Download as pdf or txt
You might also like
- Deep Learning Image ClassificationDocument11 pagesDeep Learning Image ClassificationPRIYANKA TATANo ratings yet
- Feng Liang Et Al - 2021 - Efficient Neural Network Using Pointwise Convolution Kernels With Linear PhaseDocument8 pagesFeng Liang Et Al - 2021 - Efficient Neural Network Using Pointwise Convolution Kernels With Linear Phasebigliang98No ratings yet
- Feature Fusion Based On Convolutional Neural Netwo PDFDocument8 pagesFeature Fusion Based On Convolutional Neural Netwo PDFNguyễn Thành TânNo ratings yet
- ReportDocument21 pagesReportkiswah computersNo ratings yet
- Deep Learning Approach For Object Detection Using CNN: AbstractDocument7 pagesDeep Learning Approach For Object Detection Using CNN: AbstractAYUSH MISHRANo ratings yet
- Deep Learning Algorithms and ArchitecturesDocument26 pagesDeep Learning Algorithms and Architecturessashank7No ratings yet
- A Survey On Deep Network PDFDocument24 pagesA Survey On Deep Network PDFMateus MeirelesNo ratings yet
- Recognition of Handwritten Digit Using Convolutional Neural Network in Python With Tensorflow and Comparison of Performance For Various Hidden LayersDocument6 pagesRecognition of Handwritten Digit Using Convolutional Neural Network in Python With Tensorflow and Comparison of Performance For Various Hidden Layersjaime yelsin rosales malpartidaNo ratings yet
- Deep Cascade LearningDocument11 pagesDeep Cascade Learningcoelho.alv4544No ratings yet
- Gap Method For Keyword Spotting: Varsha Thakur, HimanisikarwarDocument7 pagesGap Method For Keyword Spotting: Varsha Thakur, HimanisikarwarSunil ChaluvaiahNo ratings yet
- Feature Extraction Using Convolution Neural Networks (CNN) and Deep LearningDocument5 pagesFeature Extraction Using Convolution Neural Networks (CNN) and Deep LearningHarshitha SNo ratings yet
- A High-Efficiency Spaceborne Processor For Hybrid Neural NetworksDocument16 pagesA High-Efficiency Spaceborne Processor For Hybrid Neural NetworksguantongpengNo ratings yet
- Student Notes - Convolutional Neural Networks (CNN) Introduction - Belajar Pembelajaran Mesin IndonesiaDocument14 pagesStudent Notes - Convolutional Neural Networks (CNN) Introduction - Belajar Pembelajaran Mesin Indonesiaandres alfonso varelo silgadoNo ratings yet
- A New Channel Boosted Convolutional Neural Network Using Transfer LearningDocument24 pagesA New Channel Boosted Convolutional Neural Network Using Transfer LearningMistlemagicNo ratings yet
- Deep Embedding Network For ClusteringDocument6 pagesDeep Embedding Network For Clusteringdonaldo garciaNo ratings yet
- Technical Seminar PDFDocument9 pagesTechnical Seminar PDFAdil khanNo ratings yet
- Improved Fault Diagnosis in Wireless Sensor Networks Using Deep Learning TechniqueDocument4 pagesImproved Fault Diagnosis in Wireless Sensor Networks Using Deep Learning TechniqueKeerthi GuruNo ratings yet
- A Literature Study of Deep Learning and Its Application in Digital Image ProcessingDocument12 pagesA Literature Study of Deep Learning and Its Application in Digital Image ProcessingArct John Alfante ZamoraNo ratings yet
- A Deep Learning Convolutional Neural Network in Health Care EnvironmentDocument17 pagesA Deep Learning Convolutional Neural Network in Health Care EnvironmentVasiha Fathima RNo ratings yet
- Hafemann Ijcnn 2015Document7 pagesHafemann Ijcnn 2015Betül KaraNo ratings yet
