Download as pdf or txt
You might also like
- Computer Graphics A Programming Approach Harrington, Steven 1987Document492 pagesComputer Graphics A Programming Approach Harrington, Steven 1987Aryan Gupta100% (2)
- Principles of Optimal Design 2ed - Papalambros, Wilde PDFDocument412 pagesPrinciples of Optimal Design 2ed - Papalambros, Wilde PDFlig100% (3)
- Step Pattern in QuadraticDocument2 pagesStep Pattern in Quadraticanistirmizi9683100% (2)
- Mirror Descent and Nonlinear Projected Subgradient Methods For Convex OptimizationDocument9 pagesMirror Descent and Nonlinear Projected Subgradient Methods For Convex OptimizationfurbyhaterNo ratings yet
- Indefinite Symmetric SystemDocument18 pagesIndefinite Symmetric SystemsalmansalsabilaNo ratings yet
- Wen You Chen 2020Document14 pagesWen You Chen 2020HAFIZ LAWAL IBRAHIMNo ratings yet
- Hindawi2022 The - Solution - of - Absolute - Value - Equations - Using - TwoDocument7 pagesHindawi2022 The - Solution - of - Absolute - Value - Equations - Using - Two1915607No ratings yet
- Symmetry: Modified Jacobi-Gradient Iterative Method For Generalized Sylvester Matrix EquationDocument15 pagesSymmetry: Modified Jacobi-Gradient Iterative Method For Generalized Sylvester Matrix EquationEDU CIPANANo ratings yet
- Time Harmonic Maxwell EqDocument16 pagesTime Harmonic Maxwell Eqawais4125No ratings yet
- An Efficient Itterative Method Based On 2 Stage Spliting Method To Solve Weakly Nonlinear SystemsDocument17 pagesAn Efficient Itterative Method Based On 2 Stage Spliting Method To Solve Weakly Nonlinear SystemsSIDDHARTH MITRANo ratings yet
- Approximating The Logarithm of A Matrix To Specified AccuracyDocument14 pagesApproximating The Logarithm of A Matrix To Specified AccuracyfewieNo ratings yet
- Hone On Nonstandard Numerical Integration Methods For Biological OscillatorsDocument17 pagesHone On Nonstandard Numerical Integration Methods For Biological Oscillatorsjjj_ddd_pierreNo ratings yet
- Block Biconjugate o LearyDocument30 pagesBlock Biconjugate o Learybikash bayanNo ratings yet
- Remezr2 ArxivDocument30 pagesRemezr2 ArxivFlorinNo ratings yet
- A Deterministic Strongly Polynomial Algorithm For Matrix Scaling and Approximate PermanentsDocument23 pagesA Deterministic Strongly Polynomial Algorithm For Matrix Scaling and Approximate PermanentsShubhamParasharNo ratings yet
- Marsden, J.E. Ratiu, T.S. - SupplementDocument95 pagesMarsden, J.E. Ratiu, T.S. - SupplementcorneliaNo ratings yet
- Steepest DescentDocument7 pagesSteepest DescentstankccNo ratings yet
- Lifting Ell - Q-Optimization ThresholdsDocument29 pagesLifting Ell - Q-Optimization Thresholdscrocoali000No ratings yet
- Kernal Methods Machine LearningDocument53 pagesKernal Methods Machine LearningpalaniNo ratings yet
- Applications of Random SamplingDocument35 pagesApplications of Random Samplingvanessita578No ratings yet
- Aula 7 - Teoria de Cordas MITDocument7 pagesAula 7 - Teoria de Cordas MITErick MouraNo ratings yet
- A Dynamic Topological Sort Algorithm For Directed Acyclic GraphsDocument24 pagesA Dynamic Topological Sort Algorithm For Directed Acyclic Graphsgallium.09.gleeNo ratings yet
