 33 Measures of Position of Ungrouped Datajovielyn kathley manaloNo ratings yet
- Animal Classification Using A Dichotomous Key: BackgroundDocument4 pagesAnimal Classification Using A Dichotomous Key: BackgroundD'Savon StokisNo ratings yet
- P ValueDocument13 pagesP ValueKamal AnchaliaNo ratings yet
- Chapter Four Logic Programming: Logics in Computer Science (Cosc3141)Document9 pagesChapter Four Logic Programming: Logics in Computer Science (Cosc3141)Yonathan BerhanuNo ratings yet
- ES714glm Generalized Linear ModelsDocument26 pagesES714glm Generalized Linear ModelsscurtisvainNo ratings yet
- 1 Probability: or and NotDocument4 pages1 Probability: or and NotNicole NgNo ratings yet
- AlBiI WS2002 3 HusonDocument163 pagesAlBiI WS2002 3 HusonTales FernandoNo ratings yet
- Stat MethDocument66 pagesStat MethalscribdsaNo ratings yet
- Downloadartificial Intelligence - Unit 3Document20 pagesDownloadartificial Intelligence - Unit 3blazeNo ratings yet
- Chapter13 UncertaintyDocument49 pagesChapter13 Uncertaintynaseem hanzilaNo ratings yet
- Steps in Hypothesis TestingDocument2 pagesSteps in Hypothesis TestingSerah Ann JohnsonNo ratings yet
- P-Values P-Values: Statistical InferenceDocument8 pagesP-Values P-Values: Statistical Inferencenitin guptaNo ratings yet
- AI First Order Logic ExamplesDocument3 pagesAI First Order Logic ExamplesDk SahaNo ratings yet
- Interacting with Animals: Understanding their Behaviour and WelfareFrom EverandInteracting with Animals: Understanding their Behaviour and WelfareNo ratings yet
- Java For SeleniumDocument9 pagesJava For SeleniumJoe1No ratings yet
- Selenium Java Environment SetupDocument7 pagesSelenium Java Environment SetupJoe1No ratings yet
- Selenium Class 3 Selenium Testing Process Part 2 PDFDocument7 pagesSelenium Class 3 Selenium Testing Process Part 2 PDFJoe1No ratings yet
- Selenium Testing ProcessDocument9 pagesSelenium Testing ProcessJoe1No ratings yet
- Worksheet 2Document3 pagesWorksheet 2Joe1No ratings yet
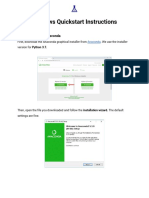
- Windows Quickstart Instructions: Step 1: Download AnacondaDocument7 pagesWindows Quickstart Instructions: Step 1: Download AnacondaJoe1No ratings yet
- Hive and ImpalaDocument46 pagesHive and ImpalaJoe1No ratings yet
- HDFS and YARNDocument91 pagesHDFS and YARNJoe1No ratings yet
- SELECT From WORLD TutorialDocument13 pagesSELECT From WORLD TutorialJoe1No ratings yet
- Knn1 HouseVotesDocument2 pagesKnn1 HouseVotesJoe1No ratings yet
- SELECT From NobelDocument13 pagesSELECT From NobelJoe1No ratings yet
- Decision Tree and EDA With Functions: Import Pandas As PDDocument9 pagesDecision Tree and EDA With Functions: Import Pandas As PDJoe1No ratings yet
- # Import Plotting Libraries: in (1) : Import Pandas As PDDocument13 pages# Import Plotting Libraries: in (1) : Import Pandas As PDJoe1No ratings yet
- Regular Expressions in PythonDocument16 pagesRegular Expressions in PythonJoe1No ratings yet
- Random Forest/Roc&Auc - Hyperparamer Tuning With For Loop - TITANIC DBDocument17 pagesRandom Forest/Roc&Auc - Hyperparamer Tuning With For Loop - TITANIC DBJoe1No ratings yet
- Random Forest: Random Forest Has Classifier For Classification and Regressor For RegressionDocument9 pagesRandom Forest: Random Forest Has Classifier For Classification and Regressor For RegressionJoe1No ratings yet
- Digits Recognition DatasetDocument4 pagesDigits Recognition DatasetJoe1No ratings yet
- How To Analyze Data Using The Average: Link ForDocument1 pageHow To Analyze Data Using The Average: Link ForJoe1No ratings yet