- Handwritten Digit Recognition Using Machine LearningDocument5 pagesHandwritten Digit Recognition Using Machine LearningGowthami Reddy KovvuriNo ratings yet
- Deep LearningDocument8 pagesDeep LearningSheela SankariNo ratings yet
- An Overview of Popular Deep Learning Methods PDFDocument12 pagesAn Overview of Popular Deep Learning Methods PDFOussama El B'charriNo ratings yet
- Convolutional Neural Networks For Image Processing: An Application in Robot VisionDocument14 pagesConvolutional Neural Networks For Image Processing: An Application in Robot Visionvamsidhar2008No ratings yet
- Google Wakeword Detection 2 PDFDocument5 pagesGoogle Wakeword Detection 2 PDFÖzgür Bora GevrekNo ratings yet
- Chord Detection Using Deep LearningDocument7 pagesChord Detection Using Deep LearningD Ban ChoNo ratings yet
- A Compressed Deep Convolutional Neural Networks For Face RecognitionDocument6 pagesA Compressed Deep Convolutional Neural Networks For Face RecognitionSiddharth KoliparaNo ratings yet
- Structured Pruning of Deep Convolutional Neural Netw Orks: Sajid Anwar, Kyuyeon Hwang and Wonyong SungDocument11 pagesStructured Pruning of Deep Convolutional Neural Netw Orks: Sajid Anwar, Kyuyeon Hwang and Wonyong Sungali shaarawyNo ratings yet
- 1 s2.0 S2213138822001102 MainDocument8 pages1 s2.0 S2213138822001102 MainGuru VelmathiNo ratings yet
- Icarcv 2014 LCWZFCDocument5 pagesIcarcv 2014 LCWZFCMuhammad FajriantoNo ratings yet
- MLOA Exp 1 - C121Document18 pagesMLOA Exp 1 - C121Devanshu MaheshwariNo ratings yet
- Aidl Unit IIIDocument79 pagesAidl Unit IIIkanchiraju vamsiNo ratings yet
- 2 Convolutional Neural Network For Image ClassificationDocument6 pages2 Convolutional Neural Network For Image ClassificationKompruch BenjaputharakNo ratings yet
- A Survey of Deep Neural Network Architectures and Their Applications PDFDocument16 pagesA Survey of Deep Neural Network Architectures and Their Applications PDFFuwei TIANNo ratings yet
- Neural Network With Bag of FeaturesDocument11 pagesNeural Network With Bag of FeaturesMilad EslaminiaNo ratings yet
- Deep PaperDocument12 pagesDeep PaperasdfghNo ratings yet
- Review of Deep Learning Algorithms and ArchitecturDocument29 pagesReview of Deep Learning Algorithms and ArchitecturShuvo H AhmedNo ratings yet
- Human Action Recognition System For Elderly and Children Care Using Three Stream ConvNetDocument5 pagesHuman Action Recognition System For Elderly and Children Care Using Three Stream ConvNetMitchell Angel Gomez OrtegaNo ratings yet
- Deeplab: Semantic Image Segmentation With Deep Convolutional Nets, Atrous Convolution, and Fully Connected CrfsDocument14 pagesDeeplab: Semantic Image Segmentation With Deep Convolutional Nets, Atrous Convolution, and Fully Connected CrfsDesigner TeesNo ratings yet
- Joint Estimation of Age and Gender From Unconstrained Face Images Using Lightweight Multi-Task CNN For Mobile ApplicationsDocument4 pagesJoint Estimation of Age and Gender From Unconstrained Face Images Using Lightweight Multi-Task CNN For Mobile ApplicationsAnil Kumar BNo ratings yet
- Modelling and Designing of CNN For Feature Abstraction.: Presented By:-Krusha Sandip JoshiDocument13 pagesModelling and Designing of CNN For Feature Abstraction.: Presented By:-Krusha Sandip JoshiKrusha JoshiNo ratings yet
