Download as pdf or txt
You might also like
- Sqoop CommandsDocument4 pagesSqoop CommandsSenthil KumarNo ratings yet
- Hadoop Interview Questions NewDocument9 pagesHadoop Interview Questions NewRupali ShettyNo ratings yet
- Hands On Big DataDocument52 pagesHands On Big DatapratapNo ratings yet
- Resources For Rero - Micro Lessons 1 To 10Document11 pagesResources For Rero - Micro Lessons 1 To 10hj waladcute100% (3)
- Exploring Bigdata With Hadoop: Dr.A.Bazila Banu Associate Professor Department of CseDocument23 pagesExploring Bigdata With Hadoop: Dr.A.Bazila Banu Associate Professor Department of CseMAMAN MYTHIEN SNo ratings yet
- Hadoop and Their EcosystemDocument24 pagesHadoop and Their Ecosystemsunera pathan100% (2)
- Hadoop Module 3.2Document57 pagesHadoop Module 3.2Sainath Reddy100% (1)
- Hadoop LabDocument6 pagesHadoop Labanirudh sanga100% (2)
- Hive Real Life Use Cases - AcadGild BlogDocument19 pagesHive Real Life Use Cases - AcadGild BlogHarshit SinhaNo ratings yet
- HADOOPDocument35 pagesHADOOPEkapop Verasakulvong100% (1)
- Bigdata With PythonDocument19 pagesBigdata With PythonAmrit ChhetribNo ratings yet
- Course Contents of Hadoop and Big DataDocument11 pagesCourse Contents of Hadoop and Big DatarahulsseNo ratings yet
- Edureka Interview Questions - HDFSDocument4 pagesEdureka Interview Questions - HDFSvarunpratapNo ratings yet
- Hadoop NotesDocument11 pagesHadoop NotesVijay Vishwanath ThombareNo ratings yet
- Big Data and Spark DevelopersDocument5 pagesBig Data and Spark DevelopersBalaji ArunNo ratings yet
- Big Data Introduction PDFDocument180 pagesBig Data Introduction PDFvaltech20086605No ratings yet
- Spark Sample Resume 2Document7 pagesSpark Sample Resume 2pupscribd100% (1)
- 24 Hadoop Interview Questions & Answers For MapReduce Developers - FromDevDocument7 pages24 Hadoop Interview Questions & Answers For MapReduce Developers - FromDevnalinbhattNo ratings yet
- Hadoop & Big DataDocument36 pagesHadoop & Big DataParesh BhatiaNo ratings yet
- Spark With BigdataDocument94 pagesSpark With BigdataNagendra VenkatNo ratings yet
- Ajay Singh - Hadoop ResumeDocument2 pagesAjay Singh - Hadoop ResumeAjay Singh67% (3)
- Hadoop and Java Ques - AnsDocument222 pagesHadoop and Java Ques - AnsraviNo ratings yet
- Hadoop Shell CommandsDocument63 pagesHadoop Shell Commandssrikant4u4670100% (1)
- Hadoop Interviews QDocument9 pagesHadoop Interviews QS KNo ratings yet
- ResumeDocument4 pagesResumeshekharNo ratings yet
- Deepak Professional SummaryDocument3 pagesDeepak Professional Summaryaras4mavis1932No ratings yet
- Certified Hadoop and Spark Course CurriculumDocument9 pagesCertified Hadoop and Spark Course Curriculummano555No ratings yet
- Sqoop Interview QuestionsDocument6 pagesSqoop Interview QuestionsGuruprasad VijayakumarNo ratings yet
- Apache HiveDocument3 pagesApache Hivekual21No ratings yet
- Unit 5Document109 pagesUnit 5Rajesh Kumar RakasulaNo ratings yet
- Hortonworks Cluster Config Guide.1.0Document15 pagesHortonworks Cluster Config Guide.1.0Parham KhanlarkhaniNo ratings yet
- Hadoop Admin Download Syllabus PDFDocument4 pagesHadoop Admin Download Syllabus PDFshubham phulariNo ratings yet
- BIG DATA WITH HADOOP, HDFS & MAPREDUCE (Hands On Training)Document35 pagesBIG DATA WITH HADOOP, HDFS & MAPREDUCE (Hands On Training)D.KESAVARAJANo ratings yet
- Hadoop: Fasilkom/Pusilkom UI (Credit: Samuel Louvan)Document44 pagesHadoop: Fasilkom/Pusilkom UI (Credit: Samuel Louvan)Johan Rizky AdityaNo ratings yet