- Model Question Paper Subject Code: MC0068 Subject Name: Data Structure Using C Credits: 4 Marks: 140 Part A (One Mark Questions)Document13 pagesModel Question Paper Subject Code: MC0068 Subject Name: Data Structure Using C Credits: 4 Marks: 140 Part A (One Mark Questions)sailendra31No ratings yet
- Math Clue Words Activities FreebieDocument5 pagesMath Clue Words Activities Freebieandrea dulayNo ratings yet
- Parwaz TalkDocument25 pagesParwaz TalkArtik JainNo ratings yet
- Live 4992 9623 JairDocument76 pagesLive 4992 9623 JairAntonio MarcegagliaNo ratings yet
- Kirchner, PaulDocument1 pageKirchner, PaulRaphael BazanNo ratings yet
- (Always Learning) Bali, S.P - Electrical Technology-Dorling Kindersley (India) (2013)Document605 pages(Always Learning) Bali, S.P - Electrical Technology-Dorling Kindersley (India) (2013)theking Cor100% (1)
- Fluid Mechanics II (Chapter 2)Document16 pagesFluid Mechanics II (Chapter 2)حيدر محمدNo ratings yet
- 4th Grade - Adding and Subtracting Whole NumbersDocument2 pages4th Grade - Adding and Subtracting Whole NumbersCandice NunesNo ratings yet
- 2.1 Determinants by Cofactor ExpansionDocument9 pages2.1 Determinants by Cofactor ExpansionDương KhảiNo ratings yet
- Questions & Answers On Techniques of Circuit AnalysisDocument47 pagesQuestions & Answers On Techniques of Circuit Analysiskibrom atsbha100% (2)
- Book Summary Made To StickDocument4 pagesBook Summary Made To StickMichiel Kraijer100% (1)
- Lecture 17 - Parity Generators & Checkers and Magnitude Comparator PDFDocument14 pagesLecture 17 - Parity Generators & Checkers and Magnitude Comparator PDFModhumita DasNo ratings yet
- New Syllabus Additional MathematicsDocument556 pagesNew Syllabus Additional MathematicsChin Mun Loy100% (3)
- Ann - Simulation of Fault Detection For Protection of Transmission Line Using Neural Network - 2014Document5 pagesAnn - Simulation of Fault Detection For Protection of Transmission Line Using Neural Network - 2014andhita mahayana buat tugasNo ratings yet
- KA SET A Cost PrelimsDocument16 pagesKA SET A Cost PrelimsGeozelle BenitoNo ratings yet
- 4 Expressions and Iteration - Terraform in DepthDocument76 pages4 Expressions and Iteration - Terraform in DepthHarsh GuptaNo ratings yet
- Final Project ReportDocument20 pagesFinal Project ReportAnonymous OE2WpW0% (1)
- Holidays Homework (9th) (2023-24)Document14 pagesHolidays Homework (9th) (2023-24)Vedhant KhajuriaNo ratings yet
- Temporary Refuge - FPSO AccommodationDocument10 pagesTemporary Refuge - FPSO Accommodationcxb07164No ratings yet
- CH07 Characters, Strings and StringBuilderDocument43 pagesCH07 Characters, Strings and StringBuilderNhemi EstradaNo ratings yet
- Programming Methodology: Subject Title: Subject Code: Periods/Week: 3+2 Periods /semester: 90 Credits: 4Document7 pagesProgramming Methodology: Subject Title: Subject Code: Periods/Week: 3+2 Periods /semester: 90 Credits: 4om98474831879339No ratings yet
- Uimo Success 03 A4Document13 pagesUimo Success 03 A4nageswara kuchipudiNo ratings yet
- Notes From Anton 10 TH Ed CH 4Document5 pagesNotes From Anton 10 TH Ed CH 4Web MastersNo ratings yet
- Physics DPPDocument24 pagesPhysics DPPAmudala HemashviniNo ratings yet
- Engineering Mechanics QuestionsDocument9 pagesEngineering Mechanics QuestionsHarshil PatelNo ratings yet
- Pairs Trading Strategy For BANKNIFTYDocument16 pagesPairs Trading Strategy For BANKNIFTYAmber Gupta100% (1)
- 《燃烧学导论 概念与应用》第四章习题 参考答案Document7 pages《燃烧学导论 概念与应用》第四章习题 参考答案Yue ZhaoNo ratings yet
- Power Series: By: Engr. Ferdinand L. MarcosDocument35 pagesPower Series: By: Engr. Ferdinand L. MarcosVince Joseph FabayNo ratings yet
- 1 Mat071 Module1 PDFDocument100 pages1 Mat071 Module1 PDFjurilyn alvadorNo ratings yet
- Math G10 Nat Leaf Oco CallioDocument5 pagesMath G10 Nat Leaf Oco CallioChester Austin Reese Maslog Jr.No ratings yet