
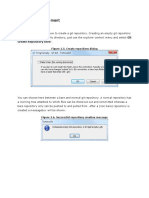
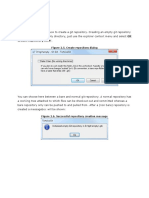
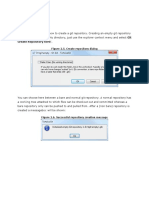
DQ Standardization
DQ Standardization
You might also like
- SCL Cheat SheetDocument2 pagesSCL Cheat SheetboegschroefNo ratings yet
- MSX Basic ManualDocument105 pagesMSX Basic Manualelastomania67% (3)
- 100+ SQL Queries T-SQL for Microsoft SQL ServerFrom Everand100+ SQL Queries T-SQL for Microsoft SQL ServerRating: 4 out of 5 stars4/5 (17)
- Introduction To DataStageDocument111 pagesIntroduction To DataStageabreddy2003No ratings yet
- Chapter 4.1 Introduction To Assembly LanguageDocument46 pagesChapter 4.1 Introduction To Assembly LanguagecudarunNo ratings yet
- DBMS Lab Manual 2017Document69 pagesDBMS Lab Manual 2017Monica GaneshNo ratings yet
- Pattern Action Reference: Ibm Infosphere QualitystageDocument74 pagesPattern Action Reference: Ibm Infosphere QualitystagezipzapdhoomNo ratings yet
- SAS PresentationDocument35 pagesSAS PresentationJaideep DhimanNo ratings yet
- Experiment-5: Addressing Modes, CALL, RET, XLAT, Stack, ArraysDocument27 pagesExperiment-5: Addressing Modes, CALL, RET, XLAT, Stack, ArraysAnik MazumderNo ratings yet
- Spatial Query LanguageDocument18 pagesSpatial Query LanguageKrishna GautamNo ratings yet
- ComputerDocument47 pagesComputerHarish DNo ratings yet
- Computer NotesDocument47 pagesComputer NotesHarish DNo ratings yet
- Consolidated L&DDocument70 pagesConsolidated L&DAnantha RamanNo ratings yet
- 10th Order by NotesDocument11 pages10th Order by NotesAshwiniNo ratings yet
- Oracle - Error at Command Line - 1 Column - 698 Error Report - SQL Error - ORA-00984 - Column Not Allowed Here - Stack OverflowDocument2 pagesOracle - Error at Command Line - 1 Column - 698 Error Report - SQL Error - ORA-00984 - Column Not Allowed Here - Stack OverflowsoydeyudruNo ratings yet
- Reading Data in SASDocument9 pagesReading Data in SASChand ShaNo ratings yet
- TSQL and Index Cheat SheetDocument16 pagesTSQL and Index Cheat SheetMehmood SulimanNo ratings yet
- Relational LanguageDocument69 pagesRelational LanguageSonia SahityaNo ratings yet
- DBDocument59 pagesDBshahbazNo ratings yet
- Working With Strings: Select Ucase (Lastname) As (Last), Ucase (Firstname) As (First), City, State, Zip From CustomersDocument15 pagesWorking With Strings: Select Ucase (Lastname) As (Last), Ucase (Firstname) As (First), City, State, Zip From Customersprsiva2420034066No ratings yet
- Dbms 4Document55 pagesDbms 4Krishna ChaitanyaNo ratings yet
- Table 2-1 Core SQL:2003 CommandsDocument8 pagesTable 2-1 Core SQL:2003 CommandsZoran VasicNo ratings yet
- Chapter 4.1 Introduction To Assembly LanguageDocument46 pagesChapter 4.1 Introduction To Assembly LanguagesagniNo ratings yet
- Contents (Exploded View) : z/OS DFSORT Application Programming Guide Previous TopicDocument15 pagesContents (Exploded View) : z/OS DFSORT Application Programming Guide Previous TopicNelson FerruchoNo ratings yet
- HW3 DB/Sudoku: Part A - DatabaseDocument13 pagesHW3 DB/Sudoku: Part A - DatabaseShubham GoyalNo ratings yet
- Newvar Varname: Encode - Encode String Into Numeric and Vice VersaDocument7 pagesNewvar Varname: Encode - Encode String Into Numeric and Vice VersaAndrew TandohNo ratings yet
- Proc - ContentsDocument6 pagesProc - Contentsnagap1914No ratings yet
- Structured Query LanguageDocument73 pagesStructured Query LanguageradwanNo ratings yet