- WP 95 015Document21 pagesWP 95 015Carlos Eduardo Morales MayhuayNo ratings yet
- Mathematics 05 00005 PDFDocument17 pagesMathematics 05 00005 PDFTaher JelleliNo ratings yet
- General Least Squares Smoothing and Differentiation of Nonuniformly Spaced Data by The Convolution Method.Document3 pagesGeneral Least Squares Smoothing and Differentiation of Nonuniformly Spaced Data by The Convolution Method.Vladimir PelekhatyNo ratings yet
- Defense Technical Information Center Compilation Part NoticeDocument10 pagesDefense Technical Information Center Compilation Part NoticeAhmed RebiiNo ratings yet
- Convergence of the generalized-α scheme for constrained mechanical systemsDocument18 pagesConvergence of the generalized-α scheme for constrained mechanical systemsCesar HernandezNo ratings yet
- Abstract Poster PDFDocument21 pagesAbstract Poster PDFMohan Kumar100% (1)
- A Parallel Algorithm For Constrained Optimization ProblemsDocument6 pagesA Parallel Algorithm For Constrained Optimization Problemssami_aldalahmehNo ratings yet
- D034017022 PDFDocument6 pagesD034017022 PDFmario olivaresNo ratings yet
- Long-Term Prediction of Time Series Using State-Space ModelsDocument11 pagesLong-Term Prediction of Time Series Using State-Space ModelsMurilo CamargosNo ratings yet
- Jennings, Tuff - An Iterative Method For Large Systems of Linear Structural Equations, 1973Document9 pagesJennings, Tuff - An Iterative Method For Large Systems of Linear Structural Equations, 1973martrantNo ratings yet
- Algorithms For Solving Nonlinear Systems of EquationsDocument28 pagesAlgorithms For Solving Nonlinear Systems of Equationslvjiaze12100% (1)
- Variable Neighborhood Search For The Probabilistic Satisfiability ProblemDocument6 pagesVariable Neighborhood Search For The Probabilistic Satisfiability Problemsk8888888No ratings yet
- COMSOL Conf CardiffDocument8 pagesCOMSOL Conf CardiffLexin LiNo ratings yet
- Iterative Solution of Algebraic Riccati Equations For Damped SystemsDocument5 pagesIterative Solution of Algebraic Riccati Equations For Damped Systemsboffa126No ratings yet
- Improving The Accuracy of Computed Eigenvalues and EigenvectorsDocument23 pagesImproving The Accuracy of Computed Eigenvalues and EigenvectorsFilipe AmaroNo ratings yet
- Stats306b Spring14 Lecture7 - ScribedDocument6 pagesStats306b Spring14 Lecture7 - ScribedasfdSFDSFGENo ratings yet
- 1 s2.0 S0893965924000855 MainDocument9 pages1 s2.0 S0893965924000855 Mainmosab.backkupNo ratings yet
- Amc LrsweDocument29 pagesAmc LrsweSwagata BhaumikNo ratings yet
- An Improved Heaviside Approach To Partial Fraction Expansion and Its ApplicationsDocument3 pagesAn Improved Heaviside Approach To Partial Fraction Expansion and Its ApplicationsDong Ju ShinNo ratings yet
- Fixed-Point Iteration Based Algorithm For A ClassDocument13 pagesFixed-Point Iteration Based Algorithm For A ClassNick MantzakourasNo ratings yet
- Optimal Ordering SchemesDocument26 pagesOptimal Ordering SchemesSubramaniam GnanasekaranNo ratings yet
- A Matrix Pencil Approach To The Row by Row DecouplDocument22 pagesA Matrix Pencil Approach To The Row by Row DecouplfatihaNo ratings yet