- Advancements in Image Classification Using Convolutional Neural NetworkDocument8 pagesAdvancements in Image Classification Using Convolutional Neural NetworkvamsidayyalaNo ratings yet
- A 64-Tile 2.4-Mb in-Memory-Computing CNN Accelerator Employing Charge-Domain ComputeDocument5 pagesA 64-Tile 2.4-Mb in-Memory-Computing CNN Accelerator Employing Charge-Domain ComputeHelloNo ratings yet
- An Introduction To Convolutional Neural NetworksDocument7 pagesAn Introduction To Convolutional Neural NetworksIJRASETPublicationsNo ratings yet
- Image Based ClassificationDocument8 pagesImage Based ClassificationMuhammad Sami UllahNo ratings yet
- Prakash2019 - Face RecognitionDocument4 pagesPrakash2019 - Face Recognitioneshwari2000No ratings yet
- DL Anonymous Question BankDocument22 pagesDL Anonymous Question BankAnuradha PiseNo ratings yet
- Accelerated Deep Learning Inference From Constrained Embedded DevicesDocument5 pagesAccelerated Deep Learning Inference From Constrained Embedded DevicesBhargav BhatNo ratings yet
- Design of UWB Antenna Based On Improved Deep Belief Network and Extreme Learning Machine Surrogate ModelsDocument9 pagesDesign of UWB Antenna Based On Improved Deep Belief Network and Extreme Learning Machine Surrogate ModelsPonduri SivaprasadNo ratings yet
- Multi-Branch Network With Dynamically Matching Algorithm in Person Re-IdentificationDocument5 pagesMulti-Branch Network With Dynamically Matching Algorithm in Person Re-IdentificationThien ThaiNo ratings yet
- On An Improvement of Graph Convolutional Network in Semi-Supervised LearningDocument4 pagesOn An Improvement of Graph Convolutional Network in Semi-Supervised LearningThien ThaiNo ratings yet
- Chord Detection Using Deep LearningDocument8 pagesChord Detection Using Deep LearningEugene QuahNo ratings yet
- MobileNetV2 Inverted Residuals and Linear BottlenecksDocument11 pagesMobileNetV2 Inverted Residuals and Linear BottlenecksPedro PietrafesaNo ratings yet
- Understanding of Convolutional Neural Network (CNN)Document9 pagesUnderstanding of Convolutional Neural Network (CNN)senthilNo ratings yet
- Sensors: Depth Estimation and Semantic Segmentation From A Single RGB Image Using A Hybrid Convolutional Neural NetworkDocument20 pagesSensors: Depth Estimation and Semantic Segmentation From A Single RGB Image Using A Hybrid Convolutional Neural NetworkKratika VarshneyNo ratings yet
- 3098 15835 1 PB 2011 PDFDocument6 pages3098 15835 1 PB 2011 PDFJorge Velasquez RamosNo ratings yet
- Environmental Sound Classificationwith Convolutional Neural NetworksDocument6 pagesEnvironmental Sound Classificationwith Convolutional Neural Networksamine hamdiNo ratings yet
- Object Detection Using CNNDocument5 pagesObject Detection Using CNNHi ManshuNo ratings yet
- tmpD684 TMPDocument8 pagestmpD684 TMPFrontiersNo ratings yet
- Deep Learning with Python: A Comprehensive Guide to Deep Learning with PythonFrom EverandDeep Learning with Python: A Comprehensive Guide to Deep Learning with PythonNo ratings yet
- CS230 Midterm Solutions Fall 2021Document14 pagesCS230 Midterm Solutions Fall 2021ahmedmody2001No ratings yet
- Lecture 6Document41 pagesLecture 6Sher Afghan MalikNo ratings yet
- Unit 5 ClusteringDocument70 pagesUnit 5 ClusteringrrrNo ratings yet
- Airport Terminal Construction Delay Prediction Using BPNNDocument11 pagesAirport Terminal Construction Delay Prediction Using BPNNKhrisna PrimaputraNo ratings yet