- Chapter 1: Creating SAS Data Sets - The BasicDocument78 pagesChapter 1: Creating SAS Data Sets - The BasicJacky PoNo ratings yet
- Sas Asst 3Document9 pagesSas Asst 3Mallikarjun MangapuramNo ratings yet
- LAB - 7 - R - AKASH - 20BCE1501 - TemplateDocument15 pagesLAB - 7 - R - AKASH - 20BCE1501 - TemplateATTHUNURI RAJESH REDDY 20BCE1658No ratings yet
- Chapter 4 Assembly Language and ProgrammingDocument85 pagesChapter 4 Assembly Language and ProgrammingPetra Kalasa100% (1)
- Dbms ProjectDocument30 pagesDbms ProjectPankaj SharmaNo ratings yet
- Basic SQL: CHAPTER 4 (6/E) CHAPTER 8 (5/E)Document28 pagesBasic SQL: CHAPTER 4 (6/E) CHAPTER 8 (5/E)Will IztarNo ratings yet
- Database Management System (DBMS) Project On The Topic "Online Music Library"Document30 pagesDatabase Management System (DBMS) Project On The Topic "Online Music Library"abhi rajNo ratings yet
- Lecture 05 SQL DefinitionDocument51 pagesLecture 05 SQL DefinitionTrịnh Thái TuấnNo ratings yet
- Experiment-5: Addressing Modes, CALL, RET, XLAT, Stack, ArraysDocument27 pagesExperiment-5: Addressing Modes, CALL, RET, XLAT, Stack, ArraysAnik MazumderNo ratings yet
- L2 - The Relational ModelDocument30 pagesL2 - The Relational ModelKatrina youngNo ratings yet
- Paper 233-30 An Introduction To SAS® Character Functions (Including Some New SAS®9 Functions) Ronald Cody, Ed.DDocument15 pagesPaper 233-30 An Introduction To SAS® Character Functions (Including Some New SAS®9 Functions) Ronald Cody, Ed.Disaias.prestesNo ratings yet
- Lecture 9 ArraysDocument7 pagesLecture 9 Arraysapi-3739389100% (5)
- Lecture1 SQLDocument44 pagesLecture1 SQLBirhanu AtnafuNo ratings yet
- SQLDocument71 pagesSQLDrKrishna Priya ChakireddyNo ratings yet
- ComparchDocument59 pagesComparchhaileasrat4No ratings yet
- CH1 Book BackDocument7 pagesCH1 Book Backvasanthi niranjanNo ratings yet
- SQL 1Document22 pagesSQL 1kvsureshmysoreNo ratings yet
- Name Synopsis: Rrdtool Xport:vnameDocument3 pagesName Synopsis: Rrdtool Xport:vnameAymen ChaoukiNo ratings yet
- Taming The Proc Transpose PDFDocument5 pagesTaming The Proc Transpose PDFSantosh KumarNo ratings yet
- DBMS Lecture04Document40 pagesDBMS Lecture04Haseeb MuhammadNo ratings yet
- W3 Syntax ReviewDocument4 pagesW3 Syntax ReviewCansu YöreoğluNo ratings yet
- VoLTE Site Activation in TAS - 01042019123938Document20 pagesVoLTE Site Activation in TAS - 01042019123938Gustavo BessoneNo ratings yet
- CS352H Computer Systems Architecture: Lecture 2: Instruction Set Architectures I September 1, 2009Document23 pagesCS352H Computer Systems Architecture: Lecture 2: Instruction Set Architectures I September 1, 2009farah_nishuNo ratings yet
- Meenakshi AroraDocument34 pagesMeenakshi AroraManmeet Kaur100% (1)
- SAS Slides 2: Basics of SAS Programming LanguageDocument25 pagesSAS Slides 2: Basics of SAS Programming LanguageSASTechies100% (1)
- 100+ SQL Queries Jet SQL for Microsoft Office AccessFrom Everand100+ SQL Queries Jet SQL for Microsoft Office AccessRating: 5 out of 5 stars5/5 (1)
- Advanced SAS Interview Questions You'll Most Likely Be AskedFrom EverandAdvanced SAS Interview Questions You'll Most Likely Be AskedNo ratings yet
- Querying with SQL T-SQL for Microsoft SQL ServerFrom EverandQuerying with SQL T-SQL for Microsoft SQL ServerRating: 2.5 out of 5 stars2.5/5 (4)