- Numerically Stable LDL Factorizations in Interior Point Methods For Convex Quadratic ProgrammingDocument21 pagesNumerically Stable LDL Factorizations in Interior Point Methods For Convex Quadratic Programmingmajed_ahmadi1984943No ratings yet
- Radial Basis Functions by BuhmannDocument38 pagesRadial Basis Functions by BuhmannSarah Ayu NandaNo ratings yet
- Global Convergence of A Trust-Region Sqp-Filter Algorithm For General Nonlinear ProgrammingDocument25 pagesGlobal Convergence of A Trust-Region Sqp-Filter Algorithm For General Nonlinear ProgrammingAndressa PereiraNo ratings yet
- Christophe Andrieu - Arnaud Doucet Bristol, BS8 1TW, UK. Cambridge, CB2 1PZ, UK. EmailDocument4 pagesChristophe Andrieu - Arnaud Doucet Bristol, BS8 1TW, UK. Cambridge, CB2 1PZ, UK. EmailNeil John AppsNo ratings yet
- Averaging Oscillations With Small Fractional Damping and Delayed TermsDocument20 pagesAveraging Oscillations With Small Fractional Damping and Delayed TermsYogesh DanekarNo ratings yet
- An Algorithm For Quadratic Optimization With One Quadratic Constraint and Bounds On The VariablesDocument9 pagesAn Algorithm For Quadratic Optimization With One Quadratic Constraint and Bounds On The Variablesgijs fehmersNo ratings yet
- Almost Sharp Fronts For The Surface Geostrophic Equation: SignificanceDocument4 pagesAlmost Sharp Fronts For The Surface Geostrophic Equation: SignificanceNeil JethaniNo ratings yet
- A New Lower Bound Via Projection For The Quadratic Assignment ProblemDocument17 pagesA New Lower Bound Via Projection For The Quadratic Assignment Problemبن الشيخ عليNo ratings yet
- Lattice QCDDocument42 pagesLattice QCDBarbara YaeggyNo ratings yet
- Effective Partitioning Method For Computing Generalized Inverses and Their GradientsDocument13 pagesEffective Partitioning Method For Computing Generalized Inverses and Their GradientsVukasinnnNo ratings yet
- Technical Report No. 1/12, February 2012 Jackknifing The Ridge Regression Estimator: A Revisit Mansi Khurana, Yogendra P. Chaubey and Shalini ChandraDocument22 pagesTechnical Report No. 1/12, February 2012 Jackknifing The Ridge Regression Estimator: A Revisit Mansi Khurana, Yogendra P. Chaubey and Shalini ChandraRatna YuniartiNo ratings yet
- Theoretical Analysis of Numerical Integration in Galerkin Meshless MethodsDocument22 pagesTheoretical Analysis of Numerical Integration in Galerkin Meshless MethodsDheeraj_GopalNo ratings yet
- Reconstruction of Variational Iterative Method For Solving Fifth Order Caudrey-Dodd-Gibbon (CDG) EquationDocument4 pagesReconstruction of Variational Iterative Method For Solving Fifth Order Caudrey-Dodd-Gibbon (CDG) EquationInternational Journal of Science and Engineering InvestigationsNo ratings yet
- KMeansPP SodaDocument9 pagesKMeansPP Sodaalanpicard2303No ratings yet
- Factoring Algorithm Based On Parameterized Newton Method-Zhengjun Cao and Lihua LiuDocument7 pagesFactoring Algorithm Based On Parameterized Newton Method-Zhengjun Cao and Lihua LiuLuiz MattosNo ratings yet
- Section-3.8 Gauss JacobiDocument15 pagesSection-3.8 Gauss JacobiKanishka SainiNo ratings yet
- A Method For The Approximation of Functions Defined by Formal Series ExpansionsDocument13 pagesA Method For The Approximation of Functions Defined by Formal Series ExpansionskensaiiNo ratings yet