- Teradata & AbinitioDocument2 pagesTeradata & AbinitioAtlury JeyyadevNo ratings yet
- Big Data and Hadoop For Developers - SyllabusDocument6 pagesBig Data and Hadoop For Developers - Syllabusvkbm42No ratings yet
- AaxHadoop Interview Questions and AnswersDocument37 pagesAaxHadoop Interview Questions and Answersshubham rathodNo ratings yet
- Srikanth HadoopDocument4 pagesSrikanth HadoopKarthick ThoppanNo ratings yet
- Lecture Notes HadoopDocument11 pagesLecture Notes Hadoopsakshi kureleyNo ratings yet
- Big Data Hadoop Training 8214944.ppsxDocument52 pagesBig Data Hadoop Training 8214944.ppsxhoukoumatNo ratings yet
- Hadoop Administrator Interview Questions: Cloudera® Enterprise VersionDocument13 pagesHadoop Administrator Interview Questions: Cloudera® Enterprise VersionmadhubaddapuriNo ratings yet
- Apache Hadoop Developer Training PDFDocument397 pagesApache Hadoop Developer Training PDFBalakumara Vigneshwaran100% (1)
- Hadoop Training Institute in HyderabadDocument8 pagesHadoop Training Institute in HyderabadOrienIt OrienitNo ratings yet
- Class: CS 237 Distributed Systems Middleware Instructor: Nalini VenkatasubramanianDocument55 pagesClass: CS 237 Distributed Systems Middleware Instructor: Nalini VenkatasubramanianPratheesh KumarNo ratings yet
- 7 Hive NotesDocument36 pages7 Hive NotesSandeep BoyinaNo ratings yet
- Hadoop Interview QuestionsDocument17 pagesHadoop Interview QuestionspatriciaNo ratings yet
- Cloudera Academic Partnership 3 PDFDocument103 pagesCloudera Academic Partnership 3 PDFyo2k90% (1)
- Primer On Big Data TestingDocument24 pagesPrimer On Big Data TestingSurojeet SenguptaNo ratings yet
- YARN - MapReduceDocument34 pagesYARN - MapReduceYashu SagarNo ratings yet
- Apache SparkDocument6 pagesApache SparkgeoinsysNo ratings yet
- Hadoop Developer Training - Hive Lab BookDocument51 pagesHadoop Developer Training - Hive Lab BookKarthick selvamNo ratings yet
- Hadoop Training #1: Thinking at ScaleDocument20 pagesHadoop Training #1: Thinking at ScaleDmytro Shteflyuk100% (1)
- Abinitio Online Training in USA, UK, IndiaDocument4 pagesAbinitio Online Training in USA, UK, IndiaPriyanka CHNo ratings yet
- Hadoop Interview Questions and AnswersDocument3 pagesHadoop Interview Questions and AnswersatoztargetNo ratings yet
- (Smtebooks - Eu) Apache Hadoop 3 Quick Start Guide 1st EditionDocument329 pages(Smtebooks - Eu) Apache Hadoop 3 Quick Start Guide 1st Editionyamakoy100% (2)
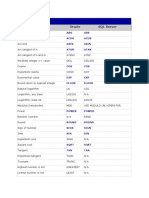
- Math Functions: Function Oracle SQL ServerDocument3 pagesMath Functions: Function Oracle SQL ServerSivaprasad ReddyNo ratings yet
- Mathematical FunctionsDocument16 pagesMathematical FunctionsSivaprasad ReddyNo ratings yet
- MPMC Lab ManualDocument37 pagesMPMC Lab ManualSivaprasad ReddyNo ratings yet
- 15A04301 Electronic Devices and CircuitsDocument1 page15A04301 Electronic Devices and CircuitsSivaprasad ReddyNo ratings yet
- CSE Department - Text Books For II-I:: A.Y - 2017-2018Document1 pageCSE Department - Text Books For II-I:: A.Y - 2017-2018Sivaprasad ReddyNo ratings yet
- RLJLDocument7 pagesRLJLSivaprasad ReddyNo ratings yet
- Assembler DirectivesDocument11 pagesAssembler DirectivesSivaprasad Reddy100% (2)
- UART - Universal Asynchronous Receiver TransmitterDocument26 pagesUART - Universal Asynchronous Receiver TransmitterSivaprasad Reddy100% (2)