- S.No Emp - No Emp - Name Designation Department DOJ Current - Location Mobile NoDocument16 pagesS.No Emp - No Emp - Name Designation Department DOJ Current - Location Mobile Noabreddy2003No ratings yet
- Data Stage Course Content: Unit-1 Data Warehousing ConceptsDocument3 pagesData Stage Course Content: Unit-1 Data Warehousing Conceptsabreddy2003No ratings yet
- Bhaskar ReddyDocument7 pagesBhaskar Reddyabreddy2003No ratings yet
- Reference ResidualDocument150 pagesReference Residualabreddy2003No ratings yet
- Bhaskar Datastage Profile2Document7 pagesBhaskar Datastage Profile2abreddy2003No ratings yet
- Datastage ArchitectureDocument4 pagesDatastage Architecturenithinmamidala999No ratings yet
- IA RulesDocument120 pagesIA Rulesabreddy2003No ratings yet
- Data Stage Scenarios: Scenario1. Cummilative SumDocument13 pagesData Stage Scenarios: Scenario1. Cummilative Sumabreddy2003No ratings yet
- DataStage XML and Web Services Packs OverviewDocument71 pagesDataStage XML and Web Services Packs Overviewnithinmamidala999No ratings yet
- Git ExtDocument1 pageGit Extabreddy2003No ratings yet
- Ds QuestionsDocument11 pagesDs Questionsabreddy2003No ratings yet
- Git DocDocument1 pageGit Docabreddy2003No ratings yet
- Git ExtensionDocument1 pageGit Extensionabreddy2003No ratings yet
- How To Start SQL Assistant Using Batch Mode or Using Command Prompt?Document9 pagesHow To Start SQL Assistant Using Batch Mode or Using Command Prompt?abreddy2003No ratings yet
- How To Start SQL Assistant Using Batch Mode or Using Command Prompt?Document9 pagesHow To Start SQL Assistant Using Batch Mode or Using Command Prompt?abreddy2003No ratings yet
- Chapter 3 InternetDocument33 pagesChapter 3 InternetJeanette LynnNo ratings yet
- HD Consumer Behavior AssignmentDocument9 pagesHD Consumer Behavior AssignmentAishwaryaNo ratings yet
- Power Electronics ProjectDocument38 pagesPower Electronics Projectvishwatheja198950% (2)
- 9th Biology NotesDocument12 pages9th Biology Notesramaiz darNo ratings yet
- PR m1Document15 pagesPR m1Jazmyn BulusanNo ratings yet
- Latest Volleyball News From The NCAA and NAIADocument3 pagesLatest Volleyball News From The NCAA and NAIAFernan RomeroNo ratings yet
- Rahmania Tbi 6 D Soe...Document9 pagesRahmania Tbi 6 D Soe...Rahmania Aulia PurwagunifaNo ratings yet
- The First Vertebrates, Jawless Fishes, The Agnathans: 2.1 OstracodermsDocument22 pagesThe First Vertebrates, Jawless Fishes, The Agnathans: 2.1 OstracodermsAlejandro Tepoz TelloNo ratings yet
- Final PDF - To Be Hard BindDocument59 pagesFinal PDF - To Be Hard BindShobhit GuptaNo ratings yet
- Explosion Protection - E PDFDocument7 pagesExplosion Protection - E PDFAPCANo ratings yet
- Tranzen1A Income TaxDocument46 pagesTranzen1A Income TaxMonica SorianoNo ratings yet
- Moxa PT g7728 Series Manual v1.4Document128 pagesMoxa PT g7728 Series Manual v1.4Walter Oluoch OtienoNo ratings yet
- Parasnis - 1951 - Study Rock MidlandsDocument20 pagesParasnis - 1951 - Study Rock MidlandsIsaac KandaNo ratings yet
- Activity Sheets Signal WordsDocument15 pagesActivity Sheets Signal WordsGrace Ann EscabarteNo ratings yet
- Shapes of NailsDocument14 pagesShapes of NailsIyannNo ratings yet
- 04-46 Analysis of Gold-Copper Braze Joint in Glidcop For UHV Components at The APS W.Toter S.SharmaDocument10 pages04-46 Analysis of Gold-Copper Braze Joint in Glidcop For UHV Components at The APS W.Toter S.SharmaKai XuNo ratings yet