- Unit 3Document39 pagesUnit 3Bhavani GNo ratings yet
- Group 11 Ba PresentationDocument11 pagesGroup 11 Ba PresentationRaveendra SrnNo ratings yet
- Lesson 3 Artificial Neural NetworkDocument77 pagesLesson 3 Artificial Neural NetworkVIJENDHER REDDY GURRAMNo ratings yet
- Deep Learning Unit 1Document32 pagesDeep Learning Unit 1Aditya Pratap SinghNo ratings yet
- H2o ProtDocument359 pagesH2o ProtJoël Fleur Nzamba KombilaNo ratings yet
- Difference Between CURE Clustering and DBSCAN Clustering - GeeksforGeeksDocument3 pagesDifference Between CURE Clustering and DBSCAN Clustering - GeeksforGeeksRavindra Kumar PrajapatiNo ratings yet
- MITXPRO BROCHURE Deep Learning DRN ENG Oct 2021Document9 pagesMITXPRO BROCHURE Deep Learning DRN ENG Oct 2021Kevin FloresNo ratings yet
- 08 An Example of NN Using ReLuDocument10 pages08 An Example of NN Using ReLuHafshah DeviNo ratings yet
- Artificial Neural Networks: ReferencesDocument57 pagesArtificial Neural Networks: Referencesprathap394No ratings yet
- KSC2016 - Recurrent Neural NetworksDocument66 pagesKSC2016 - Recurrent Neural NetworksshafiahmedbdNo ratings yet
- CIS787-Final Review: Reza Zafarani (Reza@data - Syr.edu)Document11 pagesCIS787-Final Review: Reza Zafarani (Reza@data - Syr.edu)ankurkothariNo ratings yet
- Data Clustering (Contd) : CS771: Introduction To Machine Learning Piyush RaiDocument15 pagesData Clustering (Contd) : CS771: Introduction To Machine Learning Piyush RaiRajachandra VoodigaNo ratings yet
- ClusteringDocument36 pagesClusteringKapildev KumarNo ratings yet
- Echo State NetworkDocument4 pagesEcho State Networknigel989No ratings yet
- LSTM LectureDocument163 pagesLSTM LectureGunnar CalvertNo ratings yet
- Winsem2020-21 Eee1007 Eth Vl2020210500383 Model Question Paper Eee1007 QPDocument4 pagesWinsem2020-21 Eee1007 Eth Vl2020210500383 Model Question Paper Eee1007 QPAPURVA PATEL 19BEI0020No ratings yet
- Perceptrons and SVMS: Cs771: Introduction To Machine Learning NisheethDocument18 pagesPerceptrons and SVMS: Cs771: Introduction To Machine Learning NisheethRajaNo ratings yet
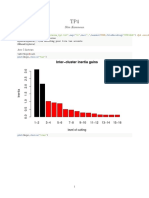
- Inter Cluster Inertia Gains: Slim KammounDocument13 pagesInter Cluster Inertia Gains: Slim KammounJames OptimisteNo ratings yet
- 2022 Ac ExnormalDocument7 pages2022 Ac ExnormalPedro SilvaNo ratings yet
- Asset-V1 MITx+6.86x+3T2020+typeasset+blockslides Lecture6 CompressedDocument22 pagesAsset-V1 MITx+6.86x+3T2020+typeasset+blockslides Lecture6 CompressedRahul VasanthNo ratings yet
- 2019 6S191 L3 PDFDocument71 pages2019 6S191 L3 PDFManash Jyoti KalitaNo ratings yet
- ClusteringDocument21 pagesClusteringdeetsha.banerjeeNo ratings yet
- Activation Functions: Sigmoid, Tanh, Relu, Leaky Relu, Prelu, Elu, Threshold Relu and Softmax Basics For Neural Networks and Deep LearningDocument15 pagesActivation Functions: Sigmoid, Tanh, Relu, Leaky Relu, Prelu, Elu, Threshold Relu and Softmax Basics For Neural Networks and Deep LearningRMolina65No ratings yet
- Assignment MtechDocument5 pagesAssignment MtechyounisNo ratings yet
- Welcome To:: Introduction To Classification & Classification AlgorithmsDocument42 pagesWelcome To:: Introduction To Classification & Classification AlgorithmsAasmiNo ratings yet
- Fundamentals of Deep Learning: Part 2: How A Neural Network TrainsDocument54 pagesFundamentals of Deep Learning: Part 2: How A Neural Network TrainsPraveen SinghNo ratings yet