- Priyadarshini Institute of Technology:: Tirupati: Department of Electronics and Communication EngineeringDocument1 pagePriyadarshini Institute of Technology:: Tirupati: Department of Electronics and Communication EngineeringSivaprasad ReddyNo ratings yet
- MPMCDocument7 pagesMPMCSivaprasad ReddyNo ratings yet
- Tech Info - SS7 Protocols: SIGTRAN and SS7 TrainingDocument6 pagesTech Info - SS7 Protocols: SIGTRAN and SS7 TrainingMadhunath YadavNo ratings yet
- Definition of FunctionDocument3 pagesDefinition of Functionapi-247658686No ratings yet
- Chapter Two Overview of Contemporary Database Models Database ModelsDocument11 pagesChapter Two Overview of Contemporary Database Models Database ModelsIroegbu Mang JohnNo ratings yet
- DBA Checklist 14Document18 pagesDBA Checklist 14shivaNo ratings yet
- SCSP 5 2 8 MP2 Release NotesDocument60 pagesSCSP 5 2 8 MP2 Release NotesMing Chek YeoNo ratings yet
- Fanuc M 900ia SeriesDocument4 pagesFanuc M 900ia SeriesLeonardo AlexNo ratings yet
- AlliedWare PlusTM HOWTODocument42 pagesAlliedWare PlusTM HOWTOliveNo ratings yet
- 1993 - Menter - Zonal Two Equation K-W Turbulence Models For Aerodynamic Flows PDFDocument22 pages1993 - Menter - Zonal Two Equation K-W Turbulence Models For Aerodynamic Flows PDFMayra ZezattiNo ratings yet
- Tamil Iamwarm MagazineDocument3 pagesTamil Iamwarm MagazinerpNo ratings yet
- 01 OverviewDocument65 pages01 OverviewdqltakedaNo ratings yet
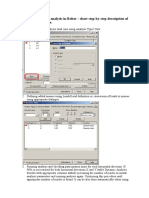
- Defining EC8 Seismic Analysis in Robot - ExampleDocument5 pagesDefining EC8 Seismic Analysis in Robot - ExampleMircea TomusNo ratings yet
- M.Sc. Degree Examination, November 2015 Third Semester Computer Science and Information Technology Elective - E-COMMERCE (CBCS - 2011 Onwards)Document31 pagesM.Sc. Degree Examination, November 2015 Third Semester Computer Science and Information Technology Elective - E-COMMERCE (CBCS - 2011 Onwards)Kishore KumarNo ratings yet
- Adriana Paraschiv, PMPDocument4 pagesAdriana Paraschiv, PMPadaparas7095No ratings yet
- Manual - Forex Generator Version 7.x: Main WebsiteDocument115 pagesManual - Forex Generator Version 7.x: Main WebsiteAly DianisNo ratings yet
- 1Z0-071 Sample QuestionsDocument8 pages1Z0-071 Sample QuestionsmadhubanNo ratings yet
- 2 Overview of Numerical AnalysisDocument59 pages2 Overview of Numerical AnalysisVashish RamrechaNo ratings yet
- Script To Load FND USER in R11iDocument3 pagesScript To Load FND USER in R11imuthuaptNo ratings yet
- Action Cam T5e: Quick Start GuideDocument34 pagesAction Cam T5e: Quick Start GuideRicardo HodlsNo ratings yet
- Security Concerns and Best Practices For A SAS GridDocument7 pagesSecurity Concerns and Best Practices For A SAS GridValli DadigeNo ratings yet
- Ansa For Automatic MeshingDocument6 pagesAnsa For Automatic MeshingRanjit RajendranNo ratings yet
- Enhanced VPC Design n5kDocument12 pagesEnhanced VPC Design n5ktopdavisNo ratings yet
- How To Find The Overdue Jobs?Document12 pagesHow To Find The Overdue Jobs?Denizio CaldasNo ratings yet
- PythonDocument14 pagesPythonDarshan M MNo ratings yet
- HTML Basic LessonDocument8 pagesHTML Basic LessonR TECHNo ratings yet
- Action On NCRDocument31 pagesAction On NCRArunPadmanManayil100% (1)
- Regular ExpressionDocument17 pagesRegular ExpressionMag CreationNo ratings yet
- 16 N217 ResumeDocument2 pages16 N217 ResumePalani Kathir VelNo ratings yet
- Cpu Utilisation CommandsDocument7 pagesCpu Utilisation Commandsvijukm2000No ratings yet