- Bolting Chart For Industrial FlangesDocument6 pagesBolting Chart For Industrial FlangesPritam JadhavNo ratings yet
- Lancaster University Dissertation HandbookDocument5 pagesLancaster University Dissertation HandbookPaperWritingServiceCheapAnnArbor100% (1)
- SPB ClientDocument4 pagesSPB ClientRKNo ratings yet
- Clique Student Sheet (Manteran Lamo)Document4 pagesClique Student Sheet (Manteran Lamo)Dina Rizkia RachmahNo ratings yet
- Chapter 6Document18 pagesChapter 6Lydelle Mae CabaltejaNo ratings yet
- 3I Grading Rubric For Output PresentationDocument2 pages3I Grading Rubric For Output PresentationBinibining Michelle CenizaNo ratings yet
- Oracle Read STATSPACK OutputDocument43 pagesOracle Read STATSPACK OutputRajNo ratings yet
- Policy Copy 3005 314095178 00 000Document3 pagesPolicy Copy 3005 314095178 00 000alagardharshan2No ratings yet
- AP Practice Test - BreakdownDocument4 pagesAP Practice Test - BreakdowncheyNo ratings yet
- The Laws On Local Governments SyllabusDocument4 pagesThe Laws On Local Governments SyllabusJohn Kevin ArtuzNo ratings yet
- A Picture Is Worth A Thousand Words: The Benefit of Medical Illustration in Medical PublishingDocument6 pagesA Picture Is Worth A Thousand Words: The Benefit of Medical Illustration in Medical PublishingSinisa RisticNo ratings yet
- WRAP - Case Study - Aggregates - The Channel Tunnel Rail LinkDocument2 pagesWRAP - Case Study - Aggregates - The Channel Tunnel Rail LinkFatmah El WardagyNo ratings yet
- (00 Cari) - Iso - 8466 1 1990Document5 pages(00 Cari) - Iso - 8466 1 1990faridsidikNo ratings yet
- Asset Accounting (J62) - Process DiagramsDocument8 pagesAsset Accounting (J62) - Process DiagramsMohammed Nawaz ShariffNo ratings yet







































































































Download as docx, pdf, or txt
You might also like
- SCL Cheat SheetDocument2 pagesSCL Cheat SheetboegschroefNo ratings yet
- MSX Basic ManualDocument105 pagesMSX Basic Manualelastomania67% (3)
- 100+ SQL Queries T-SQL for Microsoft SQL ServerFrom Everand100+ SQL Queries T-SQL for Microsoft SQL ServerRating: 4 out of 5 stars4/5 (17)
- Introduction To DataStageDocument111 pagesIntroduction To DataStageabreddy2003No ratings yet
- Chapter 4.1 Introduction To Assembly LanguageDocument46 pagesChapter 4.1 Introduction To Assembly LanguagecudarunNo ratings yet
- DBMS Lab Manual 2017Document69 pagesDBMS Lab Manual 2017Monica GaneshNo ratings yet
- Pattern Action Reference: Ibm Infosphere QualitystageDocument74 pagesPattern Action Reference: Ibm Infosphere QualitystagezipzapdhoomNo ratings yet
- SAS PresentationDocument35 pagesSAS PresentationJaideep DhimanNo ratings yet
- Experiment-5: Addressing Modes, CALL, RET, XLAT, Stack, ArraysDocument27 pagesExperiment-5: Addressing Modes, CALL, RET, XLAT, Stack, ArraysAnik MazumderNo ratings yet
- Spatial Query LanguageDocument18 pagesSpatial Query LanguageKrishna GautamNo ratings yet
- ComputerDocument47 pagesComputerHarish DNo ratings yet
- Computer NotesDocument47 pagesComputer NotesHarish DNo ratings yet
- Consolidated L&DDocument70 pagesConsolidated L&DAnantha RamanNo ratings yet
- 10th Order by NotesDocument11 pages10th Order by NotesAshwiniNo ratings yet
- Oracle - Error at Command Line - 1 Column - 698 Error Report - SQL Error - ORA-00984 - Column Not Allowed Here - Stack OverflowDocument2 pagesOracle - Error at Command Line - 1 Column - 698 Error Report - SQL Error - ORA-00984 - Column Not Allowed Here - Stack OverflowsoydeyudruNo ratings yet