- Matrices and Determinants Explanations and SamplesDocument15 pagesMatrices and Determinants Explanations and SamplesIvy Lopez FranciscoNo ratings yet
- Grade 4 - Q3 Math LessonDocument42 pagesGrade 4 - Q3 Math LessonHF ManigbasNo ratings yet
- M Athematics 7: Quarter 1 - Module 3: Lesson 1: Absolute Value of A Number Lesson 2: Fundam Ental Operations OnDocument20 pagesM Athematics 7: Quarter 1 - Module 3: Lesson 1: Absolute Value of A Number Lesson 2: Fundam Ental Operations OnhaileyNo ratings yet
- FunctionsDocument17 pagesFunctionsAnshika ChawlaNo ratings yet
- Entity Analysis ResolutionDocument22 pagesEntity Analysis Resolutionalfredo14838100% (1)
- TCS NQT Aptitude Paper: Sum of The Squares of Its DigitsDocument8 pagesTCS NQT Aptitude Paper: Sum of The Squares of Its DigitsAman RajNo ratings yet
- 4.divide and ConquerDocument22 pages4.divide and ConquerPraveen MenasinakaiNo ratings yet
- 00660Document244 pages00660Marcelino MeinckeNo ratings yet
- First-Order Logic Syntax of FOL: - Objects, - Properties - Relations - FunctionsDocument7 pagesFirst-Order Logic Syntax of FOL: - Objects, - Properties - Relations - FunctionsdokeosNo ratings yet
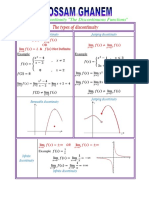
- 2.5 Continuity (The Discontinuous Functions) (A)Document8 pages2.5 Continuity (The Discontinuous Functions) (A)Erwiyan Fajar Ansori100% (1)
- 11-Hamiltonian Using BACKTRACKINGDocument5 pages11-Hamiltonian Using BACKTRACKINGNandeesh PuriNo ratings yet
- SadfasdfDocument7 pagesSadfasdfred cowNo ratings yet
- 1966 EngulfingDocument3 pages1966 Engulfingnishio fdNo ratings yet
- Optimization TechniqueDocument30 pagesOptimization Techniquerahuljiit100% (6)
- Worksheet On Straight Line Graphs Part 1 KS3 and KS4 - by - Hassan - LakissDocument10 pagesWorksheet On Straight Line Graphs Part 1 KS3 and KS4 - by - Hassan - LakissZaleha ZazaNo ratings yet
- MATH2059 - Ozge KK-Chapter1Document34 pagesMATH2059 - Ozge KK-Chapter1demir ermanNo ratings yet
- Brockington College Mathematics Faculty Homework BookletDocument31 pagesBrockington College Mathematics Faculty Homework BookletNayem Hossain HemuNo ratings yet
- Applied Calculus For The Managerial Life and Social Sciences 9th Edition Tan Test BankDocument46 pagesApplied Calculus For The Managerial Life and Social Sciences 9th Edition Tan Test Banklisaclarkfgsocdkpix100% (41)
- CentralityDocument4 pagesCentralitymesay83No ratings yet
- Calculus 1 - Math6100: QUIZ 1 - Prelim ExamDocument79 pagesCalculus 1 - Math6100: QUIZ 1 - Prelim ExamDan Jasper RoncalNo ratings yet
- Lecture24 PDFDocument4 pagesLecture24 PDFalagarg137691No ratings yet
- Module 7Document34 pagesModule 7Laika EnriquezNo ratings yet
- j1q Que 1jiDocument4 pagesj1q Que 1jiPro sethNo ratings yet
- Conjugate Roots MarkschemeDocument5 pagesConjugate Roots MarkschemeDileep NaraharasettyNo ratings yet
- Workshop On Exact EquationsDocument18 pagesWorkshop On Exact EquationsLawson SangoNo ratings yet
- Chapter 8 PDFDocument5 pagesChapter 8 PDFSHIVAS RAINANo ratings yet
- bAcAl PpTs 3rD QDocument78 pagesbAcAl PpTs 3rD QJoe NasalitaNo ratings yet