- Reading Data in SASDocument9 pagesReading Data in SASChand ShaNo ratings yet
- TSQL and Index Cheat SheetDocument16 pagesTSQL and Index Cheat SheetMehmood SulimanNo ratings yet
- Relational LanguageDocument69 pagesRelational LanguageSonia SahityaNo ratings yet
- DBDocument59 pagesDBshahbazNo ratings yet
- Working With Strings: Select Ucase (Lastname) As (Last), Ucase (Firstname) As (First), City, State, Zip From CustomersDocument15 pagesWorking With Strings: Select Ucase (Lastname) As (Last), Ucase (Firstname) As (First), City, State, Zip From Customersprsiva2420034066No ratings yet
- Dbms 4Document55 pagesDbms 4Krishna ChaitanyaNo ratings yet
- Table 2-1 Core SQL:2003 CommandsDocument8 pagesTable 2-1 Core SQL:2003 CommandsZoran VasicNo ratings yet
- Chapter 4.1 Introduction To Assembly LanguageDocument46 pagesChapter 4.1 Introduction To Assembly LanguagesagniNo ratings yet
- Contents (Exploded View) : z/OS DFSORT Application Programming Guide Previous TopicDocument15 pagesContents (Exploded View) : z/OS DFSORT Application Programming Guide Previous TopicNelson FerruchoNo ratings yet
- HW3 DB/Sudoku: Part A - DatabaseDocument13 pagesHW3 DB/Sudoku: Part A - DatabaseShubham GoyalNo ratings yet
- Newvar Varname: Encode - Encode String Into Numeric and Vice VersaDocument7 pagesNewvar Varname: Encode - Encode String Into Numeric and Vice VersaAndrew TandohNo ratings yet
- Proc - ContentsDocument6 pagesProc - Contentsnagap1914No ratings yet
- Structured Query LanguageDocument73 pagesStructured Query LanguageradwanNo ratings yet
- Chapter 1: Creating SAS Data Sets - The BasicDocument78 pagesChapter 1: Creating SAS Data Sets - The BasicJacky PoNo ratings yet
- Sas Asst 3Document9 pagesSas Asst 3Mallikarjun MangapuramNo ratings yet
- LAB - 7 - R - AKASH - 20BCE1501 - TemplateDocument15 pagesLAB - 7 - R - AKASH - 20BCE1501 - TemplateATTHUNURI RAJESH REDDY 20BCE1658No ratings yet
- Chapter 4 Assembly Language and ProgrammingDocument85 pagesChapter 4 Assembly Language and ProgrammingPetra Kalasa100% (1)
- Dbms ProjectDocument30 pagesDbms ProjectPankaj SharmaNo ratings yet
- Basic SQL: CHAPTER 4 (6/E) CHAPTER 8 (5/E)Document28 pagesBasic SQL: CHAPTER 4 (6/E) CHAPTER 8 (5/E)Will IztarNo ratings yet
- Database Management System (DBMS) Project On The Topic "Online Music Library"Document30 pagesDatabase Management System (DBMS) Project On The Topic "Online Music Library"abhi rajNo ratings yet
- Lecture 05 SQL DefinitionDocument51 pagesLecture 05 SQL DefinitionTrịnh Thái TuấnNo ratings yet
- Experiment-5: Addressing Modes, CALL, RET, XLAT, Stack, ArraysDocument27 pagesExperiment-5: Addressing Modes, CALL, RET, XLAT, Stack, ArraysAnik MazumderNo ratings yet
- L2 - The Relational ModelDocument30 pagesL2 - The Relational ModelKatrina youngNo ratings yet
- Paper 233-30 An Introduction To SAS® Character Functions (Including Some New SAS®9 Functions) Ronald Cody, Ed.DDocument15 pagesPaper 233-30 An Introduction To SAS® Character Functions (Including Some New SAS®9 Functions) Ronald Cody, Ed.Disaias.prestesNo ratings yet
- Lecture 9 ArraysDocument7 pagesLecture 9 Arraysapi-3739389100% (5)
- Lecture1 SQLDocument44 pagesLecture1 SQLBirhanu AtnafuNo ratings yet
- SQLDocument71 pagesSQLDrKrishna Priya ChakireddyNo ratings yet
- ComparchDocument59 pagesComparchhaileasrat4No ratings yet
- CH1 Book BackDocument7 pagesCH1 Book Backvasanthi niranjanNo ratings yet
- SQL 1Document22 pagesSQL 1kvsureshmysoreNo ratings yet
- Name Synopsis: Rrdtool Xport:vnameDocument3 pagesName Synopsis: Rrdtool Xport:vnameAymen ChaoukiNo ratings yet
- Taming The Proc Transpose PDFDocument5 pagesTaming The Proc Transpose PDFSantosh KumarNo ratings yet
- DBMS Lecture04Document40 pagesDBMS Lecture04Haseeb MuhammadNo ratings yet
- W3 Syntax ReviewDocument4 pagesW3 Syntax ReviewCansu YöreoğluNo ratings yet
- VoLTE Site Activation in TAS - 01042019123938Document20 pagesVoLTE Site Activation in TAS - 01042019123938Gustavo BessoneNo ratings yet
- CS352H Computer Systems Architecture: Lecture 2: Instruction Set Architectures I September 1, 2009Document23 pagesCS352H Computer Systems Architecture: Lecture 2: Instruction Set Architectures I September 1, 2009farah_nishuNo ratings yet
- Meenakshi AroraDocument34 pagesMeenakshi AroraManmeet Kaur100% (1)
- SAS Slides 2: Basics of SAS Programming LanguageDocument25 pagesSAS Slides 2: Basics of SAS Programming LanguageSASTechies100% (1)
- 100+ SQL Queries Jet SQL for Microsoft Office AccessFrom Everand100+ SQL Queries Jet SQL for Microsoft Office AccessRating: 5 out of 5 stars5/5 (1)
- Advanced SAS Interview Questions You'll Most Likely Be AskedFrom EverandAdvanced SAS Interview Questions You'll Most Likely Be AskedNo ratings yet
- Querying with SQL T-SQL for Microsoft SQL ServerFrom EverandQuerying with SQL T-SQL for Microsoft SQL ServerRating: 2.5 out of 5 stars2.5/5 (4)
- S.No Emp - No Emp - Name Designation Department DOJ Current - Location Mobile NoDocument16 pagesS.No Emp - No Emp - Name Designation Department DOJ Current - Location Mobile Noabreddy2003No ratings yet
- Data Stage Course Content: Unit-1 Data Warehousing ConceptsDocument3 pagesData Stage Course Content: Unit-1 Data Warehousing Conceptsabreddy2003No ratings yet
- Bhaskar ReddyDocument7 pagesBhaskar Reddyabreddy2003No ratings yet
- Reference ResidualDocument150 pagesReference Residualabreddy2003No ratings yet
- Bhaskar Datastage Profile2Document7 pagesBhaskar Datastage Profile2abreddy2003No ratings yet
- Datastage ArchitectureDocument4 pagesDatastage Architecturenithinmamidala999No ratings yet
- IA RulesDocument120 pagesIA Rulesabreddy2003No ratings yet
- Data Stage Scenarios: Scenario1. Cummilative SumDocument13 pagesData Stage Scenarios: Scenario1. Cummilative Sumabreddy2003No ratings yet
- DataStage XML and Web Services Packs OverviewDocument71 pagesDataStage XML and Web Services Packs Overviewnithinmamidala999No ratings yet
- Git ExtDocument1 pageGit Extabreddy2003No ratings yet
- Ds QuestionsDocument11 pagesDs Questionsabreddy2003No ratings yet
- Git DocDocument1 pageGit Docabreddy2003No ratings yet
- Git ExtensionDocument1 pageGit Extensionabreddy2003No ratings yet
- How To Start SQL Assistant Using Batch Mode or Using Command Prompt?Document9 pagesHow To Start SQL Assistant Using Batch Mode or Using Command Prompt?abreddy2003No ratings yet
- How To Start SQL Assistant Using Batch Mode or Using Command Prompt?Document9 pagesHow To Start SQL Assistant Using Batch Mode or Using Command Prompt?abreddy2003No ratings yet
- Chapter 3 InternetDocument33 pagesChapter 3 InternetJeanette LynnNo ratings yet
- HD Consumer Behavior AssignmentDocument9 pagesHD Consumer Behavior AssignmentAishwaryaNo ratings yet
- Power Electronics ProjectDocument38 pagesPower Electronics Projectvishwatheja198950% (2)
- 9th Biology NotesDocument12 pages9th Biology Notesramaiz darNo ratings yet
- PR m1Document15 pagesPR m1Jazmyn BulusanNo ratings yet
- Latest Volleyball News From The NCAA and NAIADocument3 pagesLatest Volleyball News From The NCAA and NAIAFernan RomeroNo ratings yet
- Rahmania Tbi 6 D Soe...Document9 pagesRahmania Tbi 6 D Soe...Rahmania Aulia PurwagunifaNo ratings yet
- The First Vertebrates, Jawless Fishes, The Agnathans: 2.1 OstracodermsDocument22 pagesThe First Vertebrates, Jawless Fishes, The Agnathans: 2.1 OstracodermsAlejandro Tepoz TelloNo ratings yet
- Final PDF - To Be Hard BindDocument59 pagesFinal PDF - To Be Hard BindShobhit GuptaNo ratings yet
- Explosion Protection - E PDFDocument7 pagesExplosion Protection - E PDFAPCANo ratings yet
- Tranzen1A Income TaxDocument46 pagesTranzen1A Income TaxMonica SorianoNo ratings yet
- Moxa PT g7728 Series Manual v1.4Document128 pagesMoxa PT g7728 Series Manual v1.4Walter Oluoch OtienoNo ratings yet
- Parasnis - 1951 - Study Rock MidlandsDocument20 pagesParasnis - 1951 - Study Rock MidlandsIsaac KandaNo ratings yet
- Activity Sheets Signal WordsDocument15 pagesActivity Sheets Signal WordsGrace Ann EscabarteNo ratings yet
- Shapes of NailsDocument14 pagesShapes of NailsIyannNo ratings yet
- 04-46 Analysis of Gold-Copper Braze Joint in Glidcop For UHV Components at The APS W.Toter S.SharmaDocument10 pages04-46 Analysis of Gold-Copper Braze Joint in Glidcop For UHV Components at The APS W.Toter S.SharmaKai XuNo ratings yet
- Bolting Chart For Industrial FlangesDocument6 pagesBolting Chart For Industrial FlangesPritam JadhavNo ratings yet
- Lancaster University Dissertation HandbookDocument5 pagesLancaster University Dissertation HandbookPaperWritingServiceCheapAnnArbor100% (1)
- SPB ClientDocument4 pagesSPB ClientRKNo ratings yet
- Clique Student Sheet (Manteran Lamo)Document4 pagesClique Student Sheet (Manteran Lamo)Dina Rizkia RachmahNo ratings yet
- Chapter 6Document18 pagesChapter 6Lydelle Mae CabaltejaNo ratings yet
- 3I Grading Rubric For Output PresentationDocument2 pages3I Grading Rubric For Output PresentationBinibining Michelle CenizaNo ratings yet
- Oracle Read STATSPACK OutputDocument43 pagesOracle Read STATSPACK OutputRajNo ratings yet
- Policy Copy 3005 314095178 00 000Document3 pagesPolicy Copy 3005 314095178 00 000alagardharshan2No ratings yet
- AP Practice Test - BreakdownDocument4 pagesAP Practice Test - BreakdowncheyNo ratings yet
- The Laws On Local Governments SyllabusDocument4 pagesThe Laws On Local Governments SyllabusJohn Kevin ArtuzNo ratings yet
- A Picture Is Worth A Thousand Words: The Benefit of Medical Illustration in Medical PublishingDocument6 pagesA Picture Is Worth A Thousand Words: The Benefit of Medical Illustration in Medical PublishingSinisa RisticNo ratings yet
- WRAP - Case Study - Aggregates - The Channel Tunnel Rail LinkDocument2 pagesWRAP - Case Study - Aggregates - The Channel Tunnel Rail LinkFatmah El WardagyNo ratings yet
- (00 Cari) - Iso - 8466 1 1990Document5 pages(00 Cari) - Iso - 8466 1 1990faridsidikNo ratings yet
- Asset Accounting (J62) - Process DiagramsDocument8 pagesAsset Accounting (J62) - Process DiagramsMohammed Nawaz ShariffNo ratings yet